







摘要
在目标导向的对话规划中,通常需要模拟未来的对话互动并估计任务进展。因此,许多方法考虑训练神经网络来执行前瞻性搜索算法,如A*搜索和蒙特卡洛树搜索(MCTS)。然而,这种训练往往需要大量的标注数据,当面临噪声标注或资源稀缺的情况下,会带来挑战。我们提出了一种名为GDP-ZERO的方法,使用开环MCTS进行目标导向的对话策略规划,而无需任何模型训练。GDP-ZERO在树搜索过程中,通过大型语言模型来充当策略先验、价值函数、用户模拟器和系统模型。我们在目标导向任务“PersuasionForGood”上评估了GDP-ZERO,发现其生成的响应在多达59.32%的情况下比ChatGPT更受青睐,并且在交互评估中,其说服力被认为优于ChatGPT。
主要工作
提出了一种新的目标导向对话规划方法,称为GDP-ZERO。GDP-ZERO通过提示大型语言模型(LLM)来模拟未来的对话互动进行规划(见图1),这使其特别适用于那些通常需要高质量对话和标注的任务。与以往的方法不同,我们将策略规划视为一个随机博弈,并在开环树搜索的每个阶段使用提示。我们在PersuasionForGood任务上对GDP-ZERO进行了评估,因该任务具有较高难度的规划要求(Wang等人,2019)。结果表明,无论是静态评估还是交互评估,GDP-ZERO生成的响应都更受欢迎,相比ChatGPT表现更佳。
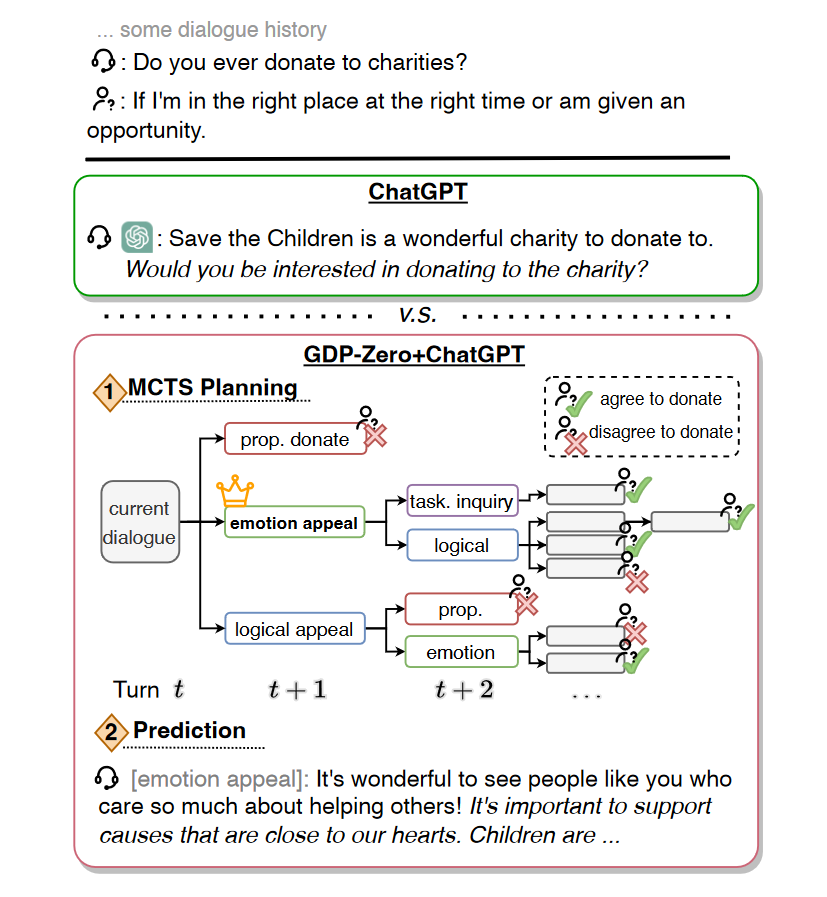
图 1:使用 GDP-ZERO 通过零模型训练进行说服。
方法
在这项工作中,我们引入了GDP-ZERO,这是一种专注于算法的对话策略规划器,适用于像劝说等目标导向的对话任务。GDP-ZERO无需任何模型训练,而是在决策时通过提示大型语言模型(LLM)来模拟用户和系统的响应,评估当前任务的进展,并预测下一个对话行为的先验。基于Chen等人(2023b)的研究成果,我们的方法与现有的策略规划工作有两个主要区别:
- 我们使用少量样例提示(few-shot prompting),以绕过在噪声数据上进行模型训练的需求;
- 我们使用开环蒙特卡洛树搜索(Open-Loop MCTS),通过在树搜索过程中不断重新生成系统和用户的响应,减少模拟过程中累积的错误。
这种方法特别适用于那些数据噪声较大或者资源有限的环境,能够有效提高对话策略的规划能力。
问题定义
为了引入用于对话策略规划的树搜索方法,我们首先将规划表示为马尔可夫决策过程(MDP)。系统和用户之间的一个t轮对话可以表示为:
h = ( a 0 s y s , u 1 s y s , u 1 u s r , . . . , a t − 1 s y s , u t s y s , u t u s r ) h = (a_0^{sys}, u_1^{sys}, u_1^{usr}, ..., a_{t-1}^{sys}, u_t^{sys}, u_t^{usr}) h=(a0sys,u1sys,u1usr,...,at−1sys,utsys,utusr)
其中, a i s y s a_i^{sys} aisys 是第i轮中系统的对话行为, u i s y s u_i^{sys} uisys 是系统的响应, u i u s r u_i^{usr} uiusr 是第i轮中用户的发言。类似于Yang等人(2021)和Wang等人(2020)的工作,我们将规划下一个系统动作 a s y s a^{sys} asys 定义为一个MDP问题 ⟨ S , A , R , P , γ ⟩ \langle S, A, R, P, \gamma \rangle ⟨S,A,R,P,γ⟩。
系统的对话行为 a i s y s a_i^{sys} aisys 表示在第i轮中的动作 a i ∈ A a_i \in A ai∈A,并且对应的对话历史直到第i轮时的状态可以表示为 s i = ( a 0 , u 1 s y s , u 1 u s r , . . . , a i − 1 , u i s y s , u i u s r ) s_i = (a_0, u_1^{sys}, u_1^{usr}, ..., a_{i-1}, u_i^{sys}, u_i^{usr}) si=(a0,u1sys,u1usr,...,ai−1,uisys,uiusr),即 s i ∈ S
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











