






哈希表的基本原理
哈希表可以理解为一个加强版的数组。
数组可以通过索引(非负整数)在 O(1) 的时间复杂度内查找到对应元素。
哈希表是类似的,可以通过 key 在 O(1) 的时间复杂度内查找到这个 key 对应的 value。key 的类型可以是数字、字符串等多种类型。
怎么做的?特别简单,哈希表的底层实现就是一个数组(我们不妨称之为 table)。它先把这个 key 通过一个哈希函数(我们不妨称之为 hash)转化成数组里面的索引,然后增删查改操作和数组基本相同:
#include <iostream>
#include <vector>
#include <list>
#include <string>
// 哈希表的大小,可以根据需要进行调整
const int TABLE_SIZE = 100;
// 哈希表中每个节点的结构体
template<typename K, typename V>
struct HashNode {
K key;
V value;
HashNode(K k, V v) : key(k), value(v) {}
};
// 哈希表类
template<typename K, typename V>
class HashMap {
private:
// 使用链表解决哈希冲突
std::vector<std::list<HashNode<K, V>>> table;
// 哈希函数,根据键值生成哈希码
int hash(const K& key) {
// 这里简单地模拟了一个哈希函数,可以根据实际情况修改
return std::hash<K>{}(key) % TABLE_SIZE;
}
public:
HashMap() : table(TABLE_SIZE) {}
// 插入或修改键值对
void put(const K& key, const V& value) {
int index = hash(key);
for (auto& node : table[index]) {
if (node.key == key) {
node.value = value;
return;
}
}
table[index].emplace_back(key, value);
}
// 根据键查找对应的值
V get(const K& key) {
int index = hash(key);
for (auto& node : table[index]) {
if (node.key == key) {
return node.value;
}
}
// 如果没有找到对应的键,则返回默认值
return V();
}
// 根据键删除对应的键值对
void remove(const K& key) {
int index = hash(key);
table[index].remove_if([&key](const HashNode<K, V>& node) {
return node.key == key;
});
}
};
int main() {
HashMap<std::string, int> hashMap;
// 插入键值对
hashMap.put("apple", 5);
hashMap.put("banana", 10);
hashMap.put("orange", 15);
// 获取键对应的值
std::cout << "Value for 'apple': " << hashMap.get("apple") << std::endl;
std::cout << "Value for 'banana': " << hashMap.get("banana") << std::endl;
// 删除键值对
hashMap.remove("apple");
std::cout << "Value for 'apple' after removal: " << hashMap.get("apple") << std::endl;
return 0;
}
几个关键概念及原理
key 是唯一的,value 可以重复
数组里面每个索引都是唯一的,不可能说你这个数组有两个索引 0。
哈希函数
哈希函数的作用是把任意长度的输入(key)转化成固定长度的输出(索引)。
增删查改的方法中都会用到哈希函数来计算索引,如果你设计的这个哈希函数复杂度是 O(N),那么哈希表的增删查改性能就会退化成 O(N),所以说这个函数的性能很关键。
这个函数还要保证的一点是,输入相同的 key,输出也必须要相同,这样才能保证哈希表的正确性。
哈希冲突
上面给出了 hash 函数的实现,那么你肯定也会想到,如果两个不同的 key 通过哈希函数得到了相同的索引,怎么办呢?这种情况就叫做「哈希冲突」。
一定会出现哈希冲突的,因为这个 hash 函数相当于是把一个无穷大的空间映射到了一个有限的索引空间,所以必然会有不同的 key 映射到同一个索引上。
出现哈希冲突的情况怎么解决?两种常见的解决方法,一种是拉链法,另一种是线性探查法(也经常被叫做开放寻址法)。
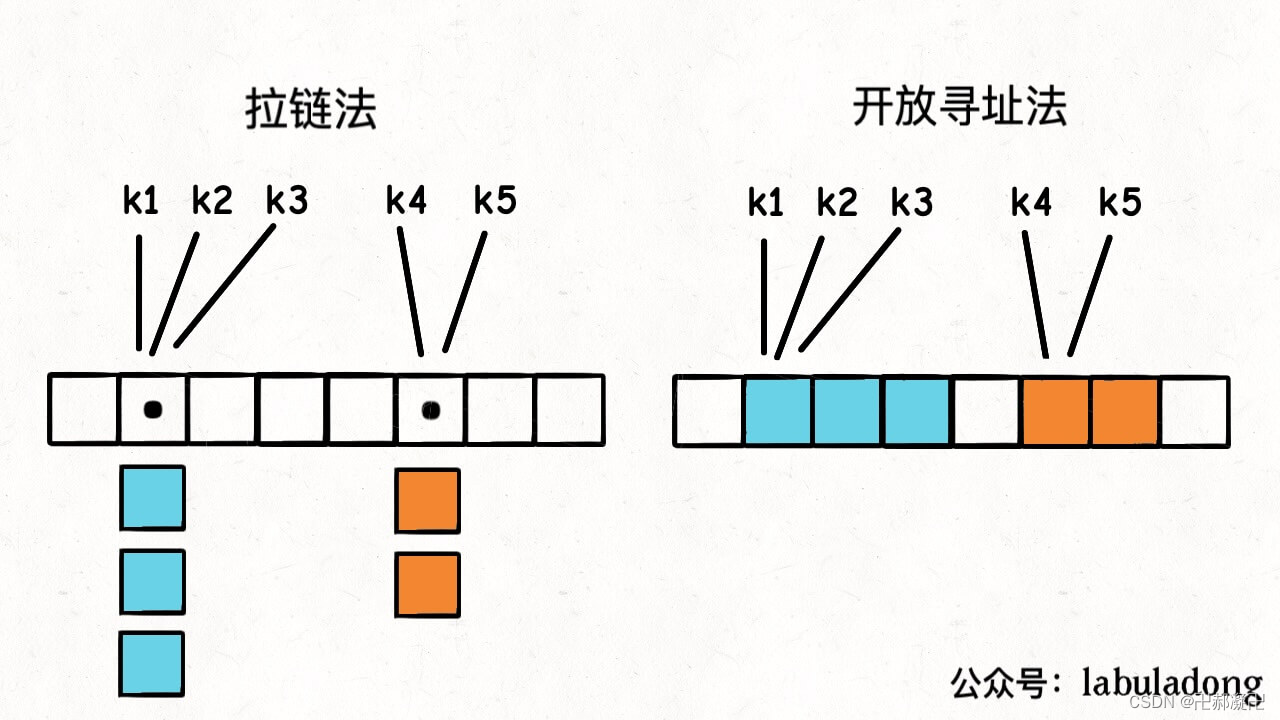
拉链法相当于是哈希表的底层数组并不直接存储 value 类型,而是存储一个链表,当有多个不同的 key 映射到了同一个索引上,这些 key -> value 对儿就存储在这个链表中,这样就能解决哈希冲突的问题。
而线性探查法的思路是,一个 key 发现算出来的 index 值已经被别的 key 占了,那么它就去 index + 1 的位置看看,如果还是被占了,就继续往后找,直到找到一个空的位置为止。















 672
672

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









