






环境要求:Python 3.7
opencv-python~=3.4.2.16代码 label_tool.py
import os
import cv2
import random
from xml.dom import minidom
from xml.etree import ElementTree as ET
import json
import argparse
object_class = 0
exits_bboxes = []
now_box = []
def ensure_dir(path):
if not os.path.exists(path):
os.mkdir(path)
def on_mouse(event, x, y, flags, param):
global now_box, exits_bboxes, object_class
if event == cv2.EVENT_LBUTTONDOWN: # 左键点击
now_box = [x, y, x, y, object_class]
elif event == cv2.EVENT_MOUSEMOVE and (flags & cv2.EVENT_FLAG_LBUTTON): # 按住左键拖曳,画框
now_box[2] = x
now_box[3] = y
elif event == cv2.EVENT_LBUTTONUP: # 左键释放,显示
exits_bboxes.append(now_box.copy())
now_box.clear()
def show_boxes(img, bboxes, object_class, colors):
box_img = img.copy()
for bbox in bboxes:
if bbox:
cv2.rectangle(box_img, (bbox[0], bbox[1]), (bbox[2], bbox[3]), color=colors[bbox[4]], thickness=2)
cv2.putText(box_img, object_class[bbox[4]], (bbox[0], bbox[1]),
cv2.FONT_HERSHEY_SIMPLEX,
0.75, colors[bbox[4]], 1)
return box_img
def read_cls(cls_txt):
if (os.path.exists(cls_txt)):
with open(cls_txt, "r") as f:
cls = [i for i in f.read().split("\n") if i]
else:
cls = list(eval(cls_txt))
return cls
def random_colors(color_num):
colors = []
for i in range(color_num):
colors.append((random.randint(0, 255), random.randint(0, 255), random.randint(0, 255)))
return colors
def create_voc(data_bboxes, annotations_path, cls):
for data in data_bboxes:
img_name = data[0]
bboxes = data[1]
img_shape = data[2]
with open(os.path.join(annotations_path, img_name.split(".")[0]) + ".xml", "w") as f:
root = ET.Element('annotation')
folder = ET.SubElement(root, "folder")
folder.text = "images"
filename = ET.SubElement(root, "filename")
filename.text = img_name
size = ET.SubElement(root, "size")
width = ET.SubElement(size, "width")
height = ET.SubElement(size, "height")
depth = ET.SubElement(size, "depth")
height.text, width.text, depth.text = str(img_shape[0]), str(img_shape[1]), str(img_shape[2])
segmented = ET.SubElement(root, "segmented")
segmented.text = str(0)
for obj in bboxes:
object = ET.SubElement(root, "object")
name = ET.SubElement(object, "name")
name.text = cls[int(obj[4])]
pose = ET.SubElement(object, "pose")
pose.text = "unspecified"
truncated = ET.SubElement(object, "truncated")
truncated.text = str(0)
difficult = ET.SubElement(object, "difficult")
difficult.text = str(0)
bndbox = ET.SubElement(object, "bndbox")
xmin = ET.SubElement(bndbox, "xmin")
ymin = ET.SubElement(bndbox, "ymin")
xmax = ET.SubElement(bndbox, "xmax")
ymax = ET.SubElement(bndbox, "ymax")
xmin.text = str(obj[0])
ymin.text = str(obj[1])
xmax.text = str(obj[2])
ymax.text = str(obj[3])
xml_string = ET.tostring(root)
dom = minidom.parseString(xml_string)
dom.writexml(f, addindent='\t', newl='\n', encoding='utf-8')
def create_coco(data_bboxes, annotation_path, cls):
coco_dict = {
"images": [],
"type": "instances",
"annotations": [],
"categories": []
}
image_dict = dict()
annotation_dict = dict()
category_dict = dict()
box_id = 1
for i, data in enumerate(data_bboxes):
image_dict["file_name"] = data[0]
image_dict["height"] = data[2][0]
image_dict["width"] = data[2][1]
image_dict["id"] = i
coco_dict["images"].append(image_dict.copy())
for bbox in data[1]:
annotation_dict["area"] = int((bbox[2] - bbox[0]) * (bbox[3] - bbox[1]))
annotation_dict["iscrowd"] = 0
annotation_dict["image_id"] = i
annotation_dict["bbox"] = [bbox[0], bbox[1], bbox[2] - bbox[0], bbox[3] - bbox[1]]
annotation_dict["category_id"] = bbox[4]
annotation_dict["id"] = box_id
annotation_dict["ignore"] = 0
annotation_dict["segmentation"] = []
box_id += 1
coco_dict["annotations"].append(annotation_dict.copy())
for i, label in enumerate(cls):
category_dict["supercategory"] = 'none'
category_dict['id'] = i
category_dict['name'] = label
coco_dict["categories"].append(category_dict.copy())
with open(annotation_path, "w") as f:
f.write(json.dumps(coco_dict))
def read_voc(annotatiion_path):
result = []
cls = []
xml = minidom.parse(annotatiion_path).documentElement
object_list = xml.getElementsByTagName("object")
for obj in object_list:
name = obj.getElementsByTagName('name')[0].childNodes[0].data
bbox = obj.getElementsByTagName('bndbox')[0]
xmin = bbox.getElementsByTagName('xmin')[0].childNodes[0].data
ymin = bbox.getElementsByTagName('ymin')[0].childNodes[0].data
xmax = bbox.getElementsByTagName('xmax')[0].childNodes[0].data
ymax = bbox.getElementsByTagName('ymax')[0].childNodes[0].data
if not (name in cls):
cls.append(name)
result.append((int(xmin), int(ymin), int(xmax), int(ymax), cls.index(name)))
return result, cls
def read_coco(img_path, annotatiion_path):
img_name = os.path.basename(img_path)
result = []
img_id = 0
find_img = 0
with open(annotatiion_path, "r") as f:
coco_dict = json.load(f)
for img_dict in coco_dict["images"]:
if img_name in img_dict["file_name"]:
img_id = img_dict["id"]
find_img = 1
break
if find_img:
for annotation_dict in coco_dict["annotations"]:
if img_id == annotation_dict["image_id"]:
bbox = annotation_dict["bbox"]
result.append((bbox[0], bbox[1], bbox[0] + bbox[2], bbox[1] + bbox[3], annotation_dict["category_id"]))
cls = [0 for i in range(len(coco_dict["categories"]))]
for category in coco_dict["categories"]:
cls[category["id"]] = category["name"]
return find_img, result, cls
def create_dataset(data_bboxes, result_path, cls, data_format, val_ratio=0.2, shuffle=True):
ensure_dir(result_path)
ensure_dir(os.path.join(result_path, "annotations"))
ensure_dir(os.path.join(result_path, "images"))
if shuffle:
random.shuffle(data_bboxes)
train = data_bboxes[int(val_ratio * len(data_bboxes)):len(data_bboxes)]
val = data_bboxes[0:int(val_ratio * len(data_bboxes))]
if data_format == "voc":
with open(os.path.join(result_path, "label_list.txt"), "w") as f:
for label in cls:
f.write(label + "\n")
with open(os.path.join(result_path, "train.txt"), "w") as f:
for data in train:
img_path = data[0]
f.write("./images/" + img_path + " ./annotations/" + img_path.split(".")[0] + ".xml\n")
with open(os.path.join(result_path, "valid.txt"), "w") as f:
for data in val:
img_path = data[0]
f.write("./images/" + img_path + " ./annotations/" + img_path.split(".")[0] + ".xml\n")
create_voc(train, os.path.join(result_path, "annotations"), cls)
create_voc(val, os.path.join(result_path, "annotations"), cls)
elif data_format == "coco":
create_coco(train, os.path.join(result_path, "annotations", "train.json"), cls)
create_coco(val, os.path.join(result_path, "annotations", "valid.json"), cls)
def show_dataset(img_path, annotatiion_path, data_format):
img = cv2.imread(img_path)
if data_format == "voc":
bboxes, cls = read_voc(annotatiion_path)
colors = random_colors(len(cls))
img = show_boxes(img, bboxes, cls, colors)
elif data_format == "coco":
find_img, bboxes, cls = read_coco(img_path, annotatiion_path)
if find_img:
colors = random_colors(len(cls))
img = show_boxes(img, bboxes, cls, colors)
else:
print(img_path, "is not in", annotatiion_path)
exit()
cv2.imshow(img_path, img)
print("note: Press any key to continue.")
cv2.waitKey(0)
def parse_args():
parser = argparse.ArgumentParser(
description="This is a script to label the target detection dataset in VOC or COCO format."
)
parser.add_argument(
'--mode',
# required=True,
type=str,
choices=["label", "show"],
default="label",
help="The 'label' mode is used for labeling, and the 'show' mode is used for displaying."
)
parser.add_argument(
'--data_format',
# required=True,
type=str,
choices=["voc", "coco"],
default="voc",
help="The optional data set formats are 'voc' and 'coco'."
)
parser.add_argument(
'--img_dir',
type=str,
# default="./data/roadsign_voc/images",
help="Path of the image folder to be labeled."
)
parser.add_argument(
'--label_list',
type=str,
# default="./label_list.txt",
help="Label list or the path of the label list file."
)
parser.add_argument(
'--result_path',
type=str,
default="./result",
help="Path of the folder where the annotation results are saved."
)
parser.add_argument(
'--val_ratio',
type=float,
default=0.2,
help="Percentage of valid datasets."
)
parser.add_argument(
'--img_path',
type=str,
# default="./data/roadsign_voc/images/road160.png",
help="Path of image to display."
)
parser.add_argument(
'--annotation_path',
type=str,
# default="./data/roadsign_voc/annotations/road160.xml",
help="Path of annotation file."
)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = parse_args()
if args.mode == "label":
if not (args.img_dir and args.label_list and args.result_path and args.val_ratio):
print("Missing parameter:", end="")
print("img_dir", "label_list", "result_path", "val_ratio", sep=" or ")
exit()
esc_flag = 0 # 退出
cls = read_cls(args.label_list)
if not cls:
print("no object class.")
exit()
data_bboxes = []
colors = random_colors(len(cls))
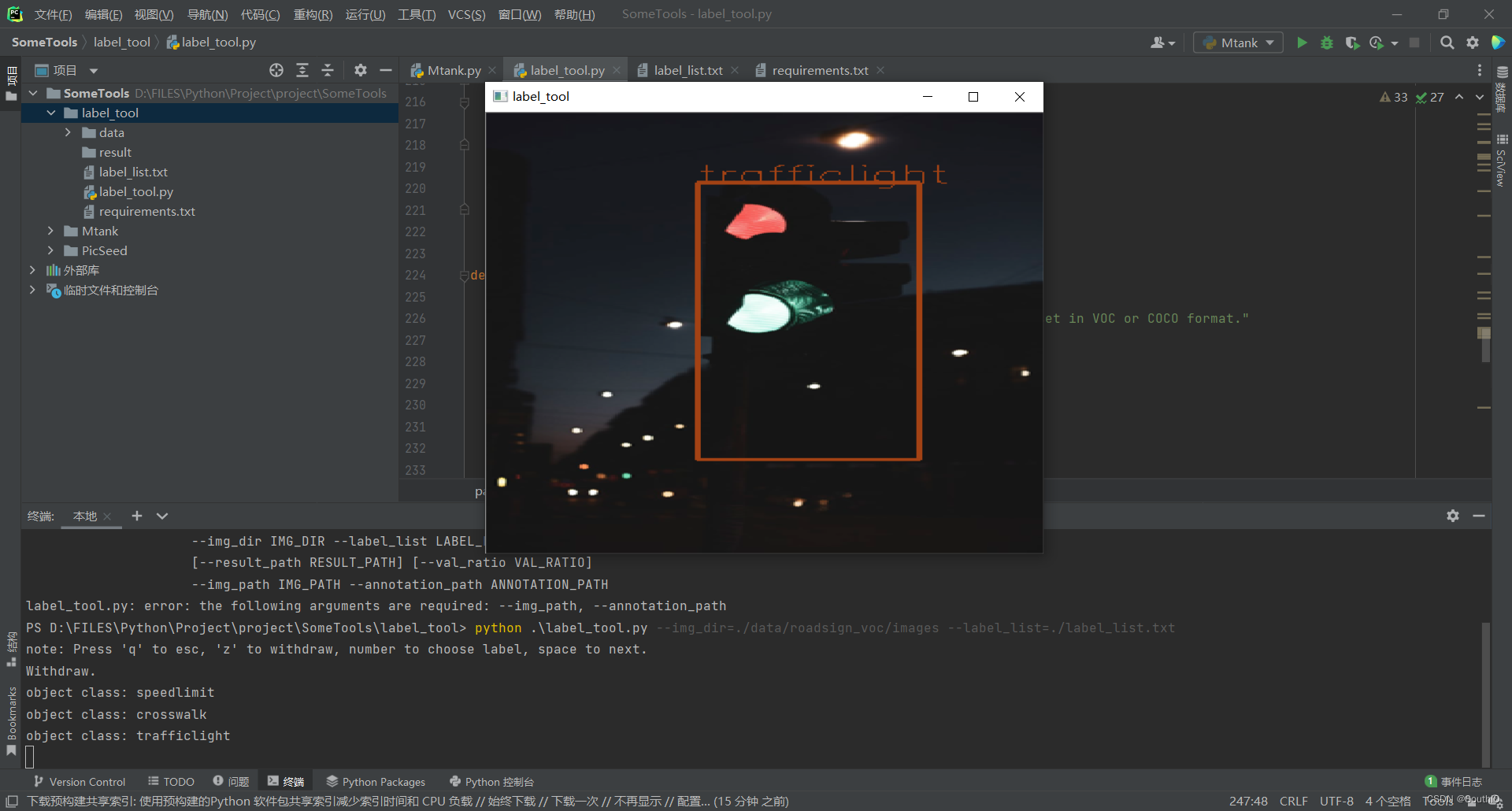
print("note: Press 'q' to esc, 'z' to withdraw, number to choose label, space to next.")
for img_path in os.listdir(args.img_dir):
path = os.path.join(args.img_dir, img_path)
img = cv2.imread(path)
while True:
exits_bboxes.append(now_box)
box_img = show_boxes(img, exits_bboxes, cls, colors)
exits_bboxes.pop()
cv2.namedWindow("label_tool", cv2.WINDOW_NORMAL)
cv2.setMouseCallback("label_tool", on_mouse)
cv2.imshow("label_tool", box_img)
key_val = cv2.waitKey(1)
if ord('q') == key_val: # 按下q退出
print("Escape.")
esc_flag = 1
break
elif ord('z') == key_val: # 按下z撤回
print("Withdraw.")
if exits_bboxes:
exits_bboxes.pop()
elif ord(' ') == key_val: # 按空格下一张
break
for cls_id in range(len(cls)):
if ord(str(cls_id)) == key_val:
object_class = cls_id
print("object class:", cls[object_class])
if esc_flag:
break
print(path, "bboxes:", *exits_bboxes)
data_bboxes.append((img_path, exits_bboxes.copy(), img.shape))
exits_bboxes.clear()
print("data_bboxes:", *data_bboxes, sep="\n")
print("Saving now...")
create_dataset(data_bboxes, args.result_path, cls, args.data_format, args.val_ratio)
elif args.mode == "show":
if os.path.exists(args.img_path) and os.path.exists(args.annotatiion_path):
show_dataset(args.img_path, args.annotatiion_path, args.data_format)
else:
print(args.img_path, "or", args.annotatiion_path, "not exists.")
exit()
print("Done.")
img_dir参数指明待标注图片文件夹路径,label_list参数指明分类的种类列表文件路径,例如:
python .\label_tool.py --img_dir=./data/roadsign_voc/images --label_list=./label_list.txt














 3527
3527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









