







 本文通过Python的sklearn库展示了如何使用CountVectorizer进行词频统计,以及TfidfVectorizer和TfidfTransformer计算TF-IDF权重。TF-IDF是一种文本特征提取方法,它可以反映单词在文档中的重要性。代码示例中,对训练集和测试集的文本进行了处理,转化成词频矩阵和TF-IDF权重矩阵,揭示了不同词汇在文档中的相对重要程度。
本文通过Python的sklearn库展示了如何使用CountVectorizer进行词频统计,以及TfidfVectorizer和TfidfTransformer计算TF-IDF权重。TF-IDF是一种文本特征提取方法,它可以反映单词在文档中的重要性。代码示例中,对训练集和测试集的文本进行了处理,转化成词频矩阵和TF-IDF权重矩阵,揭示了不同词汇在文档中的相对重要程度。
1.fit_transform
1.1CountVectorizer的fit_transform得到的是词频
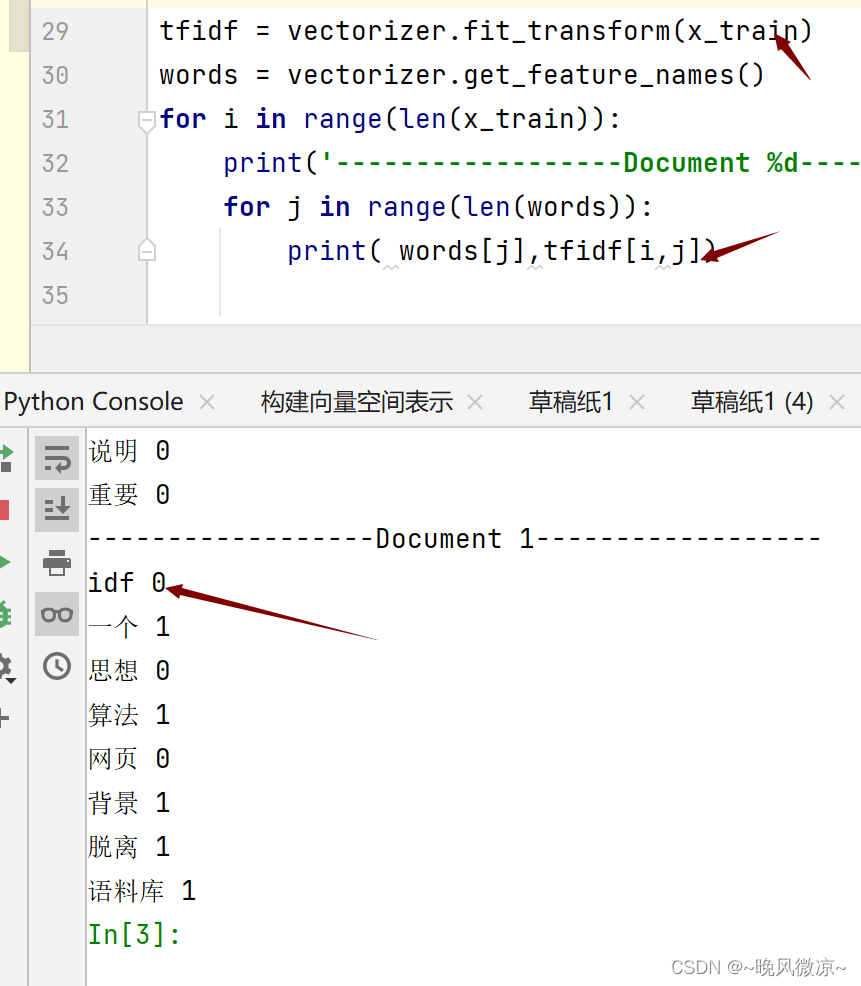
1.2TfidfVectorizer的fit_transform得到的是频率
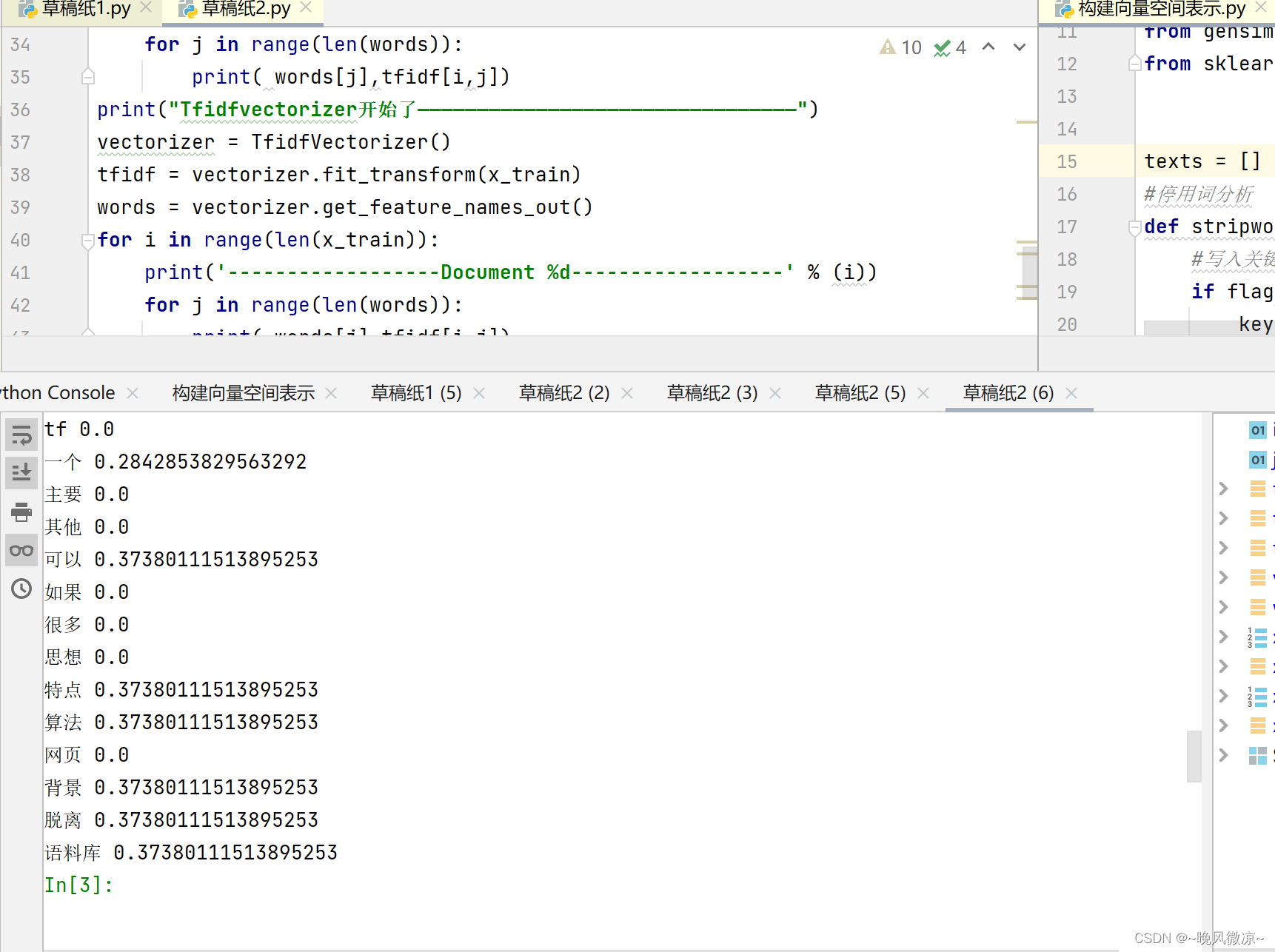
测试代码如下:
import sklearn
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
x_train = ['TF-IDF 主要 思想 是', '算法 一个 重要 特点 可以 脱离 语料库 背景',
'如果 一个 网页 被 很多 其他 网页 链接 说明 网页 重要']
x_test = ['原始 文本 进行 标记', '主要 思想']
# 该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer(max_features=10) #列数为10
# 该类会统计每个词语的tf-idf权值
tf_idf_transformer = TfidfTransformer()
# 将文本转为词频矩阵并计算tf-idf
tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))
# 将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
x_train_weight = tf_idf.toarray()
# 对测试集进行tf-idf权重计算
tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))
x_test_weight = tf_idf.toarray() # 测试集TF-IDF权重矩阵
print('vectorizer.fit_transform(x_train) : ')
print(vectorizer.fit_transform(x_train))
print('输出x_train文本向量:')
print(x_train_weight)
print('输出x_test文本向量:')
print(x_test_weight)
tfidf = vectorizer.fit_transform(x_train)
words = vectorizer.get_feature_names_out()
for i in range(len(x_train)):
print('------------------Document %d------------------' % (i))
for j in range(len(words)):
print( words[j],tfidf[i,j])
print("Tfidfvectorizer开始了————————————————————————————————")
vectorizer = TfidfVectorizer()
tfidf = vectorizer.fit_transform(x_train)
words = vectorizer.get_feature_names_out()
for i in range(len(x_train)):
print('------------------Document %d------------------' % (i))
for j in range(len(words)):
print( words[j],tfidf[i,j])


















 1760
1760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











