







1.预处理指令 --- #define 的作用
对于预处理指令#define ,它具有两个作用
1.#define定义标识符
所谓定义标识符其实就是将标识符与我们新定义的内容进行等价,当我们想在程序中书写我们新定义的内容都用标识符替代,并且在预处理阶段会用我们新定义的内容直接替换程序中的标识符
通过这样一种方式可以大大提高我们的编程效率,只要我们已修改我们定义给标识符的内容,程序中所有标识符对应的内容都会发生相应的改变,是不是很方便呀~
关于#define标识符有一种比较特殊的情况,那就是 ---- 预定义符号
所谓预定义符号就是当我们创建源文件的时候,编译器就会自动帮我们准备好的#define定义的标识符 ,如下:

这些都是在我们创建源文件的时候计算机自动帮我们准备好的#define定义的标识符,每个表示符被定义的内容就是上面图中注释的内容
说明:
__FILE__ 标识符被定义的内容是当前源文件的完整文件名 --- 文件路径 + 文件命名 + 文件后缀
__LINE__标识符被定义的内容是当前__LINE__标识符所处的语句的行号
__STDC__标识符比较特殊,它只有在编译器遵循ANSI C标准的时候,才被定义为1,否则未定义
#define定义标识符时,能够用来定义标识符的 --- 由我们定义的内容有很多种类型:
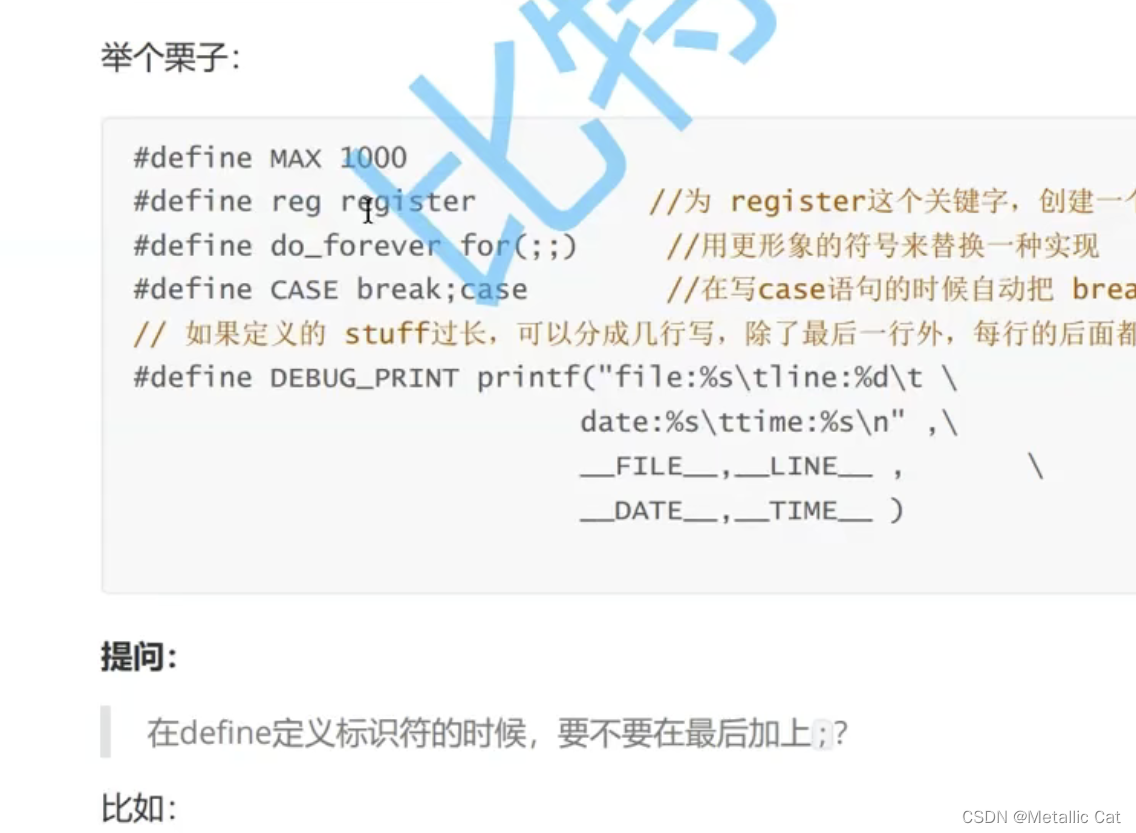
比如:
1. 替换为整型,浮点型数字
2.替换为类型说明符
3.替换为单个/多个语句等等
总之无论用来替换标识符的内容是什么,我们都要牢记一点:
#define的替换是直接替换!!
且#define标识符后面最好不要有分号 ; 避免出错
2.#define定义宏
首先要讲的是:
#define定义宏的申明格式:
#define name(parament(参数)-list) stuff(东西,特征)
我们称 name(parament(参数)-list) 这一块东西为宏 ,而后面的stuff则是我们自定义的,用来替换宏的东西 --- stuff
宏的特点:
1.name和括号之间不能有空隙,不然的话就变成了#define标识符了
2.括号里面必须有参数,可以有多个,也可以只有一个,参数由大写字母来表示
用来替换宏的由我们定义的stuff 的特点:
1.必须得是一个能够输出结果的表达式 / 一个能够执行的语句
表达式包括:
逻辑表达式 --- 如x>y?x:y ---(x>y是否为真,为真选x ,为假选y )
算术表达式 --- x*x 等等都行 --- stuff中的参数也用大写表示
2.表达式 / 可执行语句中的参数种类必须等于宏给出的参数种类
宏的传参特点:参数是不经过任何计算直接传进去的!-- 你传什么参数它就直接把参数替换过去,无论是数字还是字母也好,都是直接替换的!!!
宏的总体实现逻辑:
定义好宏 --- 程序中调用宏并传参如add(1+2,3) --- 将参数不经计算传给#define定义的宏接收 --- add(X,Y) --- 宏接收之后再将参数不经计算的传给stuff --- Y -X --- 3-1+2 --- 再用传好参数的stuff将程序中对应的宏直接替换 --- 然后就是程序中的计算分析了
ps : 由于宏的直接替换的特性,当我们传的参数是计算式的时候,很可能得到错误的结果,为了避免这种情况,我们最好定义宏的stuff中的每个参数都加上括号,同时也包括stuff本身这个整体也加上括号,这样的话能够很好的避免stuff替换程序中对应的宏可能出现的错误
#define替换规则

1.首先检测宏中是否有#define定义的表示符,如果有,就先替换这些标识符
2.进行#define定义的标识符和宏的对应替换
3.再一次扫描文件,看看还有没有需要替换的,如果有重复上面的步骤,否则,结束。
对于宏定义而言,两个特殊的符号 ---- # 和 ##
#的作用是 --- 将#后面的参数转化为字符串形式并插入到字符串中
#只能在#define定义宏中使用,而且作用对象只能是宏的参数

如上图:
int a = 10
当我们把参数a传过去的时候 ,首先是#X会将a这个参数直接转换为字符串的形式插入到宏中的字符串中 --- 即 #X == “ x ” ---> #a == " a "
补充一个点: printf函数的括号中可以有多个字符串,且每个字符串按照从左到右的顺序打印
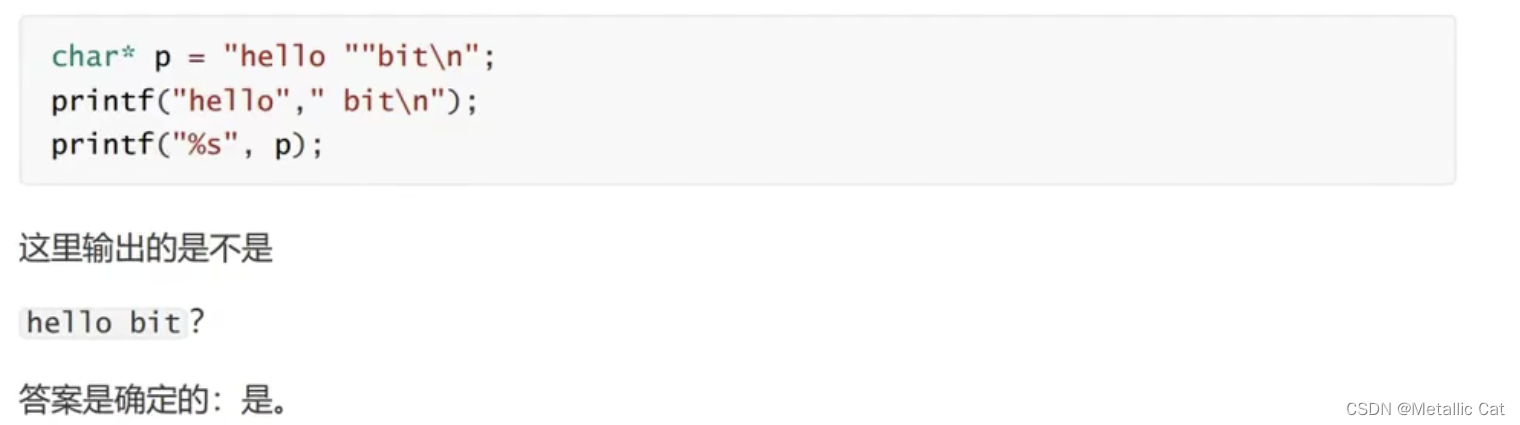
##的作用 ---- 是把两个符号合成为一个符号 --- 仅在#define定义宏中起作用
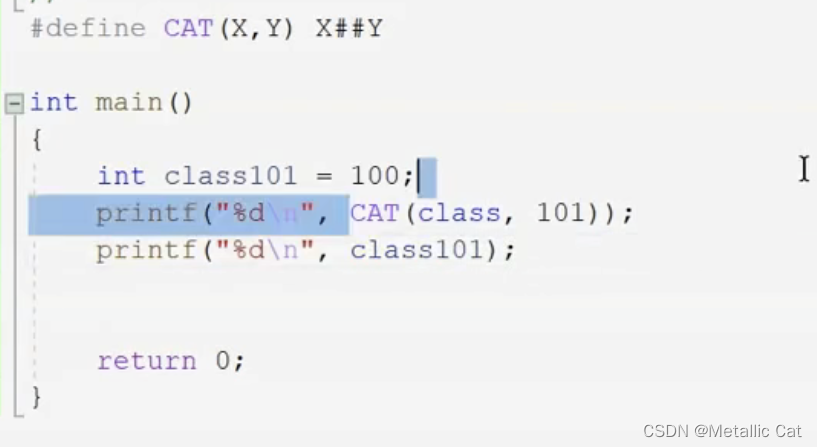
如图,上下两个printf的作用是一样的
##的作用就是将左右两个参数作为两个标识符合并在一起,并用这个合成标识符来替换程序中对应的宏。
带副作用的宏参数
首先我们要解释一个问题,就是什么叫做参数的副作用:请看下面这一段代码:

在这段代码中,第二行和第三行都成功的给b赋值了2,但是第三行代码在完成了赋值工作的同时还改变了a的值,此时我们就称 --- 参数具有副作用
参数具有副作用即指:参数在实现赋值的同时还起到了其它的作用 --- 最典型的如参数是 a++,此时不仅给stuff中的参数赋值了a,还让a进行+1
实现了赋值的同时还实现了别的操作,就称为副作用
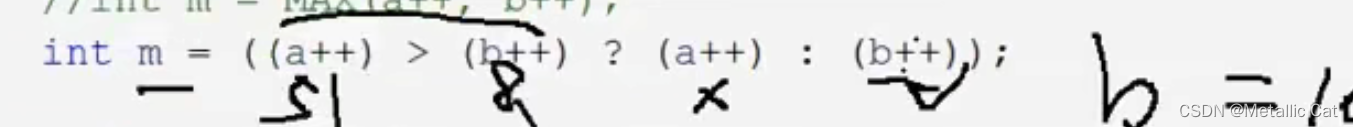
补充一个逻辑运算式的运算逻辑:
1.进行判断
a = 5 , b = 8
(a++) > (b++) ? --- 后置++的话必须先使用再++ , 所以先是 5 和 8 进行比较,比较结果为假,比较结束,开始 ++ ,a -> 6 ,b ->9
然后上面的逻辑表达式是若(a++) > (b++)为假,则之后后一个,即执行(b++)而前一个(a++)不执行 ,依然是先使用再++ ,(b++)先使用b,输出结果9,然后再b++ 得到10
总结:尽量少用带有副作用的宏参数,除非完全想清楚了,不然会很容易出错的
宏是与类型无关的,宏能够适用于各种各样的类型
我们调试的是可执行程序,而宏在编译阶段就已经全都被替换完成了,所以说我们无法在可执行文件中调试未被替换的宏
.c -> 编译 ->链接 -> .exe可执行文件
宏具有一个函数实现不了的功能 --- 宏能够将类型作为参数传递

宏与函数的优劣势对比
函数传参如果传的是计算式的话,会先将式子计算好后再把结果传过去,这是与宏不计算直接替换非常不同的一点
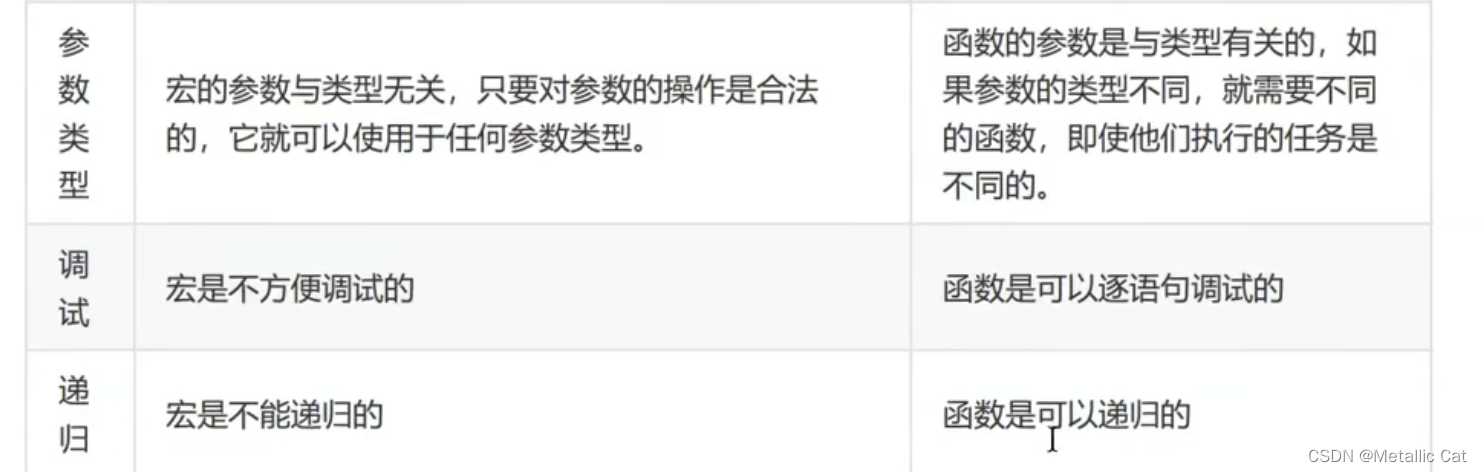
宏不可以自己调用自己(递归),而函数可以!! 宏不可以调试而函数可以
运算逻辑足够简单 --- 用宏,足够复杂 --- 用函数
命名约定

命名约定就是 --- 宏名全部大写,函数名不要全部大写
#undef
这条指令用于移除一个#define对符号的定义,移除格式是:
#undef 标识符名

命令行定义
书写命令行的时候我们要给命令行传一个参数 ,这个参数就被我们称为命令行参数

将标识符在命令行中定义,就称为命令行定义

命令行定义就是在命令行中直接进行标识符定义
条件编译
所谓的条件编译就是 --- 满足一定条件就进行编译,不满足条件就不进行编译

编译时会删除掉调试性的代码,但有时候我们想保留一部分代码而不是全删除,这时候就可以使用我们的工具 --- 条件编译 ,这样我们就可以有选择的保留代码了。
条件编译格式如下:

#ifdef 是一个判断 ,#endif是一个终点
如果 #ifdef 其后的标识符被定义了,那么它和#endif之间的语句就会被编译,否则的话不会被编译
然后只要 #ifdef 后面的标识符有出现在 #define 后面的话,我们就称这个标识符被定义了!
常见的条件编译指令

1.
#if 常量表达式
//....
#endif --- 例子如下:

#if 后面放一个常量表达式 ,如果这个表达式的输出结果为非0,则该表达式为真,为真就编译下面的语句 ,为假就不编译下面的
如果代码没被编译的话,代码就不会被执行
ps: 常量表达式可以为1,也可以为 3+1这种 ,常量表达式为1时输出结果为1 ,为 3 +1 时输出结果为 4
2.多个分支的条件编译 --- 其实就和 if else 语句差不多
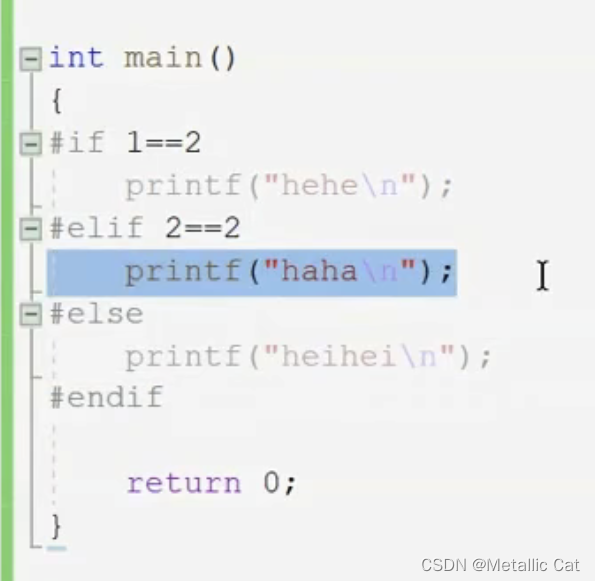
如果第一个#if 后面为真那就编译 #if 范围内(#if 到 下一个#elif / #else)的语句
如果为假就判断 #elif 后面是否为真 ,如果为真就编译 #elif 范围内的语句 ,范围同上 #if替换为#elif,依此类推,如果#else前面的都为假,哪就编译 #else到#endif范围内的语句
注意 #if 和 #elif 后面只能是常量表达式 ,而 #ifdef 后面则只能是标识符 ,判断逻辑是如果这个标识符被定义了,则 #ifdef 和 #endif 之间的语句被编译,否则不被编译
关于 #ifdef 还有两个它的变种形式:
第一个是: #ifndef

对于#ifndef来说,如果其后的标识符没被定义的话,则其和 #endif 之间的代码被编译,否则的话不被编译
#ifndef --- 也有一个变种形式 : #if !defind( 标识符 )
对于这个#if !defind( 标识符 ))来说,如果它括号里的标识符没被定义的话,则它和#endif之间的代码被编译,否则不被编译
第二个是 : #if defind( 标识符 )
对于这个#if defind( 标识符 )来说,如果它括号里的标识符被定义的话,则它和#endif之间的代码被编译,否则不被编译

上面这些条件编译指令是可以嵌套起来用的!! 就跟if的用法差不多
头文件被包含的方式
1.本地文件包含 --- #include "文件命名 + 后缀"
本地文件即指 我们自己创建的头文件
2.库文件包含 --- #include <文件命名 + 后缀>
库文件即指c语言库中已经包含,不需要我们自己创建的文件
这两种包含方式的本质区别就是它们的查找策略的区别:
1. “ ” 双引号这种包含形式的查找策略是:
先在源文件所在目录下查找冒号里的文件,如果该头文件未找到,编译器就会去到库函数的头文件所在的目录下查找该头文件 ,如果还找不到的话就提示编译错误。
2. < >箭头这种包含形式的查找策略是:
直接去到库函数的头文件的目录下查找箭头里的头文件,如果找不到的话就会报错。
3.嵌套文件包含
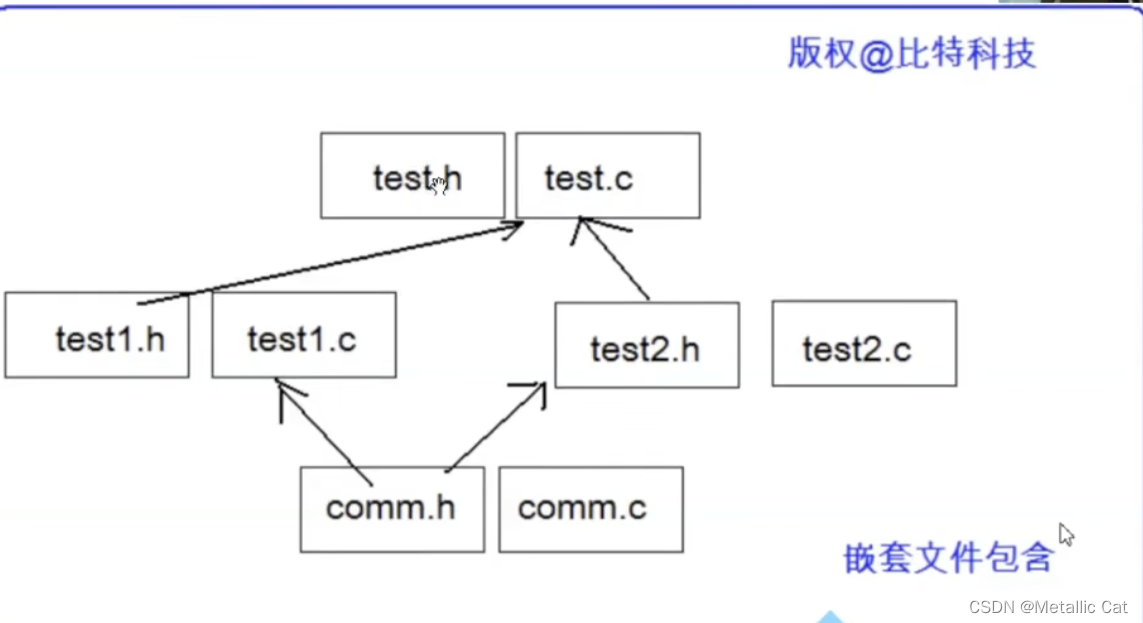
如何防止一个头文件被重复多次包含呢?
1.在该头文件中写上 #pragram once 指令
这样的话,哪怕这个头文件已经被重复多次包含,也只会在预编译阶段被拷贝一次
2. 用条件编译指令来避免多次包含带来的预编译阶段的重复拷贝
其他预处理指令
......非常多.....
寄存器变量 ---- 由关键字register修饰的变量 --- 格式是 register + 变量类型 + 变量名 --- 写出这样一个格式后我们就成功申请了一个寄存器变量了。寄存器变量和其它变量之间的差别就是,寄存器变量是直接存储在CPU中的寄存器中的,而不是存储在内存中的。寄存器变量的特点是能够被快速调用和操作。
寄存器型变量常用于作为循环控制变量,这是使用它的高速特点的最佳场合
对于switch 来说 --- 格式是 case + 判断数字 + :冒号
如果代码太长就要加上续航符
if后面跟一条语句 --- 不用加花括号
跟两条语句 --- 要加花括号















 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









