







目录
4.Advantages and disadvantages
5.Conclusions and future work(idea)
0. Abstract
我们提出了一个新的框架,通过一个对抗的过程来估计生成模型,在此过程中我们同时训练两个模型:一个生成模型G捕获数据分布,和一种判别模型D,它估计样本来自训练数据而不是G的概率。G的训练程序是最大化D犯错的概率,这个框架对应于一个极小极大的双人游戏。在任意函数G和D的空间中,存在唯一解,G可以重现训练数据分布,D处处等于1/2。在G和D由多层感知器定义的情况下,整个系统可以通过反向传播进行训练。在训练或生成样本的过程中,不需要任何马尔科夫链或展开的近似推理网络。通过对生成的样本进行定性和定量评估,实验证明了该框架的潜力。
1. Introduction
深度学习的前景是发现丰富的分层模型,它代表人工智能应用中遇到的各种数据的概率分布,如自然图像、包含语音的音频波形和自然语言语料库中的符号。到目前为止,在深度学习中最显著的成功涉及到判别模型,通常是那些将高维、丰富的感官输入映射到类标签的模型。这些惊人的成功主要是基于反向传播和dropout算法,使用分段线性单元,具有特别良好的梯度。由于在极大似然估计和相关策略中出现的许多难以处理的概率计算的近似性,以及由于难以在生成环境中利用分段线性单元的优点,深度生成模型的影响较小。我们提出了一种新的生成模型估计方法来克服这些困难。
在提出的对抗网框架中,生成模型与对手进行了比较:一个学习确定样本是来自模型分布还是来自数据分布的判别模型。生成模型可以被认为类似于一组伪造者,他们试图制造假币并在不被发现的情况下使用它,而判别模型则类似于警察,试图发现假币,这个游戏的竞争促使两队改进他们的方法,直到仿冒品无法从真品中辨别出来。
该框架可以生成针对多种模型的特定训练算法和优化算法,在这篇文章中,我们探讨了生成模型通过一个多层感知器传递随机噪声来生成样本的特殊情况,而判别模型也是一个多层感知器,我们把这种特殊情况称为对抗网络。在这种情况下,我们可以只使用非常成功的反向传播和dropout算法来训练这两个模型,并且只使用正向传播来训练生成模型的样本,不需要近似推论或马尔科夫链。
2. Relatedwork
有潜在变量的有向图形模型的另一种选择是有潜在变量的无向图形模型,如限制玻尔兹曼机(RBMs),深玻尔兹曼机(DBMs)及其众多变体。这些模型中的相互作用被表示为未归一化势函数的乘积,由随机变量所有状态的全局求和/积分进行归一化。这个数量(配分函数)和它的梯度是棘手的,但最琐碎的情况下,虽然他们可以由马尔可夫链蒙特卡罗(MCMC)方法估计。对于依赖于MCMC的学习算法来说,混合是一个很重要的问题。
深度置信网络(DBNs)[16]是包含一个无向层和多个有向层的混合模型。虽然存在一种快速的分层近似训练准则,但DBNs存在与无向和有向模型相关的计算困难。
也有人提出了不近似或不限制对数似然的替代标准,如分数匹配和噪声对比估计(NCE),这两种方法都要求所学习的概率密度被解析指定为一个归一化常数。请注意,在许多具有多层潜在变量(如DBNs和DBMs)的有趣生成模型中,甚至不可能导出可处理的非规范化概率密度,一些模型,如去噪自动编码器[30]和收缩自动编码器的学习规则非常类似于分数匹配应用于RBMs。在NCE中,与本文一样,使用了判别训练准则来拟合生成模型。然而,生成模型本身用于从固定噪声分布的样本中区分生成的数据,而不是拟合一个单独的判别模型。由于NCE使用一个固定的噪声分布,当模型学习到即使是在观察变量的一个小子集上的一个近似正确的分布之后,学习速度也会显著减慢。
最后,一些技术不涉及明确定义概率分布,而是训练生成机器从期望的分布中抽取样本,这种方法的优点是可以通过反向传播来训练这些机器。近期主要的工作包括生成随机网络(GSN)框架:它扩展了广义去噪自动编码器:两者都可以看作是定义一个参数化的马尔科夫链,即一个人学习机器的参数,执行一个步骤的生成马尔科夫链。与GSNs相比,对抗网的采样不需要马尔科夫链,由于反求网络在生成过程中不需要反馈环,所以它们能够更好地利用分段线性单元,这提高了反向传播的性能,但在使用反馈环时存在无限制激活的问题。通过反向传播训练生成机器的最新例子包括自动编码变分贝叶斯和随机反向传播。
当模型都是多层感知器时,对抗性建模框架最容易应用。为了学习生成器在数据x上的分布pg,我们定义了一个输入噪声变量pz (z), G (z;θg)表示将噪声变量映射到数据空间, G是一个可微函数,表示为一个参数为θg的多层感知器。我们还定义一个多层感知器D (x;θd)输出一个标量,D(x)表示x来自数据集而不是pg的概率。我们训练D最大限度地将正确的标签分配给训练样本和来自G的样本的概率,我们同时训练G,使得 log(1 - D(G(z))) 最小化。
换句话说,D和G玩了一个具有值函数V (G,D)的二人极大极小博弈:

在下一节中,我们将对对抗网进行理论分析,主要说明当G和D具有足够的容量时,训练准则允许恢复数据生成分布,例如在非参数极限下。请参见图1,其中对该方法进行了不太正式的、更具教育性的解释。在实践中,我们必须使用迭代的数值方法来实现游戏。优化完成内环的训练在计算上是禁止的,对于有限的数据集会导致过度拟合。相反,我们在优化D的k个步骤和优化G的一个步骤之间交替进行,只要G变化足够慢,D就会保持在其最优解附近,这种策略类似于SML/PCD:训练从一个学习步骤到下一个学习步骤保持来自马尔可夫链的样本,该过程在算法1中正式给出。
在实际应用中,公式1可能无法为G提供足够的梯度来学习。在学习的早期,当G较差时,D可以很有信心地拒绝样本,因为它们与训练数据明显不同。在这种情况下,log(1 - D(G(z)))饱和,与其训练G去最小化log(1 - D(G(z))不如训练G去最大化logD(G(z))这一目标函数的结果与动态函数相同,但在学习中提供了更强的学习效果。
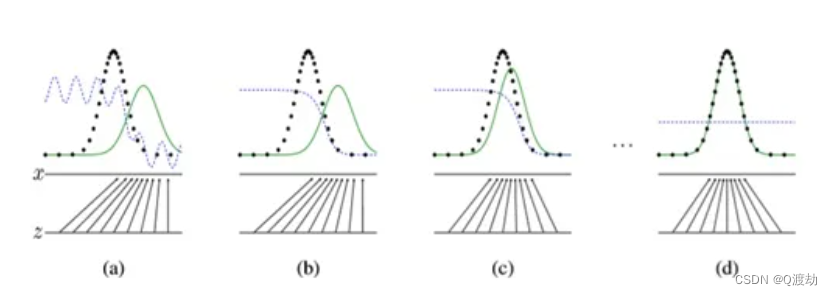
注:图中的黑色虚线表示真实的样本的分布情况,蓝色虚线表示判别器判别概率的分布情况,绿色实线表示生成样本的分布。Z表示噪声,Z到x表示通过生成器之后的分布的映射情况。
我们的目标是使用生成样本分布(绿色实线)去拟合真实的样本分布(黑色虚线),来达到生成以假乱真样本的目的。
可以看到在(a)状态处于最初始的状态的时候,生成器生成的分布和真实分布区别较大,并且判别器判别出样本的概率不是很稳定,因此会先训练判别器来更好地分辨样本。
通过多次训练判别器来达到(b)样本状态,此时判别样本区分得非常显著和良好。然后再对生成器进行训练。
训练生成器之后达到(c)样本状态,此时生成器分布相比之前,逼近了真实样本分布。
经过多次反复训练迭代之后,最终希望能够达到(d)状态,生成样本分布拟合于真实样本分布,并且判别器分辨不出样本是生成的还是真实的(判别概率均为0.5)。也就是说我们这个时候就可以生成出非常真实的样本啦,目的达到。[2]
3.Experiments
包括MNIST, theTorontoFace Database (TFD),和CIFAR-10一系列数据集上训练了对抗网络。生成网络使用rectifier linear and sigmoid两种激活函数,而判别器使用maxout激活。应用dropout训练判别器网络。虽然我们的理论框架允许在生成器的中间层使用dropout和其他噪声,但我们只使用噪声作为生成器网络最底层的输入。
4.Advantages and disadvantages
与以前的建模框架相比,这个新框架有优点也有缺点。缺点主要是没有显式表示的pg (x),在训练时D必须与G同步。它的优点是不需要使用马尔科夫链,只使用backprop来获得梯度,在学习过程中不需要推理,可以将多种函数合并到模型中。
5.Conclusions and future work(idea)
- 将c作为G和D的输入,可以得到条件生成模型p(x | c)。
- 学习近似推理:可以利用一个辅助网络在给定x时来预测z。这与wake-sleep算法训练的推理网络类似,但具有在生成器网络完成训练后,可以对固定生成器网络进行推理网络训练的优点。
- 通过训练一系列共享参数的条件模型,可以近似地对所有条件p(xS | x)进行建模,其中s是x指标的子集。本质上,我们可以使用对抗网来实现确定性MP-DBM[11]的随机扩展。
- 半监督学习:当有限的标记数据可用时,鉴别器或推理器的特性可能会降低分类器的性能。
- 效率改进:在培训过程中,通过划分更好的方法来协调G和D,或者确定更好的z分布,可以大大加快训练的速度。
6. 网络训练源代码
读入自己的数据
from __future__ import print_function
from torch.utils.data import DataLoader
from torchvision import transforms
#%matplotlib inline
import argparse
import os
import torch
import torch.nn as nn
import torch.optim as optimizer
import torchvision
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.tensorboard import SummaryWriter
import matplotlib.animation as animation
from IPython.display import HTML
os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
dataroot = "cats/"
image_size = 64
nc = 3
un_pretreatment_dataset = torchvision.datasets.ImageFolder(root=dataroot, transform=transforms.Compose([transforms.Resize((200,200)),
transforms.ToTensor()]))
print("dataset[0] ", un_pretreatment_dataset[0])
print("dataset[0][0].shape ", un_pretreatment_dataset[0][0].shape)
un_pretreatment_dataloader = DataLoader(dataset=un_pretreatment_dataset, batch_size=b_size, shuffle=True)
write = SummaryWriter('GAN')
for batch_id, data in enumerate(un_pretreatment_dataloader):
batch_data, batch_label = data[0],data[1]
print("batch_label ",batch_label)
write.add_images('原始图片', batch_data, batch_id+1)
write.close()
# 数据预处理操作
pretreatment_op = transforms.Compose([
transforms.Resize((image_size, image_size)),
transforms.CenterCrop((image_size, image_size)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
])
dataset = torchvision.datasets.ImageFolder(root=dataroot,transform=pretreatment_op)
print("dataset[0] ", dataset[0])
print("dataset[0][0].shape ", dataset[0][0].shape)
dataloader = DataLoader(dataset=dataset, batch_size=b_size, shuffle=True)
real_batch = next(iter(dataloader))
#print(real_batch[0].shape) torch.Size([64, 3, 64, 64])
print(len(dataloader))
for batch_id, data in enumerate(dataloader):
batch_data, batch_label = data[0],data[1]
print("batch_label ",batch_label)
write.add_images('经过预处理的图片', batch_data, batch_id+1)
write.close()定义网络结构
# Generator Code
# 转置卷积常常被用于生成对抗网络(GANs)中的生成器部分,以逐步增大特征图的尺寸并生成最后的图像
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# torch.randn(b_size, nz, 1, 1, device=device)
# torch.randn(64, 100, 1, 1, device=device)
self.main = nn.Sequential(
# 64, 100, 1, 1
# output = (input - 1)*stride + output_padding(0) – 2*padding + kernel_size
# (1-1)*1+0-2*0+4 = 4,所以为 (64、ngf*8、4、4)
nn.ConvTranspose2d(in_channels=nz, out_channels=ngf * 8, kernel_size=4, stride=1, padding=0, bias=False),
nn.BatchNorm2d(ngf * 8),
nn.ReLU(True),
# (4-1)*2+0-1*2+4 = 6-2+4 = 8,所以为(64、ngf * 4、8、8)
nn.ConvTranspose2d(in_channels=ngf * 8, out_channels=ngf * 4, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
# (8-1)*2+0-1*2+4 = 16 所以为(64、ngf * 2、16、16)
nn.ConvTranspose2d(in_channels=ngf * 4, out_channels=ngf * 2, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
# (16-1)*2+0-1*2+4 = 32,所以为(64、ngf、32、32)
nn.ConvTranspose2d( ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
# (32-1)*2+0-1*2+4 = 64 所以为(64、nc、64、64)
nn.ConvTranspose2d( ngf, nc, 4, 2, 1, bias=False),
nn.Tanh()
# state size. (nc) x 64 x 64
)
def forward(self, input):
return self.main(input)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.main = nn.Sequential(
# 卷积神经网络组合一般组合为 卷积+激活函数(relu)+池化
# newH = (H-F+2p)/S newW = (W-F+2p)/S
# 输入为 64 个 3*64*64的图片 经过 (64-4+2*1)/2+1=32 计算得到 64个 64*32*32的图片
nn.Conv2d(in_channels=nc, out_channels=ndf, kernel_size=4, stride=2, padding=1, bias=False),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
# 输入为64个 64*32*32的图片 经过 (32-4+2*1)/2+1=16 计算得到 64个 64*2*16*16的图片 64*2是输出通道数
nn.Conv2d(in_channels=ndf, out_channels=ndf * 2, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ndf * 2),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
# 64个 64*2*16*16的图片 64*2是通道数 经过 (16-4+2*1)/2+1 = 8 计算得到 64个 64*4*8*8的图片 64*4是输出通道数
nn.Conv2d(in_channels=ndf * 2, out_channels=ndf * 4, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ndf * 4),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
# 64个 64*4*8*8的图片 64*4是通道数 经过 (8-4+2*1)/2+1 = 4 计算得到 64个 64*8*4*4的图片 64*8是输出通道数
nn.Conv2d(in_channels=ndf * 4, out_channels=ndf * 8, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ndf * 8),
nn.LeakyReLU(negative_slope=0.2, inplace=True),
# 64个 64*8*4*4的图片 64*8是通道数 经过 (4-4+2*0)/1+1 = 1 计算得到 64个 1*1*1的图片 1是输出通道数
nn.Conv2d(in_channels=ndf * 8, out_channels=1, kernel_size=4, stride=1, padding=0, bias=False),
# 最后将64个 1*1*1的图片经过Sigmod函数求每一个图片的概率
nn.Sigmoid()
)
def forward(self, input):
return self.main(input)
G = SummaryWriter("G")
D = SummaryWriter("D")
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
netG = Generator()
netG.to(device)
netD = Discriminator()
netD.to(device)
noise = torch.randn(b_size, nz, 1, 1).to(device)
G.add_graph(model=netG, input_to_model=noise)
data_input = torch.randn(b_size,3,image_size,image_size).to(device)
D.add_graph(model=netD, input_to_model=data_input)
write.close()训练过程
criterion = nn.BCELoss().to(device)
fixed_noise = torch.randn(64, nz, 1, 1).to(device)
real_label = 1.0
fake_label = 0.0
optimizerD = optimizer.Adam(netD.parameters(), lr=lr, betas=(beta1, 0.999))
optimizerG = optimizer.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
img_list = []
G_losses = []
D_losses = []
step = 0
print("Starting Training Loop...")
num_epochs = 200
write = SummaryWriter("GAN")
for epoch in range(num_epochs):
import time
start = time.time()
for batch_id, data in enumerate(dataloader, 0):
############################
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z)))
###########################
####################判别器学习真实数据####################
real_data = data[0].to(device)
b_size = real_data.size(0)
label = torch.full((b_size,), real_label).to(device)
output = netD(real_data)
output = output.view(-1)
realLoss = criterion(output, label)
realLoss.backward()
####################判别器识别噪声数据####################
noise = torch.randn(b_size, nz, 1, 1).to(device)
fake = netG(noise)
label.fill_(fake_label)
output = netD(fake.detach())
output = output.view(-1)
fakeLoss = criterion(output, label)
fakeLoss.backward()
dLoss = realLoss + fakeLoss
optimizerD.step()
optimizerD.zero_grad()
############################
# (2) Update G network: maximize log(D(G(z)))
###########################
label.fill_(real_label).to(device)
output = netD(fake).view(-1)
gLoss = criterion(output, label)
gLoss.backward()
optimizerG.step()
optimizerG.zero_grad()
G_losses.append(gLoss.item())
D_losses.append(dLoss.item())
if batch_id % 50 == 0:
print("当前第 {} 次训练===============判别器的 Loss: {}===============生成器的 Loss: {}".format(step+1, dLoss.item(), gLoss.item()))
if (step % 20 == 0) or ((epoch == num_epochs-1) and (batch_id == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(torchvision.utils.make_grid(fake, padding=2, normalize=True))
i = torchvision.utils.make_grid(fake, padding=2, normalize=True)
fig = plt.figure(figsize=(8, 8))
plt.imshow(np.transpose(i, (1, 2, 0)))
plt.axis('off') # 关闭坐标轴
if not os.path.exists('out'):
os.mkdir("./out")
plt.savefig("out/%d_%d.png" % (epoch, step))
plt.close(fig)
step += 1
print(f'总用时{time}:', time.time() - start)训练200个epochs的Loss对比

训练200个epochs的生成图与原图对比
# Grab a batch of real images from the dataloader
# real_batch = next(iter(dataloader))
# Plot the real images
plt.figure(figsize=(15,15))
plt.subplot(1,2,1)
plt.axis("off")
plt.title("Real Images")
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=5, normalize=True).cpu(),(1,2,0)))
# Plot the fake images from the last epoch
plt.subplot(1,2,2)
plt.axis("off")
plt.title("Fake Images")
plt.imshow(np.transpose(img_list[-1],(1,2,0)))
plt.show()
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











