







问题描述
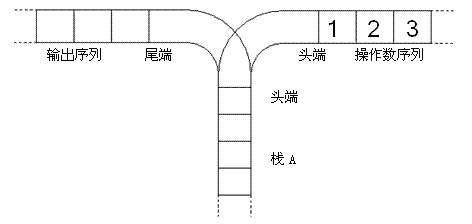
宁宁考虑了这样一个问题:一个操作数序列1,2,…,n(图示为 1 到 3 的情况),栈 A 的深度大于n。
现在可以进行两种操作,
1.将一个数,从操作数序列的头端移到栈的头端(对应数据结构栈的push操作)
2.将一个数,从栈的头端移到输出序列的尾端(对应数据结构栈的pop操作)
使用这两种操作,由一个操作数序列就可以得到一系列的输出序列,下图所示为由 1 2 3 生成序列 2 3 1 的过程。
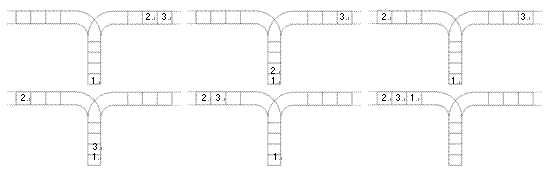
(原始状态如上图所示)
你的程序将对给定的n,计算并输出由操作数序列1,2,…,n 经过操作可能得到的输出序列的总数。
输入格式
输入文件只含一个整数n(1≤n≤18)。
输出格式
输出文件只有一行,即可能输出序列的总数目。
输入输出样例
输入 #1
3
输出 #1
5
问题分析
本问题涉及到了卡特兰算法,但是也有其他的方法能够解决该问题,这里我使用的是dfs法(dfs大法好)。题目的意思是给出一个队列,问这个队列进栈再出栈有多少种不同的排列顺序,这里我们可以设一个二维数组f[x][y],x代表队列中的元素个数,y代表栈中的元素个数,每次递归可以做两件事:
- 将队列中的一个元素进行入栈操作,即f[x-1][y+1]操作
- 将栈里的一个元素进行出栈操作,即f[x][y-1]操作
其中递归的截至条件即为x为0时,即队列中的元素全部都入栈为止,此时return 1;表示只有这一种方法了。同时也要注意操作2有一个限制条件,即y>0才能进行该操作。至此一个dfs的代码就完成啦。
&emps;&emps;但是这样的程序交上去会出现超时的现象,所以需要优化,这里我们可以使用记忆化的方式,即对于已经算好的情况,直接带值运算,无需再算一遍,大大的降低了程序的时间复杂度。最后代码也是成功AC。
代码实现
#include <iostream>
using namespace std;
int f[20][20]; //x表示队列里数的个数,y表示栈里数的个数
int dfs(int x, int y);
int main()
{
int n;
cin >> n;
cout << dfs(n, 0) << endl;
return 0;
}
int dfs(int x, int y)
{
if (f[x][y] != 0) //记忆化,如果已经算过这种情况,直接带值计算
return f[x][y];
if (x == 0) //队列里的数全部入栈,情况唯一
return 1;
if (y > 0) //注意条件
f[x][y] += dfs(x, y - 1); //两件事
f[x][y] += dfs(x - 1, y + 1);
return f[x][y];
}
运行结果
总结
本题主要考察卡特兰算法,这里使用了深度搜索来解决问题,代码简洁明了清晰,所以说dfs大法还是好东西,之后要多加练习。














 1422
1422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









