







个人环境:win10
Package:Python 3.8.12
torch 1.11.0+cu113
torchvision 0.12.0+cu113
tensorboard 2.8.0
一、目标:
1.实验对象:选取数据集 CIFAR10
2.目标网络:搭建分类网络
3.操作流程:准备数据,加载数据,准备模型,设置损失函数,设置优化器,开始训练,最后验证,结果聚合展示。
二、分析
1.数据集:
Cifar-10是由Hinton的两个大弟子Alex Krizhevsky、Ilya Sutskever收集的一个用于普适物体识别的数据集。Cifar是加拿大政府牵头投资的一个先进科学项目研究所。
Cifar-10由60000张32*32的RGB彩色图片构成,共10个分类。50000张训练,10000张测试(交叉验证)。这个数据集最大的特点在于将识别迁移到了普适物体,而且应用于多分类(姊妹数据集Cifar-100达到100类,ILSVRC比赛则是1000类)。
2.该分类网络模型如图:
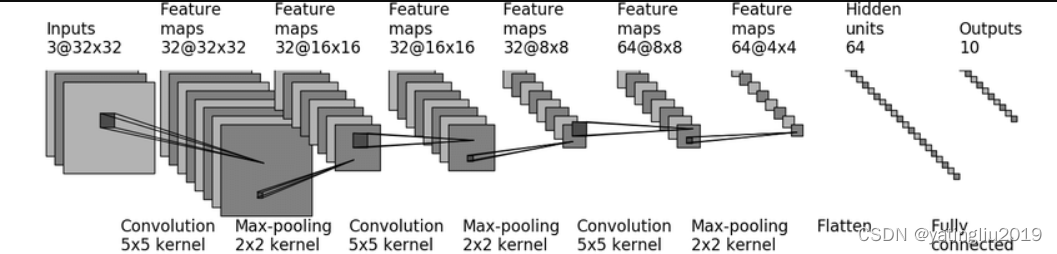
输入内容先通过卷积层1Conv2d(input_channel3=3, output_channel3=32, kernel_size=5, stride=1, padding=2)->最大池化层1MaxPool2d(2)->卷积层2Conv2d(32, 32, 5, 1, 2)->最大池化层2MaxPool2d(2)->卷积层3Conv2d(32, 64, 5, 1, 2)->最大池化层3MaxPool2d(2)->展平层Flatten()->线性化Linear(64*4*4, 64)->线性化Linear(64, 10)
三、训练代码
1.准备测试集和训练集数据 :使用 Dataset 和DataLoader
#准备数据集 训练数据 + 测试数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10("../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)2.确定两个数据集的大小 len() 并打印
#数据集的长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# train_data_size->数据集的长度
print("训练数据集的长度是: {}".format(train_data_size))
print("测试数据集的长度是: {}".format(test_data_size))3.利用DataLoader加载两个数据集
#利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)4.建立神经网络模型
# 因为数据集是有10种类别,所以必须要搭建一个十分类的网络
#创建网络模型
class N(nn.Module):
def __init__(self):
super(N, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
NN = N()5.损失函数
# 因为是分类问题,所以选择用交叉熵
#损失函数
# 因为是分类问题,所以选择用交叉熵
loss_fn = nn.CrossEntropyLoss()6.优化器
#优化器
learning_rate = 1e-2#=1 x 10 ^ (-2) = 0.01
optimizer = torch.optim.SGD(NN.parameters(), lr=learning_rate)7.设置训练网络参数
# 包含训练次数、测试次数和训练轮数
#设置训练网络参数
# 训练次数
total_train_step = 0
# 测试次数
total_test_step = 0
# 训练轮数
epoch = 108.添加tensorboard
#添加tensorboard
writer = SummaryWriter("../logs_model")9.开始重复训练
9.1 训练部分
# 注意损失函数的backward的优化
NN.train()#把网络设置成训练模式(不必要,.eval()一样,对Dropout和BatchNorm层有用
#开始训练
for data in train_dataloader:
imgs, targets = data
output = NN(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数 {}, LOSS = {}".format(total_train_step, loss.item())) #.item()->把tensor型转化成真实数字
writer.add_scalar("train_loss", loss.item(), total_train_step)9.2 开始测试
# 注意计算正确率的算法还有损失的统计方法
#开始测试
NN.eval()#不必要
total_test_loss = 0
# 计算整体正确的个数
total_accuracy = 0
#调试的时候不需要带梯度来优化
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = NN(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss = {}".format(total_test_loss))
print("整体测试集上的正确率 = {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", loss.item(), total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 19.3保存每一轮训练的结果
# 注意保存模型的命名区分
#保存每一轮训练的结果
torch.save(NN, "NN_{}.pth".format(i))
#torch.save(NN.state_dict(), "NN_{}.pth".format(i))
print("-----模型已保存------")10.结果展示
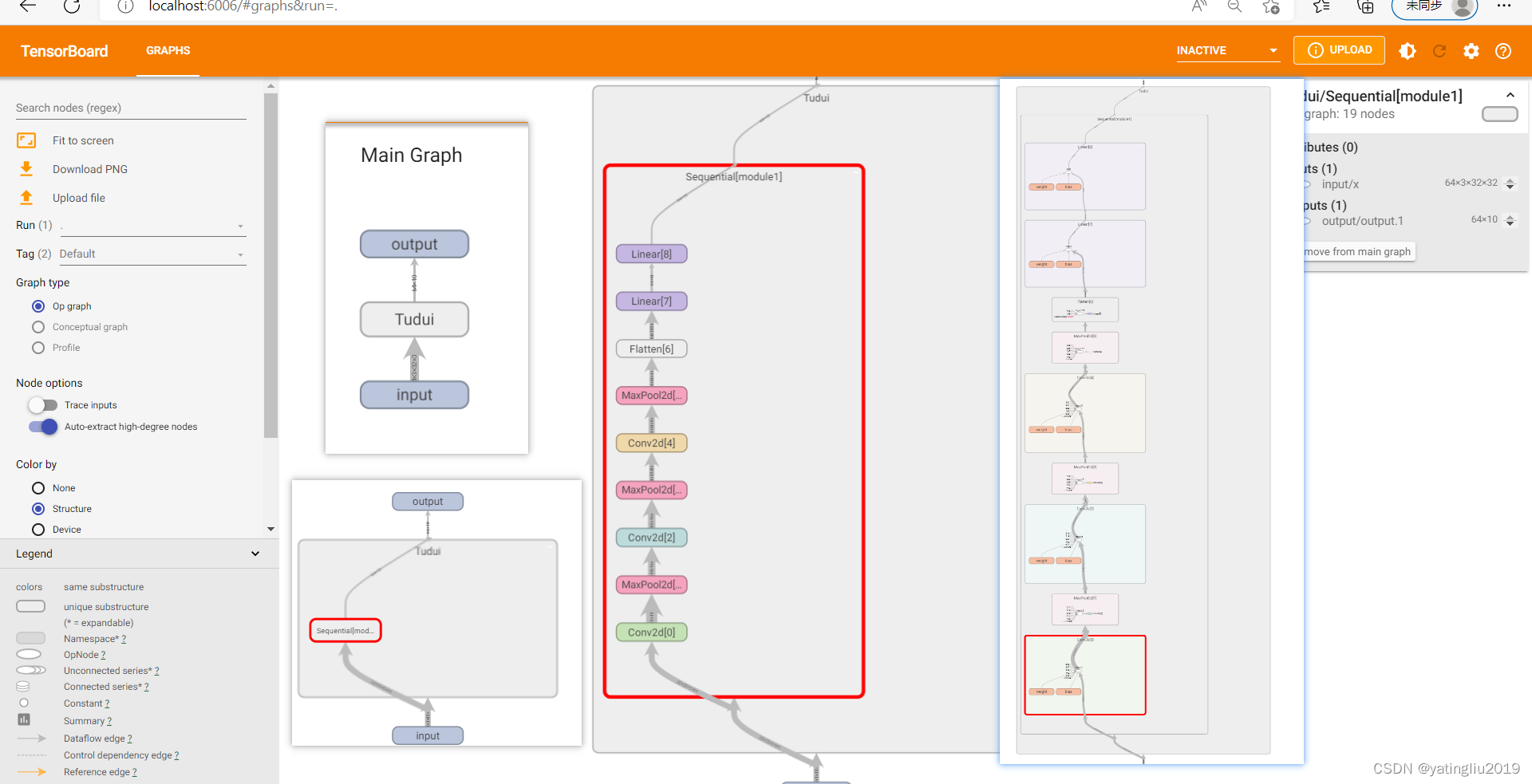
10.1网络模型 tensorboard展示
10.2训练结果的正确率
# 重复训练了30次后,正确率稳定在64%左右

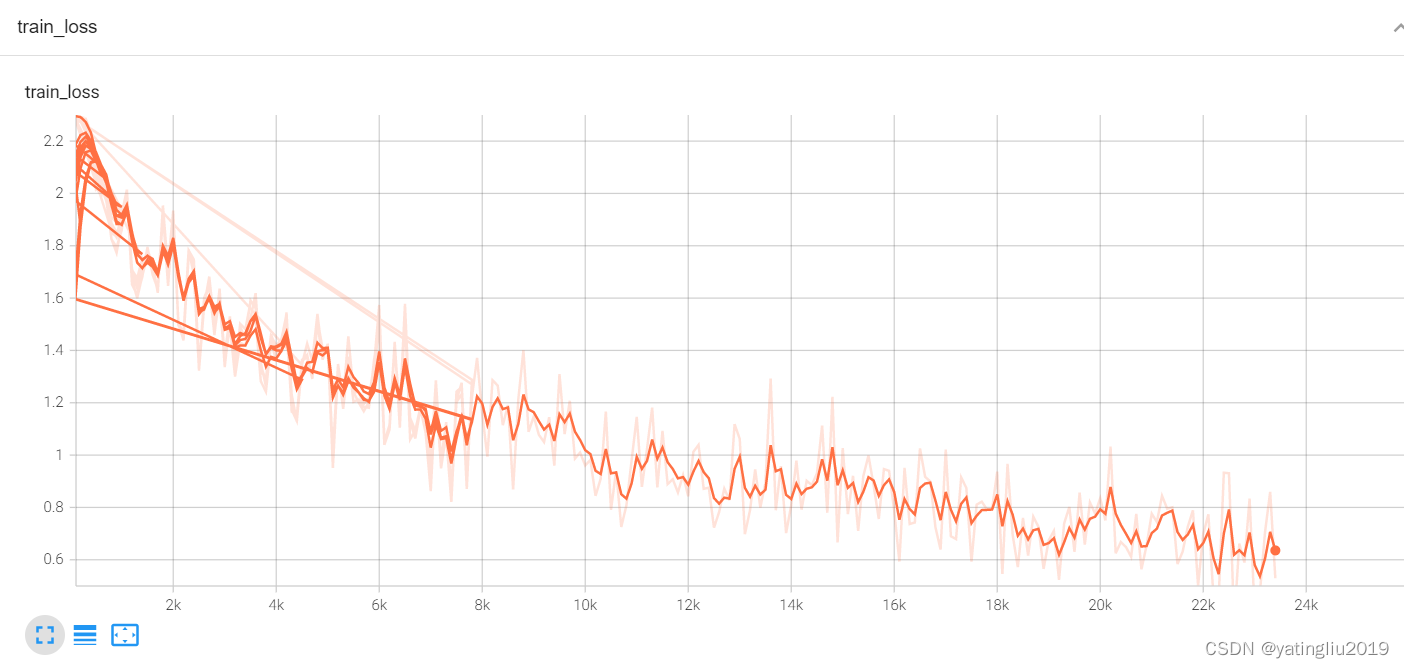
10.3train_loss
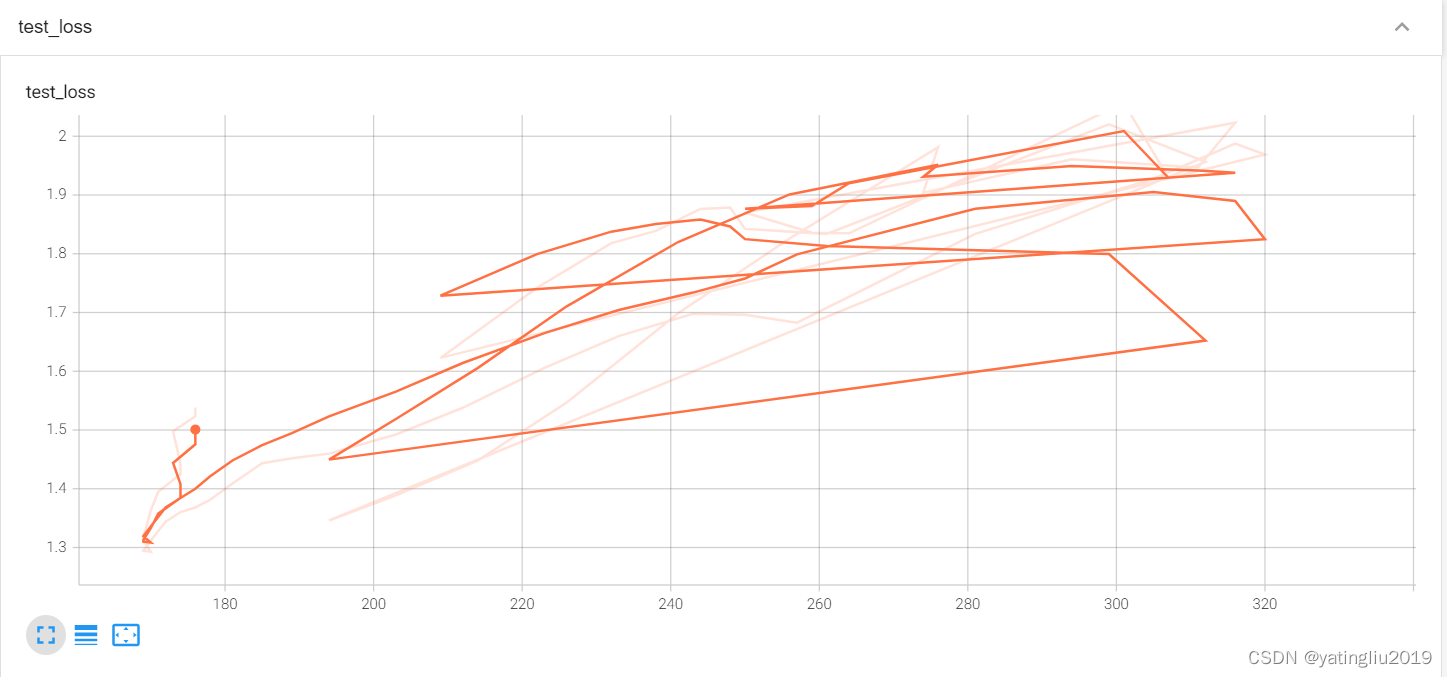
10.4test_loss
四、测试
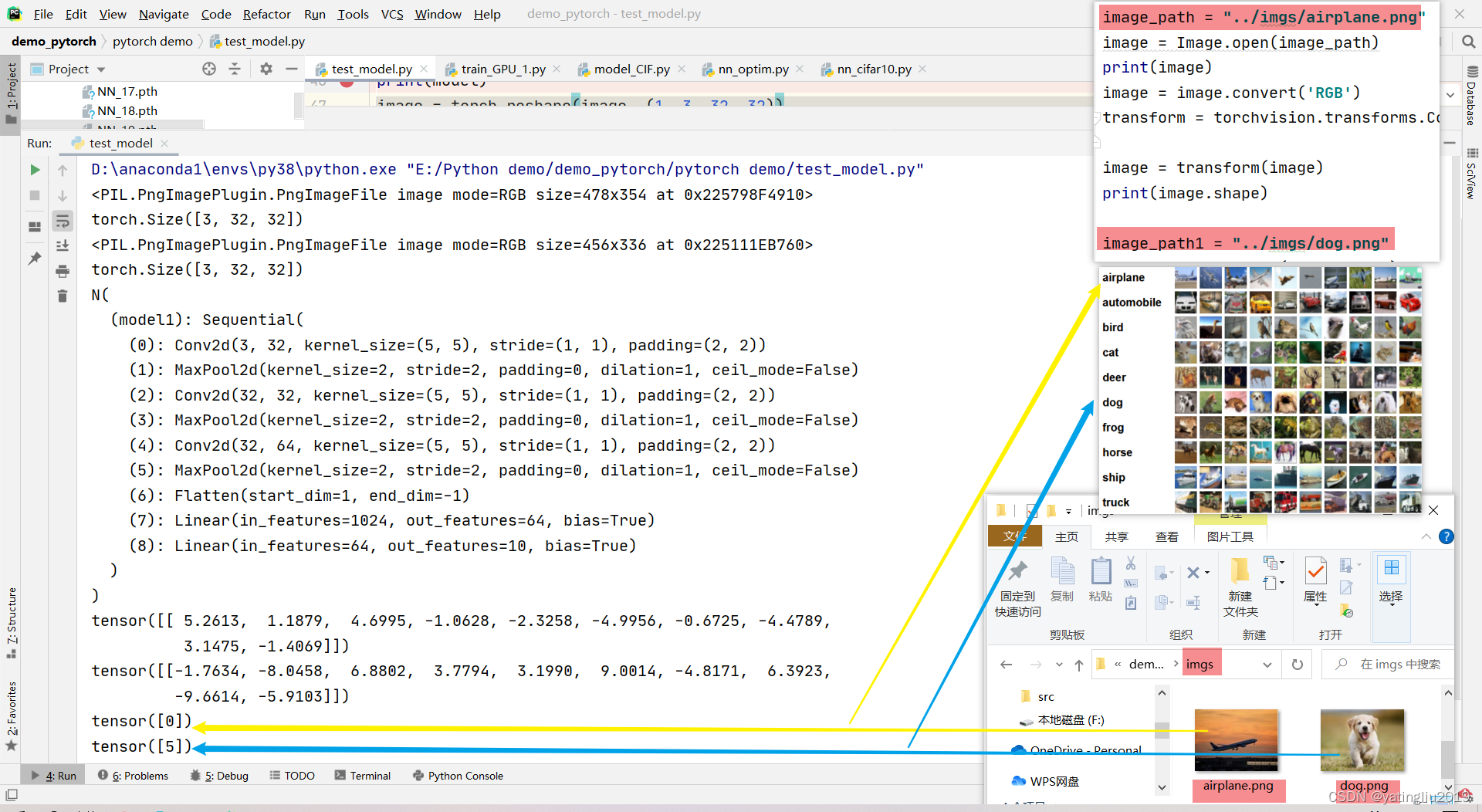
1.利用 Image 读取图片
# 注意这里读取的照片是.png格式的,所以这里需要先转换为RGB,原因是如果不使用.convert(‘RGB’)进行转换的话,读出来的图像是RGBA四通道的。A通道为透明通道,该对深度学习模型训练来说暂时用不到,因此使用convert(‘RGB’)进行通道转换。同时还需要转换成transforms格式
image_path = "../imgs/airplane.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)2.测试部分代码
# 注意我是使用GPU环境进行训练得到的模型,现在在cpu环境运行,需要转换一下device;同时这里可以带上model.eval()激活一下;这里最好使用不带梯度的来计算模型的输出
model = torch.load("NN_9.pth", map_location=torch.device('cpu'))#我现在在cpu环境,但是我的模型是用cuda,所以模型加载的环境用map_location
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))3.结果
# 测试了网络图片:飞机和小狗,分类均正确
五、完整代码:
1.训练模型和保存模型(GPU版本)
#CIFAR10分类模型
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
import time
# from model_CIF import *
#准备数据集 训练数据 + 测试数据集
from torch import nn
from torch.utils.data import DataLoader
train_data = torchvision.datasets.CIFAR10("../data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
#数据集的长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# train_data_size->数据集的长度
print("训练数据集的长度是: {}".format(train_data_size))
print("测试数据集的长度是: {}".format(test_data_size))
print()
#利用DataLoader加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
#因为数据集是有10种类别,所以必须要搭建一个十分类的网络
#搭建神经网络 在model_CIF.py中
#创建网络模型
class N(nn.Module):
def __init__(self):
super(N, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
NN = N()
if torch.cuda.is_available():
NN = NN.cuda()
#损失函数
# 因为是分类问题,所以选择用交叉熵
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():
loss_fn = loss_fn.cuda()
#优化器
learning_rate = 1e-2#=1 x 10 ^ (-2) = 0.01
optimizer = torch.optim.SGD(NN.parameters(), lr=learning_rate)
#设置训练网络参数
# 训练次数
total_train_step = 0
# 测试次数
total_test_step = 0
# 训练轮数
epoch = 30
#添加tensorboard
writer = SummaryWriter("../logs_model")
#开始计时
start_time = time.time()
#重复训练过程
for i in range(epoch):
print("-----第 {} 轮训练开始-----".format(i+1))
NN.train()#把网络设置成训练模式(不必要,.eval()一样,对Dropout和BatchNorm层有用
#开始训练
for data in train_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
output = NN(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
end_time = time.time()
print("第 {} 次训练用时 : {}".format(total_train_step, end_time-start_time))
print("LOSS = {}".format(loss.item())) #.item()->把tensor型转化成真实数字
writer.add_scalar("train_loss", loss.item(), total_train_step)
#开始测试
NN.eval()#不必要
total_test_loss = 0
# 计算整体正确的个数
total_accuracy = 0
#调试的时候不需要带梯度来优化
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
if torch.cuda.is_available():
imgs = imgs.cuda()
targets = targets.cuda()
outputs = NN(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy
print("整体测试集上的loss = {}".format(total_test_loss))
print("整体测试集上的正确率 = {}".format(total_accuracy/test_data_size))
writer.add_scalar("test_loss", loss.item(), total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
total_test_step = total_test_step + 1
#保存每一轮训练的结果
torch.save(NN, "NN_{}.pth".format(i))
#torch.save(NN.state_dict(), "NN_{}.pth".format(i))
print("-----模型已保存------")
writer.close()2.测试效果和检测照片
import torch
import torchvision
from PIL import Image
from torch import nn
image_path = "../imgs/airplane.png"
image = Image.open(image_path)
print(image)
image = image.convert('RGB')
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
print(image.shape)
class N(nn.Module):
def __init__(self):
super(N, self).__init__()
self.model1 = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10)
)
def forward(self,x):
x = self.model1(x)
return x
model = torch.load("tudui_29_gpu.pth", map_location=torch.device('cpu'))
print(model)
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1)) 

airplane.png dog.png

















 216
216











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











