






一、卷积神经网络
卷积神经网络(Convolutional Neural Network,简称CNN)是一种深度学习模型,特别适用于处理具有网格结构的数据,如图像、视频和声音等。它的设计灵感来源于生物视觉系统,能够通过学习数据中的空间特征来进行高效的特征提取和识别任务。以下是CNN的一些关键组件和概念:
-
卷积层(Convolutional Layer):这是CNN的核心部分,使用一组可学习的滤波器(或称卷积核)在输入数据上滑动,执行元素级的乘积并求和操作,从而检测局部特征。每个滤波器都会生成一个特征图(Feature Map),显示输入数据中与该滤波器匹配的特征。
-
池化层(Pooling Layer):用于下采样,减少数据的空间尺寸,降低计算复杂度,同时保持重要特征。常见的池化方式有最大池化(Max Pooling)、平均池化(Average Pooling)等。
-
激活函数(Activation Function):如ReLU(Rectified Linear Unit)、sigmoid、tanh等,用于引入非线性,使得网络能够学习更复杂的模式。
-
全连接层(Fully Connected Layer):通常位于CNN的尾部,用于将学到的特征进行分类或其他高级任务。在全连接层中,每个神经元与前一层的所有神经元相连。
-
权重共享与局部连接:卷积层中的滤波器在输入数据的整个宽度和高度上共享相同的权重,减少了参数数量,同时允许网络学习到平移不变性(即图像中的对象即使位置稍有变化,也能被正确识别)。
CNN广泛应用于图像分类、物体识别、图像分割、人脸识别等领域,并且在许多挑战赛中取得了显著成果,如ImageNet大规模视觉识别挑战赛(ILSVRC)。由于其强大的特征提取能力,CNN也被成功地应用于自然语言处理和其他序列数据分析任务中,通过一维卷积等技术进行调整。
二、常用激活函数
- 激活函数的作用:引入非线性因素,使其具备解决非线性问题的能力。
- ReLU激活函数:
f ( x ) = max ( 0 , x ) \begin{align} f(x) = \max(0, x)\tag{1} \end{align} f(x)=max(0,x)(1)
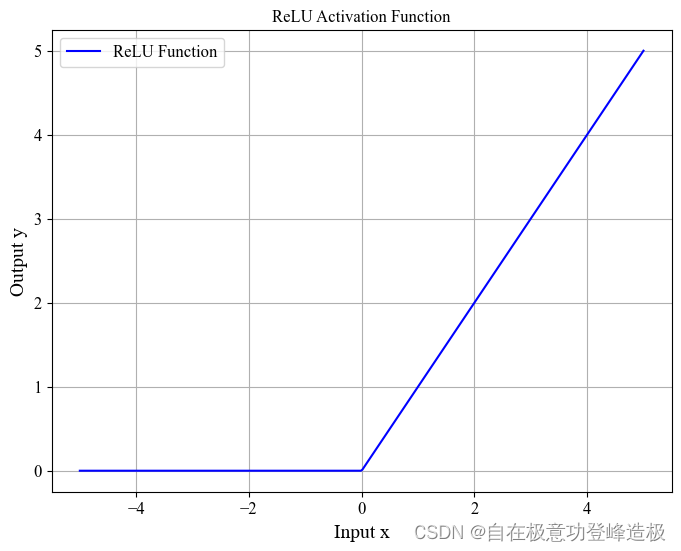
- 优点: ReLU是目前深度学习中最常用的激活函数之一,其主要优点在于计算效率高。由于其在正数区域的导数为常数1,这不仅简化了反向传播过程中的计算,还有效缓解了梯度消失问题,使得深层神经网络的训练变得更加高效。此外,ReLU能够使一部分神经元处于不活跃状态(对于负输入),有助于稀疏化表示,减少模型复杂度。
- 缺点:尽管ReLU有诸多优点,但它存在“死亡ReLU”(Dead ReLU)问题,即当输入为负且其绝对值较大时,该单元的输出恒为0,且其导数也为0,这会导致在训练过程中这些神经元不再被更新,从而影响模型的学习能力。选择合适的初始化方法和使用如Leaky ReLU、Parametric ReLU等变体可以缓解这一问题。
- Sigmoid激活函数:
f ( x ) = 1 1 + e − x \begin{align} f(x) = \frac{1}{1 + e^{-x}}\tag{2} \end{align} f(x)=1+e−x1(2)
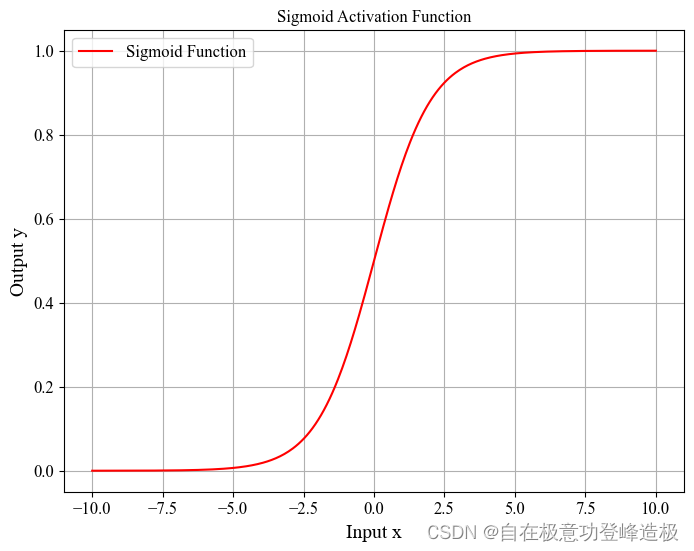
- 优点: Sigmoid函数具有平滑性和连续性的特性,其输出范围为(0,1),这使得它天然适合处理二分类问题,可以直接作为概率输出。此外,Sigmoid函数的输出具有饱和性,使得它在早期的神经网络中被广泛用于增加网络的非线性表达能力。
- 缺点:Sigmoid函数的主要缺点是其梯度消失问题,特别是在函数输出接近两端(0或1)的饱和区时,梯度非常小,这在深层网络中会导致梯度消失,影响训练的收敛速度。此外,Sigmoid函数的输出不是以零为中心的,这可能会导致在训练过程中权重更新时出现梯度爆炸或消失的问题。与ReLU相比,Sigmoid函数的计算也更为昂贵,因为它涉及指数运算。
三、卷积层
- 卷积的目的是进行图像特征的提取
- 卷积特性:
- 拥有局部感知机制
- 进行卷积操作时是以一个滑动窗口的形式进行滑动计算。
- 权重共享
- 在滑动计算时,卷积核的值是不会发生变化的。
- 权重共享有利于减少参数量。
- 拥有局部感知机制
下图简单展示了卷积神经网络(CNN)中的卷积操作(不考虑偏置):

在这个例子中,我们有三个输入特征矩阵(R、G和B),每个都是3x3的矩阵,代表图像的红绿蓝三原色通道;对应不同的颜色通道,我们有三个卷积核,每个都是2x2的矩阵。
在卷积过程中,这些输入特征矩阵分别与其对应的2x2的卷积核进行运算。卷积核是一个小的权重矩阵,它滑过输入特征矩阵,并对每个重叠部分执行乘法运算,然后将结果相加得到一个新的数值。这个过程会生成一个新的特征矩阵,其中包含了原始数据经过卷积核处理后的信息。
具体来说,在这个例子中:
- 对于红色通道(R),卷积核与输入特征矩阵对应位置相乘后求和的结果为1。
- 对于绿色通道(G),卷积核与输入特征矩阵对应位置相乘后求和的结果为1。
- 对于蓝色通道(B),卷积核与输入特征矩阵对应位置相乘后求和的结果为0。
这三个新的特征值1, 1, 0相加得到2,作为输出特征矩阵左上部分的值,其它三部分计算类似,最终被组合成一个新的2x2的输出特征矩阵。
通过以上的卷积操作可以得出以下两个规律:
- 卷积核的通道(channel)与输入特征层的通道(channel)相同。
- 输出的特征矩阵通道(channel)与卷积核个数相同。
补充思考:
- 加上偏移量bias该如何计算?

- 加上激活函数该如何计算?:直接施加激活函数即可
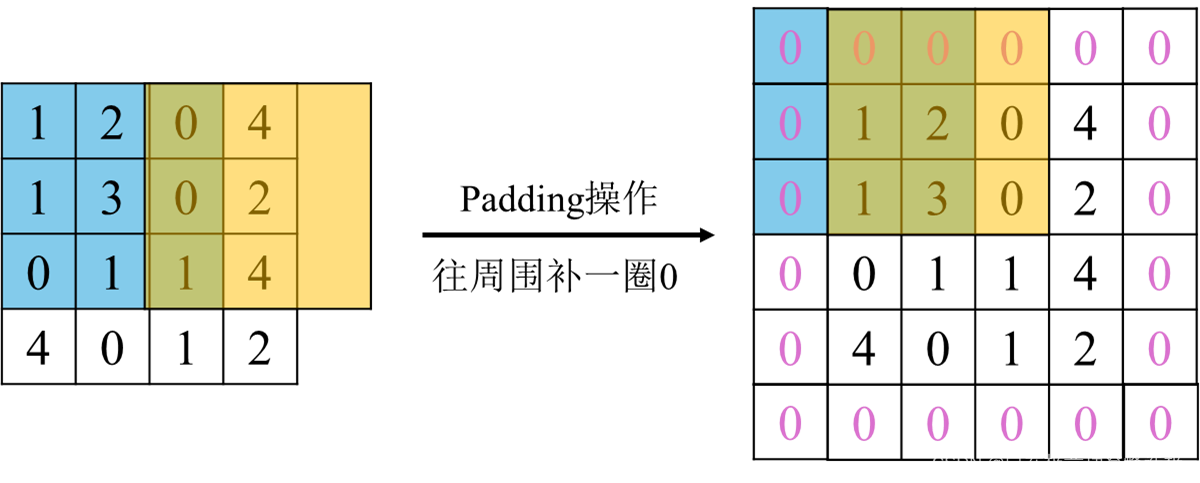
- 如果卷积过程中出现越界的情况该怎么办? :Padding操作
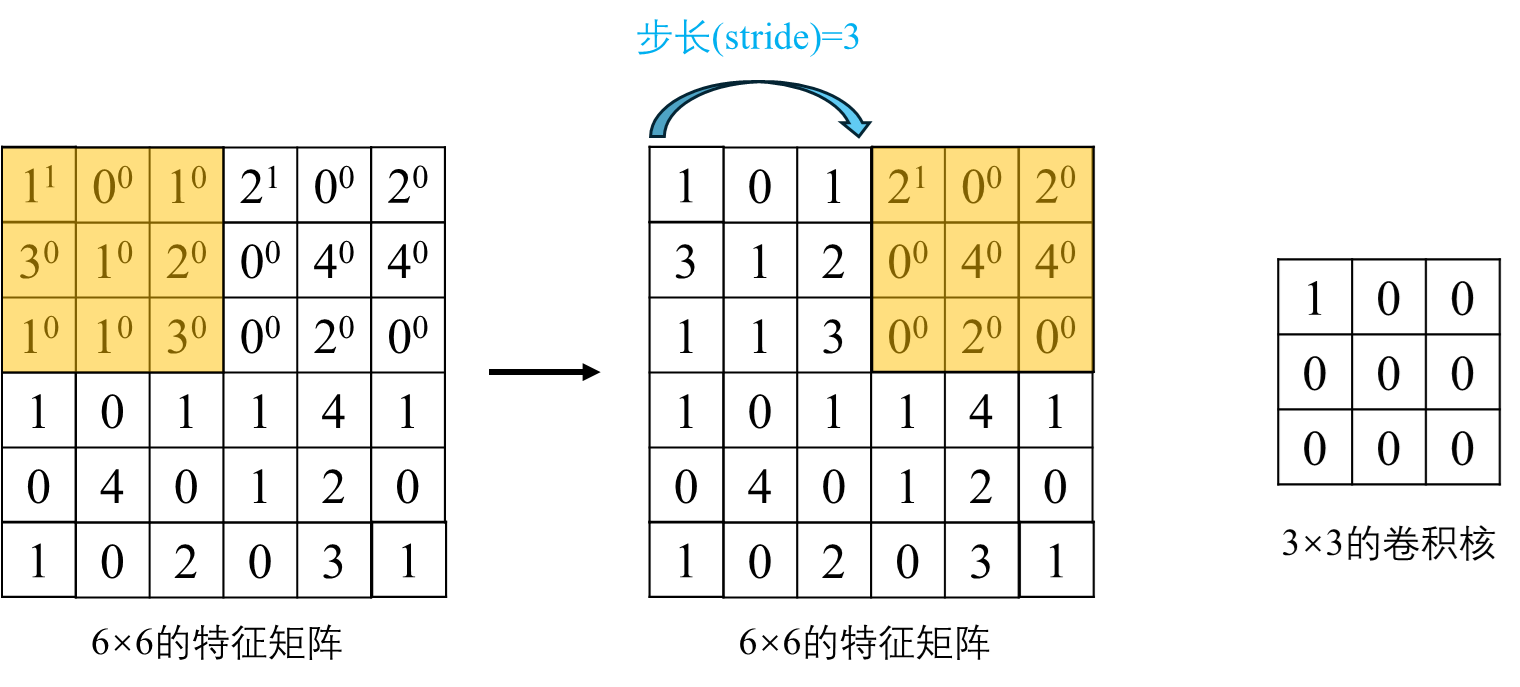
- 步长 s
步长(Stride)是卷积神经网络(CNN)中卷积层的一个重要参数,它指定了卷积核(filter)在输入数据(通常是图像或前一层的特征图)上滑动时的跳跃距离。换句话说,步长决定了每次卷积操作后卷积核移动多少像素。具体来说,如果步长为1,卷积核会在输入数据上逐像素移动,覆盖每一个位置;若步长为2,则卷积核每次跳过一个像素移动,这样可以更快地遍历输入数据,但同时也减少了输出特征图的空间分辨率。更大的步长可以减少计算量,加速网络运算,但可能损失部分空间信息。相反,较小的步长能够更细致地捕捉输入数据的特征,但会增加计算负担和内存使用。步长不仅影响特征图的尺寸,还间接影响模型的的感受野(receptive field,即网络能“看到”的输入数据区域大小)、参数数量以及模型的复杂度。以下为步长为3进行卷积操作的示例:
总结
在卷积操作过程中,矩阵经卷积操作后的尺寸由以下几个因素决定:
- 输入图片大小 W × W
- 卷积核(Filter)大小 F × F
- 步长 S
- Padding操作的像素数 P
则经卷积后的矩阵尺寸大小计算公式为:
输出尺寸
=
W
+
2
×
P
−
F
S
+
1
(3)
\text{输出尺寸} = \frac{\text{W} + 2 \times \text{P} - \text{F}}{\text{S}} + 1\tag{3}
输出尺寸=SW+2×P−F+1(3)
或
输出尺寸
=
输入尺寸
+
2
×
填充
−
卷积核尺寸
步幅
+
1
(4)
\text{输出尺寸} = \frac{\text{输入尺寸} + 2 \times \text{填充} - \text{卷积核尺寸}}{\text{步幅}} + 1\tag{4}
输出尺寸=步幅输入尺寸+2×填充−卷积核尺寸+1(4)
四、池化层
- 池化层的目的是对特征图进行稀疏处理,减少数据运算量
- 没有训练参数
- 只改变特征矩阵的W和H,不改变channel
- 一般Poolsize和stride相同
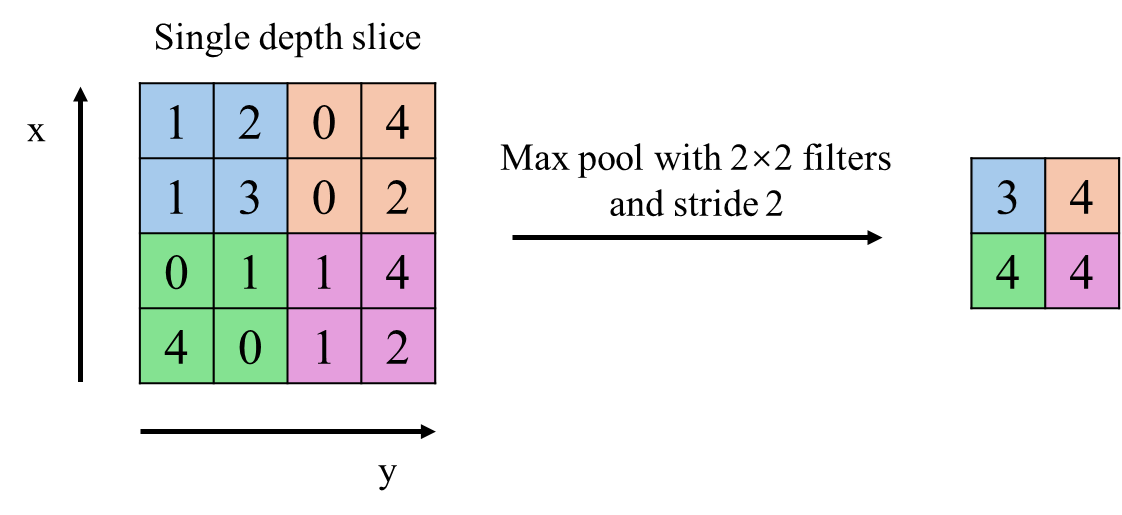
- MaxPooling下采样层
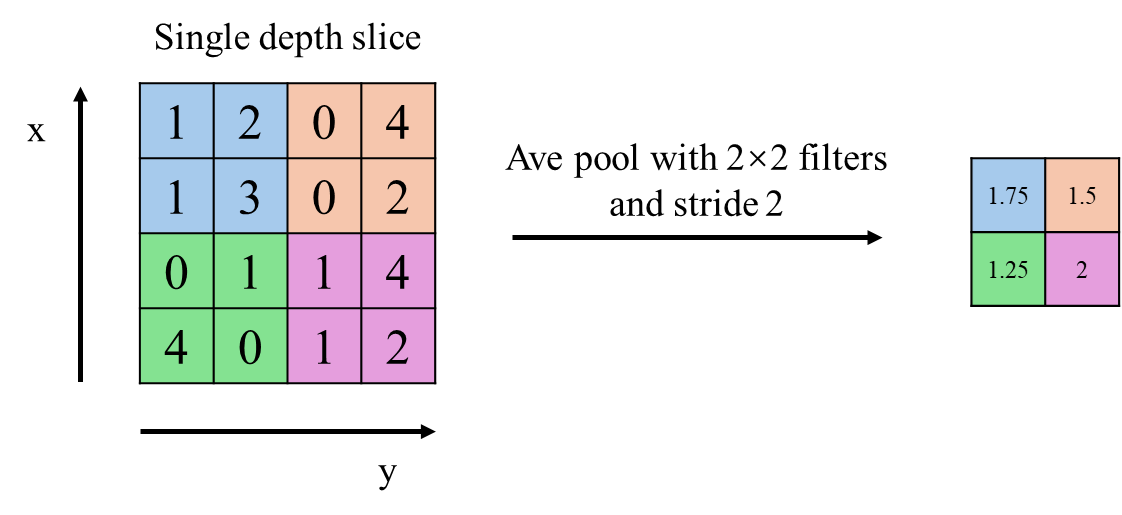
- AveragePooling下采样层
五、全连接层
- 全连接层是神经网络中的一个层,其中每个神经元与前一层的所有神经元相连,通过对前层信息进行加权求和并应用激活函数,实现特征的综合与非线性变换,常作为模型的输出层进行最终的分类或回归任务,虽参数量大,但具有强大的特征整合与表达能力。
- 深度神经网络的最后一层往往是全连接层+Softmax(分类网络),如下图所示:
图片来自StackExchange
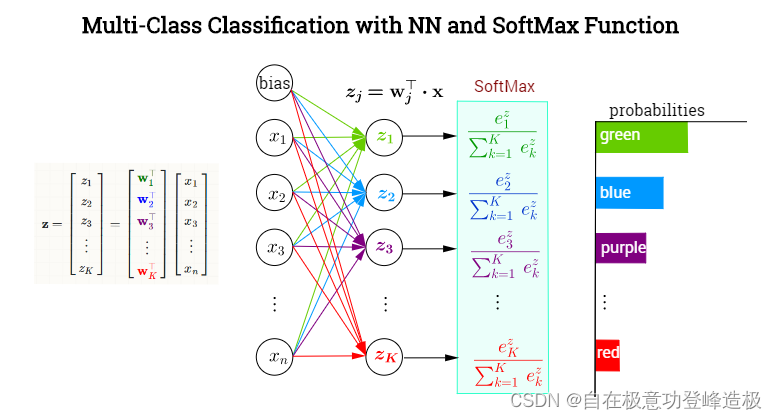
上图的计算方式:全连接层将权重矩阵与输入向量相乘再加上偏置,将
n
n
n个
(
−
∞
,
+
∞
)
(-∞,+∞)
(−∞,+∞)的实数映射为
K
K
K个
(
−
∞
,
+
∞
)
(-∞,+∞)
(−∞,+∞)的实数(分数);Softmax将
K
K
K个
(
−
∞
,
+
∞
)
(-∞,+∞)
(−∞,+∞)的实数映射为
K
K
K个
(
0
,
1
)
(0,1)
(0,1)的实数(概率),同时保证它们之和为1。具体如下:
y
^
=
softmax
(
z
)
=
softmax
(
W
T
x
+
b
)
(5)
\hat{\mathbf{y}}=\operatorname{softmax}(\mathrm{z})=\operatorname{softmax}\left(\mathrm{W}^{T} \mathrm{x}+\mathrm{b}\right)\tag{5}
y^=softmax(z)=softmax(WTx+b)(5)
其中,
x
x
x为全连接层的输入,
W
n
×
K
W_{n\times K}
Wn×K为权重,
b
b
b为偏置项,
y
^
\hat{\mathbf{y}}
y^为Softmax输出的概率,Softmax的计算方式如下:
softmax
(
z
j
)
=
e
z
j
∑
K
e
z
j
(6)
\operatorname{softmax}\left(z_{j}\right)=\frac{e^{z_{j}}}{\sum_{K} e^{z_{j}}}\tag{6}
softmax(zj)=∑Kezjezj(6)
若拆成每个类的概率如下:
y
j
^
=
softmax
(
z
i
)
=
softmax
(
W
j
⋅
x
+
b
j
)
(7)
\hat{\mathbf{y_j}}=\operatorname{softmax}(\mathrm{z_i})=\operatorname{softmax}\left(\mathrm{W_j}\cdot \mathrm{x}+\mathrm{b_j}\right)\tag{7}
yj^=softmax(zi)=softmax(Wj⋅x+bj)(7)
其中,
W
j
W_j
Wj为图中全连接层同一颜色权重组成的向量。















 1378
1378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









