






《Text-IF: Leveraging Semantic Text Guidance for Degradation-Aware and Interactive Image Fusion》
利用语义文本指导进行降级感知和交互式图像融合
一、摘要
图像融合的目的是将来自不同源图像的信息结合,以产生具有综合代表性的图像。现有的融合方法对低质量源图像的降质处理无能为力,且对多种主客观需求无交互性。为了解决这些问题,我们引入了一种新的方法,利用语义文本引导图像融合模型的降级感知和交互式图像融合任务,称为TextIF。它创新性地将经典的图像融合扩展到文本引导的图像融合,沿着能够协调地解决融合过程中的退化和交互问题。通过文本语义编码器和语义交互融合解码器,Text-IF实现了红外与可见光图像的一体化降质感知处理和交互式灵活融合结果。这样,Text-IF不仅实现了多模态图像融合,而且实现了多模态信息融合。大量的实验证明,本文提出的文本引导图像融合策略在图像融合性能和降质处理方面均优于SOTA方法。
二、现有图像融合方法存在的问题
1、缺乏自适应解决退化问题的能力
由于受环境条件的限制,原始采集的红外和可见光图像会出现退化,融合图像质量不高。可见光图像易受退化问题的影响,低光、过度曝光等。红外图像不可避免地受到噪声(包括热噪声、电子噪声和环境噪声)、对比度降低和其它相关效应的影响。现有的融合方法缺乏自适应地解决退化问题的能力,导致融合图像质量不高。此外,依靠人工预处理来增强图像存在灵活性和效率的问题[29]。
设计一个个性化退化模型来实现图像增强和融合是可行的。然而,大多数图像融合任务需要在各种复杂的条件下全天候执行。
如图1,这意味着需要多个图像恢复模型来满足要求,这需要频繁的模型切换,带来了巨大的消耗和麻烦。此外,分离方法存在实现增强和融合之间和谐的问题,导致整体性能不理想。
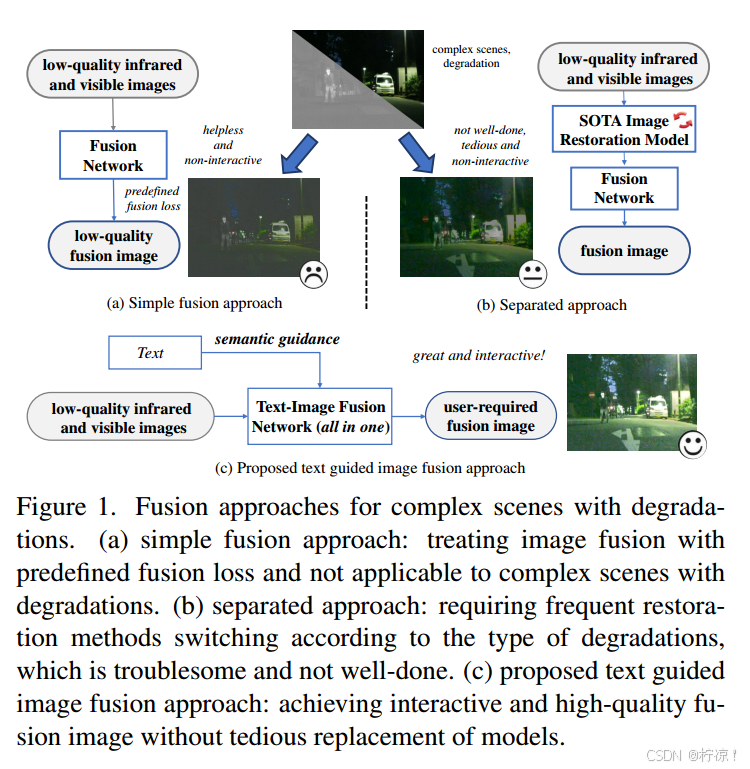
2、通常情况下的图像融合模型是非交互式的,不能满足复杂场景下用户的各种灵活要求
现实世界的图像融合是复杂、灵活和面向任务的。图像融合的要求可能会根据用户的主观需求和客观应用任务而变化。在所有场景中,如果该方法是非交互式的,并且产生相对固定的融合结果,则通常无法满足用户的各种灵活要求。
三、本文贡献
本文给出了一种利用语义文本指导进行退化感知和交互式图像融合的模型Text-IF,该算法将文本和图像融合融合在一起,满足了融合算法的和谐降维处理和交互性融合的需要。特别是,它允许文本提供灵活的语义指导以处理各种退化,这是一种多模态信息融合。一般来说,Text-IF包含图像流水线和文本交互引导架构,包括文本语义编码器和语义交互引导模块。在图像融合基准中,我们精心设计了基于Transformer的图像提取模块和交叉融合层,以实现高质量的融合。在文本语义编码器中,我们聚合了强大的预训练视觉语言模型的文本语义提取能力。通过语义交互引导模块,将文本的语义特征与图像融合特征耦合在一起,达到文本引导的图像融合的目的。它解决了现有图像融合方法难以适应复杂退化场景的融合,且只能输出相对固定的结果,缺乏交互性的问题。为后续的文本引导图像融合任务研究提供了一个可行的方向。
1、主要贡献:
(1)为了适应复杂的退化条件,解决了图像融合和退化软件处理的集成问题,突破了图像融合中质量提升的局限性。
(2)引入了一个语义交互引导模块来融合文本和图像的信息。该方法不仅实现了多模态图像融合,还实现了多模式信息融合。
(3)所提出的方法最终增加了定制融合结果的自由度。它提供了交互式融合,可以生成更灵活、高质量和用户所需的结果,而无需事先的专业知识或预定义的规则。
四、提出的方法
1、论文总体架构
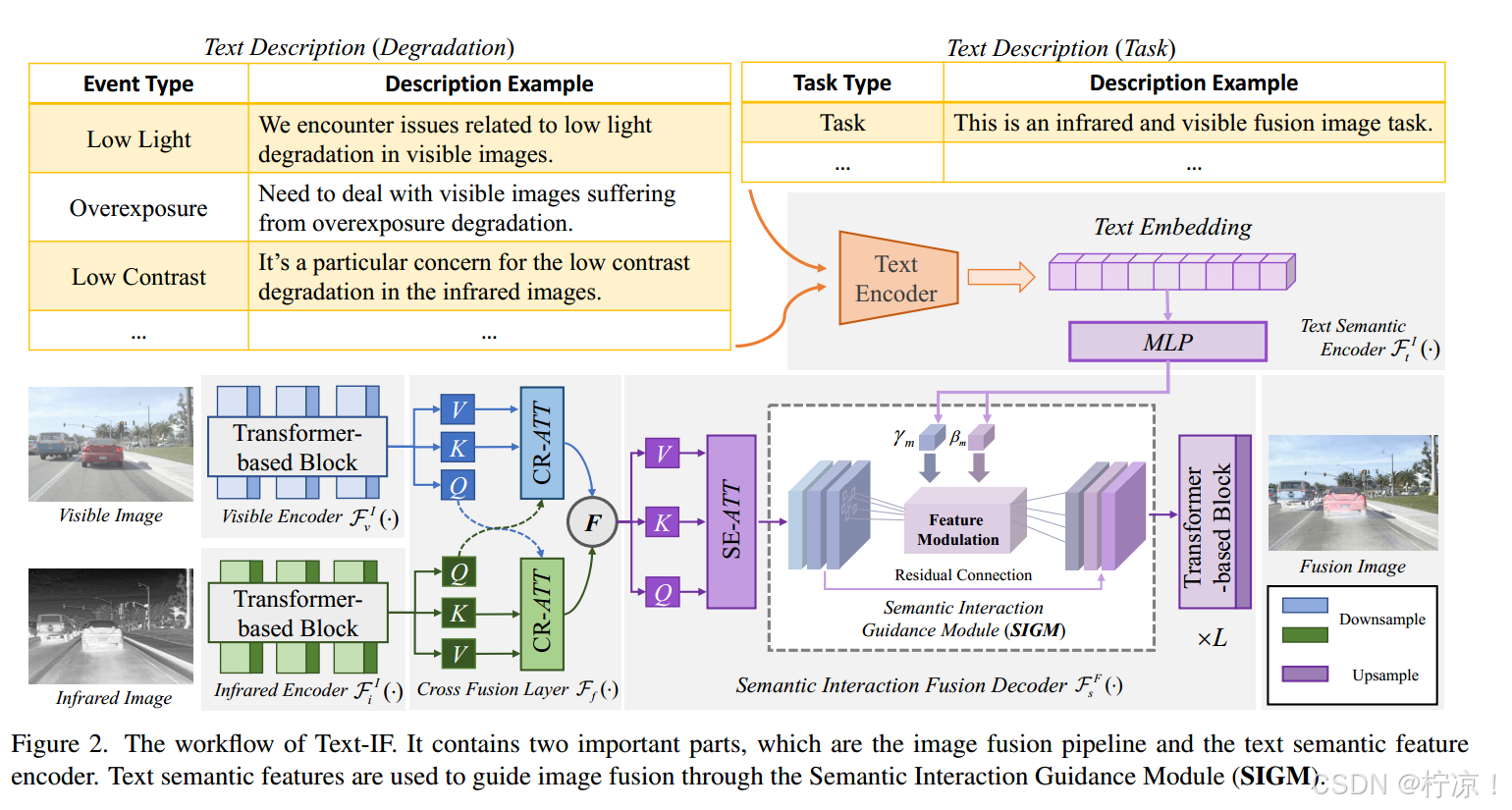
2、问题陈述
一般的图像融合方法将图像融合任务陈述为取两个源图像(例如,红外与可见光图像)作为输入,通过融合网络得到固定化图像融合结果(例如θn)。该网络被设计为学习对应于融合任务的映射预定义融合函数![]() 。简单地说,它可以被描述为:
。简单地说,它可以被描述为:
![]()
这意味着融合网络倾向于学习相对固定的融合策略。而且,在复杂的环境中,如源图像遭受退化,这种任务范式也是无能为力的。本文研究了利用文本信息进行图像融合的方法,以打破传统的单一融合结果沿着难以提高图像质量的缺陷,探索了一种新颖的文本引导的图像融合方法。由于引入了文本语义,该融合任务被重写为:
![]()
在文本语义信息引导下,将原点映射融合函数![]() 扩展为
扩展为![]() 。通过文本语义Ttext的交互,图像融合网络
。通过文本语义Ttext的交互,图像融合网络![]() 可以根据用户给定的文本,达到更加个性化和灵活的融合效果。同时,在面对各种源图像退化的情况下,还可以自由地进行图像的恢复和融合。
可以根据用户给定的文本,达到更加个性化和灵活的融合效果。同时,在面对各种源图像退化的情况下,还可以自由地进行图像的恢复和融合。
3、图像融合pipeline
(1)图像编码器
图像编码器分别将源可见光图像和红外图像作为输入。考虑到空间和深度信息提取,为了获得全面准确的表示,我们采用基于Transformer/Restormer[37]的块作为基本特征提取器。简单地说,可以表述如下:
![]()
其中![]() 和
和![]() 表示可见光和红外图像。H、W表示图像的高度和宽度。
表示可见光和红外图像。H、W表示图像的高度和宽度。![]() 和
和![]() 分别是可见光图像和红外图像编码器。
分别是可见光图像和红外图像编码器。
(2)交叉融合层
交叉融合层的目的是将来自不同模态的特征信息进行融合。为了综合集成各维度的特征,首次采用交叉注意(CR-ATT)技术对不同模态的特征进行交互。具体地说,它可以表示为:
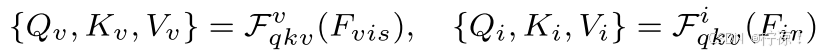
其中![]() 、
、![]() 表示来自可见光编码器和红外编码器的特征。随后,我们交换两种模态的查询Q以进行空间交互:
表示来自可见光编码器和红外编码器的特征。随后,我们交换两种模态的查询Q以进行空间交互:
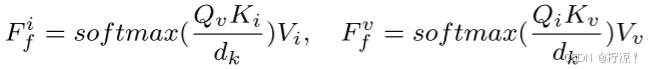
其中![]() 是缩放因子。最后,通过
是缩放因子。最后,通过![]() 将交叉注意力计算得到的结果进行拼接,得到融合特征。
将交叉注意力计算得到的结果进行拼接,得到融合特征。
(3)语义交互融合编码器
交叉融合层输出的特征首先通过自注意(SE-ATT)增强,即,![]() 。Qf、Kf和Vf是F0 f的Q、K和V。随后,它由语义文本特征交互式引导。
。Qf、Kf和Vf是F0 f的Q、K和V。随后,它由语义文本特征交互式引导。
语义交互融合解码器旨在实现文本语义特征![]() 与图像融合特征
与图像融合特征![]() 的交互。具体来说,它是由基于transformer的解码器块和语义交互指导模块(SIGM)构成的,这将在4节介绍。融合解码器模块和SIGM在多级级联中紧密耦合在一起,以实现密集调节和引导的效果。简言之,语义交互融合解码器可以描述为:
的交互。具体来说,它是由基于transformer的解码器块和语义交互指导模块(SIGM)构成的,这将在4节介绍。融合解码器模块和SIGM在多级级联中紧密耦合在一起,以实现密集调节和引导的效果。简言之,语义交互融合解码器可以描述为:
![]()
其中![]() 表示第k个块级处的图像融合特征。{·}r代表多级重复。
表示第k个块级处的图像融合特征。{·}r代表多级重复。![]() 和
和![]() 表示基于变换器的块和SIGM。注意,在解码器的级别之间需要上采样以对应于编码器处的下采样。
表示基于变换器的块和SIGM。注意,在解码器的级别之间需要上采样以对应于编码器处的下采样。
4、文本交互引导体系结构
预设的图像融合流水线可以有效地获得对应的融合特征Ff。而文本交互引导体系结构是实现文本语义信息与图像融合耦合的关键部分。
(1)文本语义编码器
给定一个提供相应语义特征的文本Ttext,引导图像融合网络得到指定的融合结果(例如,指定任务类型和降级类型),文本交互引导架构的文本语义编码器应该将其转换为文本嵌入。作为一个大型的预训练视觉语言模型,CLIP在文本特征提取方面具有较好的影响。我们倾向于从CLIP中冻结好的文本编码器,以保持良好的语言一致性。其中{·}e表示冻结权重,该过程可以表示为:
![]()
其中![]() 表示文本语义特征。在不同但语义相似的文本中,所提取的特征在约简的欧氏空间中应该是接近的。
表示文本语义特征。在不同但语义相似的文本中,所提取的特征在约简的欧氏空间中应该是接近的。
此外,我们设计了MLP ![]() 来挖掘这种连接,并进一步映射文本语义信息和语义参数。因此,可以获得:
来挖掘这种连接,并进一步映射文本语义信息和语义参数。因此,可以获得:
![]()
其中![]() 和
和![]() 是
是![]() 的组块操作以形成语义参数。
的组块操作以形成语义参数。
(2)语义交互指导模块
在语义交互引导模块中,语义参数通过特征调制和融合特征![]() 进行交互,从而达到引导的效果。特征调制包括尺度缩放和偏置控制,分别从两个角度对特征进行调整。特别地,使用剩余连接来降低网络拟合的难度。为简单起见,可以将其描述为:
进行交互,从而达到引导的效果。特征调制包括尺度缩放和偏置控制,分别从两个角度对特征进行调整。特别地,使用剩余连接来降低网络拟合的难度。为简单起见,可以将其描述为:
![]()
其中,![]() 表示Hadamard乘积。
表示Hadamard乘积。![]() 表示融合特征。
表示融合特征。![]() 是具有文本语义信息的。
是具有文本语义信息的。
5、损失函数
损失函数在很大程度上决定了提取的源信息的类型和源信息之间的比例关系。从文本引导的角度来看,我们不仅希望通过文本自由来解决各种退化问题。同时也期望文本能够根据用户的需求自主选择与融合任务相对应的最优损耗。因此,在文本引导的图像融合任务中,损失函数的构造是一种开集多点映射关系。
融合相关损失包括强度损失、结构相似性(SSIM)损失[40]、最大梯度损失和颜色一致性损失。考虑到退化,我们采用手动获取的高质量可见光图像![]() 和红外图像
和红外图像![]() 作为损失的约束条件。
作为损失的约束条件。
(1)强度损失
为了突出红外和可见光图像中的显著性目标,通过最大化结果的强度值来保证目标的显著性。其定义为:
![]()
(2)结构相似性损失
结构相似性损失主要度量融合图像与源图像之间的相似性,使得融合图像在结构上与源图像相似。其表示为:
![]()
其中![]() 表示红外结构相似性损失的比率,其是文本语义的函数。
表示红外结构相似性损失的比率,其是文本语义的函数。
(3)最大梯度损失
这种损失保留了两个源图像中的最大边缘。然后,可以获得更清晰的纹理表示。它可以表示为:
![]()
(4)颜色一致性损失
该方法使融合图像与可见光图像颜色一致。我们将图像转置到YCbCr空间,并使用Cb和Cr通道的欧几里得距离对其进行约束。它可以表示为:
![]()
其中FCbCr表示RGB到CbCr的传递函数。
(5)总损失
总体损失函数是融合相关损失的组合,并由语义信息调节。简单地说,它可以表示为:
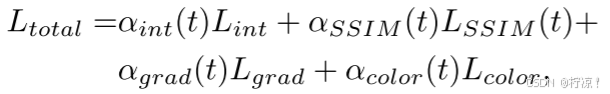
其中![]() 、
、![]() 、
、![]() 和
和![]() 是与任务t相关的语义调节超参数。融合结果的权衡起着很大的作用。
是与任务t相关的语义调节超参数。融合结果的权衡起着很大的作用。
五、实验
在本节中,我们首先介绍实现细节和相关配置。通过定性和定量的比较,评价了该方法的有效性和优越性。特别地,分析了文本引导图像融合的具体结果。最后进行了消融实验。
1、实施详情和数据集
(1)实施细节
本文提出的Text-IF是利用文本引导的图像融合数据进行训练的。使用AdamW优化器时,学习率为0.0001。批量为16个。源图像被裁剪为96 × 96。超参数集![]() ,本质上是一个与语义文本相关的离散复映射。有关详细信息,请参阅附加材料。所有实验均在采用PyTorch框架的NVIDIA GeForce RTX 3090 GPU上进行。
,本质上是一个与语义文本相关的离散复映射。有关详细信息,请参阅附加材料。所有实验均在采用PyTorch框架的NVIDIA GeForce RTX 3090 GPU上进行。
(2)数据集
为了验证通用性,常用的红外和可见光图像融合数据集为MSRS [29]、MFNet [5]、RoadScene [34]和LLVIP [8]。这些原始数据集在不同的情况下会出现退化,例如低光、过度曝光等,在可见图像中以及低对比度、噪声等,在红外图像中。我们选取场景不同的图像,采用人工复原的方式得到高质量的源图像,并添加相应的上百条描述说明,保证用户可以自由输入文字进行交互。我们总共使用了3618个图像对进行训练,使用了1135个图像对进行测试。
(3)指标
度量包括差值相关性之和(SCD)[2]、标准差(SD)、信息熵(EN)[18]、视觉信息保真度(VIF)[6]、基于梯度的融合质量(QAB/F)[18]、CLIPIQA [32]、NIQE [22]、MUSIQ [10]、BRISQUE [21]和空间频率(SF)[4]。SCD、SD、EN、VIF、QAB/F、CLIP-IQA、MUSIQ和SF的值越高,表示融合图像的质量越高。此外,NIQE和BRISQUE值较低表明质量较高。
(4)SOTA模型对比
在多个数据集上,将该方法与其他几种最新方法的性能进行了比较。用于比较的方法包括UMF-CMGR [31]、TarDAL [14]、ReCoNet [7]、MURF [36]、U2 Fusion [34]、MetaFusion [41]和DDFM [42]。
2、无文本指导的比较
现有的图像融合方法缺乏语义指导。为了比较公平性,我们首先只比较没有语义指导的融合性能。此时,Text-IF使用默认文本。这意味着没有引入额外的语义信息。
(1)定性比较
三个数据集的结果如图3所示。Text-IF由于基于Transformer的高表达能力的流水线和隐式嵌入图像恢复先验,显示了三个独特的优势。首先,我们的结果可以突出热目标。如前三组结果所示,我们的结果中热目标的像素强度最高。结果表明,热目标在计算结果中最为突出。第二,我们的结果显示了更合适的亮度和提供更多的细节。在第二组和第三组中,我们的结果的大部分区域显示出比竞争对手的结果更高的像素强度。在这种情况下,可以清楚地呈现更多的场景内容。最后,我们的结果可以呈现更生动和自然的颜色。如上一个例子所示,在我们的结果中,汽车和树木的颜色与可见图像的颜色更相似。通过减少红外图像对可见光图像中颜色信息的干扰,我们的融合结果更有利于从颜色的角度进行视觉感知。

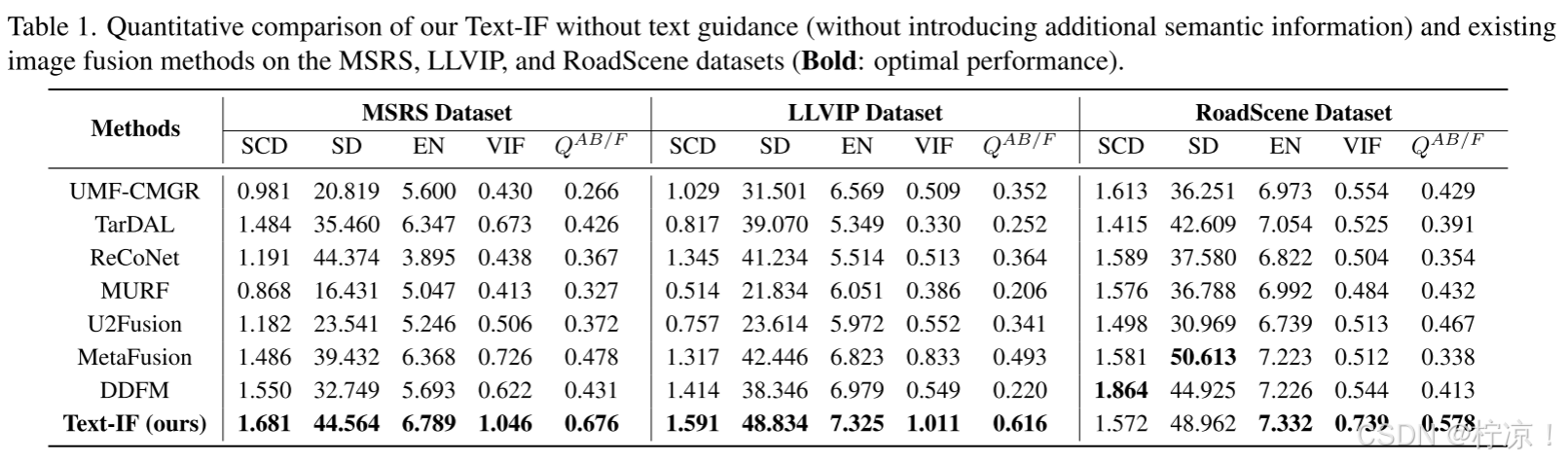
(2)定量比较
在三个数据集上使用五个指标测试的定量结果报告在表1中。在MSRS和LLVIP数据集上,该方法在所有5个指标上都表现得最好,特别是在SCD和VIF上表现出明显的优势。在RoadScene数据集上,我们的方法也在三个指标上表现最佳。在EN、VIF和QAB/F上的实验结果表明,即使在没有文本引导的情况下,该方法也能产生信息量最大的融合结果,使融合图像与源图像之间的失真最小,并将最多的边缘转移到融合图像中。在SCD和SD上的最佳或可比结果反映了我们的结果具有小的融合失真和高对比度(良好的视觉效果)。从度量的角度看,该方法在多个度量上的优越性表明了该方法在融合性能方面的全面性。从数据集的角度看,该方法在多数据集上的优越性体现了其在多种数据分布和多种场景类型下的泛化能力。
3、有文本指导的比较
在真实的场景中,源图像通常会遭受各种退化,较差的照明、噪声和低对比度。现有的图像融合方法无法处理这些退化问题,导致融合效果不理想,而我们的方法可以通过简单的文本指导。因此,为了公平起见,我们将联合收割机现有的图像融合方法与图像恢复方法结合起来进行比较。针对不同退化的SOTA图像恢复模型包括用于弱光图像增强的URetinex [33]、用于对比度增强的AirNet [12]、用于去噪的GDID [3]和用于过度曝光校正的LMPEC [1]。还值得注意的是,我们的方法在所有场景中使用相同的模型参数,即,对于所有的降级。
(1)定性比较
Text-IF的定性结果以及在退化源图像上结合SOTA图像恢复和图像融合竞争者的结果如图4所示。一般来说,与现有的方法,需要手动先验添加恢复预处理融合,文本IF只需要提供一个简单的请求/描述的场景,然后可以处理退化的源图像。它避免了在对抗退化的过程中寻找和切换不同恢复方法的繁琐任务。

然后,我们详细比较了各种退化情况下的融合结果。首先,在前两个例子中,可见图像受到低照明的影响。竞争对手可以在一定程度上使用URetinex使可见图像变亮。然而,融合后,红外图像的低像素强度仍然降低了其结果的亮度,也降低了色彩饱和度。相比之下,我们的方法产生更合适的亮度和更明亮的颜色。在第三个也是最后一个例子中,红外图像对比度低,或者可见光图像曝光过度。在此条件下,该方法可以扩大融合结果的动态范围,获得对比度更高的融合结果,同时保证其颜色信息的正确性。然后,结果可以显示更清晰的细节。在第四个例子中,红外图像遭受明显的噪声。GDID不能去除所有噪声,导致融合结果中存在残留噪声。通过比较,我们的结果显示较少的噪声污染,呈现更高的图像质量。此外,我们的结果中热目标的突出性也是有利的。
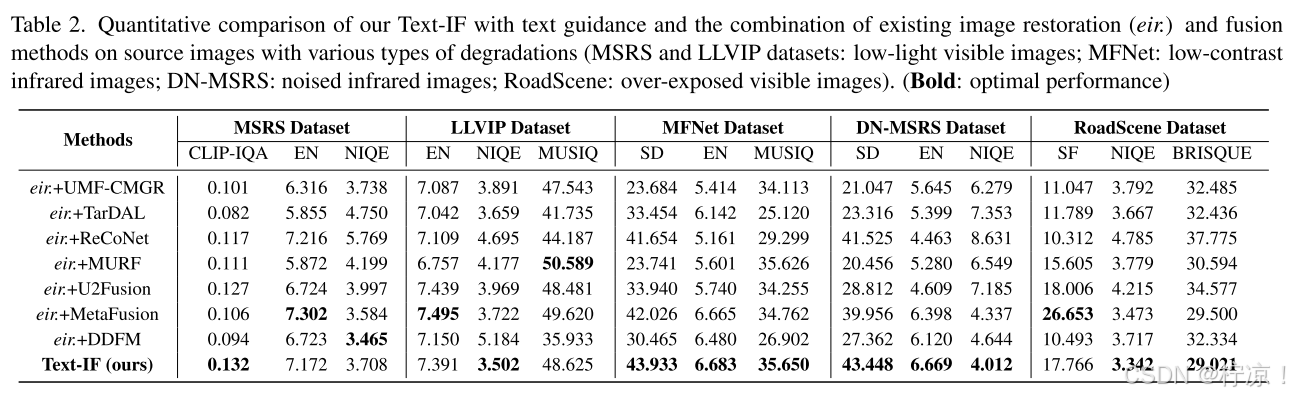
(2)定量比较
不同类型退化的数据集结果报告在表2中。TextIF仍然在MSRS、LLVIP、MFNet、DN-MSRS和RoadScene数据集的所有指标上实现了整体最佳性能。对SD、EN和SF的实验结果表明,该方法能有效地传递融合图像中的信息。在CLIP-IQA、NIQE、MUSIQ和BRISQUE上的实验结果表明,该方法能够在退化情况下产生高质量的融合结果。
4、高级任务性能
为了验证融合算法在下游高级视觉任务中的性能,我们在LLVIP数据集上对融合结果进行了目标检测实验。我们采用YOLOv 8作为物体检测主干,并在LLVIP的红外可见光源图像上对其进行微调。定性和定量实验结果见图5和表3。

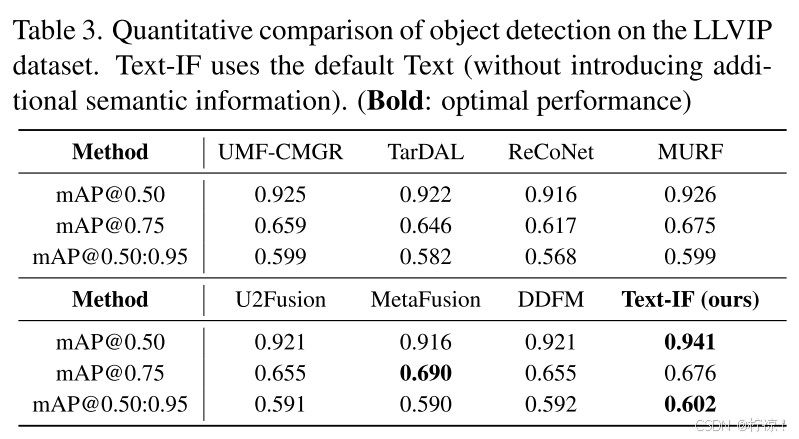
(1)SOTA模型比较
在定性比较方面,我们提出的方法Text-IF检测的所有对象在场景中,而其他方法有错过检测。在定量比较方面,Text-IF获得了最好的检测性能。
5、消融实验
为验证所提出方法的有效性,在LLVIP数据集上进行了一系列的消融实验。它主要包括图像融合的消融损失,包括亮度损失、结构相似性(SSIM)损失、最大梯度损失和颜色一致性损失。如图6和表4,给出了定性和定量结果。

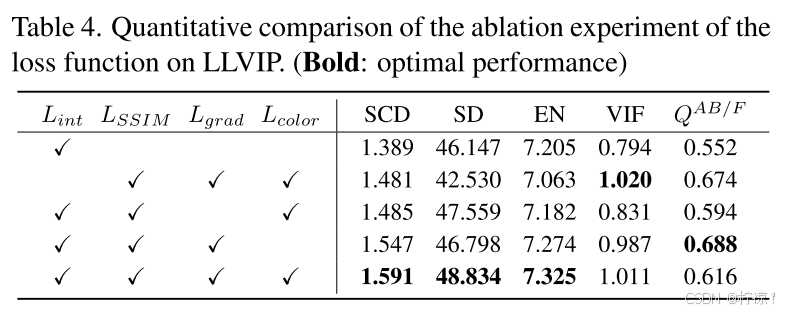
在定性结果方面,强度损失保留了目标的显著热辐射。颜色损失保持一致的颜色。最大梯度损失提供了清晰的纹理信息。在定量结果方面,每个损失对最终的定量评估结果具有相应的贡献。该方法在所有消融方法中取得了最好的定性和定量评价,证明了该方法的有效性。
六、结论
针对现有方法难以解决复杂场景的退化融合问题和难以获得用户所需的交互式融合图像的问题,本文扩展了图像融合任务,提出了一种新的文本引导图像融合框架。通过图像融合流水线、文本语义特征提取和语义交互引导模块,实现了文本语义引导的图像融合目标。大量的实验结果表明,该方法在融合性能和退化处理方面具有明显的优势。该方法使得根据用户自由输入的交互式文本生成相应的融合图像成为可能,对实践和后续的理论研究起到了推动作用。

















 1615
1615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









