







论文地址:https://arxiv.org/pdf/2111.14821v2
代码地址:https://github.com/mttr2021/MTTR
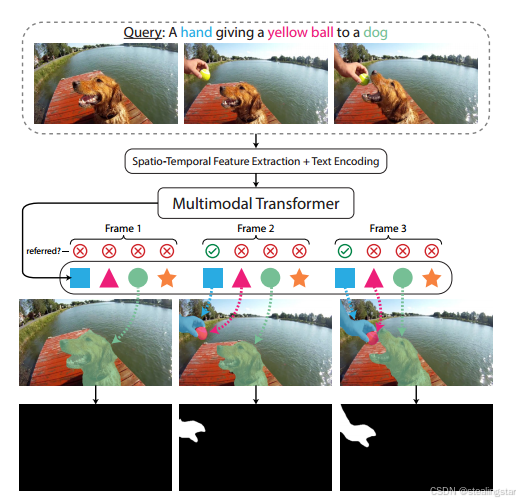
论文提出了一种基于transformer的简单RVOS方法,作者的框架称为多模态跟踪变换器(MTTR),将RVOS任务建模为一个序列预测问题。基于计算机视觉和自然语言处理的最新进展(当然对于现在来说不够新了),MTTR的核心理念是视频和文字可以通过单一的多模态变换器模型有效且优雅地一起处理。
本文只涉及项目代码实现,基于AutoDL服务器复现论文模型效果,不涉及论文原理!
AutoDL环境配置
进入autodl官网注册账号,学生党可以先进行学生认证,有一定优惠
点击左上角算力市场,然后选择按量计费,然后直接选择3090专区,其他地区的3090不好抢
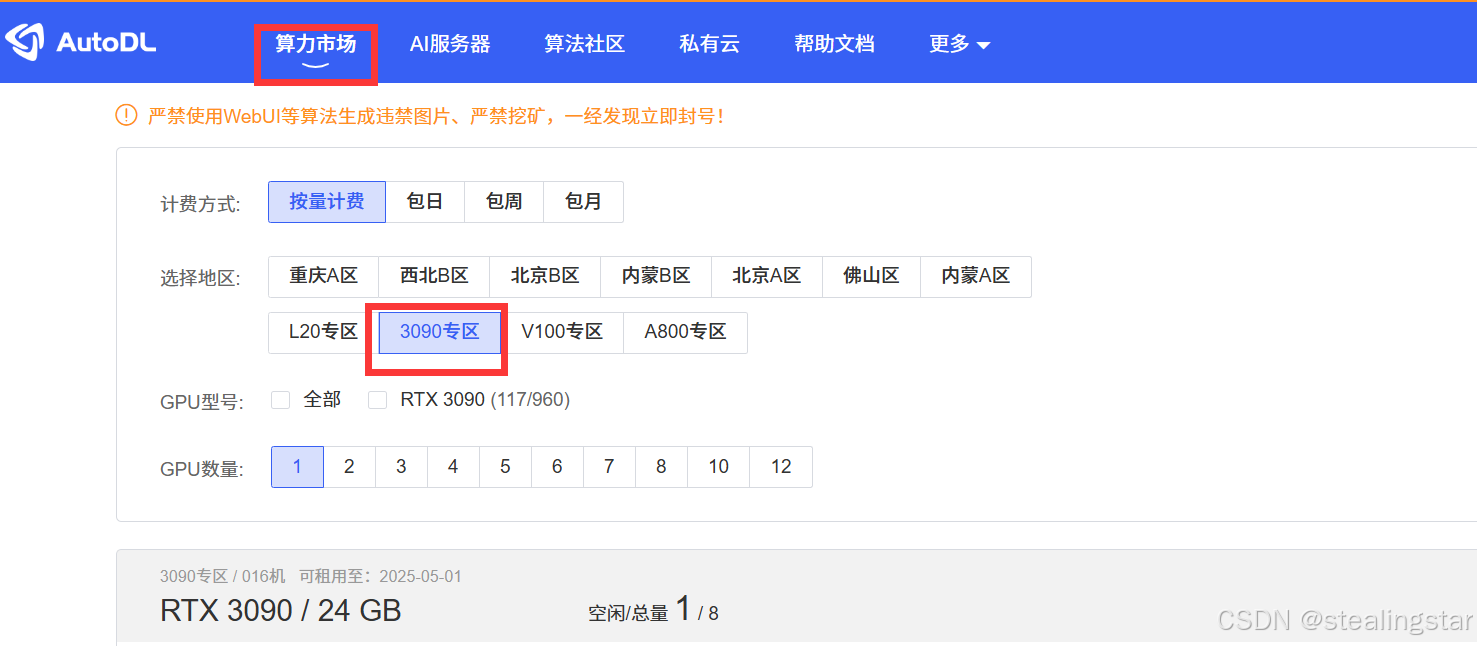
点进去后,数据盘一般不需要扩容
开始配置镜像
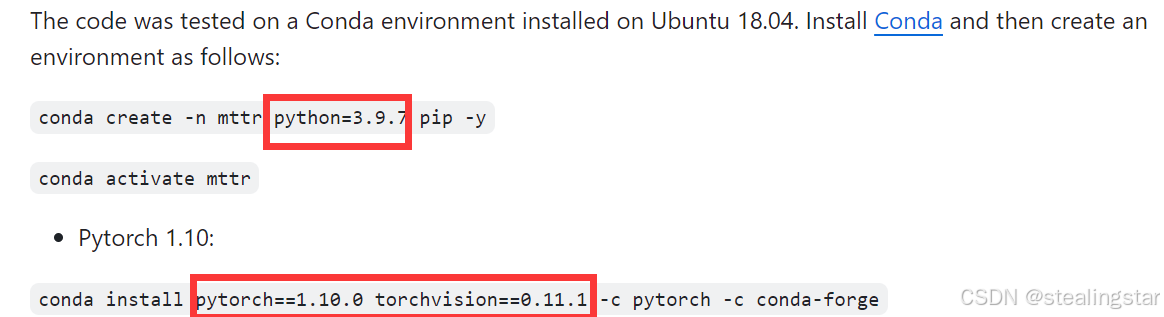
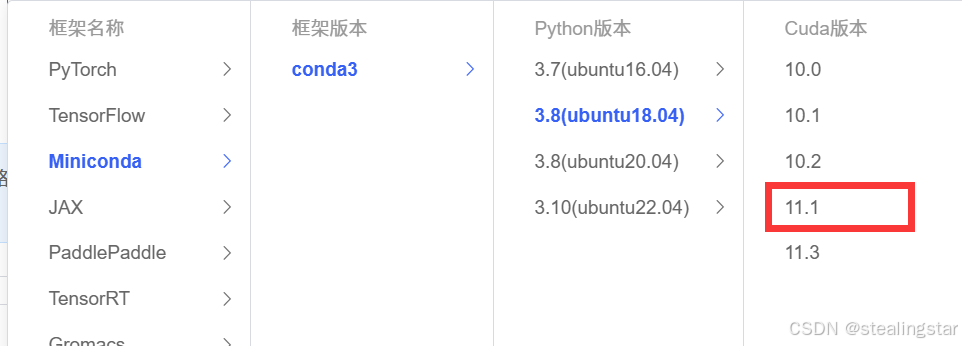
项目环境需要python3.9.7,pytorch1.10.0,直接想配置pytorch环境不行,所以只能先配Miniconda,然后自己手动安装pytorch,注意Ubuntu要安装18.04版本,cuda版本选择11.1
SSH登录
配置环境我们选择无卡开机,这样可以节省点钱
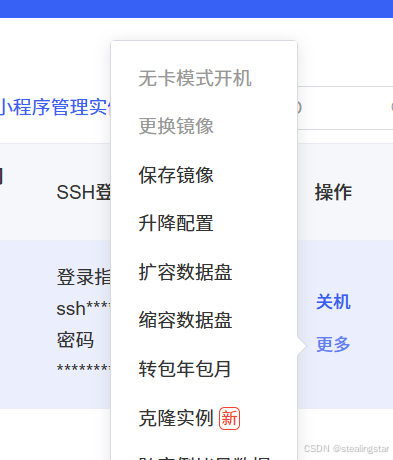
pycharm(截图自AutoDl帮助文档)
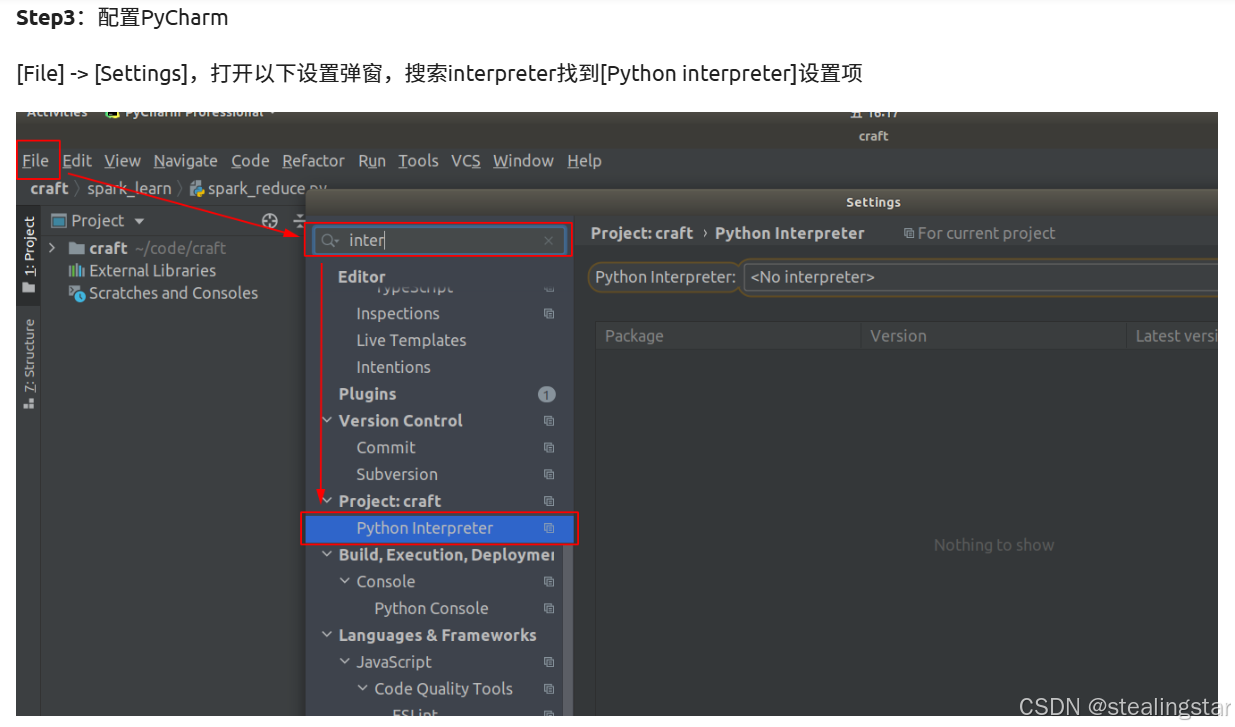
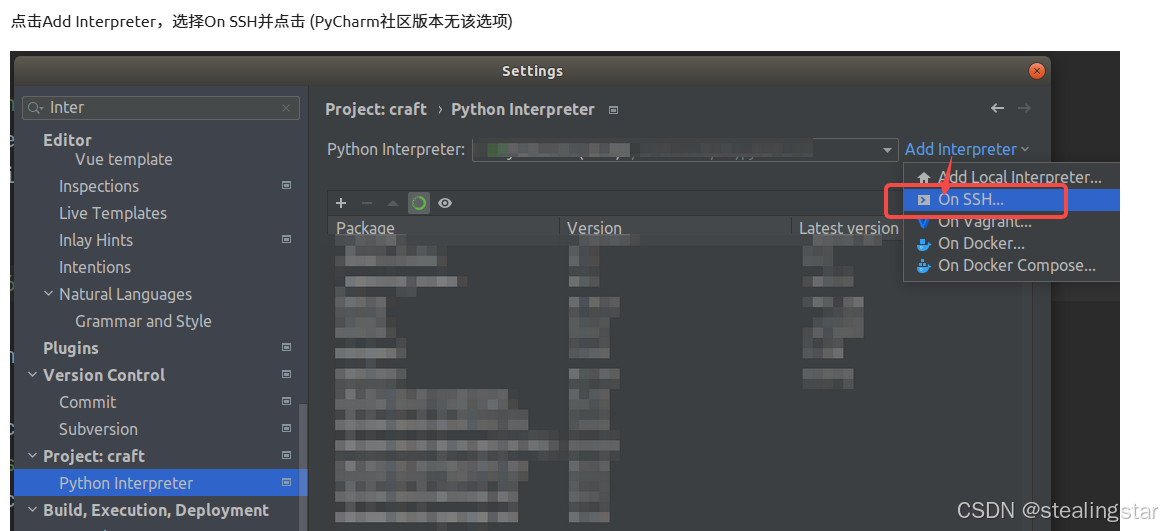
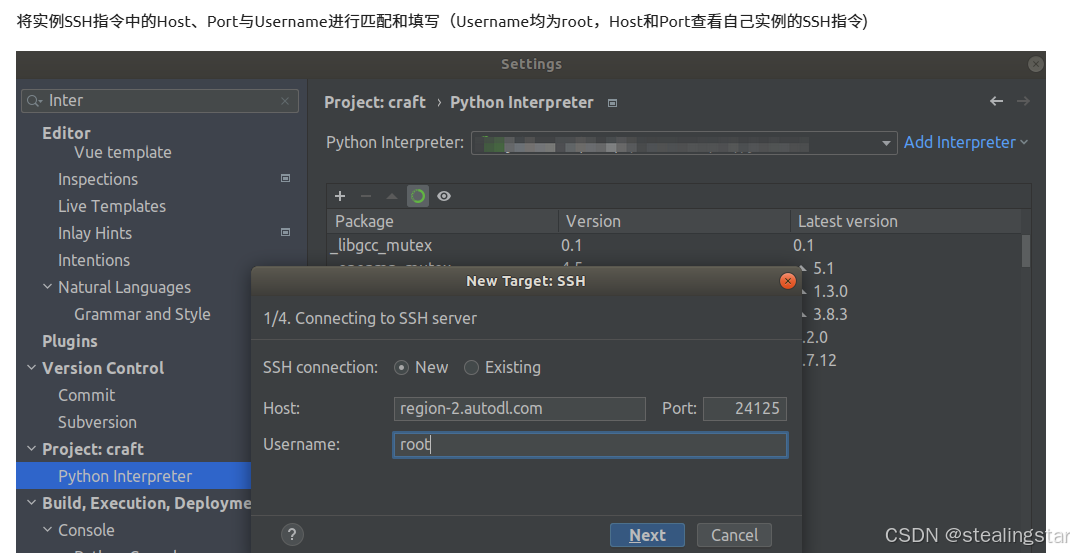
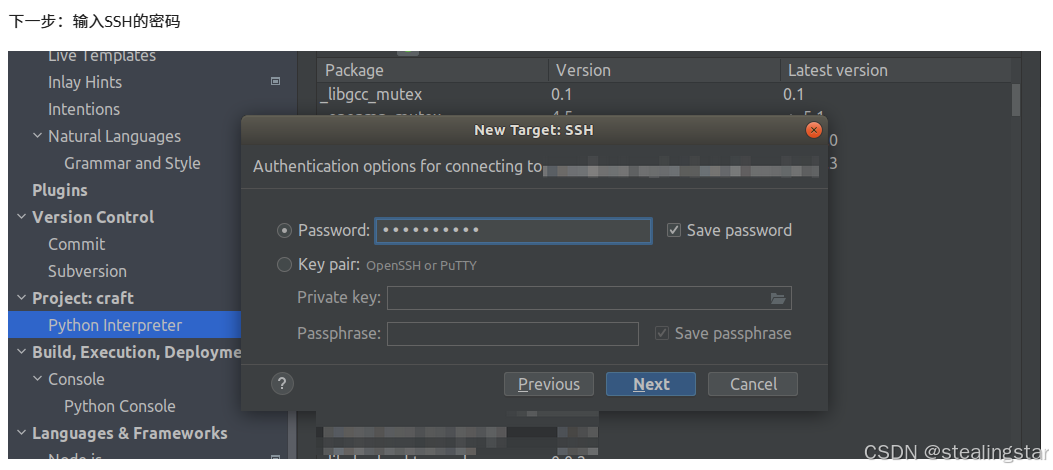
这里建议先不着急!!等我们conda创建好虚拟环境后再选择虚拟环境里面的解释器!
Filezilla(截图自AutoDl帮助文档)
下载地址:https://filezilla-project.org
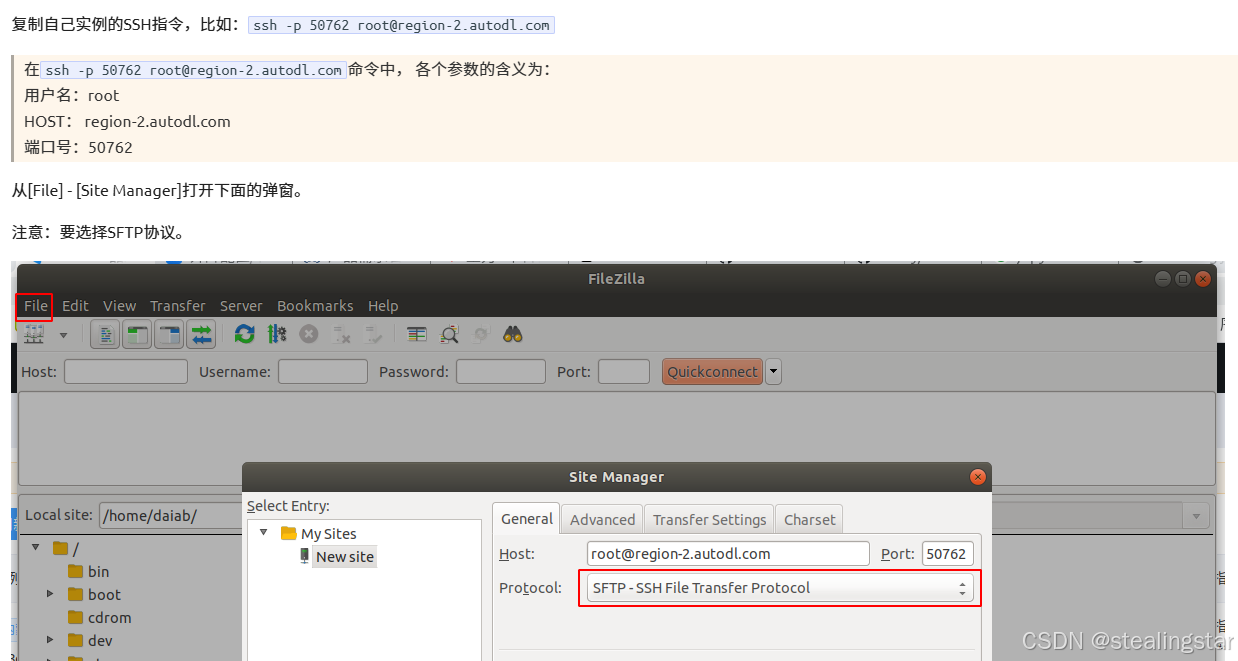
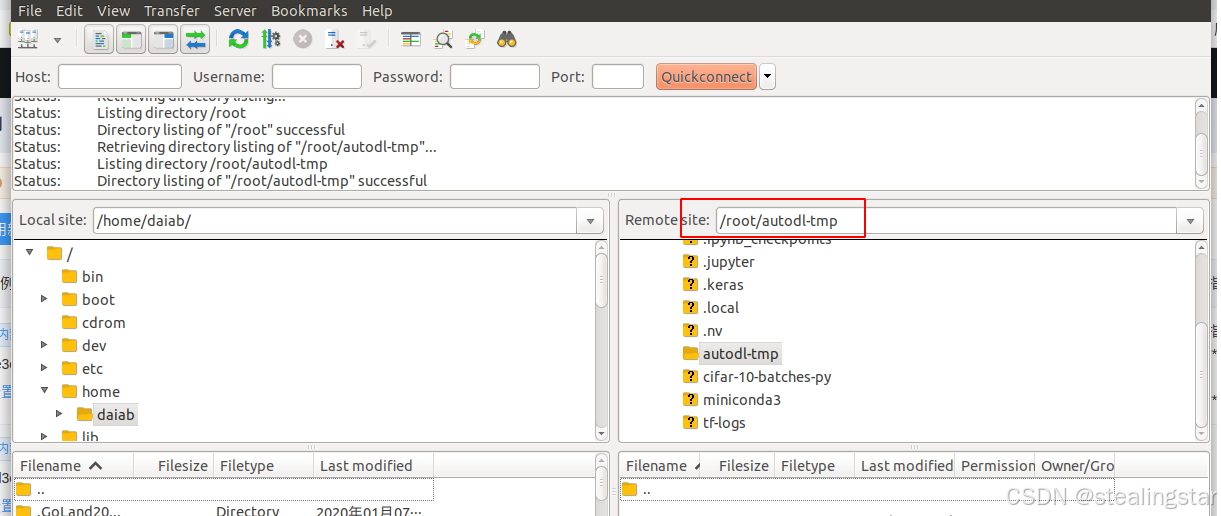
/root/autodl-tmp是数据盘,我们将所有代码和数据集放在数据盘,因为他比较大,miniconda安装在系统盘,那么我们的虚拟环境和包也就安装在系统盘上,不用担心,系统盘的大小是够的
接下来就可以通过拖拽传输文档文件了
项目环境配置
pytorch和torchvision安装
直接点击https://download.pytorch.org/whl/torch_stable.html下载到本地再通过filezilla传到服务器安装,想直接在服务器通过conda安装比较困难
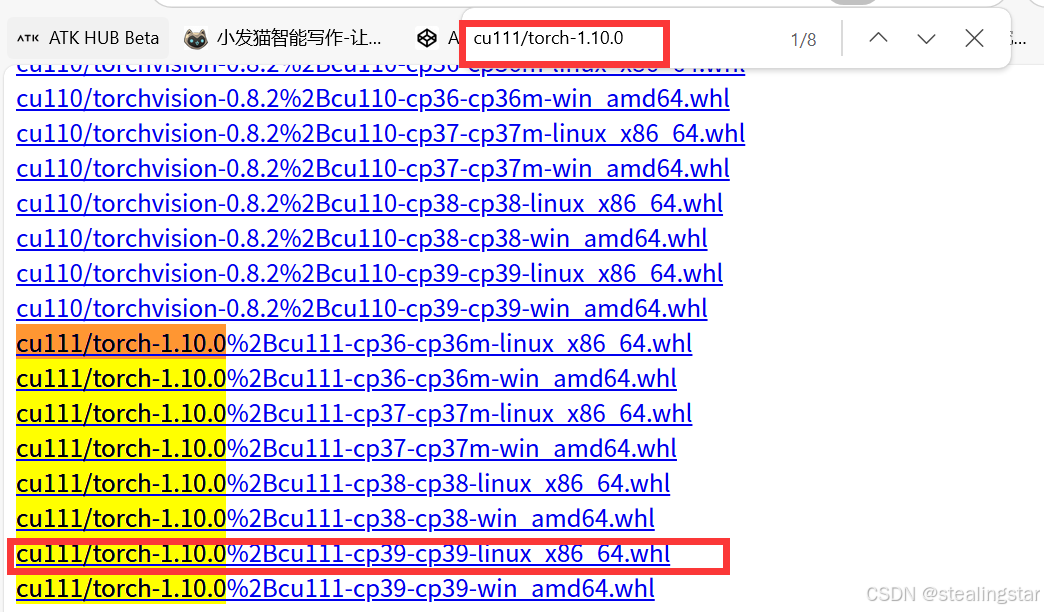
注意这里要是linux系统!cp39!
同理查找torchvision
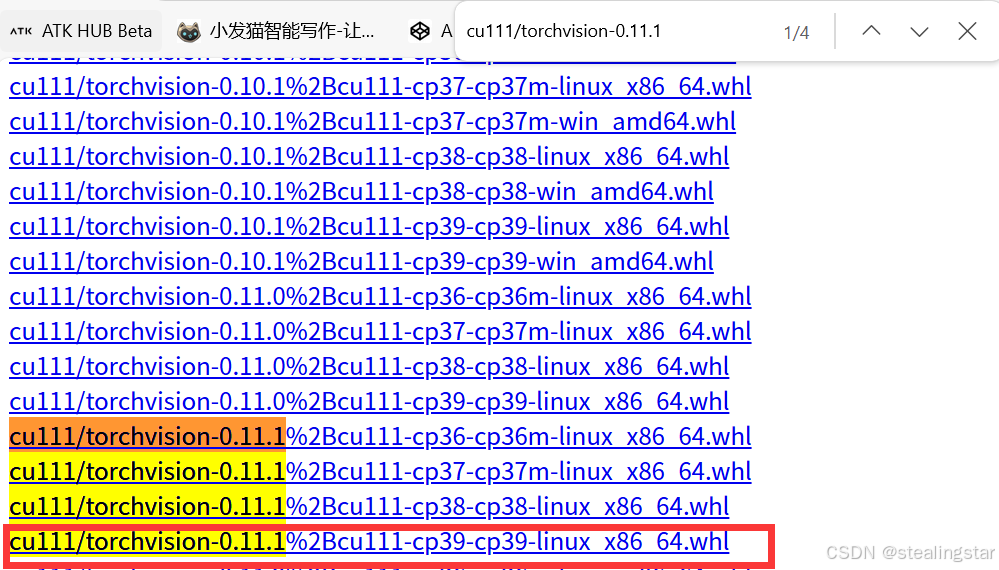
我这里默认你已经通过Filezilla传到服务器了,记住保存的位置

点击这里的JupyterLab,进入后在其他中打开终端
conda create -n mttr python=3.9.7 pip -y
# 更新bashrc中的环境变量
conda init bash && source /root/.bashrc
conda activate mttr
这时候虚拟环境已经建好了,直接git clone https://github.com/mttr2021/MTTR.git到本地,打开pycharm

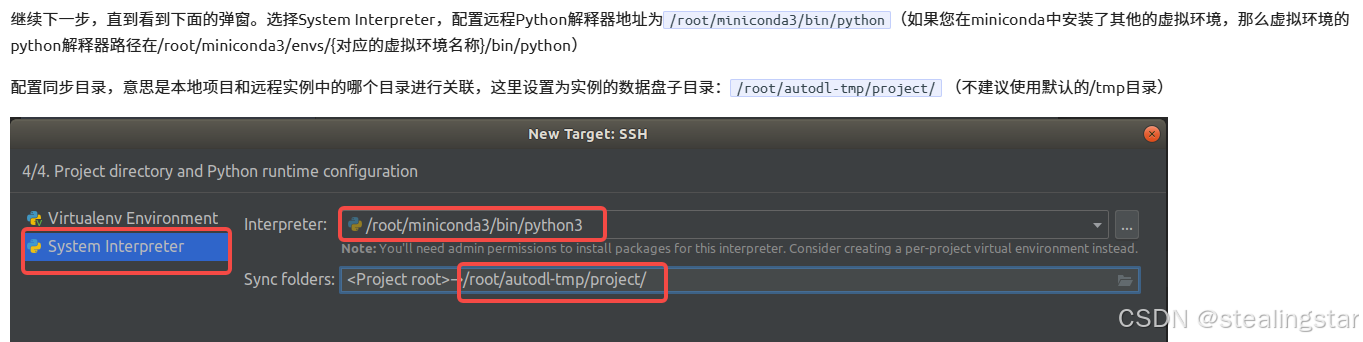
还记得上面让你先不要选择tmp目录吗?这里配置远程python解释器地址为/root/miniconda/3/env/mttr/bin/python
配置好后pycharm将自动上传项目文件到/root/autodl-tmp,如果你发现还是没有上传,你可以手动上传一下
然后安装pytorch和torchvision(确保你已进入了mttr这个虚拟环境中),cd进入你存放torch-1.10.0+cu111-cp39-cp39-linux_x86_64.whl和torchvision-0.11.1+cu111-cp39-cp39-linux_x86_64.whl的目录
pip install torch-1.10.0+cu111-cp39-cp39-linux_x86_64.whl
pip install torchvision-0.11.1+cu111-cp39-cp39-linux_x86_64.whl
然后安装transformer
pip install transformers==4.11.3
COCO API
pip install -U 'git+https://github.com/cocodataset/cocoapi.git#subdirectory=PythonAPI'
其他需要的包
pip install h5py wandb opencv-python protobuf av einops ruamel.yaml timm joblib
conda install -c conda-forge pandas matplotlib cython scipy cupy
根据上述代码我安装的h5py版本为3.12.1,后续h5py报错,卸载h5py,使用conda install h5py安装版本为3.11.0后,报错消失
数据集下载
所有文件、文件夹名称请按照规则命名!
论文中使用了三个数据集:A2D-Sentences、JHMDB-Sentences、Refer-YouTube-VOS。我发现只有前两个数据集能够下载,Refer-YouTube-VOS网站就是进不去,索性不做这个数据集了
我们都先下载到本地,再上传到服务器!
A2D-Sentences
下载链接


将下载的文件上传到服务器后,.zip .tar.bz后缀的文件需要解压,在服务器终端中cd到文件位置,使用如下所示方法解压文件
.tar.bz后缀等

.zip .rar后缀
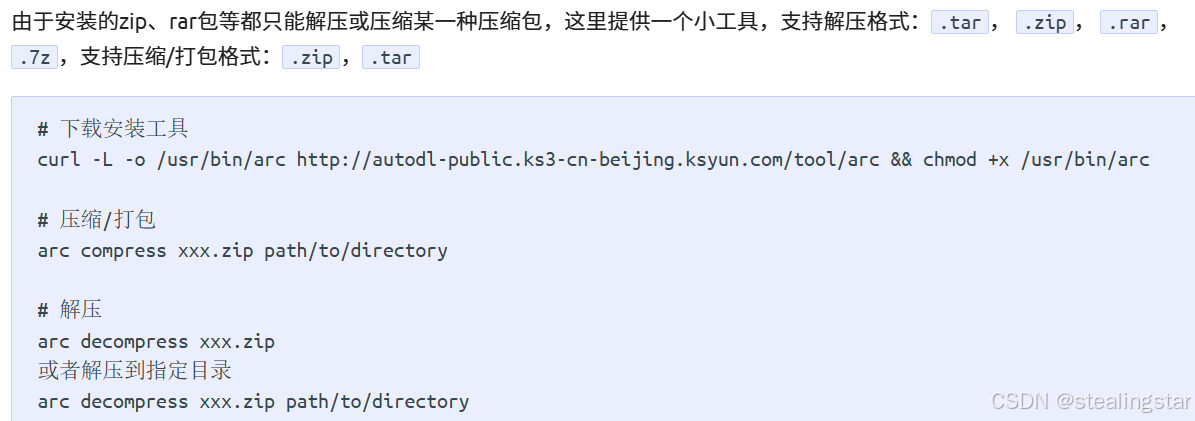
接下来安装下面的路径组织好文件,注意这里的CLIPS320需要改成clips320H
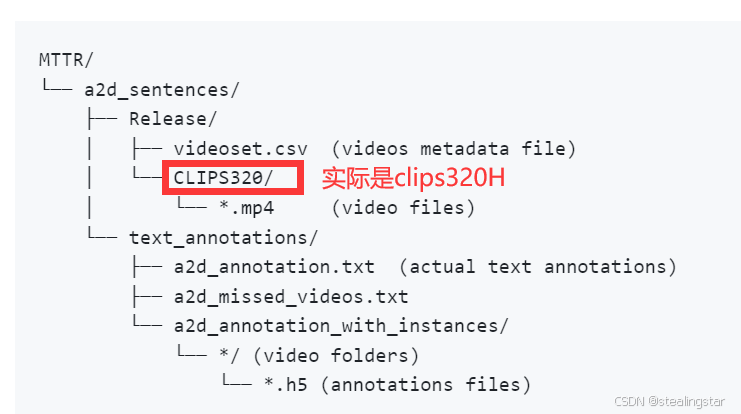
JHMDB-Sentences
下载链接

按照如下所示组织好文件
roberta-base预训练模型下载
代码中有直接加载该模型的代码,但是试了几次都说网络不行,于是只有自己将模型下载到本地
下载链接
像我一样直接在项目文件下创建个roberta-base文件夹,在上面的下载链接中下载这4个文件放在该文件夹中
pretrained_swin_transformer预训练模型下载
下载链接
同样的将下载的文件放在新创建的pretrain_swin_transformer中

check_points下载(用于复现论文效果)
A2D-Sentences
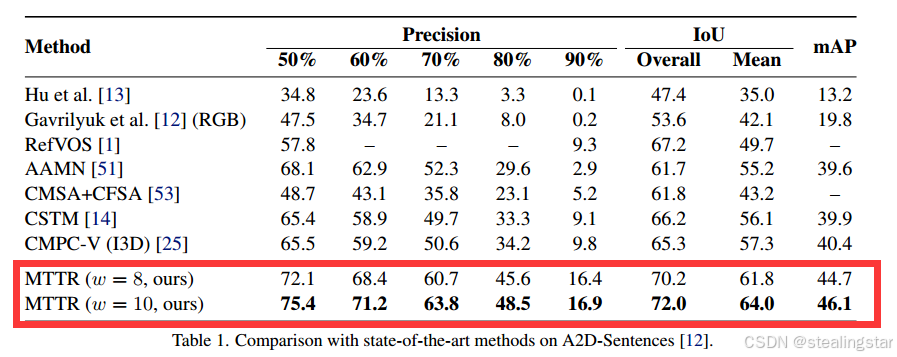
| windows size | Checkpoints file | mAP Result |
|---|---|---|
| 10 | link | 46.1 |
| 8 | link | 44.7 |
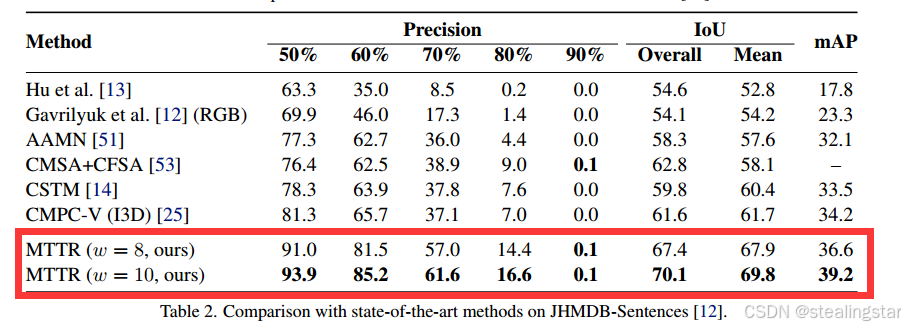
JHMDB-Sentences
| windows size | Checkpoints file | mAP Result |
|---|---|---|
| 10 | link | 39.2 |
| 8 | link | 36.6 |
下载后的文件按照我的方式放置
注意!这里下载后的文件后缀是.pth.tar,需要你手动重命名删除掉.tar,不需要解压!!
运行程序
复现论文效果
进入jupyter lab终端,先随便运行一个,放心肯定会报错
conda activate mttr
python main.py -rm eval -c configs/a2d_sentences.yaml -ws 10 -bs 3 -ckpt a2d_check_points/a2d-sentences_window-10.pth -ng 1
报错修改
- ImportError: /usr/lib/x86_64-linux-gnu/libstdc++.so.6: version `GLIBCXX_3.4.29‘ not found
根据提示是 /usr/lib/x86_64-linux-gnu/ 路径下的 libstdc++.so.6 缺少版本 GLIBCXX_3.4.29
输入以下指令查看当前路径下有哪些版本
strings /usr/lib/x86_64-linux-gnu/libstdc++.so.6 | grep GLIBCXX
使用管理员权限,查看当前系统下同类型文件
sudo find / -name "libstdc++.so.6*"
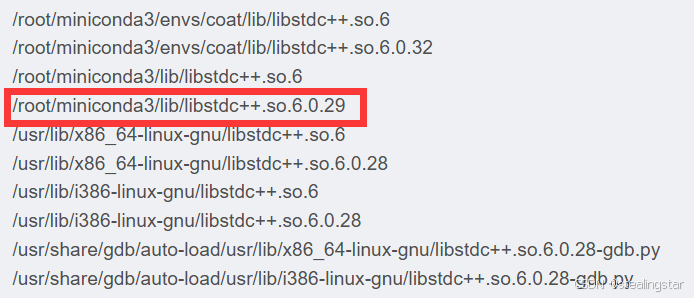
选择一个包含6.0.29的目录,在终端中输入(请将LD_LIBRARY_PATH后面改成所选的路径,只需要到lib就行,后面每次进入终端都需要这么输入)
export LD_LIBRARY_PATH=/root/miniconda3/envs/mttr/lib
-
AttributeError:“safe_load()”has been removed, use yaml = YAML(typ=‘safe‘, pure=True) yaml.load(…)
这应该是ruamel版本问题,如果你也有这个问题,直接按照我下面修改MTTR/main.py

-
ValueError: Connection error, and we cannot find the requested files in the cached path. Please try again or make sure your Internet connection is on.
这说明你的模型roberta-base没有下载好,或者路径可能有问题,好好检测一下! -
h5py报错TypeError: Unsupported integer size (0)
h5py版本有问题
pip uninstall h5py
conda install h5py
h5py版本:3.12.1 --> 3.11.0
修改好后后面进行论文效果复现
A2D-Sentences
| windows size | Command | mAP Result |
|---|---|---|
| 10 | python main.py -rm eval -c configs/a2d_sentences.yaml -ws 10 -bs 3 -ckpt a2d_check_points/a2d-sentences_window-10.pth -ng 1 | 46.1 |
| 8 | python main.py -rm eval -c configs/a2d_sentences.yaml -ws 8 -bs 3 -ckpt a2d_check_points/a2d-sentences_window-8.pth -ng 1 | 44.7 |
这里的-ckpt接的就是下载的check_points的路径,然后-ng后面是显卡数量,我是用的一张3090,所有填的1
evaluate_w=10_A2D-Sentences
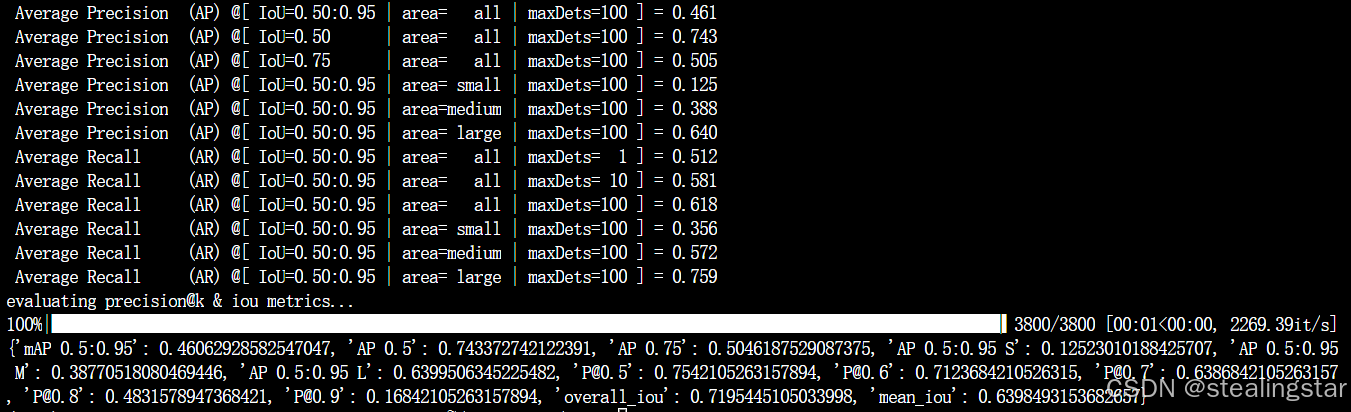
evaluate_w=8_ A2D-Sentences
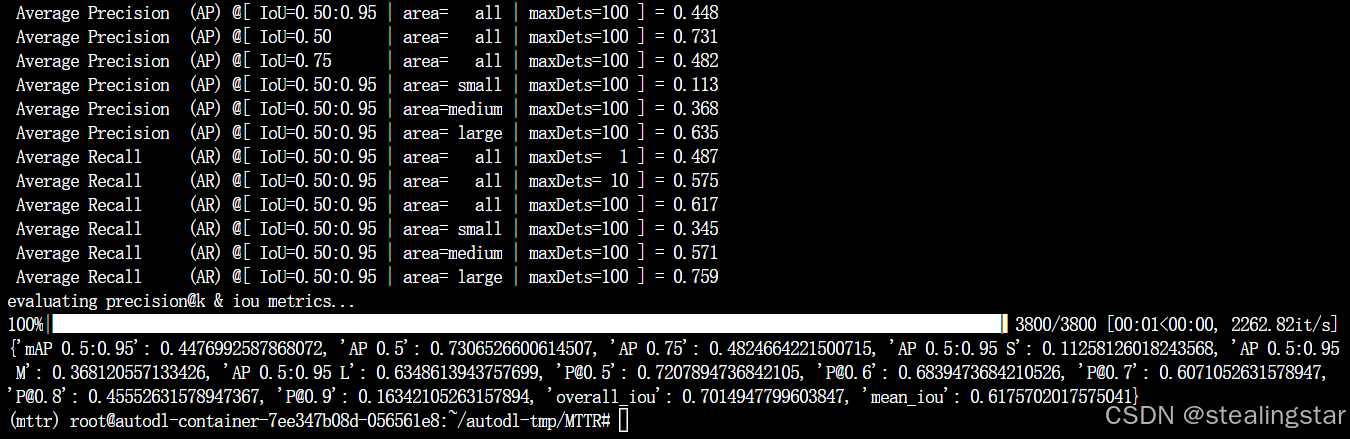
效果和论文中一样一样滴!
JHMDB-Sentences
| windows size | Checkpoints file | mAP Result |
|---|---|---|
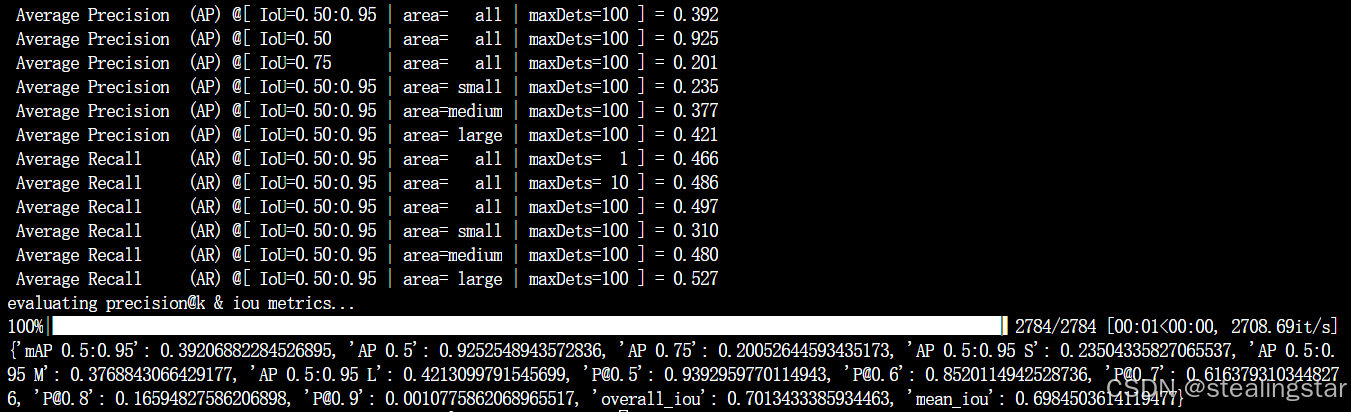
| 10 | python main.py -rm eval -c configs/jhmdb_sentences.yaml -ws 10 -bs 3 -ckpt jmdb_check_points/a2d-sentences_window-10.pth -ng 1 | 39.2 |
| 8 | python main.py -rm eval -c configs/jhmdb_sentences.yaml -ws 8 -bs 3 -ckpt jmdb_check_points/a2d-sentences_window-8.pth -ng 1 | 36.6 |
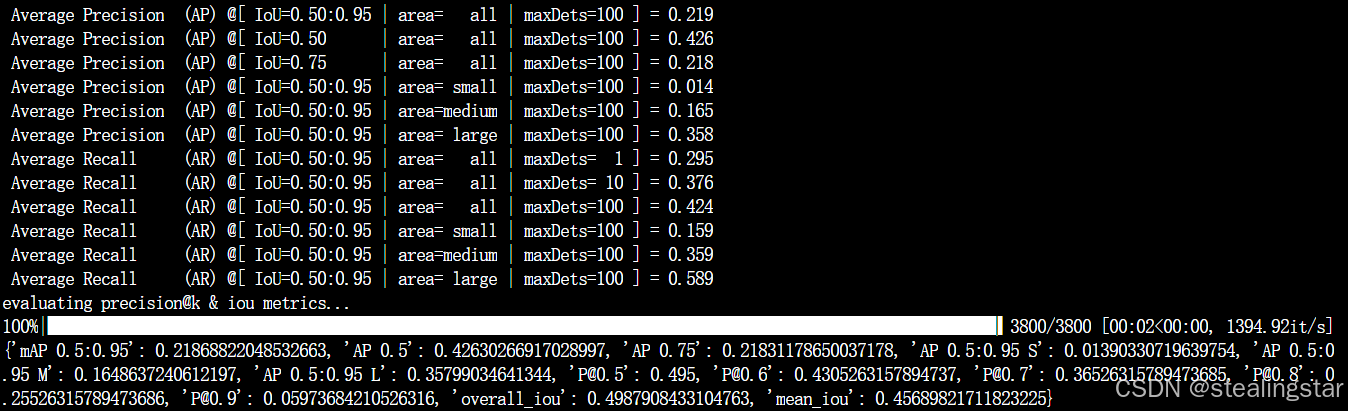
evaluate_w=10_JHMDB
evaluate_w=8_JHMDB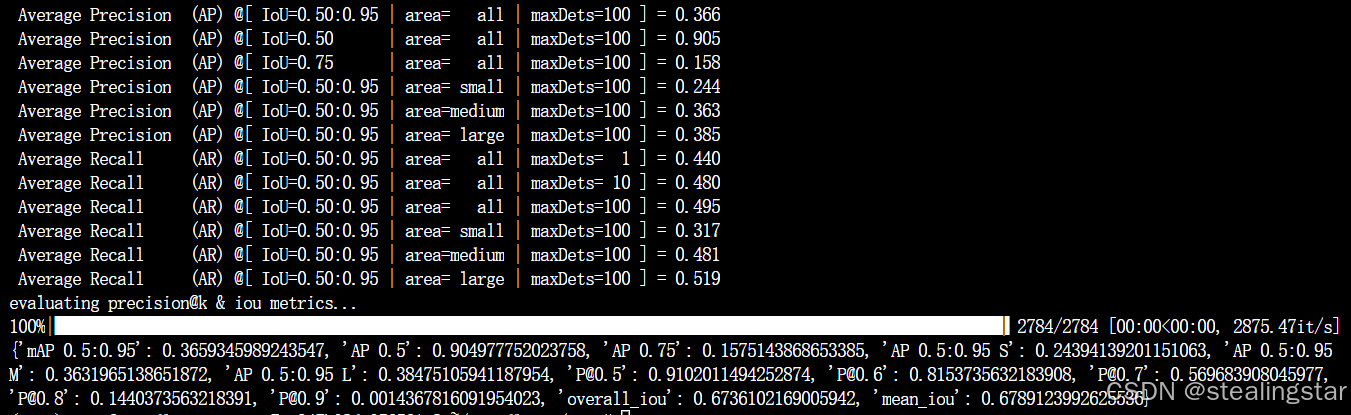
效果和论文中一样一样滴!
自行训练模型
python main.py -rm train -c configs/a2d_sentences.yaml -ws 8 -bs 2 -ng 1
注意这里只是1个epoch,我使用一张3090大概花费1个小时,程序中设定epochs为70,想自己训练出论文结果请量力而行!

















 1273
1273

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









