







由于论文写得比较抽象,偏向于数学,因此,在开篇首先谈谈我自己对MAML的理解,在后面再简要的抽取一下论文的核心部分
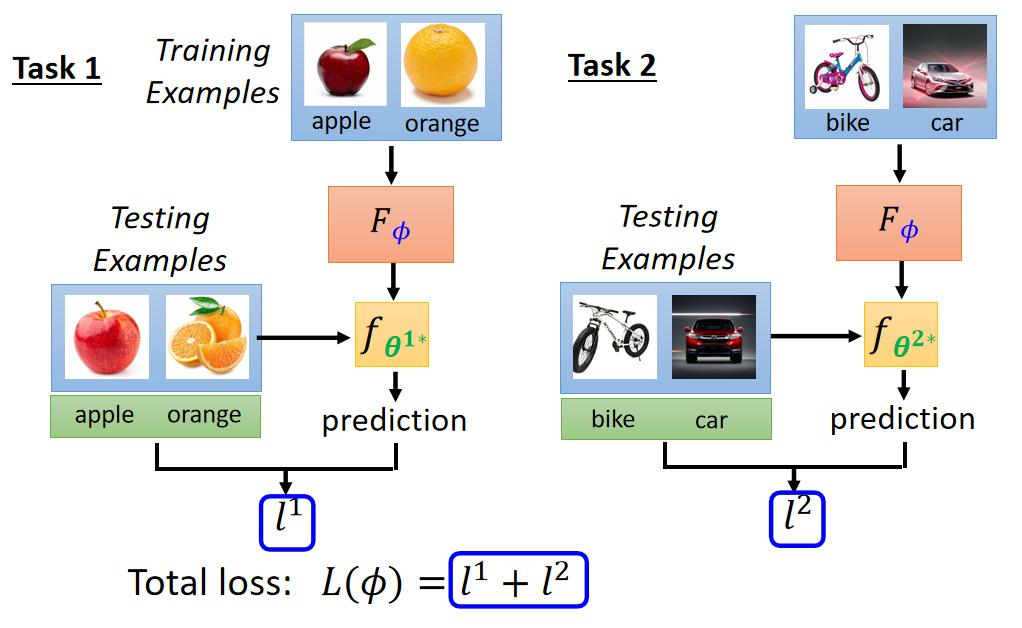
元学习解决的问题
首先,对于深度学习领域,模型初始化的权重参数尤为重要,模型参数初始化也会对性能造成很大的影响。
对于小样本数据而言,拟合效果差,一方面是数据的影响,模型没有办法拟合得很好,还有就是参数初始化的影响,模型在这个初始化参数下无法收敛得很好,这就是元学习要解决的问题
也就是说,元学习想要寻找一个学习能力极强的初始化权重参数,在这个权重参数下,模型在新任务都能拟合得很好。
那么,怎么样找到一个学习能力极强的初始化权重参数呢?我们在多个子任务下进行进行训练,并进行测试,最终返回多个子任务下的测试损失,我们尝试去最小化这些测试损失,并进行参数更新,让这组初始化参数在多个子任务上都表现得很好,那么我们就找到了一组学习能力极强的初始化权重参数
与预训练权重的区别:
预训练模型打前期,看重的是模型在当前数据集上表现得很好,而元学习是通过模型在多个task进行训练测试,找到一组较好的初始化权重参数。MAML是一整套完整的训练流程,不仅要找到较好的模型初始化参数,而且不断的对参数进行优化。
MAML的流程:
- 前提:数据能够采样,能够通过采样生成许多子任务。α,β是学习率
-
1.随机初始化当前模型权重参数
-
2,3.采 样得到每一个任务
-
计算在当前任务上的权重更新,并进行梯度下降,对子任务的参数进行更新,需要注意的是此时权重更新是根据测试的损失
-
迭代每一个子任务,并在子任务上进行参数更新
-
最终我们需要得到的是总任务的参数,根据这些子任务的更新,再更新权重Θ

Abstract
我们提出了一种与模型无关的元学习算法,在这个意义上,它与任何经过梯度下降训练的模型兼容,并适用于各种不同的学习问题,包括分类、回归和强化学习。元学习的目标是在各种学习任务上训练一个模型,这样它就可以只使用少量的训练样本来解决新的学习任务。在这种方法下,模型的参数被明确地训练,这样少量的梯度步长和来自新任务的少量训练数据将在该任务上产生良好的泛化性能。实际上,我们的方法训练的模型易于微调。我们证明了这种方法在两个少样本图像分类基准上具有最先进的性能,在少样本回归上产生了良好的结果,并加速了使用神经网络策略对策略梯度强化学习的微调。
1. Introduction
在这项工作中,我们提出了一个通用的元学习算法,它是模型不可知的,在这个意义上,它可以直接应用于任何学习问题和模型训练的梯度下降程序。我们的重点是深度神经网络模型,但我们说明了我们的方法如何可以轻松地处理不同的架构和不同的问题设置,包括分类、回归和策略梯度强化学习,以最小的修改。在元学习中,训练模型的目标是从少量的新数据中快速学习新任务,并由元学习者训练模型,使其能够学习大量不同的任务。我们的方法的关键思想是训练模型的初始参数,以便通过一个或多个新任务的梯度步骤更新参数后,模型在新任务上具有最大的性能。与之前学习更新函数或学习规则的元学习方法不同,我们的算法不扩大参数的学习数量,也不对模型架构施加约束,并且它可以很容易地与完全连接、卷积或循环神经网络结合。它还可以用于各种损失函数,包括可微监督损失和不可微强化学习目标。
训练模型参数的过程,如几个梯度步骤,甚至单个梯度步骤,可以在新任务上产生良好的结果,从特征学习的角度来看,这是构建一个广泛适用于许多任务的内部表示。如果内部表示适合于许多任务,那么简单地对参数进行轻微的微调(例如,通过主要修改前馈模型中的顶层权重)就可以产生良好的结果。实际上,我们的程序优化了易于快速微调的模型,允许在正确的空间进行快速学习。从动力系统的角度来看,我们的学习过程可以被看作是最大限度地提高新任务的损失函数对参数的敏感性:当敏感性高时,参数的小的局部变化可以导致任务损失的很大的改进。
2. Model-Agnostic Meta-Learning
2.1. Meta-Learning Problem Set-Up
假设多个任务T服从任务p (T),每个任务由从各个类别
采样K个样本组成。在元训练期间,用任务
的数据进行训练,并在
的新样本上进行测试,测试损失
就代表训练损失,然后根据梯度下降对子任务参数参数进行更新。在元训练结束时,从p(T)中采样新任务,从K个样本中学习后模型的性能来衡量元性能。一般来说,元测试的任务是在元训练期间进行的。
2.2. A Model-Agnostic Meta-Learning Algorithm
这种方法的目标是 找到模型参数敏感任务的变化,当改变方向的损失梯度(见图1)的方向时,这样小变化参数将产生大改进的损失函数从p(T)。同时对模型的形式不做任何假设,只是假设它由一些参数向量θ参数化,并且损失函数在θ中足够平滑,可以使用基于梯度的学习技术。这样一个神经网络可能会学习到广泛适用于p(T)中的所有任务的内部特征,而不是一个单一的单个任务。
形式上,考虑一个由参数为θ的参数化函数表示的模型。当适应一个新的任务Ti时,模型的参数θ变为
。更新的参数向量
在一个或多个子任务中进行梯度下降更新。例如,当使用一个梯度更新时(α)表示学习率:
![]()
模型参数是通过优化从p(T)采样的任务来训练的。更具体地说,元目标如下:
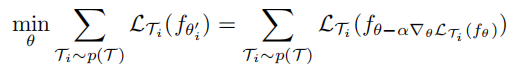
请注意,元优化是在模型参数θ上执行的,而目标是使用更新的模型参数θ来计算的。实际上,MAML旨在优化模型参数,使一个新任务上的一个或少量的梯度步骤将在该任务上产生最大有效的行为。 (意思就是实际上只在任务结束后对参数θ进行优化,子任务Ti上只是参数更新产生的中间结果)
通过随机梯度下降(SGD)进行跨任务的元优化,使模型参数θ更新如下:(损失为子任务上各个测试损失之和,β为学习率)

MAML元梯度更新涉及到一个通过梯度的梯度。在计算上,需要反向传播Hessian矩阵,这有标准的深度学习库的支持。同时,作者还比较了放弃计算Hessian矩阵,进行一阶近似。

3. Species of MAML
分类、回归、强化学习只是损失函数不同,整体流程还是上面
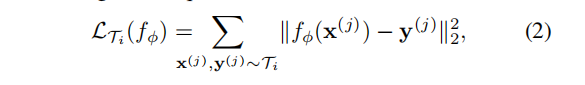
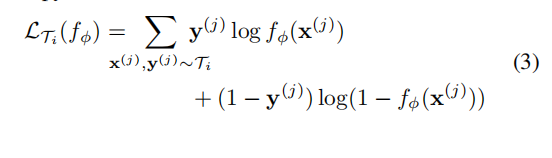
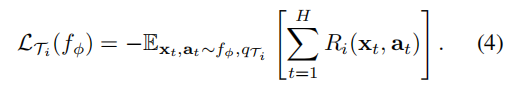


















 1682
1682











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











