







CountVectorizer与TfidfVectorizer,这两个类都是特征数值计算的常见方法。
对于每一个训练文本,CountVectorizer只考虑每种词汇在该训练文本中出现的频率,
而TfidfVectorizer除了考量某一词汇在当前训练文本中出现的频率之外,
同时关注包含这个词汇的其它训练文本数目的倒数。相比之下,训练文本的数量越多,TfidfVectorizer这种特征量化方式就更有优势。
from sklearn.feature_extraction.text import CountVectorizer
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
vectorizer = CountVectorizer( min_df=1, ngram_range=(1, 1) ) # ##创建词袋数据结构,里面相应参数设置
X = vectorizer.fit_transform(corpus) # #拟合模型,并返回文本矩阵
vectorizer.get_feature_names_out() # #显示所有文本的词汇,列表类型
vectorizer.vocabulary_ # #词汇表,字典类型 key: 词,value : 序号索引
X.toarray() # #.toarray() 是将结果转化为稀疏矩阵
print( X ) #文本矩阵 # 对应 上面的系数矩阵的
# (0, 8) 1 表示 (行,列) 词频为1
# 具体代表的是哪个字
# 文本的词汇索引为8 的this 也正好 是 vectorizer.vocabulary_ 中value 为8的 key
print(X.toarray().sum(axis=0)) #统计每个词在所有文档中的词频
## 以上就是 得到 对应词频的 系数矩阵


https://blog.csdn.net/blmoistawinde/article/details/80816179
sklearn: TfidfVectorizer 中文处理及一些使用参数
使用 TfidfVectorizer
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
corpus = [
'This is the first document.',
'This document is the second document.',
'And this is the third one.',
'Is this the first document?',
]
tfidf = TfidfVectorizer( min_df=1, ngram_range=(1, 1) )
features = tfidf.fit_transform(corpus)
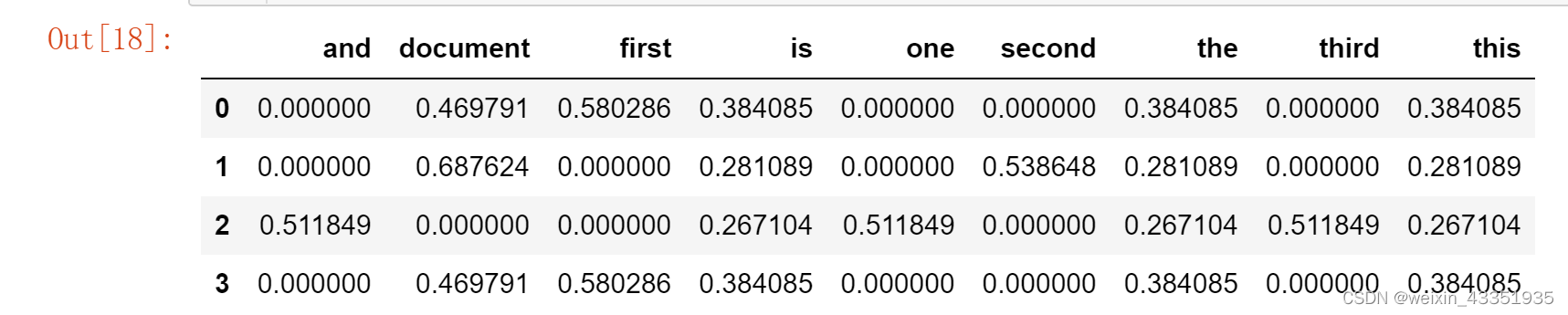
pd.DataFrame(
features.todense(),
columns=tfidf.get_feature_names_out()
)
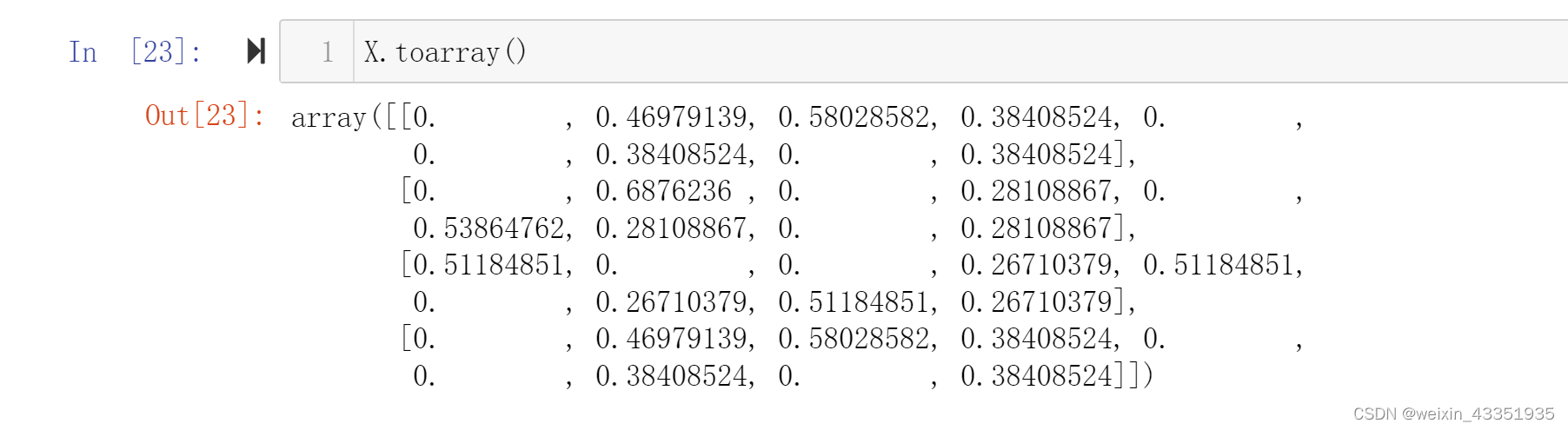
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer( min_df=1, ngram_range=(1, 1) ) # 写参数
X = vectorizer.fit_transform(corpus)
vectorizer.get_feature_names_out()
vectorizer.get_feature_names_out()
X.toarray()

参考学习链接
# https://medium.com/grabngoinfo/topic-modeling-with-deep-learning-using-python-bertopic-cf91f5676504
# BERTopic Topic Modeling with Deep Learning Using Python BERTopic
# https://towardsdatascience.com/a-friendly-introduction-to-text-clustering-fa996bcefd04
# A Friendly Introduction to Text Clustering
# Clustering Product Names with Python — Part 1
## https://towardsdatascience.com/clustering-product-names-with-python-part-1-f9418f8705c8
#Clustering Product Names with Python — Part 2
# https://towardsdatascience.com/clustering-product-names-with-python-part-2-648cc54ca2ac
# https://github.com/Derekkk/Brown-Word-Clustering-and-word-similarity
# http://brandonrose.org/clustering
# Text Analytics for Beginners using Python spaCy Part-2
# https://machinelearninggeek.com/text-analytics-for-beginners-using-python-spacy-part-2/
# https://machinelearninggeek.com/text-classification-using-python-spacy/ 使用文本有监督式 分类
















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











