






流程控制语句:
流程控制语句
-
if 语句
-
switch
1、if 判断
(1)if 语句的基本语法:
if(条件){
// 条件满足的执行
}根据 if 的计算结果是true还是false,JVM决定是否执行 if语句块,即{}花括号包含的所有语句。
注:if语句块可以包含多条语句。
当if语句块只有一行语句时,可以省略花括号{},但是省略花括号并不总是一个好主意,不推荐忽略花括号的写法。
(2)if 语句加上 else { ...}
当条件判断为false时,将执行else的语句块。
if(条件){
// 条件满足的执行
} else {
// 条件不满足的执行
}注:else不是必须的。
(3)多个"if ... else if ..."串联
if(条件1){
// 条件1满足的执行
} else if (条件2){
// 条件2满足的执行
} else {
// 条件1和条件2都不满足才执行
}在串联使用多个if时,要特别注意判断顺序,if语句从上到下执行,只要满足第一个条件后面的就不再执行。
2.switch
switch case 语句判断一个变量与一系列值中某个值是否相等,每个值称为一个分支。
switch case 语句语法格式如下:
switch (expression){
case value:
//语句;
break;//可选
case value:
//语句;
break;//可选
//任意数量的case.
default ://可选
//语句。
}例子:
public class demo10 {
public static void main(String[] args) {
int a = 10;
switch (a) {
case 1:
System.out.println("oo");
break;
case 10:
System.out.println("oo0");
break;
case 11:
System.out.println("0990");
break;
}
}
}
结果:oo0switch case 语句有如下规则:
-
switch 语句中的变量类型可以是: byte、short、int 或者 char。从 Java SE 7 开始,switch 支持字符串 String 类型了,同时 case 标签必须为字符串常量或字面量。(还可以添加枚举类型)
-
switch 语句可以拥有多个 case 语句。每个 case 后面跟一个要比较的值和冒号。
-
case 语句中的值的数据类型必须与变量的数据类型相同,而且只能是常量或者字面常量。
-
当变量的值与 case 语句的值相等时,那么 case 语句之后的语句开始执行,直到 break 语句出现才会跳出 switch 语句。
-
-
当遇到 break 语句时,switch 语句终止。程序跳转到 switch 语句后面的语句执行。case 语句不必须要包含 break 语句。如果没有 break 语句出现,程序会继续执行下一条 case 语句,直到出现 break 语句。
-
switch 语句可以包含一个 default 分支,该分支一般是 switch 语句的最后一个分支(可以在任何位置,但建议在最后一个)。default 在没有 case 语句的值和变量值相等的时候执行。default 分支不需要 break 语句。
-
switch case 执行时,一定会先进行匹配,匹配成功返回当前 case 的值,再根据是否有 break,判断是否继续输出,或是跳出判断。
-
如果 case 语句块中没有 break 语句时,JVM 并不会顺序输出每一个 case 对应的返回值,而是继续匹配,匹配不成功则返回默认 case。
-
如果 case 语句块中没有 break 语句时,匹配成功后,从当前 case 开始,后续所有 case 的值都会输出。
-
如果当前匹配成功的 case 语句块没有 break 语句,则从当前 case 开始,后续所有 case 的值都会输出,如果后续的 case 语句块有 break 语句则会跳出判断。

循环语句:
-
for
-
while
-
do while
1.for循环:
-
for循环语句是支持迭代的一种通用语句,是最有效、最灵活的循环结构
-
for循环执行的次数实在执行前就决定的。语法格式如下
for(初始化;布尔表达式;更新){ //代码语句 }
执行顺序为:初始化-----布尔表达式---------代码语句-------更新
-
如果把初始化放在for循环上面则如果每次从上面进行初始值不变 如:for循环的嵌套
2.while循环:
顺序结构的程序语句只能被执行一次。如果您想要同样的操作执行多次,,就需要使用while循环结构。
语法:
while (expression) {
statement(s)
}while语句计算的表达式,必须返回boolean值。如果表达式计算为true,while语句执行while块的所有语句。while语句继续测试表达式,然后执行它的块,直到表达式计算为false。
-
首先检查while里面的条件,如果是true,则进入while下面的花括号,执行里面的操作。如果是false,则直接跳过while循环,继续运行后面的程序。
-
如果进入了while循环,那么操作完以后,则返回到while后面的圆括号,检查那个条件是否为true, 是的话执行花括号里面的操作,不是的话跳出循环继续后面的程序。
-
重复第二步,直到跳出while循环。
动态的改变while后面的判定条件是很重要的,如果在while循环的花括号里没有改变判定条件,那么有可能导致while循环永远的执行下去,也就是传说中的死循环,我们以后可以解释一下,但是目前就告诉你,死循环就是不断的没有终止的循环。
3.do while
do……while循环格式:
初始化语句 ;
do {
循环体语句 ;
条件控制语句 ;
} while( 条件判断语句 );基本格式:
do {
循环体语句;
} while(条件判断语句);执行流程:
1.执行初始化语句
2.执行循环体语句
3.执行条件控制语句
4.执行条件判断语句,结果为ture,循环继续,结果为false,循环结束。
5.循环继续的话,返回到2.继续操作,直到结果为false。ava循环中三种循环的不同:
4.三种循环语句的不同
1、for循环和while循环是先进行判断在执行,而do……while循环是先执行再判断。
2、for循环中定义的值只属于for循环,离开不能使用,而while循环定义的值可以接着使用
3、对于 while 语句而言,如果不满足条件,则不能进入循环。但有时候我们需要即使不满足条件,也至少执行一次。 do…while 循环和 while 循环相似,不同的是,do…while 循环至少会执行一次。
break 关键字:
break语句可以用在哪里?
1,switch语句当中,用来终止switch语句的执行。
2,用于循环语句当中,用来终止循环的执行
break 主要用在循环语句或者 switch 语句中,用来跳出整个语句块。
break 跳出最里层的循环,并且继续执行该循环下面的语句。(只会终止循环)


continue 关键字:
continue 适用于任何循环控制结构中。作用是让程序立刻跳转到下一次循环的迭代。
在 for 循环中,continue 语句使程序立即跳转到更新语句。
在 while 或者 do…while 循环中,程序立即跳转到布尔表达式的判断语句。
return关键字:
1.在循环体里面使用return跳出循环体。
2.在return后面加上变量,表示该方法有返回值,并用return返回,例如返回return i。
3.最容易被忽视,在方法体里面,单独写return表示结束当前方法体,不会执行该方法后面的所有代码。
break和return的区别:
break是用来跳出循环的,例如for循环,while循环,do-while循环等各种循环体,我们都可以使用break来跳出,但是如果我们是打算跳出函数的话,不能使用break,因为break不能跳出函数。
return是使整个函数返回的,后面不管是循环里面还是循环外面都不执行。
if+return也可以代替复杂的if...else...语句进行流程的控制。
用if+return代替if...else...语句会更清晰
数组
数组的介绍:(Arrary)
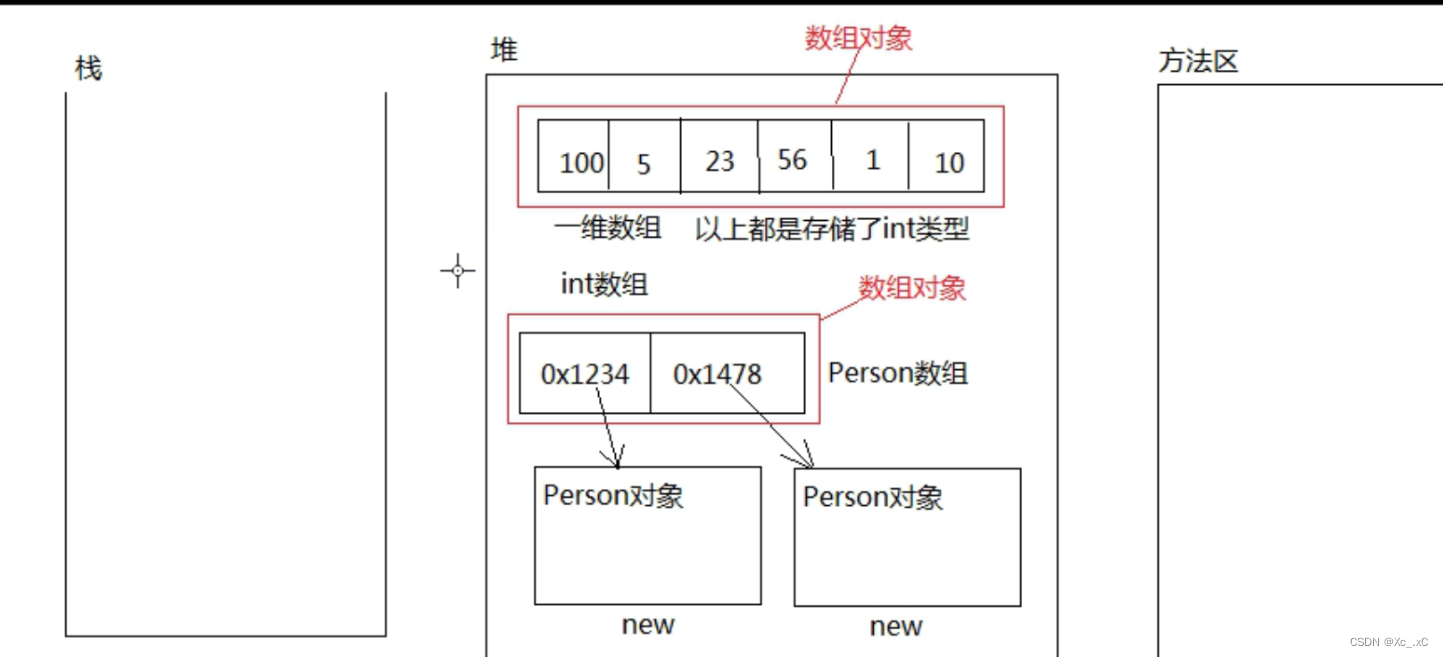
1、java语言中数组是一种引用数据类型。数组父类是Object。
2,数组实际上是一个容器,可以同时容纳多个元素。(数组是一个数据的集合)
3,数组当中可以存储“基本数据类型”,也可以存储"引用数据类型"的数据。
4,数组因为是引用数据类型,所以数组对象是存储在堆内存当中。
5,数组当中如果存储的是Java对象,实际上存储的是对象的“引用(内存地址)”
6,数组一旦创建,在Java中规定,长度是不可变的。
7,数组的分类:一维数组,二维数组,三维数组,多维数组
8,所有数组对象都有length属性(Java自带的),用来获取数组中元素的个数。
9,Java中数组要求数组中元素的类型是统一的。(int类数组只能存储int类型,Person类型数组只能存储Person类型。
10,数组在内存房买你存储的时候,数组中的元素内存地址是连续的。内存地址连续这是数组存储元素的特点。数组实际上是一种简单的数据结构。
11,所有的数组都是拿“第一个小方框的内存地址”作为整个数组对象的内存地址。
数组为什么查询效率高:
1,每一个元素的内存地址在空间上是连续的。
2,每一个元素类型相同,所以占用空间大小是一样的。
3,数组具有下标属性。
结论:知道第一个元素内存地址,知道每一个元素占用空间的大小,又知道下标,所以通过一个数学表达式就可以计算出某个小标上元素的内存地址,直接通过内存地址 定位元素,所以数组的检索效率是最高的。
数组缺点:
1,由于为了保证数组中每个元素的内存地址连续,所以在数组上随即删除或者添加元素的时候,效率较低,因为随机增删元素会涉及到后面的元素统一向前或者向后位移的操作。
2,数组不能存储大数据量,(因为很难在内存空间上找到一块特别大的连续的内存空间)
注意:对于数组中最后一个元素的增删,是没有效率影响的。
数组的格式:
格式一:
动态初始化一维数组:
元素类型 [] 数组名 = new 元素类型 [元素个数或数组长度];
int[] arr = new int[5];(长度为五的int类型数组,每个元素默认是0)
如果是String类型的数组,默认值是null
arr[0] = 1;//给数组第一个元素赋值
arr[1] = 2;//给数组第二个元素赋值格式二:
静态初始化一维数组:
元素类型 []数组名 = new 元素类型[]{元素,元素,……};
int[] arr = new int[]{3,5,1,7};
//注意:[]括号内不能写长度。
int[] arr = {3,5,1,7};注意:int arr[] 也是一种创建数组的格式。推荐使用int [] arr 的形式声明数组。
创建数组的三种方式及区别:
public static void main(String[] args) {
// 1.方式一 声明 分配空间并赋值
int[] arr1 = {1,2,3};
// 2.方式二 显示初始化
int[] arr2;
arr2 = new int[]{1,2,3};
// 3.方式三 显示初始化()
int[] arr3;
arr3 = new int[3];
}他们的区别,方式一:在声明的时候直接就已经分配空间,并赋值,方式一是不能写成如下这种形式的。
int[] arr1;
arr1 = {1,2,3};//错误写法 编译不通过
int[] arr2=new int[3];
arr2={1,2,3};//编译不通过,所以只能如下写:
int[] arr1={1,2,3,4,5};
int[] arr2=new int[3];
arr2[1]=2;
//或者
int[] arr2;
arr2=new int[3]{1,2,3};int[] arr2; 和 int[] arr3;这一步是在栈空间分配一个引用,arr中存放的是一个引用,此时是null。
arr2 = new int[]{1,2,3}; arr3 = new int[3];到这一步的时候jvm才开始在内存堆区域分配空间,并赋值,方式二直接赋值 1,2,3 方式三 默认初始化,基本类型是 0 布尔类型是 false 引用类型为null,
注:内存一旦分配不能改变,所有的数组长度固定
数组的遍历
//数组的遍历
public class demo4 {
public static void main(String[] args) {
int[] arr = {1, 2, 5, 8, 9};
//数组的遍历
//根据数组索引 下标 进行遍历 这里的i就是下标的值
// for(int i=0;i<=arr.length-1;i++){
// System.out.println(arr[i]);
// }
//增强for循环的遍历
//对于属猪的每一个实例直接遍历 所以这里的i表示的是数组中的每一个实例
for (int i : arr) {
System.out.print(i);
}
}
}数组的扩容
System.arraycopy()数组拷贝 src是原数组 ,srcPos(代码中的”1“)原数组下标,dest新数组,destpos”代码中的3“新数组下标,length”代码中的2“拷贝长度
public class demo8 {
public static void main(String[] args) {
//拷贝源
int [] src={1,22,11,3,4};
//拷贝目标(拷贝到这个目标数组上)
int [] dest=new int[6];//动态初始化一个长度为20的数组,每一个元素默认值是0
//调用JDK中System类中arraycopy方法,来完成数组的拷贝
System.arraycopy(src,1,dest,3,2);
//遍历目标数组
for (int i=0;i<dest.length;i++){
System.out.print(dest[i]+" ");
}
结果:0 0 0 22 11 0 
二维数组
1、二维数组其实是一个特殊的一维数组,特殊在这个一维数组的每一个人元素都是一维数组


递归:
什么是递归?
递归,在计算机科学中是指一种通过重复将问题分解为同类的子问题而解决问题的方法。简单来说,递归表现为函数调用函数本身。
递归最恰当的比喻,就是查词典。我们使用的词典,本身就是递归,为了解释一个词,需要使用更多的词。当你查一个词,发现这个词的解释中某个词仍然不懂,于是你开始查这第二个词,可惜,第二个词里仍然有不懂的词,于是查第三个词,这样查下去,直到有一个词的解释是你完全能看懂的,那么递归走到了尽头,然后你开始后退,逐个明白之前查过的每一个词,最终,你明白了最开始那个词的意思。
看一个递归的代码例子吧,如下:
public int sum(int n) {
if (n <= 1) {
return 1;
}
return sum(n - 1) + n;
}递归的特点 1.实际上,递归有两个显著的特征,终止条件和自身调用:
2.终止条件:递归必须有一个终止的条件,即不能无限循环地调用本身。
3.自身调用:原问题可以分解为子问题,子问题和原问题的求解方法是一致的,即都是调用自身的同一个函数。
排序:
一、冒泡排序
冒泡排序(Bubble Sort)就是把小的元素往前调或者把大的元素往后调从而实现从小到大的排序。 依次比较相邻的两个元素大小,若前一个元素大于后一个元素,则交换两个元素,每次比较一轮将最大的一个元素归位(即放到最后)
//冒泡排序
public class demo6 {
public static void main(String[] args) {
int[] arr = {2, 3, 4, 5, 6, 2};
for (int i = 0; i < arr.length - 1; i++) {
boolean flag = false;
for (int j = 0; j < arr.length - 1; j++) {
if (arr[j] > arr[j + 1]) {
arr[j] = arr[j] ^ arr[j + 1];
arr[j + 1] = arr[j] ^ arr[j + 1];
arr[j] = arr[j] ^ arr[j + 1];
flag = true;
}
}
if (!flag) {
break;
}
}
for (int i : arr) {
System.out.print(i);
}
}
}二、选择排序
选择排序(Selection Sort)是一种简单直观的排序算法。首先在未排序的数列中找到最小(or最大)元素,然后将其存放到数列的起始位置;接着,再从剩余未排序的元素中继续寻找最小(or最大)元素,然后放到已排序序列的末尾
//选择排序 第九行的arr.length不能减一
public class demo7 {
public static void main(String[] args) {
int[] arr = {3, 6, 1, 2, 8, 3, 9};
for (int i = 0; i < arr.length - 1; i++) {
int minIndex = i;
for (int j = i + 1; j < arr.length - 1; j++) {
if (arr[minIndex] > arr[j]) {
minIndex = j;
}
}
int temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
for (int i : arr) {
System.out.print(i);
}
}
}三、插入排序
插入排序(Insert Sort)就是每一步都将一个待排数据按其大小插入到已经排序的数据中的适当位置,直到全部插入完毕
四、快速排序
快速排序(Quick Sort)的基本思想:通过一次排序将待排序元素分割成两个独立的部分,其中一部分元素都要比另一部分小,之后对两部分分别排序,最终得到一个有序数列。 算法描述: 1.从数列中选择一个元素作为“基准”,即分割数列 2.排列数列,将所有小于“基准”的元素全都放到左边,将大于“基准”的元素全部放到右边 3.将分割的部分分别递归的排序
//快速排序
public class demo2 {
public static void main(String[] args) {
int arr[]={2,3,4,1,6,8,9};
KuaPai(arr,0,6);
for(int a:arr){
System.out.print(a);
}
}
public static void KuaPai(int arr[], int start, int end) {
if(start>=end||start<0&&end>arr.length-1){
return;
}
int left=start;
int right=end;
int pivot=arr[left];
while (left< right) {
while (right > left && arr[right] > pivot) {
right--;
}
arr[left]=arr[right];
while (right > left && arr[left] < pivot) {
left++;
}
arr[right]=arr[left];
}
arr[left]=pivot;
KuaPai(arr,start, right-1);
KuaPai(arr, left+1,end );
}
}














 3919
3919











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









