







概述
神经网络由大量的人工神经元联结进行计算。
神经网络是一种运算模型,由大量的节点(或称“神经元”)和之间相互的联接构成。每个节点代表一种特定的输出函数,称为激励函数、激活函数(activation function)。每两个节点间的联接都代表一个对于通过该连接信号的加权值,称之为权重,这相当于人工神经网络的记忆。网络的输出则依网络的连接方式,权重值和激励函数的不同而不同。
PyTorch的基础
导入的包
import torch
from torch import nn
from torch.nn import functional as F
torch是一个广泛支持机器学习算法的科学计算框架。
torch中的nn包含了Module等重要的类,能够更好的来帮助我们创建和训练神经网络。
nn中的functional包含了众多激活函数。
Module
torcn.nn是专门为神经网络设计的模块化接口。nn构建于autograd之上,可以用来定义和运行神经网络。
nn.Module是nn中十分重要的类,包含网络各层的定义及forward方法。
自定义块就需要继承Module。
激活函数
因为线性模型的表达能力不够,引入激活函数是为了添加非线性因素。
每一层的输出通过这些激活函数之后,就变得比以前复杂很多,从而提升了神经网络模型的表达能力。
nn和functional 下都带有激活函数,Sequential中使用functional 下的激活函数。
各个激活函数用于不同的场景。
常见的有以下几种激活函数。
- ReLU
- Sigmoid
- Tanh
- Softplus
Sequential
其实是所谓的容器(container),用来存储网络的层。
nn.Sequential 中的层是有顺序的,而且严格按照其顺序执行,相邻两个层连接必须保证前一个层的输出与后一个层的输入相匹配。functional 中的激活函数即可放入其中。
Sequential中也可以嵌套Sequential,实现多重网络。
Linear
在神经网络中常常是用来对矩阵进行线性变换的一个类。
下面是实现线性变换的公式。
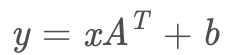
Parameter
可以把这个函数理解为类型转换函数。
其作用是将一个不可训练的类型为Tensor的参数转化为可训练的类型为parameter的参数,并将这个parameter绑定到这个module里面,成为module中可训练的参数。
模型构造
层和块
对于多层感知机而言,整个模型做的事情就是接收输入生成输出。但是并不是所有的多层神经网络都一样,所以为了实现复杂的神经网络就需要神经网络块,块可以描述单个层、由多个层组成的组件或整个模型本身。使用块进行抽象的一个好处是可以将一些块组合成更大的组件。
下面是一个多层感知机。
import torch
from torch import nn
from torch.nn import functional as F
net = nn.Sequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10)) #
X = torch.rand(2, 20)
net(X)
这个多层感知机包含一个具有256个单元和ReLU激活函数的全连接的隐藏层,然后是一个具有10个隐藏单元且不带激活函数的全连接的输出层。
nn.Sequential定义了一种特殊的Module,即在PyTorch中表示一个块的类。
运行结果:
自定义块
定义一个Module的子类,通过super().init()调用父类的__init__函数。
之后重写forward函数。
示例代码:
下面是一个自定义多层感知机。
class MLP(nn.Module):
def __init__(self):
super().__init__()
self.hidden = nn.Linear(20, 256)
self.out = nn.Linear(256, 10)
def forward(self, x):
return self.out(F.relu(self.hidden(x)))
net = MLP()
net(X)
这里包含了一个隐藏层,一个输出层,在forward函数中用relu激活函数激活,通过输出层输出,返回结果。
运行结果:

顺序块
示例代码:
这里是一个自己定义的简化版Sequential类。
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for block in args:
self._modules[block] = block
def forward(self, x):
for block in self._modules.values():
x = block(x)
return x
net = MySequential(nn.Linear(20, 256), nn.ReLU(), nn.Linear(256, 10)) # MySequential的使用和Sequential的使用类似。
net(X)
在__init__函数中,将传入的层,按顺序放入_modules这个字典中,在forward,通过for循环,按顺序执行传进来的参数包含的操作,执行完毕后返回结果。
运行结果:

在正向传播函数中执行代码
继承Module的子类可以做更多灵活的计算。
当Sequential这个类不能完全满足需求的时候,在__init__和forward函数中可以做大量的自定义的计算。
示例代码:
class FixHiddenMLP(nn.Module):
def __init__(self):
super().__init__()
self.rand_weight = torch.rand((20, 20), requires_grad=False)
self.linear = nn.Linear(20, 20)
def forward(self, x):
x = self.linear(x)
x = F.relu(torch.mm(x, self.rand_weight 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 816
816











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









