









yolo是目标检测模型(you only look once)的简称,典型的一阶段目标检测网络
1. yolo v1
1.1 思想
不同于之前二阶段目标检测网络使用分类的想法,yolo则是将目标检测任务作为一个回归问题进行处理。
首先网络对输入的图像(H×W×C)进行网格划分(划分为S×S个网格),每个网格最后回归的内容包含两个检测框信息,但是只回归一个目标(这也导致了yolov1对于密集的小目标检测效果比较弱,这是网络设计的的缺陷),每个单独的网格回归过程如下:
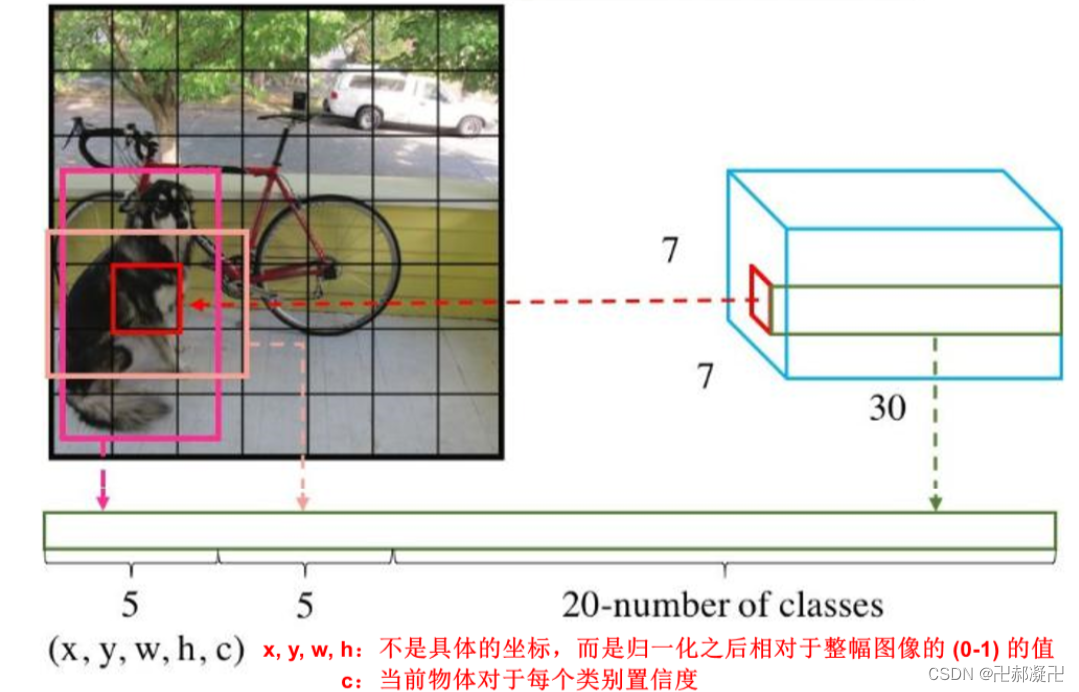
单个网格最后回归的向量维度:
l=5(x,y,w,h,c)*B(number of bounding box)+N(number of class)
1. x,y: 是指bounding box的预测框的中心坐标相较于该bounding box归属的grid cell左上角的偏移量,在0-1之间。
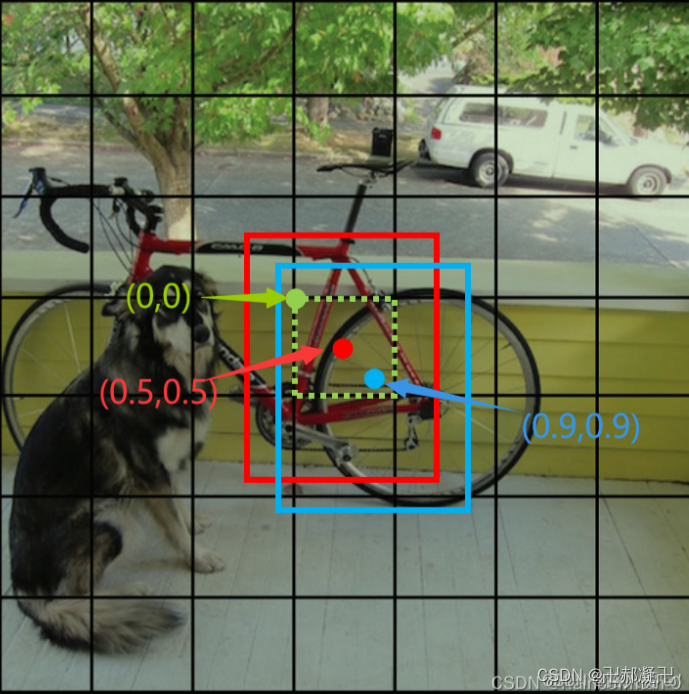
在上图中,绿色虚线框代表grid cell,绿点表示该grid cell的左上角坐标,为(0,0);红色和蓝色框代表该grid cell包含的两个bounding box,红点和蓝点表示这两个bounding box的中心坐标。有一点很重要,bounding box的中心坐标一定在该grid cell内部,因此,红点和蓝点的坐标可以归一化在0-1之间。在上图中,红点的坐标为(0.5,0.5),即x=y=0.5,蓝点的坐标为(0.9,0.9),即x=y=0.9。
2. w,h: 是指该bounding box的宽和高,但也归一化到了0-1之间,表示相较于原始图像的宽和高(即448个像素)。比如该bounding box预测的框宽是44.8个像素,高也是44.8个像素,则w=0.1,h=0.1。

红框的x=0.8,y=0.5,w=0.1,h=0.2。
3. N: 预测 N 个条件概率类别(物体属于每一种类别的可能性)
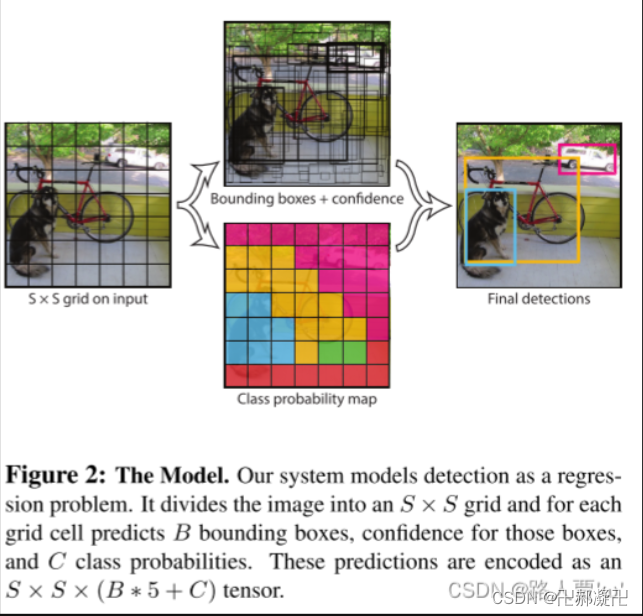
综上,S×S 个网格,每个网格要预测 B个bounding box (中间上图),还要预测 C 个类(中间下图)。将两图合并,网络输出就是一个 S × S × (5×B+C)。(S x S个网格,每个网格都有B个预测框,每个框又有5个参数,再加上每个网格都有N个预测类)
1.2 网络结构
网络结构设计借鉴了GoogleNet,比较简单:
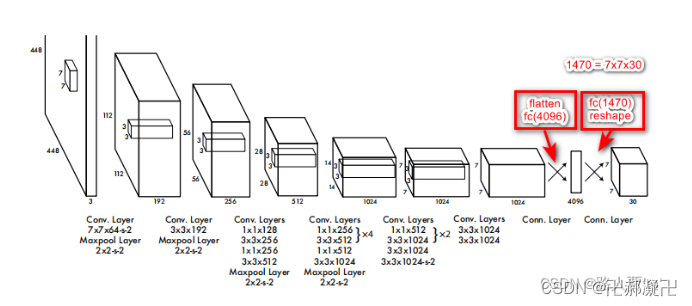
最终输出是7×7×30:7×7表示开始的时候将检测框分成了7×7个网格,30包含了两个预测框的参数和Pascal VOC的类别参数:每个预测框有5个参数:x,y,w,h,confidence。另外,Pascal VOC里面还有20个类别;所以最后的30实际上是由5x2+20组成的,也就是说这一个30维的向量就是一个gird cell的信息。
网络详解:
- YOLO主要是建立一个CNN网络生成预测7×7×1024 的张量 。
- 然后使用两个全连接层执行线性回归,以进行7×7×2 边界框预测。将具有高置信度得分(大于0.25)的结果作为最终预测。
- 在3×3的卷积后通常会接一个通道数更低1×1的卷积,这种方式既降低了计算量,同时也提升了模型的非线性能力。
- 除了最后一层使用了线性激活函数外,其余层的激活函数为 Leaky ReLU 。
- 在训练中使用了 Dropout 与数据增强的方法来防止过拟合。
- 对于最后一个卷积层,它输出一个形状为 (7, 7, 1024) 的张量。 然后张量展开。使用2个全连接层作为一种线性回归的形式,它输出1470个参数,然后reshape为 (7, 7, 30) 。
1.3 损失函数

注意:宽高使用了开根处理增强了小目标的敏感程度:
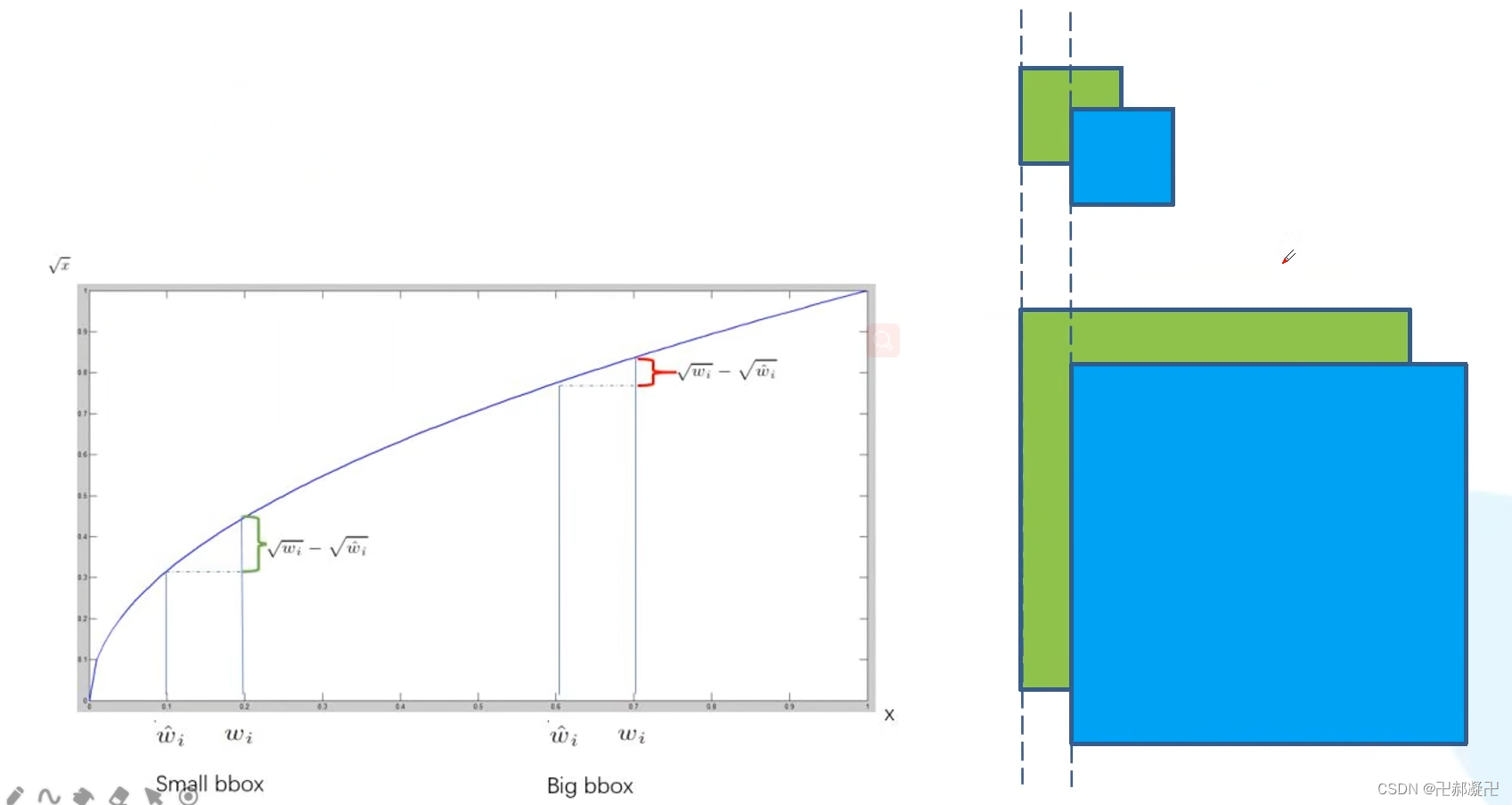
v2 基于v1改进的内容不多,不详细记录了。
2. yolo v3
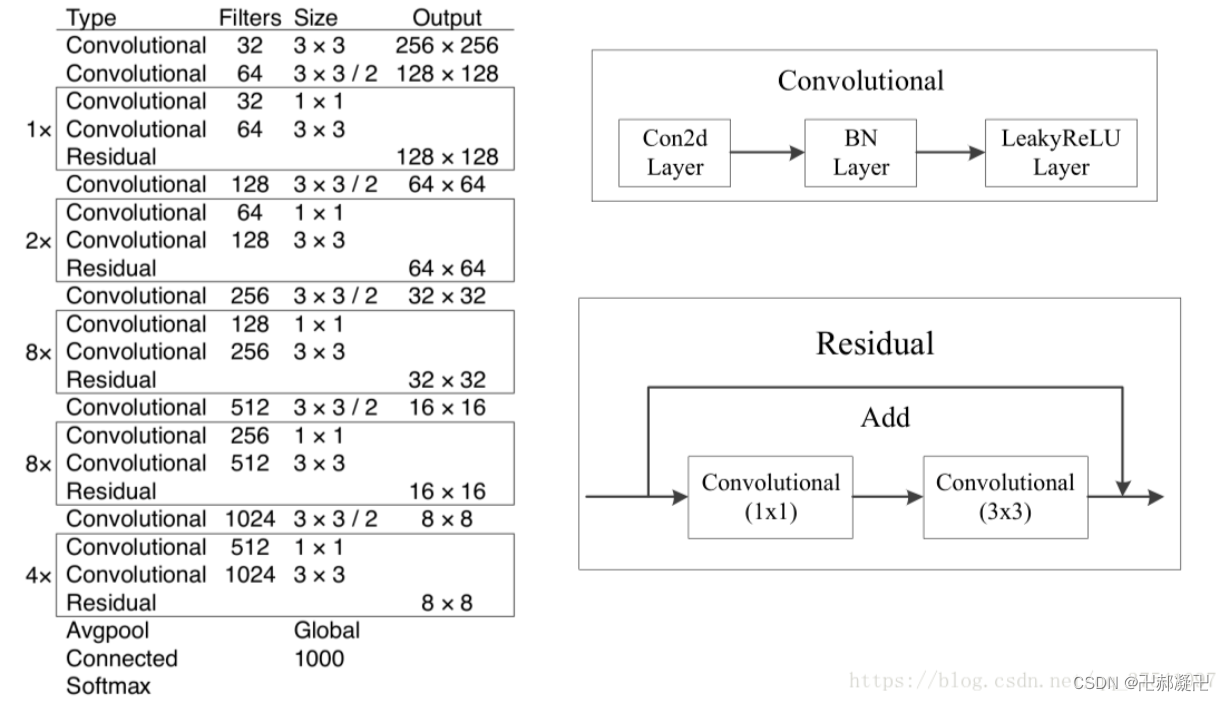
2.1 Darknet-53 模型结构
网络模型图来自于YOLO v3网络结构分析_yolov3网络结构-CSDN博客
网络名称的由来也是根据卷积的层数进行定义的,下面就是DarknNet的结构图,还是很清晰的:
2.2 yolo v3网络架构
原Darknet53中的尺寸是在图片分类训练集上训练的,所以输入的图像尺寸是256x256,下图是以YOLO v3 416模型进行绘制的,所以输入的尺寸是416x416,预测的三个特征层大小分别是52,26,13。
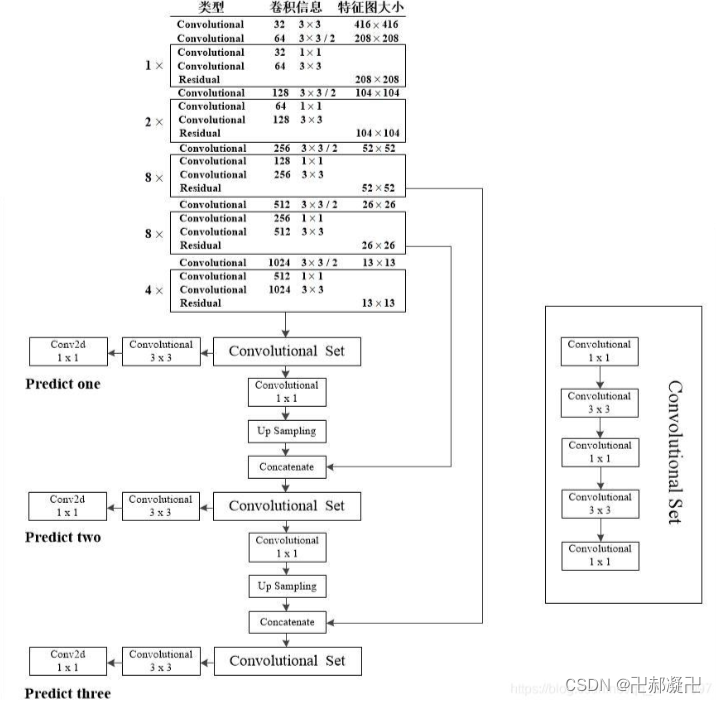
从上图我们可以看出,相较于前面的系列,v3版本从不同的维度上进行预测,克服了之前系列连续出现的小目标的检测性能不足的问题。
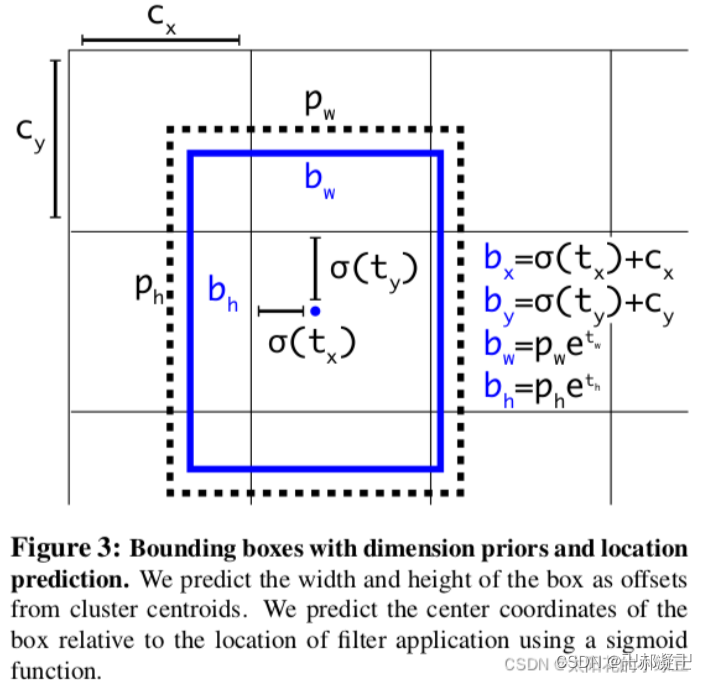
2.3 目标检测边界框的设计
YOLOv3网络在三个特征图中分别通过( 4 + 1 + c ) × k 个大小为1 × 1的卷积核进行预测。k是预设边界框的个数(默认3),c是检测类别数量。其中4k个参数负责预测目标边界框的偏移量,k个参数负责预测目标边界框内包含目标的概率,ck个参数负责预测这k个预设边界框对应c个目标类别的概率。

下图给出了三个预测层的特征图大小以及每个特征图上预设边界框的尺寸(这些预设边界框尺寸都是作者根据COCO数据集聚类得到的):

2.3 损失函数

1. 目标置信度损失

2 目标类别损失

3 目标定位损失
对应图3中的内容:
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









