







第一章偏向于各种概念的解释,如果对于各种算法没有一个理解的话,看一些地方时会比较吃力,大家在看的时候遇到实在不清楚的地方可以跳过,随着后面章节具体算法的学习,这些概念理论会更加容易理解。
我也是初次对这本教程进行完整学习,有些理解不对的地方请大家指正。
一、统计学习
统计学习是计算机基于数据构建概率模型并运用模型对数据进行预测和分析的学科(统计机器学习)
计算机系统通过运用数据及统计方法提高系统性能的机器学习。
研究对象是数据,目的是对未知数据的预测与分析(已知 → \rightarrow →未知)
实现统计学习方法的步骤:
- 得到一个有限的训练数据集合(研究对象)
- 确定包含所有可能模型的假设空间,即学习模型的集合。
理解:即模型的结构(决策树、线性回归···),参数的维度,参数的取值范围·····这些都属于假设空间的确定,确定了假设空间后,我们进行最优参数的寻找即可
- 确定模型选择的准则,即学习的策略
规定什么样的模型是优秀,如损失函数小的模型/查准率高的模型
- 实现求解最优模型的算法,即学习的算法(梯度下降及其变体)
- 通过学习方法选择最优模型(利用上面的规定进行实际操作)
- 利用学习的最优模型对新数据进行预测或分析(模型使用)
统计学习方法概括:(统计学习方法p4)
- 从给定的、有限的、用于学习的训练数据(trainingdata)集合出发,假设数据是独立同分布产生的;并且假设要学习的模型属于某个函数的集合,称为假设空间;应用某个评价准则,从假设空间中选取一个最优模型,使它对己知的训练数据及未知的测试数据(test data)在给定的评价准则下有最优的预测;最优模型的选取由算法实现。
这样统计学习方法包括模型的假设空间、模型选择的准则以及模型学习的算法。称其为统计学习方法的三要素,简称为模型(model)、策略(strategy)和算法(algorithm)
二、统计学习的分类
1. 基本分类
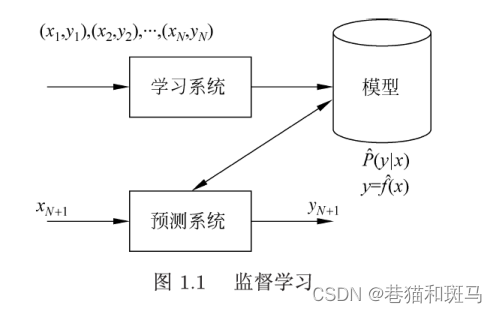
监督学习
从标注数据(需要人工打标签)中学习预测模型。标注数据表示输入与输出的对应关系。
本质:学习输入到输出的映射的统计规律。
(1) 输入空间、特征空间与输出空间
输入空间不一定等于特征空间
例如在核方法中,我们会将输入映射到高维的空间,实现输入空间到输出空间的映射;降维同理
输入空间:输入所有可能取值构成的空间
输出空间:输出所有可能取值构成的空间
特征空间:所有特征向量存在的空间,模型定义在特征空间
(2) 联合概率分布
监督学习假设输入与输出的随机变量X与Y遵循联合概率分布P(X,Y)(分布函数或分布密度函数),即二者之间要存在一定的关系。统计学习假设数据存在一定的统计规律(没有规律也就没有分析的必要),X和Y具有联合概率分布就是监督学习关于数据的基本假设。
The training data and testing data is considered to be generated by the Independent and Identically Distributed of P(X,Y).
(3) 假设空间
监督学习的目的在于学习一个由输入到输出的映射,这一映射(输入到输出的映射的集合)由模型来表示。
假设空间的确定意味着学习范围的确定。
监督学习的模型可以是概率模型或非概率模型,写作P(y|x)或y=f(x)
(4) 问题的形式化
假设训练数据与测试数据是按照联合概率分布P(X,Y)独立同分布产生的。监督学习分为学习和预测两个步骤。
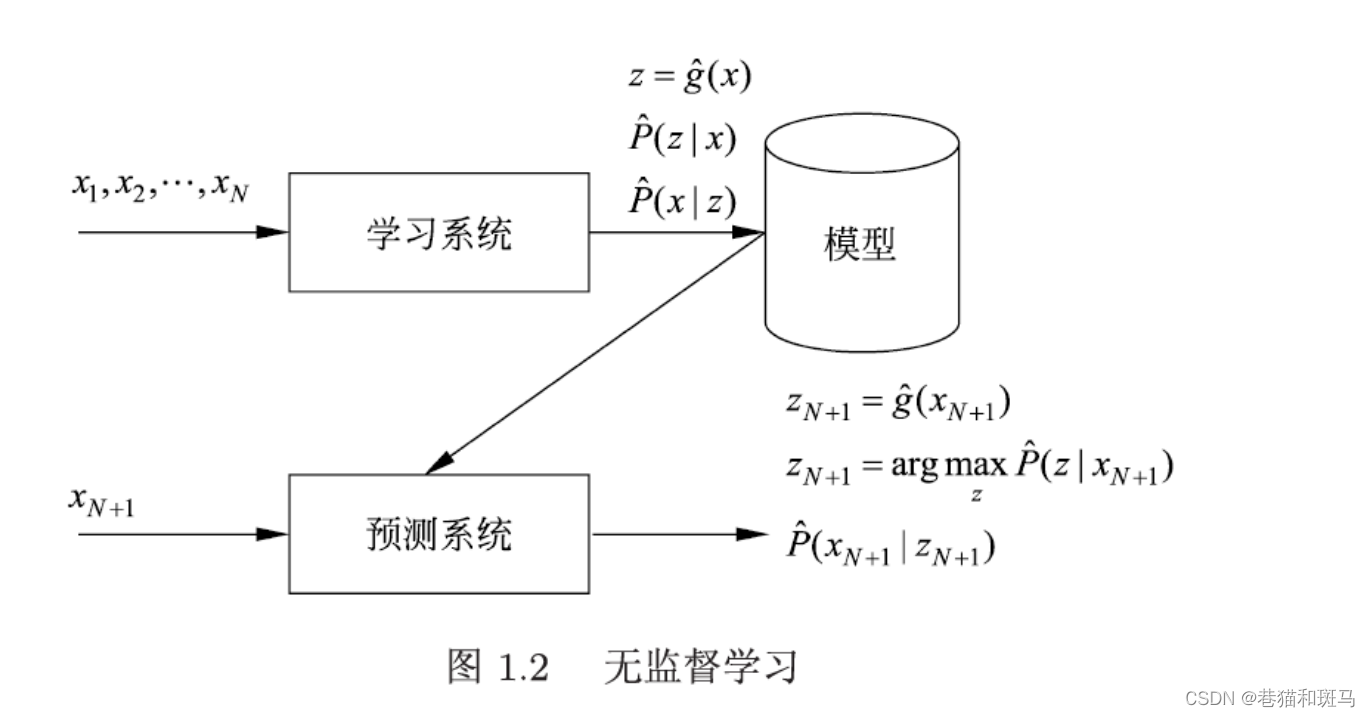
无监督学习
在之后无监督学习的章节会具体介绍,现在只要了解无监督学习是无标注即可
从无标注数据(自然得到的数据)学习中学习预测模型。
本质:学习数据中的统计规律或潜在结构。模型可以实现对数据的聚类、降维或概率估计。
无监督学习旨在从假设空间中选出在给定标准下的最优模型。
无监督学习得到模型,将学得的模型作为预测系统进行工作。
强化学习
强化学习这里由于缺少具体的例子,所以理解起来理论不太清晰,在后面的章节会有具体的介绍,这里有个了解即可
智能系统在与环境的连续互动中学习最优行为策略的机器学习问题。
假设智能系统与环境的互动基于马尔可夫决策过程,智能系统观测到的是与环境互动得到的数据序列。
本质:学习最优的序贯决策。
在每一步t中,智能系统从环境中观测到一个状态 s t s_t st与一个奖励 r t r_t rt,采取一个动作 a t a_t at。环境根据智能系统选择的动作,决定下一步t+1的状态与奖励。
要学习的策略表示为给定的状态下采取的动作。
**智能系统的目标:**不是短期奖励的最大化,而是长期累计奖励的最大化。强化学习的过程中,系统不断地试错,以达到学习最优策略的目的。
强化学习的马尔可夫决策过程是状态,奖励,动作序列上的随机过程,由五元组<S,A,P,r, γ \gamma γ>组成。
-
S是有限状态的集合
-
A是有限动作的集合
-
P是状态转移概率函数:
P ( s ′ ∣ s , a ) = P ( s t + 1 = s ′ ∣ s t = a , a t = a ) P(s'|s,a) = P(s_{t+1}=s' | s_t = a, a_t=a) P(s′∣s,a)=P(st+1=s′∣st=a,at=a)
即状态为 a a a,动作采取为 a a a的条件下,下一个时刻状态 s ′ s' s′发生的概率是多少
-
r是奖励函数: r ( s , a ) = E ( r t + 1 ∣ s t = s , a t = a ) r(s,a) = E(r_{t+1}|s_t = s, a_t = a) r(s,a)=E(rt+1∣st=s,at=a)
在s下采取行动a的奖励的条件下,奖励为 r t + 1 r_{t+1} rt+1
-
γ \gamma γ是衰减系数: γ ∈ [ 0 , 1 ] \gamma \in [0,1] γ∈[0,1]
马尔可夫决策过程具有马尔可夫性,下一个状态只依赖于前一个状态与动作,由状态转移概率函数表示。下一个奖励依赖于前一个状态与动作,由奖励函数r(s,a)表示。
策略(eg:游戏下一步该做什么) π \pi π定义为给定状态下动作的函数a = f(s)或者条件概率分布P(a|s),即状态s下应该采取什么样的a。给定一个策略 π \pi π,智能系统与环境互动的行为就已确定(确定性或随机性)
价值函数/状态价值函数
策略
π
\pi
π从某一个状态s开始的长期积累奖励的数学期望:
v
π
(
s
)
=
E
π
[
r
t
+
1
+
γ
r
t
+
2
+
γ
2
r
t
+
3
+
⋅
⋅
⋅
∣
s
t
=
s
]
v_{\pi}(s) = E_{\pi}[r_{t+1}+\gamma r_{t+2}+\gamma^2r_{t+3}+···| s_t = s]
vπ(s)=Eπ[rt+1+γrt+2+γ2rt+3+⋅⋅⋅∣st=s]
动作价值函数
策略
π
\pi
π的从某一状态s和动作a开始的长期积累的数学期望:
q
π
(
s
,
a
)
=
E
π
[
r
t
+
1
+
γ
r
t
+
2
+
γ
2
r
t
+
3
+
⋅
⋅
⋅
∣
s
t
=
s
,
a
t
=
a
]
q_{\pi}(s,a) = E_{\pi}[r_{t+1}+\gamma r_{t+2}+\gamma^2r_{t+3}+···|s_t = s,a_t = a]
qπ(s,a)=Eπ[rt+1+γrt+2+γ2rt+3+⋅⋅⋅∣st=s,at=a]
强化学习的目标:在所有可能的决策中选出价值函数最大的
π
∗
\pi^*
π∗,在实际学习中往往从具体的策略出发,不断优化已有策略。这里
γ
\gamma
γ表示未来的奖励会有衰减。
强化学习方法中有基于策略的(policy-based)、基于价值的(value–based),这两者属于无模型的(model-free)方法,还有有模型的(model–based)方法。有模型的方法试图直接学习马尔可夫决策过程的模型一包括转移概率函数 P ( s ′ ∣ s , a ) P(s'|s,a) P(s′∣s,a)和奖励函致 r ( s , a ) r(s,a) r(s,a)。这样可以通过模型对环境的反馈进行预测,求出价值函数最大的策略π*。(学习状态转移以及奖励函数来找到最优决策)
无模型的、基于策略的方法不直接学习模型,而是求解最优策略 π ∗ \pi^* π∗,表示为函数 a = f ∗ ( s ) a = f^*(s) a=f∗(s)或条件概率分布 P ∗ ( a ∣ s ) P^*(a|s) P∗(a∣s),这祥也能达到在环境中做出最优决策的目的。学习通常从一个具体策略开始,通过搜索更优的策略进行。(学习具体的策略)
无模型的、基于价值的方法也不直接学习模型,而是试图求解最优价值函数,特别是最优动作价值函数q*(s,α)。这样可以间接地学到最优策略,根据该策略在给定的状态下做出相应的动作。学习通常从一个具体价值函数开始,通过搜索更优的价值函数进行。(学习最优的价值函数,以此来指导最优策略的形成)
半监督学习与主动学习
半监督学习:少量的标注数据+大量的无标注数据
主动学习:机器不断主动给出实例让教师进行批注,然后用标注数据学习预测模型。通常的监督学习使用的标注是随机给定的,可以看作“被动学习”(给出猫狗标注,只能学习猫狗分类)。主动学习可以选出对于学习最有帮助的实例让教师标注,通过较小的代价标注。
2. 按模型分类
(1) 概率模型和非概率模型
在监督学习中,概率模型取条件概率分布形式
P
(
y
∣
x
)
P(y|x)
P(y∣x),非概率模型取函数形式
y
=
f
(
x
)
y = f(x)
y=f(x)。
概率模型:决策树、朴素贝叶斯、隐马尔可夫模型、条件随机场、概率潜在语义分析、潜在迪利克雷分配、高斯混合模型
即在给定输入x的条件下,取什么样的y概率最大
非概率模型:感知机、支持向量机、k近邻、AdaBoost、k均值、潜在语义分析、神经网络是非概率模型
即在给定输入x的条件下,输出一个特定的值或根据该特定的值进行接下来的判断(支持向量机)
区别:
条件概率分布最大化后得到函数,函数归一化也可以得到概率,所以二者的区别不是输入与输出之间的映射关系(映射可以相互转化),而在于模型的内在结构。
概率模型一定可以表示为联合概率分布的形式,而非概率模型不一定存在这样的联合概率分布。
这里的联合概率分布有点不清楚,之后找一些资料学习后回来补充
(2) 线性模型和非线性模型
主要看函数是线性还是非线性
线性模型:感知机、线性支持向量机、k近邻、k均值、潜在语义分析
非线性模型:核函数支持向量机、AdaBoost、神经网络
(3) 参数模型和非参数化模型
参数化模型:假设模型的参数维度固定,模型可以由有限维参数完全刻画;
感知机、朴素贝叶斯、logitic回归、k均值、高斯混合模型
非参数化模型:参数维度不固定,随着寻来你数据量改变;
支持向量机、决策树、AdaBoost、k近邻、潜在语义分析、概率潜在语义分析、潜在迪利克雷分配
3. 按算法分类
在线学习:一个接着一个的输入与更新模型
批量学习:输入一批,通过这一批数据更新一次模型
对应于无法进行数据存储的场景;
这里有一个自己个人的理解,不知道是否准确:
在我进行深度学习的实验时,设置网络训练的一些参数时,会遇到如bach的设置,它代表一次训练的数据量,网络参数的更新取决于这一批数据产生的平均loss,如果一个接一个输入更新网络,会导致每次更新都要改动大量的网络参数,造成模型参数震荡,难以收敛。
4. 按技巧分类
贝叶斯学习
思想:
在概率模型的推理和学习中,利用贝叶斯定理,计算在给定数据条件下模型的条件概率,即后验概率
P
(
y
∣
x
)
P(y|x)
P(y∣x),利用该原理进行模型的估计。使用先验分布是贝叶斯学习的特点。
核方法
思想:
使用核函数表示和学习非线性模型的一种ML方法。有一些线性模型的学习方法基于相似度计算(如采用内积的方式来计算相似度)。核方法将其扩展到非线性空间进行度量。
核函数支持向量机、核PCA、核k均值
线性空间到非线性空间的转换,直接的做法是显示定义从输入空间(低维空间)到特征空间(高维空间)的映射,在特征空间中进行内积的计算。
而核方法的技巧在于不显式定义这个映射,而是直接定义核函数,即映射后在特征空间的内积。
只需要记住核方法可以不显式定义核函数,直接得到两个变量在高维空间的差异,具体的解释在后面的支持向量机章节具体解释
三、统计学习方法的三要素
方法 = 模型 + 决策 + 算法
1. 模型
模型就是所要学习的条件概率分布或决策函数。模型的假设空间包含所有可能的条件概率分布或决策函数。
2. 策略
有了模型的假设空间,统计学习接着需要考虑按照什么样的准则学习或选择最优模型。
损失函数和风险函数
损失函数:度量模型一次预测的好坏
风险函数:度量平均意义下模型预测的好坏
(1) 0-1损失函数
(2) 均方误差损失函数
(3) 绝对损失函数
(4) 对数损失函数
L
(
Y
,
P
(
Y
∣
X
)
)
=
−
l
o
g
P
(
Y
∣
X
)
L(Y,P(Y|X))= -logP(Y|X)
L(Y,P(Y∣X))=−logP(Y∣X)
可以这样理解:当P(Y|X)为1时,代表没有误差,所以损失为0;当P(Y|X)为0时,代表完全错误,损失为
+
∞
+\infty
+∞。
损失函数的期望(风险函数)是:
∫
L
(
y
,
f
(
x
)
)
P
(
x
,
y
)
d
x
d
y
\int L(y,f(x))P(x,y) dxdy
∫L(y,f(x))P(x,y)dxdy
但是P(x,y)未知,如果知道P(x,y),可以直接求出P(y|x),也就不需要学习了。因此,我们使用经验风险/经验损失来近似估计:
1
N
∑
i
=
1
N
L
(
y
i
,
f
(
x
i
)
)
\frac{1}{N}\sum_{i=1}^N L(y_i,f(x_i))
N1i=1∑NL(yi,f(xi))
根据大数定律,当N足够大时,通过经验风险估计风险函数会比较准确;但是由于我们在ML中,training data一般之占有很小的一部分,所以只考虑经验风险这一个策略会发生过拟合,因此,我们又引入了结构风险最小化策略(即在测试集上的误差),通过正则化的方式进行。
3. 算法
指学习模型的具体计算方法。统计学习基于training data,根据学习策略,从假设空间中选择最优的模型,最后需要考虑用什么样的计算方法求解最优模型。(最优化求解问题,如梯度下降等)
四、模型评估与模型选择
1. 训练误差与测试误差
即在考虑训练误差的同时,给损失函数加入正则化项,限制模型的复杂程度。
模型的误差 = 偏差+方差
偏差 = 模型在training data上的误差
方差 = 模型在test data上的误差
2. 过拟合与模型选择
防止过拟合就是要考虑经验误差的同时降低结构误差;
模型的选择遵循奥卡姆剃刀原理,即尽可能选择简单的模型,防止过拟合。
五、正则化与交叉验证
这是两种模型选择两种常用的方法
1. 正则化
结构风险最小化策略的实现。
正则化项可以为 L 1 L_1 L1范数,也可以为 L 2 L_2 L2范数。
m
i
n
f
∈
F
1
N
∑
i
=
1
N
L
(
f
(
y
i
,
f
(
x
i
)
)
+
λ
J
(
f
)
min_{f \in F}\frac{1}{N}\sum_{i=1}^NL(f(y_i,f(x_i)) + \lambda J(f)
minf∈FN1i=1∑NL(f(yi,f(xi))+λJ(f)
我们通过最小化上面的式子即可
2. 交叉验证
交叉验证与正则化的区别是:没有改变损失函数的式子,而是通过将data分离出一部分作为test data,保证最后得到的模型在training data表现良好的同时,在test data上同样取得较好的表现。
六、泛化能力
1. 泛化误差
通过测试误差来评价泛化能力。
2. 泛化误差的上界
学习方法的泛化能力分析往往是通过研究泛化误差的概率上界进行–泛化误差上界。
性质:
- 样本容量的函数,当样本容量增加,泛化上界趋于0
- 假设空间容量的函数,假设空间容量越大,模型就越难学,泛化误差上界就越大;
之所以可以通过泛化误差上界来进行泛化能力的度量,是因为一下定理的成立:
对于二分类问题,当假设空间是有限个函数的集合
F
=
f
1
,
f
2
,
⋅
⋅
⋅
,
f
d
F = {f_1,f_2,···,f_d}
F=f1,f2,⋅⋅⋅,fd时,对于
∀
f
∈
F
\forall f \in F
∀f∈F,至少以概率
1
−
σ
1 - \sigma
1−σ,使得一下不等式成立:
R
(
F
)
≤
R
′
(
f
)
+
ϵ
(
d
,
N
,
σ
)
R(F) \leq R'(f) + \epsilon(d,N,\sigma)
R(F)≤R′(f)+ϵ(d,N,σ)
左端
R
(
f
)
R(f)
R(f)为泛化误差,右端为泛化误差的上界。泛化误差上界的第一项为训练误差,训练误差越小,泛化误差也越小;第二项为N的单调递减函数,当N趋向于无穷时趋于0。
即泛化误差小于泛化误差的上界,泛化误差上界越小,泛化能力越强。
这里有点不清晰,之后理解更深入后回来补充,具体推导参考《统计学习方法 第二版》p27
七、生成模型与判别模型
二者目的都是在使后验概率P(Y|X)最大化,判别式是直接对后验概率建模,但是生成模型通过贝叶斯定理这一“桥梁”使问题转化为求联合概率
一个是通过已有数据学习数据的分布,一个是通过已有的数据学习解决问题的分类边界;
我的理解是判别模型针对性更强,对于给定的分类问题可以有较好的表现;生成模型的可解释性更强,它通过对已有数据进行学习,得到(X,Y)的分布情况,不仅可以预测,也可以进行数据生成。
1. 生成模型
由数据学习联合概率分布P(X,Y),然后求出条件概率分布P(Y|X)为预测模型,即生成模型:
P
(
Y
∣
X
)
=
P
(
X
,
Y
)
P
(
X
)
P(Y|X) = \frac{P(X,Y)}{P(X)}
P(Y∣X)=P(X)P(X,Y)
贝叶斯定理将P(Y|X)转为联合概率P(X,Y)

在进行生成模型的预测时,对于一个输入,我们将它与所有的输出Y的可能取值分别进行组合生成联合概率分布P(X,Y) = P(Y=y)P(X|Y=y)。
特点:
- 通过学习P(X,Y),可以学习到数据是如何产生的。
- 生成模型不仅能够用于分类任务,还可以用于生成新的数据样本,因为它们掌握了数据生成的机制概率分布P(X,Y),这也是为什么叫做生成模型。
- 但生成模型通常需要更多的数据来准确估计概率分布,并且计算复杂度较高。
代表:
高斯混合模型(Gaussian Mixture Model, GMM)、隐马尔可夫模型(Hidden Markov Model, HMM)、朴素贝叶斯分类器(Naive Bayes Classifier)、变分自编码器(Variational Autoencoder, VAE)和生成对抗网络(Generative Adversarial Network, GAN)等。
2. 判别模型
直接学习决策函数 f ( X ) f(X) f(X)或者条件概率分布 P ( Y ∣ X ) P(Y|X) P(Y∣X)作为预测模型。
判别模型主要用于分类或回归任务
在进行判别模型的预测时,对于一个输入,直接产生一个对应的输出,作为预测的结果。有点类似于黑盒。它们不关心数据是如何生成的,只关心如何最好地区分或预测数据。
代表:
逻辑回归(Logistic Regression)、支持向量机(Support Vector Machine, SVM)、决策树(Decision Tree)、随机森林(Random Forest)、多层感知器(Multilayer Perceptron, MLP)和卷积神经网络(Convolutional Neural Network, CNN)等。
八、监督学习的应用
1. 分类问题
输出变量Y取有限个离散值。
2. 标注问题
输入一个观测序列,输出一个标记序列或状态序列。
这个问题在信息抽取、自然语言处理等邻域广泛应用,如NLP中的词性标注问题。
3. 回归问题
即数据的拟合预测,输出一般取连续值。















 186
186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









