







 本文介绍了神经网络如何通过加深网络层次并引入激活函数,从多层感知机发展为学习非线性分布的模型。重点讲解了梯度反向传播在参数学习中的作用,强调激活函数对非线性区分的关键作用,以及与传统函数调整的区别。
本文介绍了神经网络如何通过加深网络层次并引入激活函数,从多层感知机发展为学习非线性分布的模型。重点讲解了梯度反向传播在参数学习中的作用,强调激活函数对非线性区分的关键作用,以及与传统函数调整的区别。
神经网络
1. 提出背景
关键记住:多层感知机只有输入输出两层,神经网络是多层感知机,同时通过激活函数引入了非线性因素
**支持向量机的原理:**在一个线性空间中,找到划分正负样本的超平面,下图为支持向量机的一个构造:
- 在输出层只有一个简单的越阶激活函数,大于0判断为1,小于0判断为0
- 如果感知机的输入加权和(即所有输入乘以其对应权重的和再加上偏置)大于或等于零,激活函数的输出为1。
- 如果输入加权和小于零,激活函数的输出为0。

可以从构造上看出,它类似于一个只有两个输入的神经网络。通过这个网络,我们可以处理如下的一些简单问题:
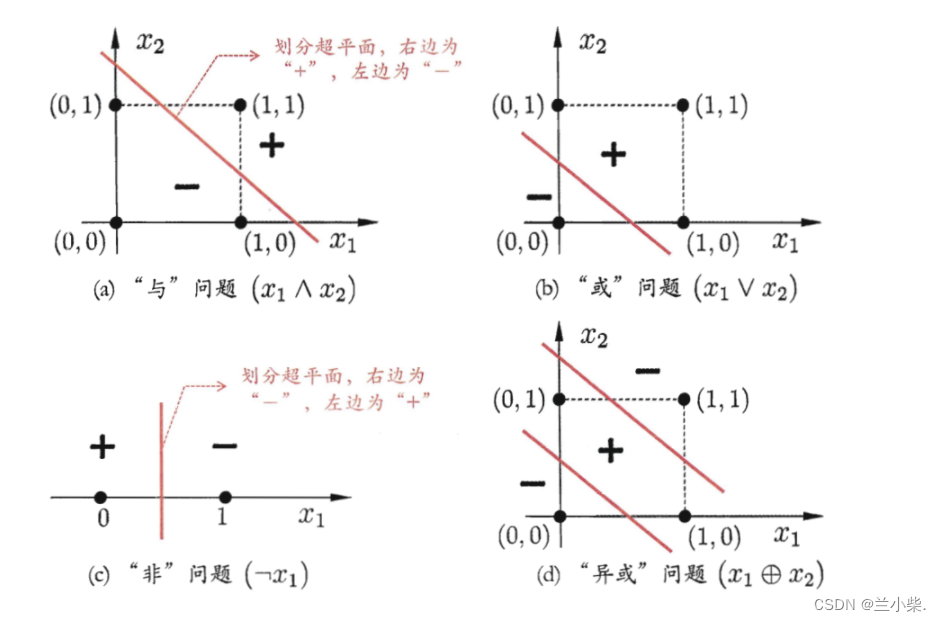
对于与问题:(1,1)为正,其他均为负,我们一定可以找到一个线性超平面进行划分,见图1;
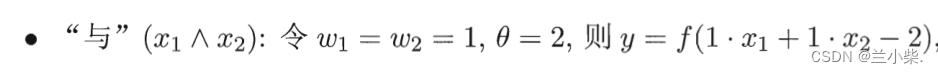
对于或问题:(0,0)为负,其他均为正,见图2
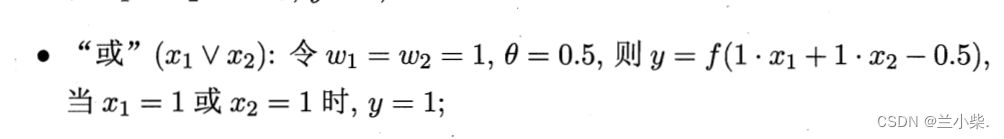
对于非问题:0为正,1为负,见图3
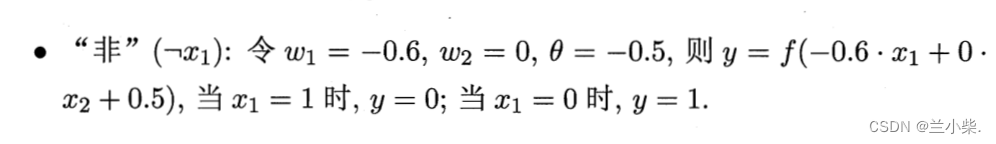
对于异或问题:(0,1)(1,0)为正,(0,0)(1,1)为负,见图4.我们从直觉就可以判断,绝对不存在相应的线性超平面(直线)可以进行正负样本的划分,至少要两条线。所以,两层的感知机已经无法学习到我们需要的模型。尽管这个模型在我们人类眼里简单无比。
因此,我们考虑加深网络的层数,也许就能在感知机的基础上,创造出更加优秀的可以学习非线性分布的函数。
神经网络由此诞生。
其中阈值代表只有达到了对应的值才能输出,否则为0。是一个简单的激活函数。
我们可以将(0,0)(1,1)分别代入,会发现满足我们的要求。
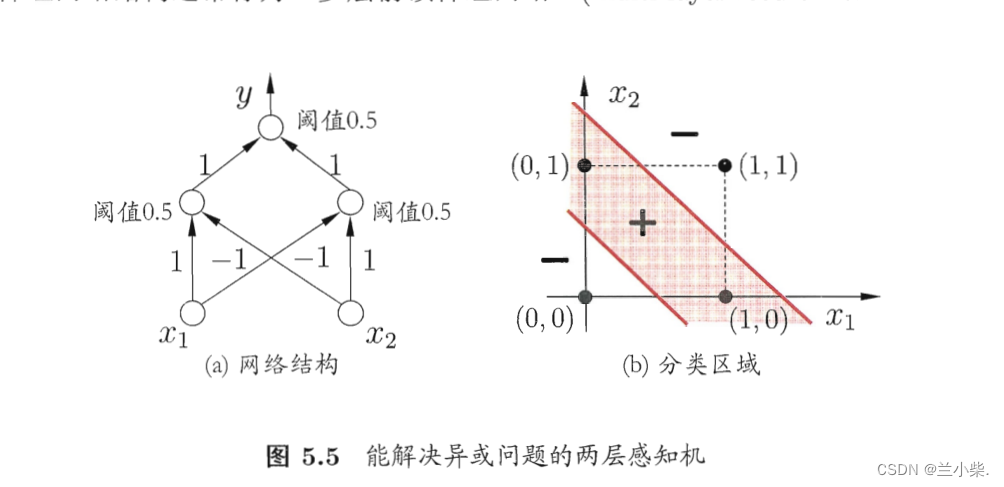
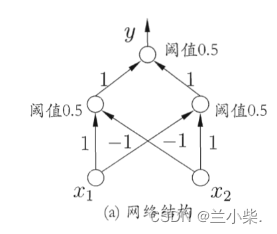
如上图所示,通过增加一个隐层(加深感知机的层数)以及在每个隐层神经元增加激活函数我们就可以实现非线性平面的划分。
这里有一个特别需要注意的点:让神经网络能够划分非线性平面的,不是因为增加了网络的层数,很多人会误解这一点,认为神经网络是黑盒子,层数堆的越多就可以学习任何线性和非线性空间。
我们来看一个简单的例子:如果没有激活函数,我们模型函数是什么样的呢(假设学习到的参数从左到右为1,2,3,4)?
隐藏层的第一个神经元: y 1 = x 1 + 3 x 2 y_1 = x_1 + 3x_2 y1=x1+3x2
隐藏层的第二个神经元: y 2 = 2 x 1 + 4 x 2 y_2 = 2x_1 + 4x_2 y2=2x1+4x2
输出层: y = y 1 + y 2 = 3 x 1 + 7 x 2 y = y_1 + y_2 = 3x_1 + 7x_2 y=y1+y2=3x1+7x2
你可以自己增加任意层数的神经网络和参数,在没有激活函数的条件下,你最后学到的函数只能是一条直线,不可能会进行非线性空间的划分。
所以,激活函数才是为神经网络引入非线性因素的关键。通过我们的常用激活函数sigmoid就可以看出:
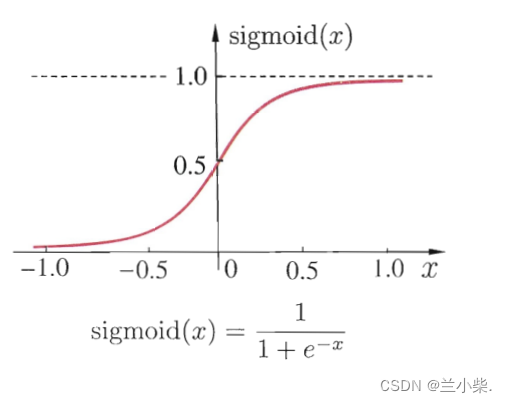
神经元在计算后经过激活函数的引射,引入了非线性因素,可以让我们很好地学习到空间中的非线性因素。
这里有的同学又会提出疑问,那relu激活函数呢,它看起来是线性函数,为什么也会为神经网络引入非线性因素呢?
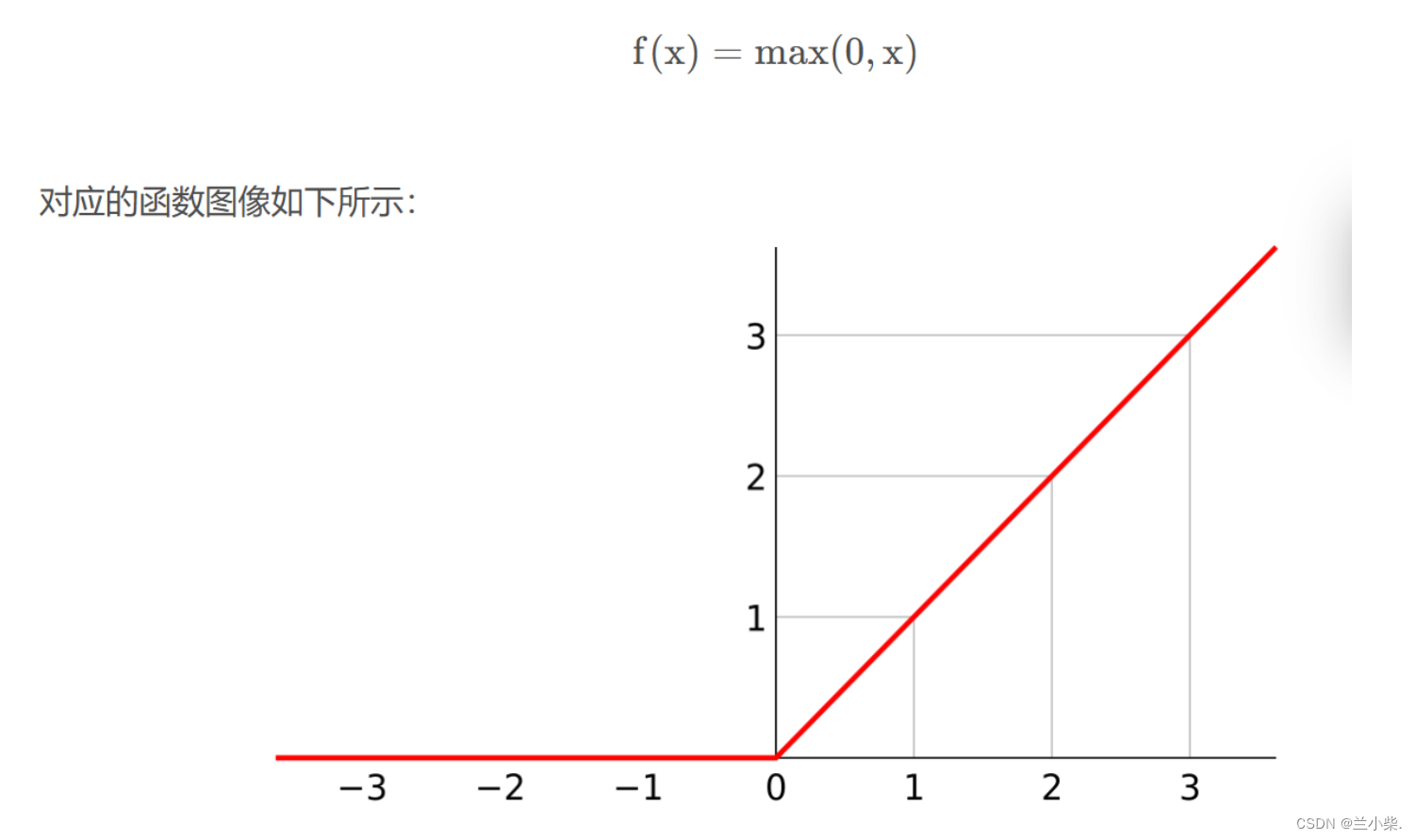
这里大家要注意线性的定义,relu只是在正负半轴各自表现为线性,但整体上为非线性函数。
所以,在学习神经网络时,我们不要再把目光只是放在显而易见的网络层次之上,每一层背后的激活函数才是它区别于感知机的关键。
老师面试问题:
为什么要使用激活函数:为神经网络引入非线性因素。
2. 思想
通过上述的介绍,神经网络的结构已经很清晰了,即在感知机的基础上加深网络层次的同时,引入了各种各样的激活函数来为模型增加非线性划分的能力。
输入我们搞清楚了,那这个模型是如何进行如此多参数的学习呢?
梯度的反向传播就是在这个过程中发挥作用,我们在随机选定初始化参数后,通过神经网络的输出与实际标签计算损失函数,通过求每个参数的梯度来确定调整的方向,学习率确定调整的步长,以此作为参数的更新方式,最小化损失函数。
3. 反向传播
首先,我们来明确几件事情:
-
**神经网络的本质:**其实就是一堆线性函数+激活函数后形成的非线性模型,它的参数大小取决于我们设置多少层网络,但是它的
本质上只是一个函数 -
**梯度与梯度下降法的理解:**梯度的求法其实就是求导数的过程。我们来看一个简单的例子
y = 2x,在这个函数中,x是未知数,假设我们此时的输入为x=2,y=2x2= 4。现在我们想要让y这个输出变小,那么就需要改变x的值,那么朝哪个方向改变呢?来看
y=2x对x求导数,得到grad=2,梯度代表着当前函数沿着哪个方向上升最快,因为我们目前假设的函数只有一个未知数,所以方向要么是往x正向调整,要么就往x负向调整,我们的目的是减小输出,所以我们要朝着下降最快即上升最快的反方向(梯度的反方向来调整x,即-grad=-2。规定了方向,我们还需要确定x需要移动的距离,这就是我们经常听说的学习率的概念,即一次调整要朝着该方向移动多远。综上,
y=2x,x=2,grad=2,学习率=0.5, x ′ = x − 学习率 ∗ g r a d = 2 − 2 ∗ 0.5 = 1 x' = x - 学习率* grad = 2 - 2*0.5 = 1 x′=x−学习率∗grad=2−2∗0.5=1。将x'带入y=2x = 2,可以看出,通过这种方式,我们完成了降低输出的目的。 -
神经网络函数与普通函数调整的区别:
我们调整普通函数时,输入x是未知数;在调整神经网络函数时,我们的输入是已知的,即我们要预测的图片或向量数据,但函数的参数,即各个神经元的连接w是未知的。所以在对神经网络函数求梯度时,我们要以 w 1 , w 2 , ⋅ ⋅ ⋅ , w n w_1,w_2,···,w_n w1,w2,⋅⋅⋅,wn求导
通过上面的解释,我们会发现,神经网络的思路是这样的:
- 选定网络层数与激活函数,初始化网络开始的参数
- 输入训练数据,得到训练的结果y,真实标签为label
- 损失函数计算 ( l a b e l − y ) 2 (label - y)^2 (label−y)2
- 目的是最小化损失函数,因为在神经网络模型中,我们通过参数的调整来进行损失的调整
- 因此,接下来要对各个参数求梯度,通过指定的学习率进行更新
那为什么要叫梯度的反向传播呢?
我们通过下面一个例子说明:
我们的目的是: m i n ( ( l a b e l − y ) 2 min((label-y)^2 min((label−y)2,为了简单,我们使用了均方误差损失函数,不考虑损失函数
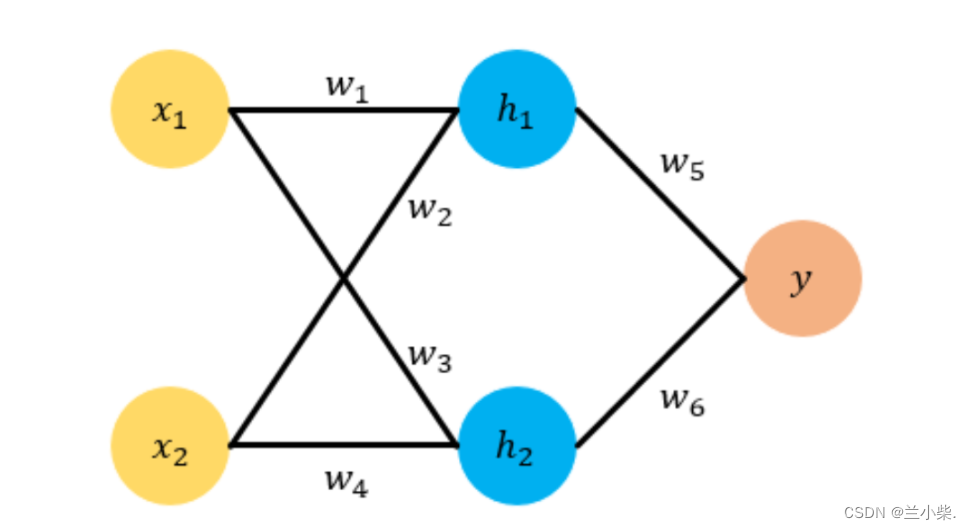
接下来,我们要更新参数,首先计算各个参数的梯度来确定参数更新方向:
目标函数为: l o s s = ( l a b e l − y ) 2 loss = (label - y)^2 loss=(label−y)2,其中, y = w 5 h 1 + w 6 h 2 = w 5 ( w 1 x 1 + w 2 x 2 ) + w 6 ( w 3 x 1 + w 4 x 2 ) y = w_5h_1 + w_6h_2 = w_5(w_1x_1 + w_2x_2) + w_6(w_3x_1 + w_4 x_2) y=w5h1+w6h2=w5(w1x1+w2x2)+w6(w3x1+w4x2)
h 1 = w 1 x 1 + w 2 x 2 h_1 = w_1x_1 + w_2x_2 h1=w1x1+w2x2
对 w 1 w_1 w1求导: α ( l o s s ) α ( w 1 ) = α ( l o s s ) α ( y ) ∗ α ( y ) α ( w 1 ) = α ( l o s s ) α ( y ) ∗ α ( y ) α ( h 1 ) ∗ α ( h 1 ) α ( w 1 ) = − 2 ( l a b e l − y ) ∗ w 5 ∗ x 1 \frac{\alpha(loss)}{\alpha (w_1)} = \frac{\alpha(loss)}{\alpha (y)}*\frac{\alpha (y)}{\alpha(w_1)} = \frac{\alpha(loss)}{\alpha (y)}*\frac{\alpha (y)}{\alpha(h_1)}*\frac{\alpha(h_1)}{\alpha(w_1)} = -2(label-y)*w_5*x_1 α(w1)α(loss)=α(y)α(loss)∗α(w1)α(y)=α(y)α(loss)∗α(h1)α(y)∗α(w1)α(h1)=−2(label−y)∗w5∗x1
通过上式,我们可以看到链式求导和反向传播的综合应用















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









