




1、报错ran out of print
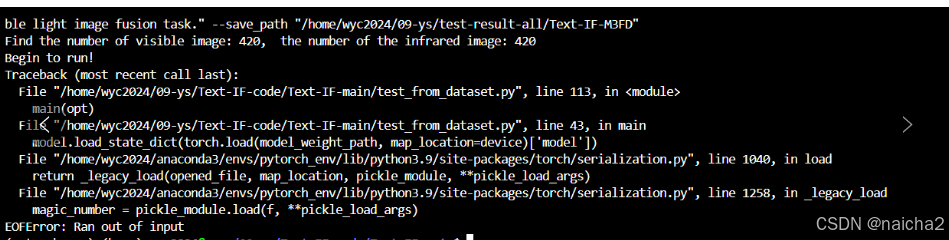
是输入错了,检查数据、权重等文件是否存在且路径正确。我这里是Text-IF模型需额外下载放进去,我没下载。所以报错。下载好放进去就行。
跑Text-IF的test.py文件是在终端输入这个:
CUDA_VISIBLE_DEVICES=1,2,3 python test_from_dataset.py --weights_path "/home/wyc2024/09-ys/Text-IF-code/Text-IF-main/pretrained_weights/text_fusion.pth" --dataset_path "/home/wyc2024/09-ys/data-all/LLVIP/test" --input_text "This is the infrared and visible light image fusion task." --save_path "/home/wyc2024/09-ys/test-result-all/Text-IF-LLVIP" --gpu_id 1 2 3
2、报错cuda溢出
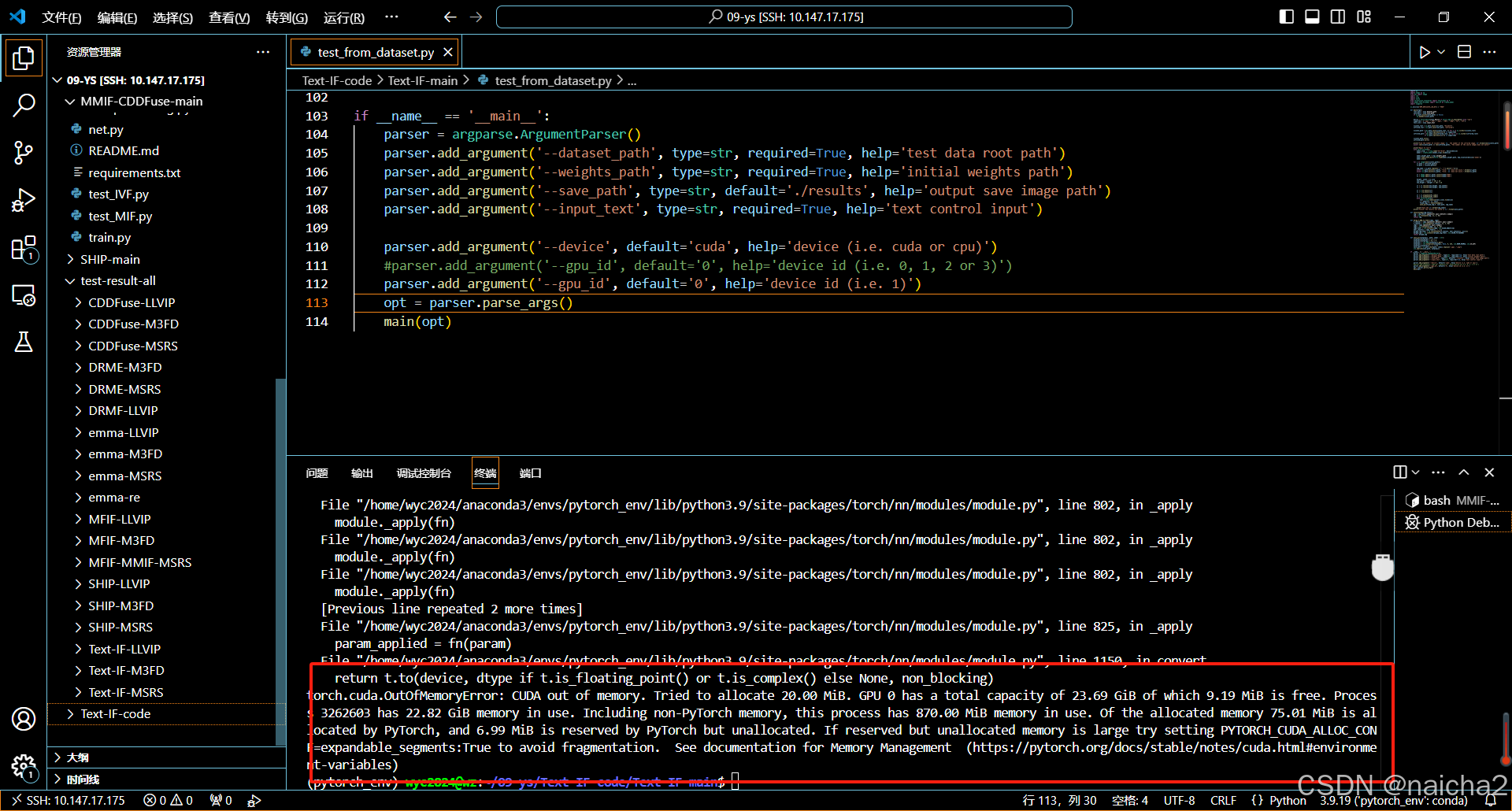
解决:首先看一下服务器显卡有没有空闲,命令如下:nvidia-smi,如果有空闲,则可以改代码,一口气用几张跑,如下:注释掉的是之前的代码,113行是更改之后的。并且跑代码的python test.py 后面加参数:gpu_id 1 2 3,故要这样:python test.py gpu_id 1 2 3
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1863
1863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









