







一、问题描述
设计C或C++程序,统计在这样的英文文本文件中,出现了多少个单词,每个单词出现了几次。连续的英文字符都认为单词(不包括数字),单词之间用空格或标点符号分隔。
二、需求分析
(1)要统计英文文本文件中出现了哪些单词,就要从文件中读取字符,读取出来的连续英文字符认为是一个单词,遇空格或标点符号单词结束。
(2)使用线性表记录单词以及每个单词出现的次数。线性表中的单词按字典顺序存储。
线性表的顺序存储结构如下:
#define LIST_INIT_SIZE 100 //线性表存储空间的初始分配量
#define LISTINCREMENT 10 //线性表存储空间的分配增量
typedef struct{
char word[21] //存储单词,不超过20个字符
int count; //单词出现的次数
} ElemType;
typedef struct{
ElemType *elem; //存储空间基址
int length; //当前长度
int listsize; //当前分配的存储容量
} Seqlist;
(3)基本操作:
顺序表的初始化:InitList(SqList &L)
顺序表上查找指定的单词:LocateElem(SqList &L,char *s) 。若找到,单词的出现次数增1,返回0,否则返回该单词的插入位置。
在顺序表上插入新的单词:InsertList(SqList &L,int i,char *s) 。要求按字典顺序有序。新单词的出现次数为1.
输出顺序表上存储的单词统计信息:PrintList(SqList &L)。输出文件中每个单词出现的次数以及文件中总的单词数(可输出到文件中)。
(4)统计单词过程如下:
- 输入要统计单词的文本文件名,打开相应的文件;
- 初始化顺序表;
- 从文本文件中读取字符,直到文件结束。具体描述如下:
while (读文件没有结束)
{
过滤单词前的非字母字符;
读取一个单词,以字符串形式存储在一个字符数组中;
在线性表中查找该单词,若找到,单词的出现次数加1,否则返回其插入位置;
上一步中,若没找到,则进行插入操作;
处理下一个单词。
} - 输出统计结果,关闭文件。
三、概要设计
1.设定顺序表的抽象数据类型定义为:
ADT SqList{
数据对象:D={ai|ai∈charset,i=1,2,……,n,n≥0}
数据关系:R1={<ai-1,ai>|ai-1,ai∈D,i=2……,n}
基本操作:
InitList(&L)
操作结果:构造一个空顺序表。
LocateElem(&L, char s)
初始条件:顺序表L已存在。
操作结果:查找指定的单词,若找到,单词的出现次数增1,返回0,否则返回该单词的插入位置。
InsertList(&L,int i,chars)
初始条件:顺序表L已存在。
操作结果:在顺序表上插入新的单词。
PrintList(&L)
初始条件:顺序表已存在。
操作结果:输出文件中每个单词出现的次数以及文件中总的单词数。
3.本程序包含二个模块
1)主程序模块
void main( ){
初始化
打开文本文件
while(字符读取不在文件末尾){
接受命令;
处理命令;
}
}
2)顺序表模块----实现顺序表抽象数据类型
各模块之间的调用关系如下: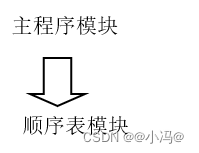
4.查找单词在顺序表中位置的伪算法:
设定当前位置的初值为入口位置;
while(单词没有比较完毕){
若和顺序表是相同单词,则
{把该单词数量+1}
反之,若该单词在字典相对位置靠前,则
{顺序表就往前移动一位}
若单词在字典位置相对靠后,则
{顺序表就往后移动一位}
}
返回该单词所在位置,或者作为新单词插入的位置
四、详细设计
1.单个单词的类型
typedef struct{
char word[21];//存储单词,不超过 20 个字符
int count; //单词出现的次数
} ElemType;
2.顺序表类型
typedef struct{
ElemType *elem; //存储空间基址
int length; //当前长度
int listsize; //当前分配的存储容量
} SqList;
int InitList(&L)
//构造一个空顺序表
//若构造成功则返回1
int LocateElem(&L, char *s)
//查找指定的单词
//若找到,单词的出现次数增1,返回0,否则返回该单词的插入位置。
int InsertList(&L,int i,char*s)
//在顺序表上插入新的单词
//插入成功则返回1
int PrintList(&L)
//输出文件中每个单词出现的次数以及文件中总的单词数到新的文件中
3. 统计文本单词数量的伪算法
//顺序表的初始化
Status InitList(SqList &L){
//构造一个空的线性表L
L.elem=(ElemType*)malloc(LIST_INIT_SIZE*sizeof(ElemType));
if(!L.elem) exit(0);//存储分配失败
L.length = 0;//空表长度为0
L.listsize = LIST_INIT_SIZE;//初始化容量
return 初始化成功;
}
//顺序表上查找指定的单词
Status LocateElem(SqList &L,char *s){
int low, mid, high;
low = 0; high = L.length-1 ;//定义顺序表的最高和最低位置
while (low<=high)//进行二分查找
{
mid = (low + high) / 2;
// 使用strcmp()比较 两个单词是否相等
if (单词相等) {
L.elem[mid].count++; return 0;
}
else if (不相等且字典位置靠前)
high = mid - 1;
else
low = mid + 1;
return单词的插入位置;
}
//在顺序表上插入新的单词
Status InsertList(SqList &L,int i,char *s){
int j;
ElemType *base; //定义一个指针用于查询
if(L.length>=L.length){
//使用 realloc函数扩大内存块
base=(ElemType*)realloc(L.elem,(L.listsize+LISTINCREMENT)*sizeof(ElemType));
if(内存扩大失败)
return 0;
//线性表存储空间增加10
L.listsize=L.listsize+LISTINCREMENT;
L.elem=base;
}
for (j = L.length; j >= i; j--)
L.elem[j] = L.elem[j-1];
//将传进来的单词复制到顺序表
strcpy(L.elem[i-1].word,s);
//将新传进来的单词次数置为一
L.elem[i - 1].count = 1;
//顺序表长度+1
L.length++;
return 插入成功;
}
//输出顺序表上存储的单词统计信息
Status PrintList(SqList &L,int num){
int i;
int no=num;
//定义文件指针
FILE *fw;
//新建一个 lcc.txt文件用于存放结果;
fw=fopen("D:\\test.txt","w");
for (i = 0; i < L.length; i++) {
//磁盘文件的写入
fprintf(fw,"%s %d\n",L.elem[i].word,L.elem[i].count);
}
fprintf(fw,"单词数量%d",num);
//关闭磁盘文件
fclose(fw);
return 打印成功;
}
4.主函数的伪算法
main(){
void Initialization()
{ //系统初始化
SqList L;
char s[21],ch,filename[30],filename1[50];
int num=0,j=0,mark=0,i;
//创建文件指针
FILE *fp;
//初始化顺序表
InitList(L);
}//Initialization
void ReadCommand(char &cmd)
{ //读入操作命令符
//读入将要扫描的文件名
scanf("%s",filename);
//将文件路径+文件名赋值给 filename1
sprintf(filename1,"D:\\ProgramData\\vs\\%s.txt",filename);
getchar();//取得文件路径及文件名
}//ReadCommand
void Interpret(char cmd)
{//解释执行操作命令
if((fp=fopen(filename1,"r"))==NULL){//判断文件是否存在
printf("文件路径错误\n"); }
ch=fgetc(fp);
//从文本文件中读取字符,直到文件结束。
while (单词没读取完毕){
//过滤单词前的非字母字符;
if (ch >= 'a'&&ch <= 'z'||ch>='A'&&ch<='Z') {
//将大小写合并(题中不区分大小写)
ch = ch >= 'A'&&ch <= 'Z' ? ch + 32 : ch;
s[j++] = ch;
//标识单词
mark = 1;
}else {
if (mark == 1)
{
s[j] = '\0';
mark = 0;
num++;
j = 0;
//查找单词
i = LocateElem(L, s);
if (i > 0)
InsertList(L,i,s);
}
}
//从磁盘中读取一个字符并返回
ch = fgetc(fp);
}
//写入文件
PrintList(L,num);
printf("扫描成功\n");
}//InterPret
5.函数的调用关系图反映了演示程序的层次结构: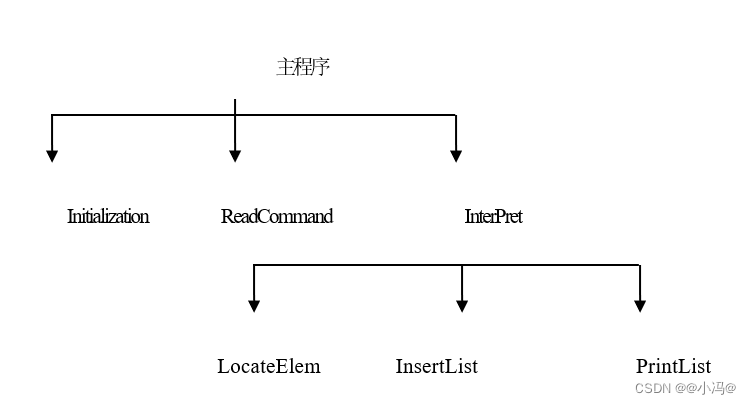
五、功能实现(用C或C++语言描述)
#include<bits/stdc++.h>
using namespace std;
#define LIST_INIT_SIZE 100 //线性表存储空间的初始分配量
#define LISTINCREMENT 10 //线性表存储空间的分配增量
typedef struct{
char word[21];//存储单词,不超过 20 个字符
int count; //单词出现的次数
} ElemType;
typedef struct{
ElemType *elem; //存储空间基址
int length; //当前长度
int listsize; //当前分配的存储容量
} SqList;
//顺序表的初始化
int InitList(SqList &L){
//构造一个空的线性表L
L.elem=(ElemType*)malloc(LIST_INIT_SIZE*sizeof(ElemType));
if(!L.elem) exit(0);//存储分配失败
L.length = 0;//空表长度为0
L.listsize = LIST_INIT_SIZE;//初始化容量
return 1;
}
//顺序表上查找指定的单词
int LocateElem(SqList &L,char *s){
int low, mid, high;
low = 0; high = L.length-1 ;//定义顺序表的最高和最低位置
while (low<=high)//进行二分查找
{
mid = (low + high) / 2;
// 使用strcmp()比较 两个单词是否相等
if (strcmp(s, L.elem[mid].word) == 0) {
L.elem[mid].count++; return 0;
}
else if (strcmp(s, L.elem[mid].word) < 0)
high = mid - 1;
else
low = mid + 1;
}
//返回该单词的插入位置
return low + 1;
}
//在顺序表上插入新的单词
int InsertList(SqList &L,int i,char *s){
int j;
ElemType *base; //定义一个指针用于查询
if(L.length>=L.length){
//使用 realloc函数扩大内存块
base=(ElemType*)realloc(L.elem,(L.listsize+LISTINCREMENT)*sizeof(ElemType));
if(base==NULL)
return 0;
//线性表存储空间增加10
L.listsize=L.listsize+LISTINCREMENT;
L.elem=base;
}
for (j = L.length; j >= i; j--)
L.elem[j] = L.elem[j-1];
//将传进来的单词复制到顺序表
strcpy(L.elem[i-1].word,s);
//将新传进来的单词次数置为一
L.elem[i - 1].count = 1;
//顺序表长度+1
L.length++;
return 1;
}
//输出顺序表上存储的单词统计信息
int PrintList(SqList &L,int num){
int i;
int no=num;
//定义文件指针
FILE *fw;
//新建一个 lcc.txt文件用于存放结果;
fw=fopen("D:\\test.txt","w");
for (i = 0; i < L.length; i++) {
//磁盘文件的写入
fprintf(fw,"%s %d\n",L.elem[i].word,L.elem[i].count);
}
fprintf(fw,"单词数量%d",num);
//关闭磁盘文件
fclose(fw);
return 1;
}
int main(){
SqList L;
char s[21],ch,filename[30],filename1[50];
int num=0,j=0,mark=0,i;
//创建文件指针
FILE *fp;
//初始化顺序表
InitList(L);
//读入将要扫描的文件名
cout<<"请输入文件名字"<<endl;
scanf("%s",filename);
//将文件路径+文件名赋值给 filename1
sprintf(filename1,"D:\\ProgramData\\vs\\%s.txt",filename);
getchar();//取得文件路径及文件名
if((fp=fopen(filename1,"r"))==NULL){//判断文件是否存在
printf("文件路径错误\n");
getchar();
exit(0);
}
ch=fgetc(fp);
//从文本文件中读取字符,直到文件结束。
while (ch != EOF){
//过滤单词前的非字母字符;
if (ch >= 'a'&&ch <= 'z'||ch>='A'&&ch<='Z') {
//将大小写合并(题中不区分大小写)
ch = ch >= 'A'&&ch <= 'Z' ? ch + 32 : ch;
s[j++] = ch;
//标识单词
mark = 1;
}else {
if (mark == 1)
{
s[j] = '\0';
mark = 0;
num++;
j = 0;
//查找单词
i = LocateElem(L, s);
//cout<<"查找单词:"<<i<<endl;
if (i > 0)
InsertList(L,i,s);
}
}
//从磁盘中读取一个字符并返回
ch = fgetc(fp);
}
//写入文件
PrintList(L,num);
printf("扫描成功\n");
system("pause");
return 0;
}
六、程序测试及运行结果
单词统计程序测试及运行结果如下: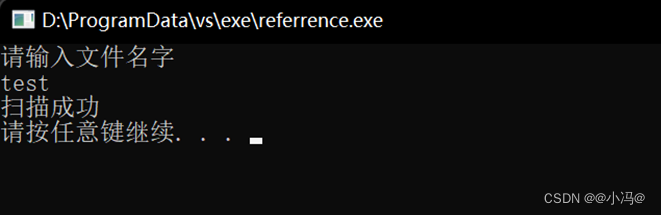
输出文件的位置是:D:\test.txt
七、心得体会
1、该题使用了FILE文件读取中的fget()方法读取文件中的内容,结束标志是fget()==EDF,因为一个单词在不同的位置可能大写可能小写,但是他们是同一个单词,为了进行区分,我将单词全部转化成了小写的方式,这样判断单词是否为同一个的时候就不会失误了,同时用printList()输出的时候,用了FILE里面的fprintf()打印内容到新文件中,文件内容由遍历顺序表得到。
2、在往顺序表中插入单词的时候不知道如何按照字典顺序给单词排顺序,但其实strcmp()方法就可以实现这个功能,用此方法从依次比较单个单词的时候,会按照字典顺序比较,第一个字符的在第二个字符的前面时,返回的的值是复数,绝对值大小是他们之间相差了几位,反之是大于零,绝对值大小亦然,如果相同的话返回0
3、这个程序可以从控制端输入文件名称打开,方便我们也可以直接用fOpen()打开目的文件
4、本题中三个主要算法:InitList的时间复杂度为0(1)和LocatElem的时间复杂度为0(log n),inserList的时间复杂度为0(n),printList的时间复杂度为0(n),本题的空间复杂度亦为0(1)
5、经验体会:借助DEBUG调试器和数据观察窗口,可以加快找到程序中疵点。
















 3623
3623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











