







1.Inception v2改进策略
(1)卷积核分解5*5——3*3
从计算代价上考虑,更大的卷积核(比如5x5或者7x7)计算代价的增长具有不对称性。比如,5x5滤波器参数量是3x3滤波器参数量的25/9=2.78倍。当然,在网络的前几层,5x5的卷积核可以获得更大的视野范围,以及获取空间信息之间的相关性,所以降低卷积核大小的代价会降低网络的表达能力。当然,我们是不是可以用多层的网络(参数更少)代替5x5卷积层,并且保持输入和输出的大小不变。如果我们放大5x5的卷积计算图,我们可以看到,每一个输出相当于一个在5x5卷积核上滑动的全连接网络,见图1所示:
由于我们试图创建一个视觉网络,很自然地,我们会利用图像平移不变性, 用两层的卷积结构代替全连接模块:第一层是3x3卷积,第二层是连接在第一层的全连接层。因此,滑动第二层,等同与用两个3x3的卷积核代替5x5的卷积核,参考如下图4和图5:


(2)卷积核分解5*5——3*3
上 述的结果表明,由于任何大的卷积核都可以分解为3x3的卷积核,那么大于3x3的滤波器似乎没有什么意义。那么,我们仍然有一个疑问,是否需要将大卷积核分解为更小的卷积核,比如2x2的卷积核。但是,实时证明,非对称卷积核由于小的2x2卷积核,比如Nx1。 例如,3x1conv + 1x3conv等价于一个3x3conv的视野范围,见图3;在输入和输出等同的情况下,参数降低33%,。作为对比,将3x3卷积核分解为两个2x2卷积核,只是降低了11%.

理论上,往更深的讨论,我们可以分解大小为NxN卷积核为1xN以及Nx1,N越大,参数量更少,节约更多的计算资源,见图6,实际中,在网络的前几层分解并不会有很好的效果,在中等feature map大小的图上有更好的效果(比如m x m 特征图,m范围在12-20之间)。这种层面上,1x7conv+7x1conv会有更好的结果。

(3)辅助分类器的设置
GoogLeNet引入了辅助分类器的概念,它可以提高网络的收敛能力。最初的动机是为了将有用的梯度反向传递到网络低层,也是为了解决梯度消失的问题,保证网络训练正常进行。Lee表明,辅助分类器促进网络训练的稳定以及更好的收敛。有趣的是,我们发现辅助分类器并不能保证收敛更快:实验表明,有无辅助分类器,训练过程基本保持一致。在训练的最后阶段,有辅助分类器略微高于无辅助分类器的网络。
GoogLeNet在不同的阶段使用了两个辅助分类器,移除网络低层的辅助分类器并不会对网络的最终性能有影响。根据当时实验的观察,最初GoogLeNet的辅助分支有助于低层特征学习的假设可能不太合适。相反地,如果在辅助分类器添加BN或者添加Dropout后,主分类器表现更好,所以我们认为辅助分类器更像是正则化的作用。也进一步推测,BN更像是个正则项。
(4)有效减少网格大小
传统上,卷积网络使用池化操作降低特征图的大小。为了避免表达瓶颈(representational bottleneck),在使用最大或者均值池化,先将其维度扩大。比如,假设有k个滤波器,大小为dxd,如果要得到d/2 x d/2的大小,个数为2k的滤波器,我们首先要计算滑动为1,个数为2k的卷积运算,然后添加池化操作。那么额外的计算代价就是卷积的操作,总共操作为(d*d*k)*2*k。一个可能性是:pooling+conv,那么总共操作为(d/2*d/2*k)*2k,降低了1/4的代价。但是,这会将表达维度降低为(d/2*d/2)*k,可能会导致更低的网络表达能力,见图9;那么另一种既可以降低计算代价,又可以消除表达瓶颈的操作,见图10;我们可以使用两个并行的,滑动为2的模块:P和C。P是Pool层(最大或者平均),他们滑动距离均为2,最终进行合并。

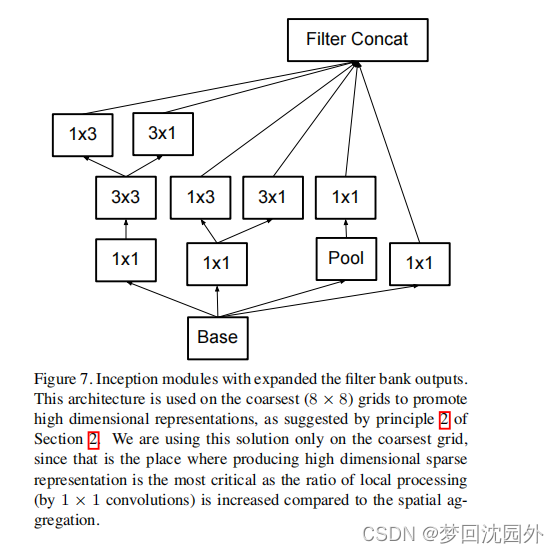
(4)Inception v2结构
基于上面的讨论,我们提出了新的网络架构,网络的具体见表1。值得注意的是,根据3.1的讨论,我们将7x7卷积分解为3个3x3卷积。对于Inception模块,我们是使用了3个传统的Inception模块,输入大小为35x35,288(见表1),维度被降为17*17,大小为768(见Section 5)。然后紧跟5个分解的Inception模块,见图5。参考图10,将其维度降为8x8x1280。这样将两个Inception模块连接为2048的数量。详细的Inception结构信息,在补充材料中(model.txt)。但是,我们观察到,如同准则2描述的,网络的性能相对是稳定的。尽管我们的网络有42层,但是计算代价比GoogLeNet2.5倍,仍比VGG效率高。
2.Inception v3改进策略
(1)更新优化算法,用RMSProp代替SGD
SGD是一种比较单纯的算法,下式为SGD的参数更新方式:
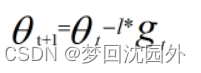
然而,学习率不应该是全局的。每个参数都应该有一个合适的学习率,从而使参数中那些梯度方向变化不大的维度加速更新。因此,RMSProp算法增加了累积项,让历史梯度也能够以一定的权重参与习率的变化。
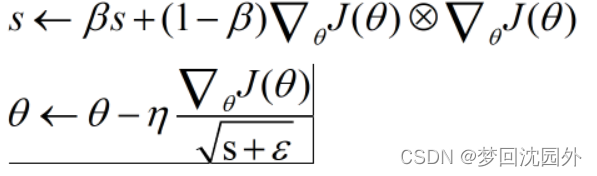
(2) 标签平滑化
通过模型得到的样本是包含标签的。在一般的模型训练中,都认为标签是正确的。不过,在少数情况下,标签有可能是错误的,而这会对模型的训练产生负影响。为了减小由标签错误引起的负影响,GoogLeNet团队采用了标签平滑处理的方法。
样本的损失函数定义为如式3.11所示的交叉嫡。对于某个类别,它的标签kE(0,1)(k)是模型对标签k计算得到的概率,q(k)是标签样本的真实分布。在标签正确的前提下,q(k)=1。如果标签可能有错误,则q(k)<1。
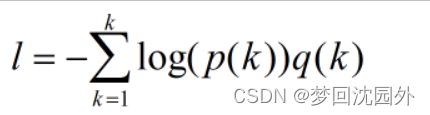
标签平滑化针对标签样本的真实分布q(k),使得其输出不再是纯粹的1或0,而是接近1的0.8或0.88、接近0的0.1或0.11,以实现标签平滑化。假设有一个真实的标签y,它使得q(y)=1,而标签k的q(k)=0。对于这个表达,可以采用狄拉克函数来表示:当k=y时,
=1;否则,
=0。
设定一个错误率c,表示某一标签有误的概率,因此有式3.12。其中,u(k)表示固定分布,建议将其设置为标签的先验分布。GoogLeNet 团队采用了均匀分布.
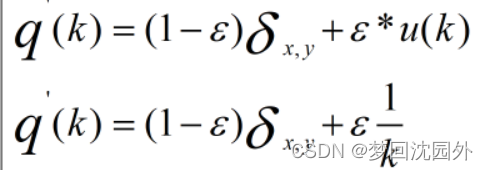
若标签为真,那么。因为
通常很小,所以(
→0,最终使
→1。当标签为假时,亦可推得
→0。最后,用
代替
,得下式 ,实现了标签平滑化,从而避免了过拟合的出现和模型适应能力的降低。
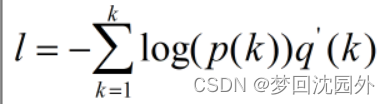
(3)在辅助分类器的全连接层后添加批标准化操作
批标准化参见我的上一篇博客
参考博客:https://blog.csdn.net/kxh123456/article/details/102676054

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











