







获取更多内容,请关注微信公众号“电路板上的一抹微笑”
写在前面:
昨天梳理并发布了与JPEG图像编码标准有关的文章,今天继续对MPEG1-音频和MPEG1-视频这两种编码压缩技术进行介绍。在您看完后,觉得对您有用的话,请帮作者点个赞支持一下。下面正式开始讲解:
Directory
一、A general introduction to MPEG
二、 MPEG-1 Audio coding standard
2.1 The basic idea of MPEG-1 Audio coding standard
2.2 MPEG-1 Audio Coding and Decoding
三、 MPEG-1 Video coding standard
一、A general introduction to MPEG
Mpeg-1 is the first video and audio lossy compression standard developed by the MPEG organization, where "MPEG" stands for Moving Image Expert Group and the suffix "1" indicates that it is the first in a series of standards. In late 1992, MPEG-1 was officially approved as an international standard.
翻译:
MPEG-1是MPEG组织制定的第一个视频和音频有损压缩标准,其中“MPEG”代表动态图像专家组,后缀“1”表示它是一系列标准中的第一个。1992年底,MPEG-1正式被批准成为国际标准。

figure1 MPEG's flag
二、MPEG-1 Audio coding standard
2.1 The basic idea of MPEG-1 Audio coding standard
The MPEG-1 audio coding standard is first described below.
MPEG-1 audio coding standards are divided into three generations, of which the most famous third-generation protocol known as MPEG-1 Layer 3, or MP3, has become a widely circulated audio compression technology. MPEG-1 audio technology provides higher compression than the previous generation with each generation, while retaining the same output quality. The first generation protocol MP1 was used in LD as a recording digital audio and Philips DGC; The second generation protocol MP2 was later used in one of the European DVD audio layers.
Like JPEG, the MPEG-1 audio coding standard is a lossy compression system. But the MPEG-1 audio coding standard enables transparent, sensorless compression for high sampling rate stereo audio signals.
翻译:
下面首先介绍MPEG-1音频编码标准。
MPEG-1音频编码标准分三代,其中最著名的第三代协议被称为MPEG-1 Layer 3,简称MP3,已经成为广泛流传的音频压缩技术。MPEG-1音频技术在每一代之间,在保留相同的输出质量之外,压缩率都比上一代高。第一代协议MP1被应用在LD作为记录数字音频以及飞利浦公司的DGC上;而第二代协议MP2后来被应用于欧洲版的DVD音频层之一。
与JPEG类似,MPEG-1音频编码标准也是一个有损压缩系统。但MPEG-1音频编码标准对于高抽样速率的立体声音频信号来说,能够实现透明的、感觉无损的压缩。
The performance of the MPEG-1/ audio coding standard is due to its use of two psychoacoustic features of the human hearing system: 1.Critical frequency band;2. Auditory shielding.
翻译:
MPEG-1/音频编码标准之所以具有这样的性能,是由于其中利用了人类听觉系统的两个心理声学特点:1.临界频带; 2.听觉屏蔽
2.1.1 Critical frequency band
Critical frequency band refers to the critical frequency band width when a pure tone is masked by continuous noise with a certain bandwidth with its central frequency. If the power of the pure tone is just heard, it is equal to the noise power in this frequency band.
The audible frequency range of human ear is 20Hz to 20kH, which is covered by 25 critical frequency bands, and their respective bandwidths increase with the increase of frequency. Loosely speaking, the auditory system can be likened to a set of bandpass filters, which consists of 25 overlapping bandpass filters. The "filter" has a minimum audible frequency of less than 100 Hz and a maximum audible stop rate of 5 kHz.
翻译:
临界频带是指当某个纯音被以它为中心频率、且具有一定带宽的连续噪声所掩蔽时,如果该纯音刚好被听到时的功率等于这一频带内的噪声功率,这个带宽为临界频带宽度。
人耳可听到的频带范围是20Hz到20 kH,被25个临界频带覆盖,其各自的带宽随频率的增大而增大。可以不严格地说,听觉系统好比一个带通滤波器集,它由25个频带相互重叠的带通滤波器组成,该“滤波器"最低可听频率小于100 Hz,而最高可听顿率达到5 kHz。

figure2 Diagram of the auditory system of the human ear
2.1.2 Auditory shielding
The sound of a weaker signal is masked by the sound of another stronger signal at a similar frequency, a property known as auditory masking.
The following figure illustrates the definition of the shielding threshold and gives a pair of adjacent frequency band related parameters. It is assumed that the blocker (i.e. the high level signal) is located in the dark shadow critical frequency band. Low level signals located in the dark range and below the shielding threshold are shielded by strong signals. As can be seen from the figure below, the shielding threshold varies with frequency in the critical frequency band. For the critical frequency band, a minimum shielding threshold can be defined, and all low-level signals below this threshold in the critical frequency band are shielded by strong signals. The difference in dB between the power of the blocker and the minimum shielding threshold is called the signal-shielding ratio (SMR). The figure below also shows the signal-to-noise ratio of the R-bit quantizer. The difference between the signal-shielding ratio and the signal-to-noise ratio (SNR) is the noise-shielding ratio (NMR) of the R-bit quantizer, expressed by the following formula :NMR=SMR-SNR
翻译:
一个较弱信号的声音会被另一个相近频率的较强信号的声音所掩蔽,这种特性被称为听觉屏蔽。
下图说明了屏蔽门限的定义并给出了一对相邻频带的相关参数。其中假定屏蔽者(即高电平信号)位于深色阴影临界频带内。位于该深色区间且低于屏蔽门限的低电平信号,被强信号屏蔽了。由下图可见,屏蔽门限在临界频带上随频率变化。对于临界频带,可定义一个最小屏蔽门限,临界频带内低于此门限的所有低电平信号均被强信号屏蔽。用dB表示的屏蔽者和最小屏蔽门限的功率之差,称为信号-屏蔽比(SMR)。下图也给出了R比特量化器的信噪比。信号-屏蔽比和信噪比的差值即为R比特量化器的噪声-屏蔽比(NMR),由下式表示:NMR=SMR-SNR
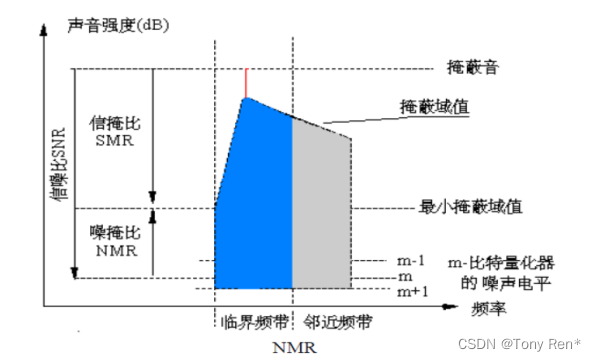
figure3 Schematic diagram of the shielding threshold
2.2 MPEG-1 Audio Coding and Decoding
2.1 describes the psychoacoustic background of the human auditory system and how the MPEG-1 audio coding standard works. Next we introduce MPEG-1 audio encoding and decoding.
翻译:
2.1中所讲的是人类听觉系统的心理声学背景,也是MPEG-1音频编码标准的工作原理。下面我们介绍MPEG-1音频编码与解码。
2.2.1 MPEG-1 Audio Encoder
The following diagram shows the basic block diagram of the encoder, which consists of four functional units: time-frequency mapping network, psychoacoustic module, quantizer and encoder, and frame-encapsulation unit.
翻译:
下图给出了编码器的基本框图,编码器由四个功能单元组成:时-频映射网络,心理声学模块,量化器和编码器,以及帧-封装单元。
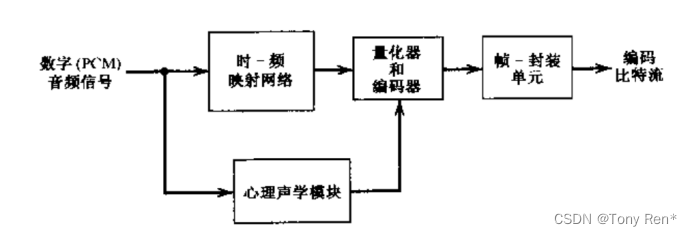
figure4 MPEG-1 audio encoder
① The function of time-frequency mapping network is to decompose the incoming audio signal into several subbands used for encoding. The mapping is divided into three layers, denoted as Ⅰ,Ⅱ and Ⅲ, whose complexity, delay and subjective sensory performance increase successively. The L-layer algorithm divides the audio signal into 32 subbands with constant bandwidth using a set of bandpass filters, which are also used in the I and Ⅲ layers. According to the previous discussion of critical frequency bands with unequal intervals, the design of this filter set should take into account both computational efficiency and sensory performance. The algorithm of layer I is simply improved on the algorithm of layer I to encode the data into a larger group, thus improving the compression performance. The layer Ⅲ algorithm is more detailed because it is designed to achieve a frequency decomposition closer to the critical band division.
② The psychoacoustic module is the core part of the encoder. Its function is to analyze the frequency harmonic content of the input audio signal, and then calculate the signal-shielding ratio of each sub-band in each of the three layers.
③ Quantizer - encoder determines how to allocate available bits to subband signals for quantization according to the output information of psychoacoustic module. The purpose of dynamic bit allocation is to minimize the audibility of quantization noise.
④ The frame-encapsulation unit sets the quantized audio samples into encoded bitstreams.
翻译:
①时-频映射网络的功能是将输人音频信号分解成编码使用的若干子带。映射分为三层,分别标为Ⅰ,Ⅱ和Ⅲ,它们的复杂度、时延和主观感觉性能依次递增。l层的算法利用一个带通滤波器集将音频信号分为32个带宽恒定的子带,I层和Ⅲ层中也采用这样的滤波器集。根据前面对不等间隔排列的临界频带的讨论,这种滤波器集的设计应兼顾计算效率和感觉性能。层的算法只在Ⅰ层算法上进行了简单改进,将数据编码为更大的群,从而提高了压缩性能。Ⅲ层的算法则更为周详,因为其设计目标是得到更接近于临界频带划分的频率分解。
②心理声学模块是编码器的核心部分。其功能是对输人音频信号的频谐内容进行分析,然后计算出这三层中每层每个子带的信号-屏蔽比。
③量化器-编码器根据心理声学模块输出的信息决定如何将可用比特分配给子带信号以进行量化。动态分配比特的目的是使量化噪声的可听性降至最小。
④帧-封装单元将量化后的音频样值集合为编码比特流。
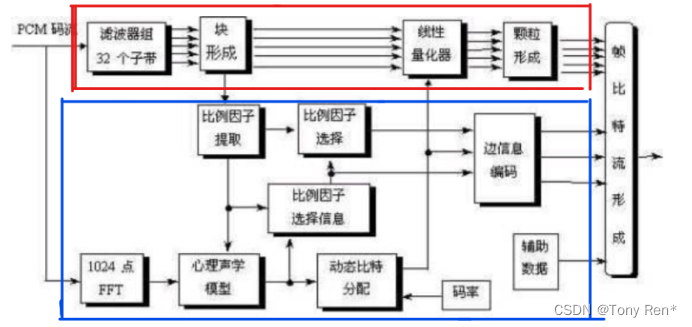
figure5 MPEG-1 audio encoder
Based on the above analysis, the encoder can be further refined into the structure shown in the figure above, which is composed of two red and blue lines.
The red line indicates that the input PCM code stream is divided into 32 subband signals through the multiphase filter banks. After the block formation, linear quantization is carried out for each subband data. Particle optimization is adopted for part of the quantization level to increase the compression ratio, and finally the output is bound.
The blue line is the FFT transformation of the input PCM code stream, the masked part of the signal is removed through the psychoacoustic model, and the scaling factor is extracted for dynamic bit allocation: the low-frequency component sensitive to human ear is allocated more bits, and the high-frequency noise is allocated less bits, so as to increase the compression ratio. After the selection of scale factor, data encoding and binding output.
翻译:
根据上述分析,编码器可进一步细化为上图所示结构,它由红蓝两条线构成。
红线是输入的PCM码流经过多相滤波器组分成32个子带信号,经过块形成后,对每个子带数据进行线性量化,对部分量化级别采用颗粒优化以增大压缩比,最后装帧输出。
蓝线是对输入的PCM码流进行FFT变换,经过心理声学模型去除信号中被掩蔽的部分,提取出比例因子后进行动态比特分配:对人耳听觉敏感的低频成分分配较多比特,对高频噪声分配较少的比特,以增大压缩比。比例因子经过选择后,数据编码装帧输出。
2.2.2 MPEG-1 Audio Decoder
The following figure shows the structure of the decoder. The decoder consists of three functional units: frame-decapsulation unit, frequency sample reconstruction network and frequency-time mapping network. Through comparison, it can be found that only the encoder must adopt the psychoacoustic module.
翻译:
下图所示为译码器结构,译码器由三个功能单元组成:帧-解封单元,频率样值重构网络以及频-时映射网络,通过对比可以发现,只有编码器必须采用心理声学模块。

figure6 MPEG-1 audio decoder
Because the decoder completes the inverse process of the signal processing operation carried out by the encoder, that is, the received encoded bit stream is converted into the time domain audio signal, the principle is similar, and will not be described here.
翻译:
因为译码器完成的是编码器所进行的信号处理操作的逆过程,即将收到的编码比特流转换为时域音频信号,原理类似,此处不再赘述。
2.3 MPEG-1 Audio’s conclusion
MPEG-1Audio specifies the encoding and decoding representation of high-quality audio for digital storage media, and is suitable for 32kHz, 44.1kHz, and 48kHz sampling rates. The encoding system can be operated in mono, dual channel, stereo and combined stereo, and the data rate of each channel is 128kb/s. This standard defines three layers of coding algorithms, allowing users to adopt different layers of coding systems according to different application needs. From level 1 to level 3, the higher the level, the better the compression performance, the progressively higher the sound quality performance, and ultimately the highest quality audio, while the more complex the encoding/decoder. Users can choose between complexity and compression quality. The first and second layer encoding modes (MP1 and MP2 for short) are subband sampling, and the third layer encoding modes (MP3 for short) are subband sampling after transformation. The following table lists the main performance indicators of different levels.
翻译:
MPEG-1Audio具体规定了用于数字存储媒介的高质量音频的编码与解码表示,适用于32kHz、44.1kHz和48kHz取样率。编码系统可以工作在单声道、双声道、立体声和联合立体声四个方式,每通道的数据率为128kb/s。该标准定义了三个层次(Layer)的编码算法,允许用户根据不同的应用需要采用不同层次的编码系统。从层次1到层次3,层次越高压缩性能越好,音质性能逐渐增加,最终能提供极高品质的音频,同时编码/解码器也越复杂。用户可在复杂性和压缩质量之间权衡选择。第1、2层编码方式(简称为MP1、MP2)为子带取样,第3层编码方式(简称为MP3)为变换后的子带取样。不同层次的主要性能指标下表所示。
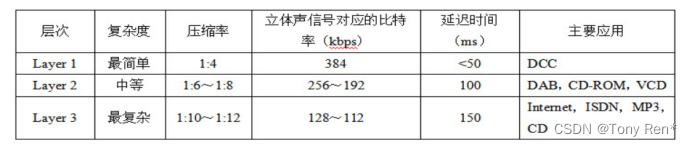
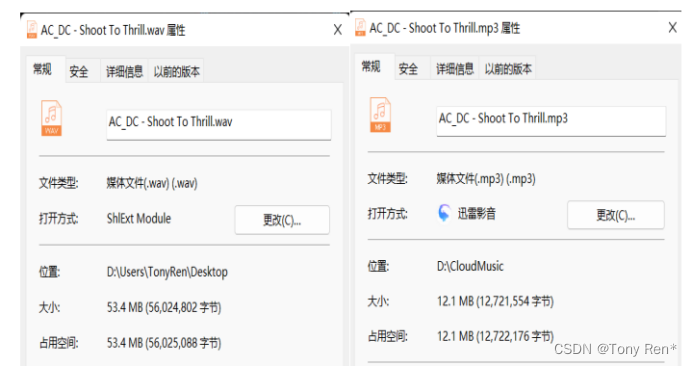
figure7 File comparison before and after compression
As shown in the figure above, the song memory footprint is significantly reduced with MP3 compression.
翻译:
如上图所示,通过MP3压缩显著地减小了歌曲内存占用空间。
三、MPEG-1 Video coding standard
The "MPEG-1 Video Coding Standard" is primarily designed to compress a 30 frame/second video signal into a 1.5 Mbps bitstream.
翻译:
“MPEC-1 视频编码标准”主要是为将30帧/秒的视频信号压缩成1.5 Mbps 的比特流而设计的。
We know that there are four basic redundancies inherent in video data: inter-frame (temporary) redundancies, intra-frame pixel redundancies, mental vision redundancies, and entropy coding redundancies. MPEG-1 compressed video data mainly starts with the first two redundancies:
(1) In the direction of time, motion compensation (also known as motion compensation) algorithm is used to eliminate inter-frame redundancy.
(2) In the spatial direction, the algorithm similar to JPEG is used to remove the pixel redundancy in the frame.
翻译:
我们知道视频数据中存在固有的四种基本冗余:帧间(暂时的)冗余、帧内像素冗余、精神视觉冗余和熵编码冗余。而MPEG-1压缩视频数据就主要从前两个冗余着手:
(1)在时间方向上,采用移动补偿(motion compensation,也叫运动补偿)算法去掉帧间冗余。
(2)在空间方向上,采用了和JPEG类似的算法来去掉帧内像素冗余。
JPEG reduces pixel redundancy through the combined use of DCT, quantization, and lossless entropy encoding. We covered this in detail in the last article, so we will focus on the removal of time-direction redundancy.
翻译:
JPEG减少像素冗余是通过综合运用 DCT,量化和无损嫡编码。这个我们在上一篇文章一文读懂JPEG算法!附C++代码实现JPEG算法,实现从BMP到JPEG转换!已经详细介绍了,因此我们下面主要介绍时间方向冗余度的去除。
In principle, adjacent frames in a typical video sequence are highly correlated. A high correlation means that, in general, the video signal does not change very quickly when switching from one frame to another, so the difference between adjacent frames has only one variance (i.e. average power), which is much smaller than the variance of the video signal itself. Therefore, interframe redundancy can be greatly reduced to produce a more efficient compressed video signal. This reduction is achieved by forecasting, that is, estimating each frame from adjacent frames. The results of the prediction errors need to be sent for dynamic valuation and compensation. The prediction is non-linear in nature.
翻译:
原则上,典型视频序列中的相邻帧具有高相关度。高相关度的含义是,通常情况下,从一帧切换到另一帧时,视频信号变化不是很快,因此邻近帧之间的差异只有一个方差(即平均功率),它远小于视频信号自身的方差。因此,可大量减少帧间冗余以产生一个更为有效的压缩视频信号。这种减少是通过预测来实现的,即从邻近帧中估计每一帧。需要发送预测错误的结果,用于动态估值和补偿。这种预测在本质上是非线性的。
The result of the removal of redundancy in both directions is a transformation of full-motion video into a 1.5Mbps computer data stream that can be saved on disc or integrated with text and pictures at the same time. Most importantly, full-motion video and associated audio can be transmitted over existing computer and telecommunications networks, making it possible to meet the demand for video on demand over the Internet.
翻译:
两个方向冗余度去除的结果是全运动视频转变为1.5 Mbps的计算机数据流,可以保存在光盘上,也可以同时集成文本和图片。最重要的是全运动视频和相关音频可以通过现有的计算机和电信网络传输,从而使在因特网上满足视频点播的需求成为可能。


















 1031
1031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











