







任务需求:
爬取一个网址,将网址的数据保存到csv中。
爬取网址:
https://www.iqiyi.com/ranks1/1/0?vfrm=pcw_home&vfrmblk=&vfrmrst=712211_dianyingbang_rebo_title网址页面:

代码实现结果:
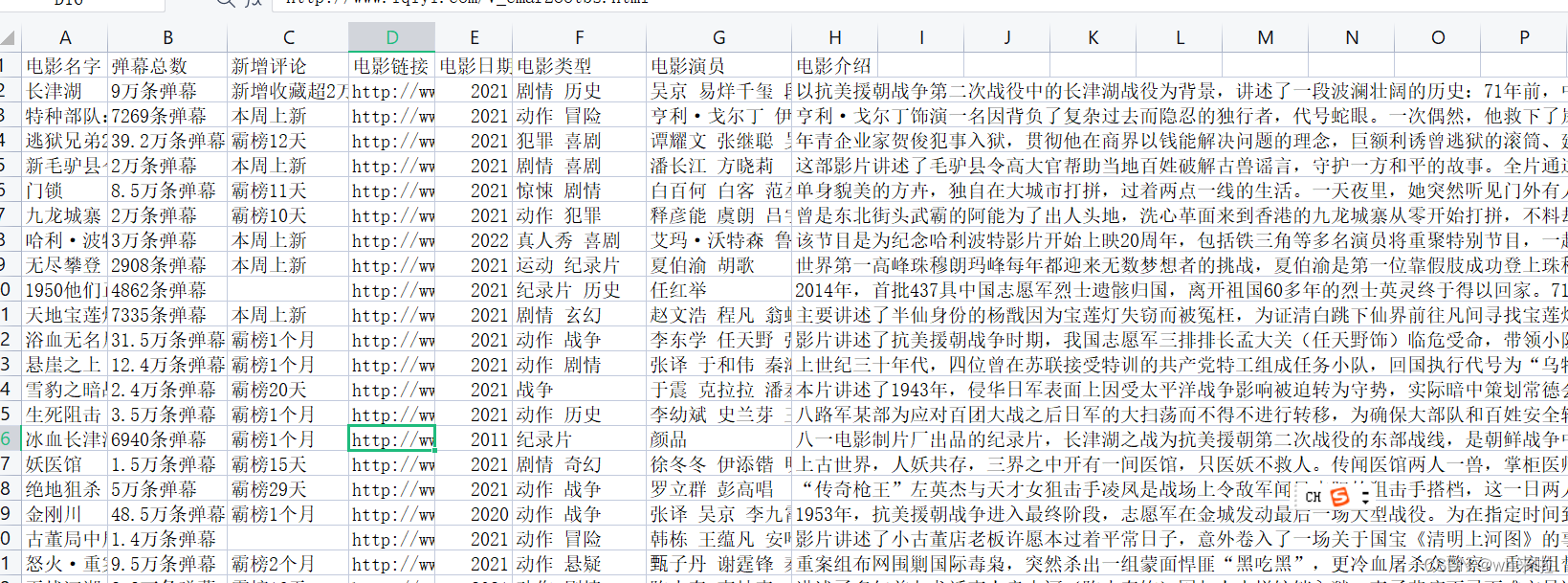
代码实现:
导入包:
import requests
import parsel
import csv设置csv文件格式:
设计未来数据的存储形式。
#打开文件
f = open('whxixi.csv', mode='a',encoding='utf-8',newline='')
#文件列名
csv_writer= csv.DictWriter(f,fieldnames=['电影名字',
'弹幕总数',
'新增评论',
'电影链接',
'电影日期',
'电影类型',
'电影演员',
'电影介绍'])
#输入文件列名
csv_writer.writeheader()获取数据:
获取网页的html,得到原始的数据( 得到的数据保存在response中)。
#选择爱奇艺热播榜的网址
url='https://www.iqiyi.com/ranks1/1/0?vfrm=pcw_home&vfrmblk=&vfrmrst=712211_dianyingbang_rebo_title'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'}
#获取网址内容,赋值 到response
response = requests.get(url=url, headers=headers)加工数据:
对得到的网页原始数据进行加工处理,即提取出有用的数据。备注,根据爬取的网页进行调整css()里面的内容,不同网站页面的结构不同,根据需要进行调整。(F12开发者模式)
#把response.text转换为selector对象 可以使用re, css,x-path选择器
webtext = parsel.Selector(response.text)
#第一步筛选数据,形成列表,可以使下次查找形成循环
list=webtext.css('.rvi__list a')
#再上一步的基础上,使用循环,进行提取数据
for li in list:
title= li.css(' .rvi__con .rvi__tit1::text').get()
bulletcomments =li.css('.rvi__con .rvi__tag__box span:nth-child(1)::text').get() #弹幕总数
newcomments =li.css(' .rvi__con .rvi__tag__box span:nth-child(2)::text').get() #新增评论数
href = li.css(' ::attr(href)').get().replace('//','http://')
movie_info=li.css(' .rvi__con .rvi__type1 span::text').get().split('/')
year = movie_info[0].strip()
type = movie_info[1].strip()
actor = movie_info[2].strip()
filmIntroduction=li.css(' .rvi__con p::text').get().strip()
dic={
'电影名字':title,
'弹幕总数':bulletcomments,
'新增评论':newcomments,
'电影链接':href,
'电影日期':year,
'电影类型':type,
'电影演员':actor,
'电影介绍':filmIntroduction
}
csv_writer.writerow(dic) #将数据输入到csv文件中完整代码:
import requests
import parsel
import csv
f = open('whxixi.csv', mode='a',encoding='utf-8',newline='')
csv_writer= csv.DictWriter(f,fieldnames=['电影名字',
'弹幕总数',
'新增评论',
'电影链接',
'电影日期',
'电影类型',
'电影演员',
'电影介绍'])
csv_writer.writeheader()
#选择爱奇艺热播榜的网址
url='https://www.iqiyi.com/ranks1/1/0?vfrm=pcw_home&vfrmblk=&vfrmrst=712211_dianyingbang_rebo_title'
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62'}
#获取网址内容,赋值 到response
response = requests.get(url=url, headers=headers)
#把response.text转换为selector对象 可以使用re, css,x-path选择器
webtext = parsel.Selector(response.text)
#第一步筛选数据,形成列表,可以使下次查找形成循环
list=webtext.css('.rvi__list a')
#再上一步的基础上,使用循环,进行提取数据
for li in list:
title= li.css(' .rvi__con .rvi__tit1::text').get()
bulletcomments =li.css('.rvi__con .rvi__tag__box span:nth-child(1)::text').get() #弹幕总数
newcomments =li.css(' .rvi__con .rvi__tag__box span:nth-child(2)::text').get() #新增评论数
href = li.css(' ::attr(href)').get().replace('//','http://')
movie_info=li.css(' .rvi__con .rvi__type1 span::text').get().split('/')
year = movie_info[0].strip()
type = movie_info[1].strip()
actor = movie_info[2].strip()
filmIntroduction=li.css(' .rvi__con p::text').get().strip()
dic={
'电影名字':title,
'弹幕总数':bulletcomments,
'新增评论':newcomments,
'电影链接':href,
'电影日期':year,
'电影类型':type,
'电影演员':actor,
'电影介绍':filmIntroduction
}
csv_writer.writerow(dic) #将数据输入到csv文件中















 2896
2896











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









