







1. JVM内存区域划分
Java进程在启动的时候,就会在操作系统申请一大块内存,然后把这一大块内存划分成不同的区域,每个区域执行不同的任务。
主要的划分方式,是划分为如下几个区域:
- 堆
- 栈
- 程序计数器
- 方法区
1. 堆
堆中存放的就是:程序中创建(new)的所有对象
2. 栈
在Java1.8之前,栈区分为:Java虚拟机栈和本地方法栈。
- Java虚拟机栈中存放Java代码。
- 本地方法栈中存放JVM内部的C++代码,即本地方法(被native关键字修饰的方法就是本地方法)。
在Java1.8的时候,对Java虚拟机栈和本地方法栈进行了合并。
栈中最关键的信息:
- 方法之间的调用关系
- 局部变量
3. 方法区
方法区存放的是类对象。

类对象怎么来的?
我们写的.java文件,会被编译成 .class文件,在类加载的时候,JVM会把
.class文件加载到内存当中,构造出类对象。
4. 程序计数器
程序计数器器就相当于一个书签,用它来记录程序进行到那个指令了,即存储下一个要执行指令的地址
【易错点】变量存储的位置
在我们创建的变量中,判断一个变量存在哪里,主要看它的形态:
局部变量存储在栈区
成员变量存储在堆区
静态变量存储在方法区
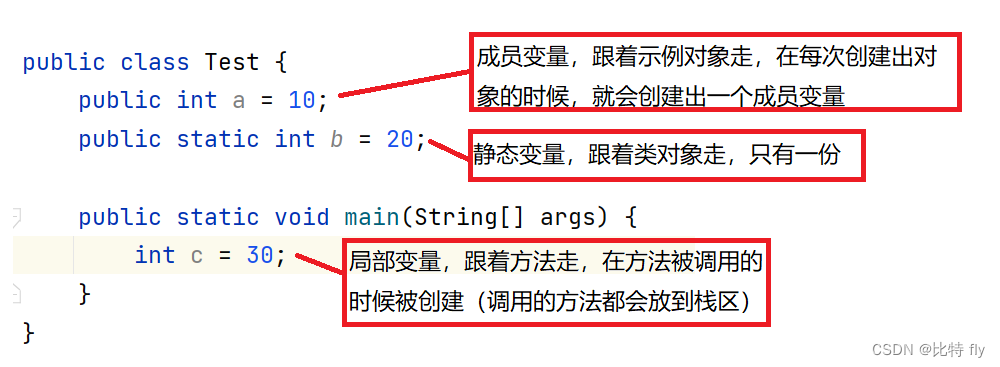 可以得出结论:变量跟着谁走,就存在那个区域
可以得出结论:变量跟着谁走,就存在那个区域
【考点】各个内存区域在进程中的数量关系
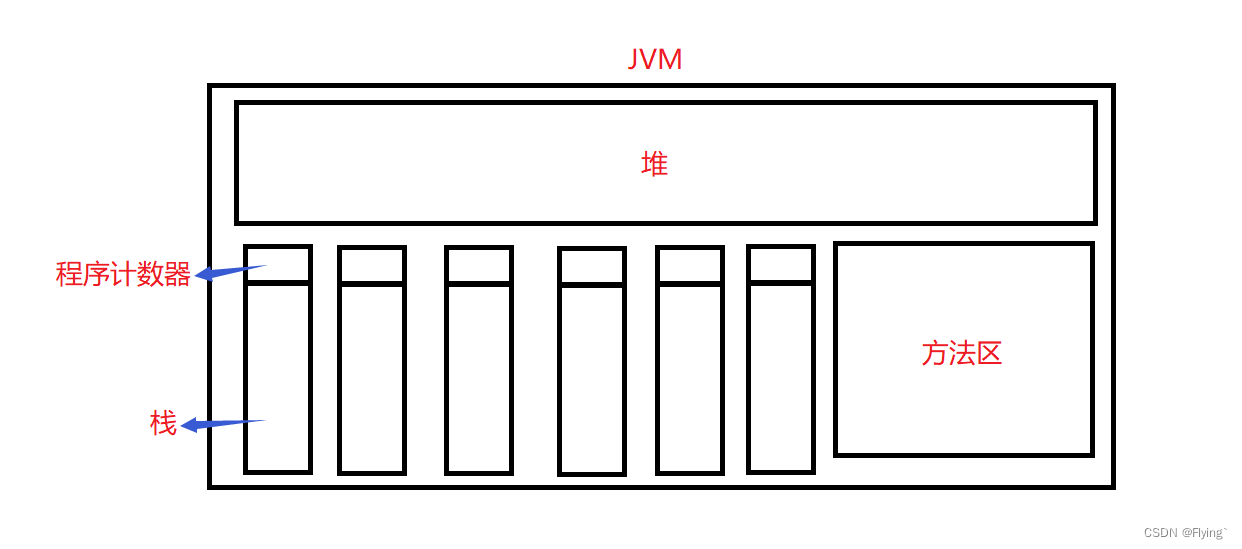
在一个进程当中:堆和方法区的空间只有一份,所有的线程共享这两个区域;而程序计数器和栈是线程私有的,所有的线程都独有一份。
原因分析:
- 对于每个线程来说,他们得知道自己执行的调用流程,也得知道自己下一步执行什么指令,这就需要有专门得区域区记录。
- 如果多个线程共用一个栈区和方法区,在保证程序不出错得情况下,那就得是单线程进行了,显然这是不可取的。
【考点】栈溢出和堆溢出(内存溢出)
- 栈溢出:报StackOverflowException错误,解决方法就是:检查是否是方法的调用层数太多了,比方说递归没有设置截至条件,导致“无限递归”
- 堆溢出:又叫内存溢出,报OutOfMemoryException错误,解决方法就是:检查是否是new的对象太多了,比如反复new一个对象而没有及时的清理就会导致堆溢出。
堆溢出还可能有两个原因:
- 内存泄漏,泄露的对象没有被及时回收
- 堆内存设置不足,此时就要根据JVM 堆参数与物理内存相比检查是否应该将JVM堆内存调大;
- 或者检查对象的生命周期是否过长。
- 数据结构的选择不合理,选用合适的数据结构可以减少堆内存的开销
2. JVM类加载机制
2.0.什么是类加载
java代码经过编译器编译生成.class文件,它是存储在硬盘里面的。Java进程启动时(JVM启动),需要将.class文件凶硬盘读取到内存中,并构造出类对象,这个过程就叫做类加载
2.1. 类加载的过程
- 加载(Loading):找到.calss文件并打开读取文件内容,并创建类对象,将数据先填充到类对象
- 链接(Linking):将.class文件里面的内容进行解析/校验
- 验证:这一阶段的目的是确保Class文件的字节 流中包含的信息符合《Java虚拟机规范》的全部约束要求,保证这些信 息被当作代码运行后不会危害虚拟机自身的安全
- 准备:准备阶段是正式为类中定义的变量(即静态变量,被static修饰的变量)分配内存并设置类变量初始值的阶段。
- 解析:解析阶段是 Java 虚拟机将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程
- 初始化(Initializing):Java 虚拟机真正开始执行类中编写的 Java 程序代码,将主导权移交给应用程序。初始化阶段就是执行类构造器方法的过程。
3. 双亲委派模型
什么是双亲委派模型
- 它描述的是类加载时的 “加载” 阶段
- 如果一个加载器收到一个类加载的请求,它不会立即进行类加载,他会先将请求传递给父类加载器,每层以此传递,直到最顶层。
- 当父类加载器无法完成类加载时,子类再尝试进行加载,子类还是不行的话,子类的子类再进行尝试类加载…
Java中的类加载器
Java中自带了三个类加载器:

双亲委派模型的工作过程
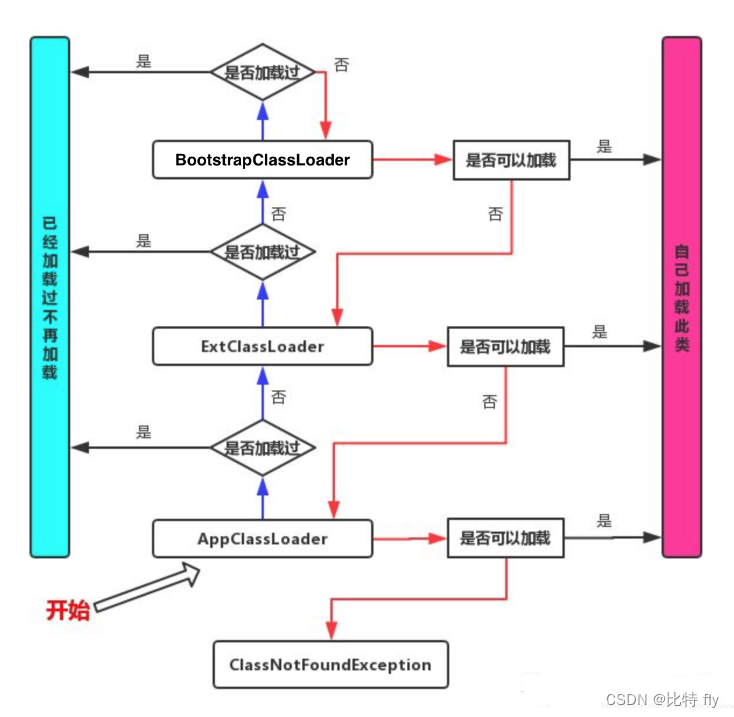
为什么要从BootStrapClassLoader开始自上而下加载
- 避免重复加载类:比如 A 类和 B 类都有一个父类 C 类,那么当 A 启动时就会将 C 类加载起来,那么在 B 类进行加载时就不需要在重复加载 C 类了。
- 安全性:使用双亲委派模型也可以保证了 Java 的核心 API 不被篡改,如果没有使用双亲委派模型,而是每个类加载器加载自己的话就会出现一些问题,比如我们编写一个称为 java.lang.Object 类的话,那么程序运行的时候,系统就会出现多个不同的 Object 类,而有些 Object 类又是用户自己提供的因此安全性就不能得到保证了。
为什么要从AppClassLoader开始自下往上找
- 我认为从BootStrapClassLoader自上而下开始找理论上是可以的,它不仅不会引起安全问题,也不会引起类的重复加载。
- 但是在类加载中,大多数加载的都是AppClass,这时如果是自上而下开始找,那查找的效率就很低。
- 所以先从AppClass开始加载,高频使用,提高效率。
4. JVM垃圾回收机制(GC)
0. 那些区域要进行垃圾回收
对于程序计数器、栈这两部分区域而言,其生命周期与相关线程有关,随线程而生,随线程而灭。并且这三个区域的内存分配与回收具有确定性,因为当方法结束或者线程结束时,内存就自然跟着线程回收了。因此我们有关内存分配和回收关注的为Java堆与方法区这两个区域
- 程序计数器:这个空间是固定的,每一个线程都有一个程序计数器,它跟随线程一起被销毁,所以不需要GC。
- 栈区:这里主要存放的局部变量,局部变量约定了作用域,出来作用域就被销毁,所以不需要GC。
- 方法区:放的是类对象,主要干的是类加载,很少会有类加载,需要GC,但是不迫切。
- 堆区:放的主要是new的对象,对象在用完之后,就要及时清理,所以需要GC。
1. 垃圾回收的单位
垃圾回收的单位是对象,不是字节,当一个对象的一半在使用,一般没使用的时候,这个对象是不能被释放的。
2. 死亡对象的判断方法
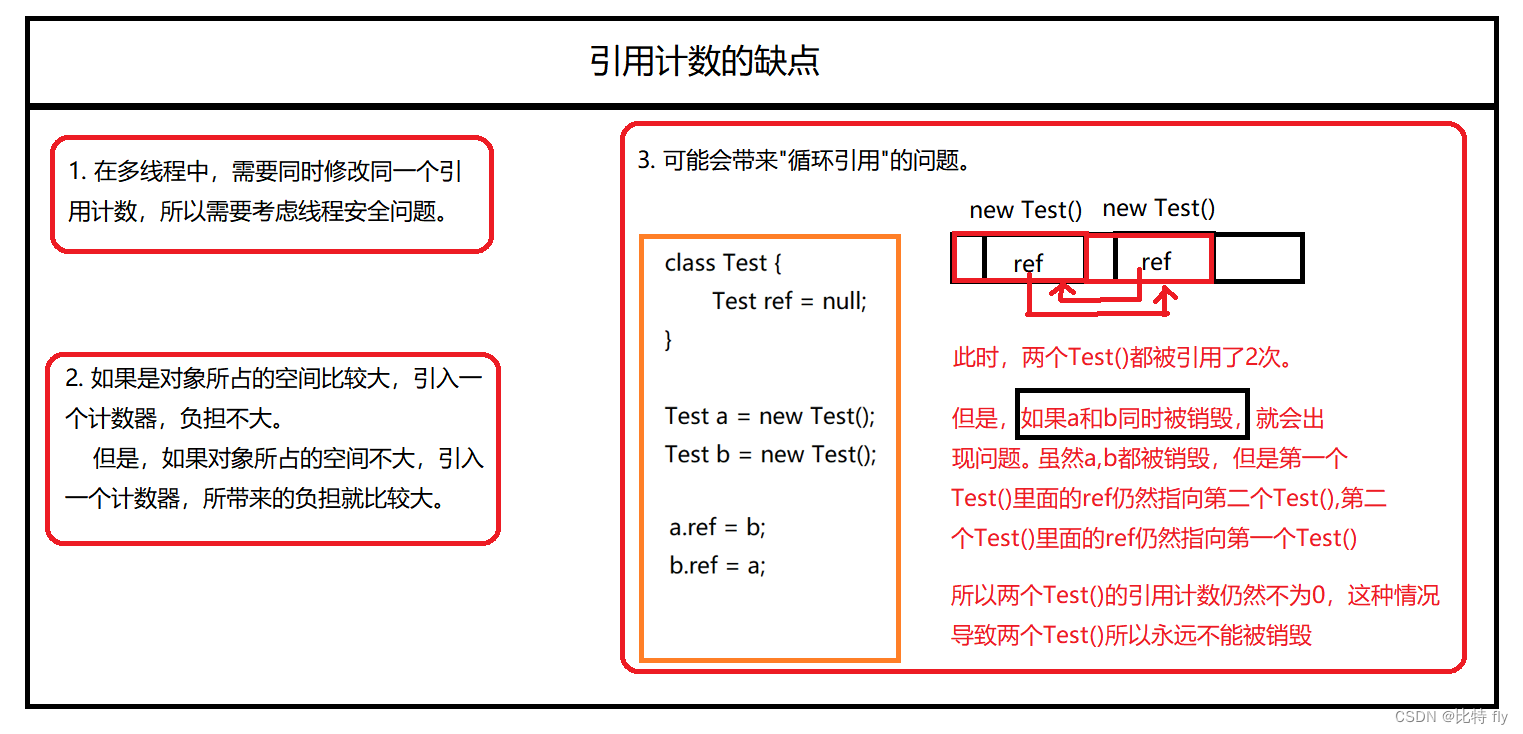
在Java语言中,主要使用的是"可达性分析"这种算法,在其他语言当中,只用的主要是“引用计数”这种算法。
引用计数算法
引用计数算法:设置额外的计数器,来记录某个对象被引用了多少次。
Test t1 = new Test();//Test()引用 +1
Test t2 = t1;//Test()引用 +1
Test t3 = t1;//Test()引用 +1
上述代码中,Test() 对象被引用了3次。
Test t1 = new Test();//Test()引用 +1
Test t2 = t1;//Test()引用 +1
t1=null;//Test()引用 -1
t2=null;//Test()引用 -1
此时,Test() 对象被引用了 0 次,此时就可以将Test() 当作垃圾回收了。
但是引用计数有一下缺点:
可达性分析算法
可达性分析算法:以代码这种的一些特殊的变量作为起点,然后以起点出发,看看那些对象能够被访问掉到,只要对象被访问到了,就标记为“可达”,当完成一圈标记后,剩下的“不可达”的就是垃圾了。
那么什么样的变量能够作为“起点”呢?
- 栈里面的局部变量
- 常量池中的变量
- 方法区中,静态引用类型的成员
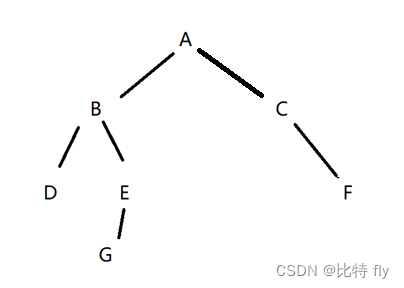
什么叫做"能够被访问到"?
类似于访问一棵树
3. 垃圾回收算法
标记-清除算法
标记-清除算法:将垃圾对象先标记出来,在标记彻底完成之后,将所有标记的对象全部清除。
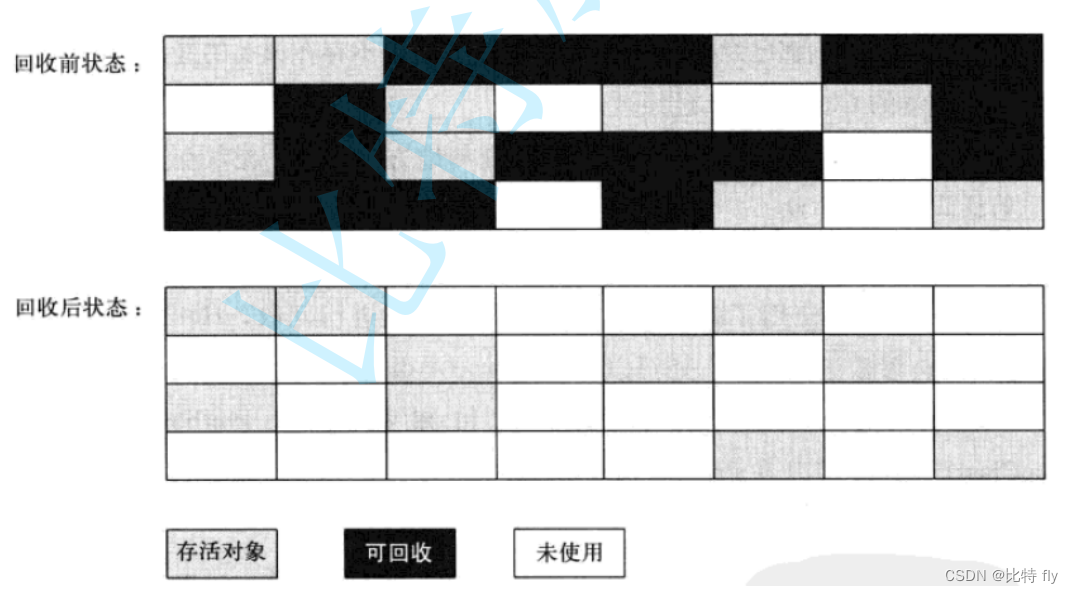
缺点:
- 这种算法的标记和清除的效率都不高
- 这种算法会引起内存碎片化问题。
复制算法
复制算法:解决了标记-清除算法所引起的内存碎片化问题。它是提前将内存划分为两个区域,用一半留一半。假设区域1在使用,在经过GC之后,就将可达的对象复制到区域2。
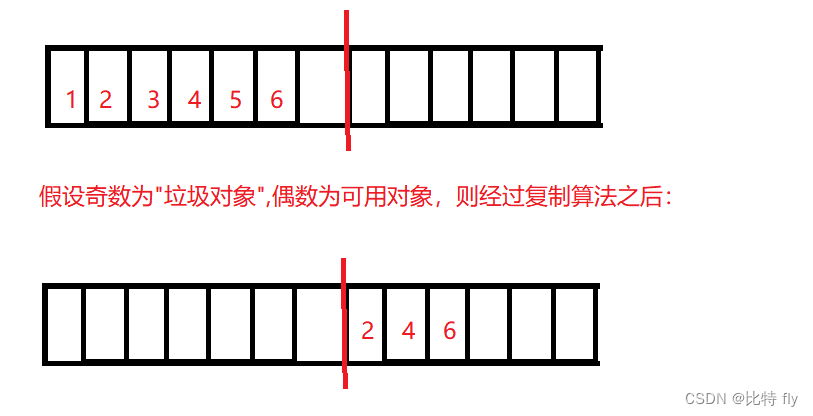
解决了标记-清除算法所引起的内存碎片化问题。但是又引入了新的问题:
使得内存的空间利用率降低,每次只能用内存的一半。
标记-整理算法
先将”垃圾对象“标记出来,然后进行整理。
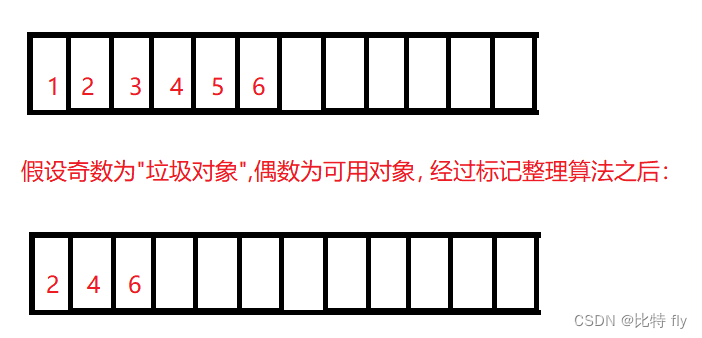
这种算法既解决了内存碎片化的问题,也解决了内存空间利用率的问题,但是它在进行整理的时候,需要对对象进行搬运,这是一个耗时费力的过程,时间复杂度为n*n, 因此,这种算法的效率也不是很高。
分代算法
分代算法综合上面的算法,在不同场景下,扬长避短,从而达到最好的效果。
分代算法的内存划分:
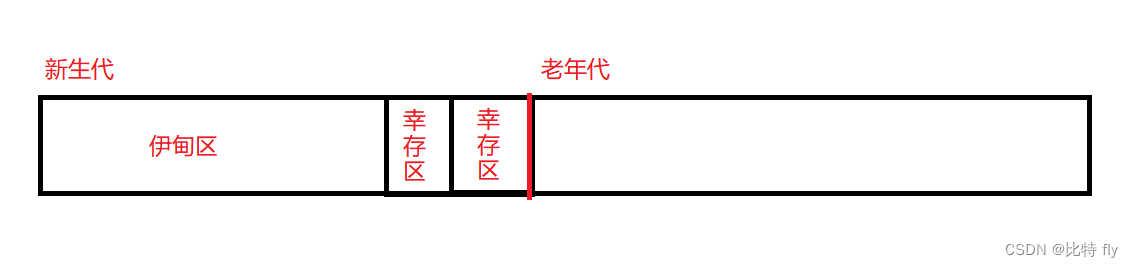
- 新创建出来的对象,先放在伊甸区。
- 伊甸区的绝大部分对象都活不过一轮GC,活过一轮的对象就被复制(复制算法)到幸存区,这里需要复制的对象不多,所以幸存区不需要很大。
- 幸存区里面的对象,又会经历第二次GC,每一轮都会淘汰一些对象,幸存的对象被复制到另一个幸存区。这个过程既保留了复制算法的高效,无内存碎片的优势,同时也没有浪费太多的内存空间。
- 幸存区里面的对象,经历过15轮的GC之后,如果然后没被淘汰,就可以放到老年区当中。
- 老年区里面的对象,仍然会接受GC的洗礼,但是频率大大降低,此时就接受用标记-整理算法带来的效率问题。
特殊:对于比较大的对象,它要是使用复制算法进行移动,那效率也是很低的,所以直接将他放到老年代进行了。
垃圾回收器
上面我们讲的收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现,不同的来及回收期可能堆上述垃圾回收算法的运用各有差异。随着技术不断地发展,可能会不断地推出新的垃圾回收期来满足不同场景地需求。
垃圾收集器的作用:垃圾收集器是为了保证程序能够正常、持久运行的一种技术,它是将程序中不用的死亡对象也就是垃圾对象进行清除,从而保证了新对象能够正常申请到内存空间















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









