







本章介绍的是现代神经网络的结构和复现,包括深度卷积神经网络(AlexNet),VGG,NiN,GoogleNet,残差网络(ResNet),稠密连接网络(DenseNet)。
文章部分文字和代码来自《动手学深度学习》
残差网络(ResNet)
残差网络(Residual Network,简称 ResNet)是由微软研究院于 2015 年提出的一种深度卷积神经网络。它的主要特点是在网络中添加了“残差块”(Residual Block),有效地解决了深层网络的梯度消失和梯度爆炸问题,从而使得更深的网络结构可以训练得更好。
ResNet 的核心思想是学习残差,即在训练过程中让神经网络学习一个残差映射,该映射将输入直接映射到输出,即 F ( x ) = H ( x ) − x F(x) = H(x) - x F(x)=H(x)−x。这里 x x x 表示残差块的输入, H ( x ) H(x) H(x) 表示残差块的输出。在传统的网络结构中,网络的每一层都需要学习一个映射函数,即 H ( x ) H(x) H(x),但这种方法会出现梯度消失和梯度爆炸问题。而使用残差块可以使网络只学习残差部分,即 F ( x ) F(x) F(x),这使得训练更加容易,并且可以构建更深的网络结构。
ResNet 的基本结构是残差块,其中包含了跨层连接(skip connection)的机制。跨层连接可以将输入直接传递到输出端,从而避免了梯度消失问题,同时也减轻了梯度爆炸问题。除了跨层连接之外,ResNet 还采用了批量归一化(Batch Normalization)和池化操作等技巧来提高网络的训练效率和泛化能力。
总体上来说,ResNet 是一种十分有效的深度神经网络结构,其在许多计算机视觉任务上都取得了优异的表现,例如图像分类、物体检测和语义分割等
恒等变换
恒等变换(Identity Transformation)指的是一种变换,使得输入和输出完全相同。在数学上,恒等变换可以用一个函数f(x) = x来表示。
在深度学习中,恒等变换通常用于残差块(Residual Block)中。在残差块中,恒等变换被用作跳跃连接(Shortcut Connection),将输入直接传递给输出,这样可以加速梯度的传播和网络的训练。
举个例子,假设有一个残差块的输入x和输出y,它们的维度都为d。那么该残差块可以表示为:
y = f(x) + x
其中,f(x)是残差块的变换,它会对输入进行处理。而x则是恒等变换,它使得输入可以直接传递给输出。通过这样的设计,残差块可以保留输入中的有用信息,同时仍然能够对输入进行一定程度的处理,从而提高网络的性能。
跳跃连接
跳跃连接(Skip Connection),也称为残差连接(Residual Connection),是深度神经网络中的一种连接方式,用于解决网络训练过程中梯度消失问题。
在跳跃连接中,网络的某一层的输出不仅会传递给下一层进行计算,还会直接传递到距离当前层较远的层。这样可以使得网络中的信息能够更快地传递和共享,同时也可以减轻梯度消失的问题,使得训练过程更加稳定。
在ResNet网络中,跳跃连接被用于将网络的输入直接连接到卷积层的输出上,形成一个残差块。这样,网络的前向传播就变成了从输入到输出的“路径”加上一个残差块的“跳跃”,即“shortcut”。跳跃连接的使用大大改善了ResNet的性能,使得它在ImageNet图像分类等任务中取得了非常优秀的表现。
残差块
残差块(Residual Block)是深度学习中常用的一种模块,可以用来构建深度神经网络。残差块的主要作用是使得神经网络的训练更加容易,并且能够加速神经网络的收敛。
让我们聚焦于神经网络局部:如图所示,假设我们的原始输入为x,而希望学出的理想映射为f(x)作为上方激活函数的输入,左图虚线框中的部分需要直接拟合出该映射f(x),而右图虚线框中的部分则需要拟合出残差映射f(x)-x。残差映射在现实中往往更容易优化。 以本节开头提到的恒等映射作为我们希望学出的理想映射f(x),我们只需将图中右图虚线框内上方的加权运算(如仿射)的权重和偏置参数设成0,那么f(x)即为恒等映射,实际中,当理想映射f(x)极接近于恒等映射时,残差映射也易于捕捉恒等映射的细微波动。

在深度神经网络中,很容易出现梯度消失或梯度爆炸的问题,这会导致深度神经网络的训练非常困难。残差块的设计可以缓解这个问题。残差块的主要思想是在网络中增加一条跳跃连接(Shortcut Connection),这条连接可以让输入直接跳过一些层,从而更加容易地传递梯度。具体来说,残差块可以分为如下几个步骤:
- 输入x经过一个卷积层,得到特征图y1。
- 将y1经过一个Batch Normalization层和ReLU激活函数。
- 将y1再次经过一个卷积层,得到特征图y2。
- 将y2经过一个Batch Normalization层。
- 将输入x和y2相加,得到残差特征图y3。
- 将y3再经过一个ReLU激活函数。
在这个过程中,输入x可以看做是一种残差,因为它会直接和特征图y2相加。这个残差块的设计可以让网络更容易地学习残差,从而更好地拟合训练数据。此外,残差块也可以增加网络的深度,从而提升网络的效果。
ResNet模型
结构
ResNet原文中给出了几种基本的网络结构配置,本文以ResNet50为例。
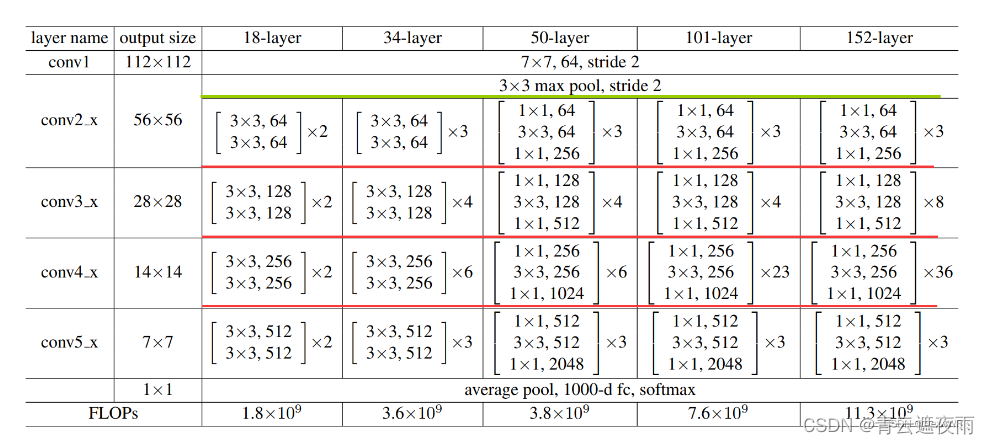
ResNet50结构详解:
-
输入层(Input Layer):输入图像的大小为224 x 224 x 3。
-
卷积层(Convolution Layer):7x7的卷积核,步长为2,输出通道为64,padding为3。
-
标准化层(Batch Normalization Layer):对每个通道的输出做标准化处理,包括均值和方差。
-
激活函数(Activation Layer):使用ReLU激活函数。
-
最大池化层(Max Pooling Layer):3x3的池化核,步长为2,padding为1,对每个通道的输出取最大值。
-
残差块(Residual Block)1:包含3个卷积层和标准化层。第一个卷积层的卷积核为1x1,输出通道为64;第二个卷积层的卷积核为3x3,输出通道为64;第三个卷积层的卷积核为1x1,输出通道为256(因为残差块的输入和输出通道数不同,需要用1x1的卷积核进行通道变换)。
-
残差块(Residual Block)2:包含4个卷积层和标准化层。第一个卷积层的卷积核为1x1,输出通道为128;第二个卷积层的卷积核为3x3,输出通道为128;第三个卷积层的卷积核为1x1,输出通道为512。
-
残差块(Residual Block)3:包含6个卷积层和标准化层。第一个卷积层的卷积核为1x1,输出通道为256;第二个卷积层的卷积核为3x3,输出通道为256;第三个卷积层的卷积核为1x1,输出通道为1024。
-
残差块(Residual Block)4:包含3个卷积层和标准化层。第一个卷积层的卷积核为1x1,输出通道为512;第二个卷积层的卷积核为3x3,输出通道为512;第三个卷积层的卷积核为1x1,输出通道为2048。
-
平均池化层(Average Pooling Layer):使用全局平均池化,将输出的特征图转化为向量。
-
全连接层(Fully Connected Layer):将向量连接到最终的输出层,该层包含1000个神经元,每个神经元对应于一个类别,表示图像属于该类别的概率。
-
Softmax层(Softmax Layer):使用softmax函数将全连接层的输出转化为概率分布,每个类别的概率为0到1之间的实数,概率之和为1。
总结:ResNet50网络结构由多个残差块组成,每个残差块内部包含多个卷积层和标准化层。通过使用残差学习的方法,ResNet50网络能够在训练深度神经网络时解决梯度消失和梯度爆炸的问题,同时在图像分类等任务中表现出色。
实现
残差块
import torch.nn as nn
import torch.onnx
class Residual(nn.Module):
def __init__(self, in_channels, channels, stride, downsample=None):
super(Residual, self).__init__()
# 1x1的卷积降维操作
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=channels, kernel_size=(1, 1),
bias=False)
self.bn1 = nn.BatchNorm2d(channels)
# 3x3的卷积提取特征操作
self.conv2 = nn.Conv2d(in_channels=channels, out_channels=channels, kernel_size=(3, 3),
stride=stride,
padding=1,
bias=False)
self.bn2 = nn.BatchNorm2d(channels)
# 1x1的卷积升维操作
self.conv3 = nn.Conv2d(in_channels=channels, out_channels=channels * 4, kernel_size=(1, 1),
bias=False)
self.bn3 = nn.BatchNorm2d(channels * 4)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
# 4组卷积层的头一层网络会做一次降采样,目的是使out和identity维度一致可以做加法
if self.downsample is not None:
self.dconv = nn.Conv2d(in_channels, channels * 4, stride=stride, kernel_size=(1, 1), bias=False)
self.dbn = nn.BatchNorm2d(channels * 4)
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
identity = self.dconv(identity)
identity = self.dbn(identity)
out += identity
out = self.relu(out)
return out
ResNet
class Resnet50(nn.Module):
def __init__(self, num_classes):
super(Resnet50, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=(7, 7), stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu1 = nn.ReLU(inplace=True)
self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# 对应第1组网络层,3*Resnet的基本结构
self.conv64_1 = Residual(64, 64, stride=1, downsample=True)
self.conv64_2 = Residual(256, 64, stride=1)
self.conv64_3 = Residual(256, 64, stride=1)
# 对应第2组网络层,4*Resnet的基本结构
self.conv128_1 = Residual(256, 128, stride=2, downsample=True)
self.conv128_2 = Residual(128 * 4, 128, stride=1)
self.conv128_3 = Residual(128 * 4, 128, stride=1)
self.conv128_4 = Residual(128 * 4, 128, stride=1)
# 对应第3组网络层,6*Resnet的基本结构
self.conv256_1 = Residual(512, 256, stride=2, downsample=True)
self.conv256_2 = Residual(256 * 4, 256, stride=1)
self.conv256_3 = Residual(256 * 4, 256, stride=1)
self.conv256_4 = Residual(256 * 4, 256, stride=1)
self.conv256_5 = Residual(256 * 4, 256, stride=1)
self.conv256_6 = Residual(256 * 4, 256, stride=1)
# 对应第4组网络层,3*Resnet的基本结构
self.conv512_1 = Residual(1024, 512, stride=2, downsample=True)
self.conv512_2 = Residual(512 * 4, 512, stride=1)
self.conv512_3 = Residual(512 * 4, 512, stride=1)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(2048, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.maxpool1(x)
x = self.conv64_1(x)
x = self.conv64_2(x)
x = self.conv64_3(x)
x = self.conv128_1(x)
x = self.conv128_2(x)
x = self.conv128_3(x)
x = self.conv128_4(x)
x = self.conv256_1(x)
x = self.conv256_2(x)
x = self.conv256_3(x)
x = self.conv256_4(x)
x = self.conv256_5(x)
x = self.conv256_6(x)
x = self.conv512_1(x)
x = self.conv512_2(x)
x = self.conv512_3(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
利用ResNet50进行CIFAR10分类
数据集
# 导入数据集
from torchvision import datasets
import torch
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomHorizontalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize((0.485,0.456,0.406),(0.229,0.224,0.225))
])
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'trunk')
cifar_train = datasets.CIFAR10(root="/data",train=True, download=True, transform=transform)
cifar_test = datasets.CIFAR10(root="/data",train=False, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(cifar_train, batch_size=16, shuffle=True)
test_loader = torch.utils.data.DataLoader(cifar_test, batch_size=16, shuffle=False)
损失函数优化器
# 定义损失函数和优化器
net=Resnet50(10);
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.001)
epoch = 5
net = net.to(device)
total_step = len(train_loader)
train_all_loss = []
val_all_loss = []
训练
import numpy as np
for i in range(epoch):
net.train()
train_total_loss = 0
train_total_num = 0
train_total_correct = 0
for iter, (images,labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
loss = criterion(outputs,labels)
train_total_correct += (outputs.argmax(1) == labels).sum().item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_total_num += labels.shape[0]
train_total_loss += loss.item()
print("Epoch [{}/{}], Iter [{}/{}], train_loss:{:4f}".format(i+1,epoch,iter+1,total_step,loss.item()/labels.shape[0]))
net.eval()
test_total_loss = 0
test_total_correct = 0
test_total_num = 0
for iter,(images,labels) in enumerate(test_loader):
images = images.to(device)
labels = labels.to(device)
outputs = net(images)
loss = criterion(outputs,labels)
test_total_correct += (outputs.argmax(1) == labels).sum().item()
test_total_loss += loss.item()
test_total_num += labels.shape[0]
print("Epoch [{}/{}], train_loss:{:.4f}, train_acc:{:.4f}%, test_loss:{:.4f}, test_acc:{:.4f}%".format(
i+1, epoch, train_total_loss / train_total_num, train_total_correct / train_total_num * 100, test_total_loss / test_total_num, test_total_correct / test_total_num * 100
))
train_all_loss.append(np.round(train_total_loss / train_total_num,4))
val_all_loss.append(np.round(test_total_loss / test_total_num,4))
可视化
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
plt.figure()
plt.title("Train Loss and Test Loss Curve")
plt.xlabel('plot_epoch')
plt.ylabel('loss')
plt.plot(train_all_loss)
plt.plot(val_all_loss)
plt.legend(['train loss', 'test loss'])

















 457
457

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











