









前面的话
目的是抛砖引玉,不太建议直接抄。
为爱发电,多点赞可能会导致我更新未来你想要的内容。
正文
1、实验目的
理解多层神经网络的结构和原理,掌握反向传播算法对神经元的训练过程,了解反向传播公式。
通过构建 BP 网络实例,熟悉前馈网络的原理及结构。
2、背景知识
误差反向传播算法即 BP 算法,是一种适合于多层神经网络的学习算法。其建立在梯度下降方法
的基础之上,主要由激励传播和权重更新两个环节组成,经过反复迭代更新、修正权值从而输出预期的
结果。
BP 算法整体上可以分成正向传播和反向传播,原理如下:
正向传播过程:信息经过输入层到达隐含层,再经过多个隐含层的处理后到达输出层。
反向传播过程:比较输出结果和正确结果,将误差作为一个目标函数进行反向传播:
对每一层依次求对权值的偏导数,构成目标函数对权值的梯度,网络权重再依次完成更新调整。
依此往复、直到输出达到目标值完成训练。
该算法可以总结为:利用输出误差推算前一层的误差,再用推算误差算出更前一层的误差,直到
计算出所有层的误差估计。
1986 年, Hinton 在论文《Learning Representations by Back-propagating Errors》中首次
系统地描述了如何利用 BP 算法来训练神经网络。
从此, BP 算法开始占据有监督神经网络算法的核心地位。它是迄今最成功的神经网络学习算法
之一,现实任务中使用神经网络时,大多是在使用 BP 算法进行训练。
为了说明 BP 算法的过程, 本实验使用一个公司招聘的例子:假设有一个公司,其人员招聘由 5
个人组成的人事管理部门负责,如下图所示:
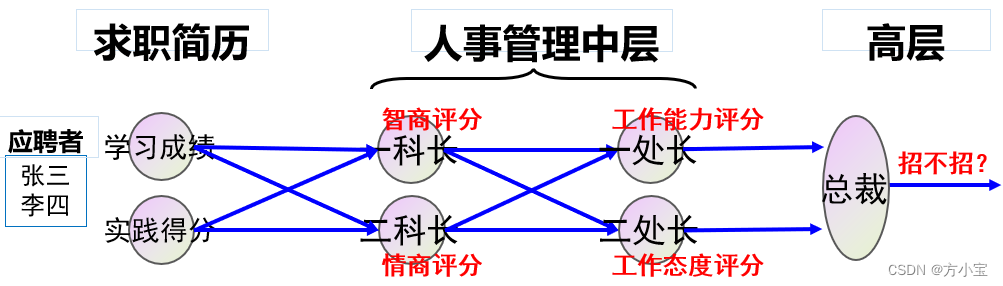
其中张三、李四等人是应聘者,他们向该部门投递简历,简历包括两类数据:学习成绩和社会
实践得分,人事部门有三个层级,一科长根据应聘者的学习成绩和实践得分评估其智商,二科长根据
同样的资料评估其情商;一处长根据两个科长提供的智商、情商评分,评估应聘者的工作能力,二处
长评估工作态度;最后由总裁汇总两位处长的意见,得出最终结论, 即是否招收该应聘者。
该模型等价于一个形状为(2,2,2,1)的前馈神经网络,输入层、隐藏层 1、隐藏层 2、输出层各
自包含 2、 2、 2、 1 个节点,如下图所示。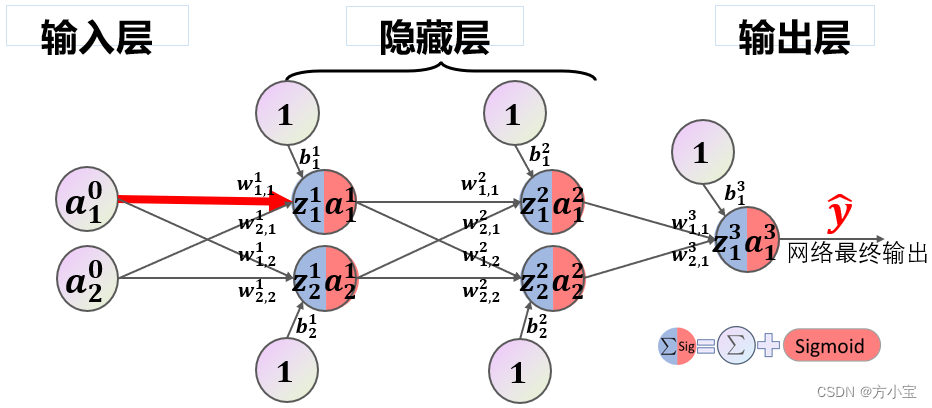
除输入节点外,每个节点都执行汇总和激活两个操作。汇总得到的数值称为净输入,用字母𝒛表
示。激活采用 sigmoid 函数,激活后的数据称为该节点的输出,用字母𝒂表示。字母的上标代表该节点
位于哪一层,下标代表该节点是该层第几个节点。注意输入节点位于 0 层。
节点与节点之间边的权值用字母𝒘表示, 上标代表该权值属于哪一层,下标有两个,代表其连
接的是左侧(上一层)第几个节点到右侧(下一层)第几个节点。偏置用字母𝒃表示,它可以视为输
入恒为 1 的边的权值。
为所有𝒘和𝒃赋初值,针对一个样本或多个样本从左到右计算出所有𝒛和𝒂的过程,即正向传播。
经正向传播后,神经网络的最终输出,记为𝒚̂。 在本案例中, 𝒚̂ = 𝒂𝟏 𝟑。
通过设计一个由权值和偏置决定的目标函数𝐽(𝑊, 𝑏),可以求出目标函数对𝒚̂的偏导数𝜕𝐽(𝑊,𝑏)
𝜕𝒚̂ =
𝜕𝐽(𝑊,𝑏)
𝜕𝒂
𝟑𝟏
(目标函数并不一定包含𝒚̂, 但本案例只讨论这种常见的情况),将该偏导数看成由权值和偏置
导致的误差,一层一层将误差反向传导到所有的权值和偏置,就是反向传播过程。
实际编程时进行了向量化(Vectorization),即将对标量的多次循环计算,用对向量、矩阵、
张量的一次运算来替代,见下图。应聘者的输入被组织为向量 A0,第一层的 4 个权值被组织为矩阵 W1,
隐藏层 1 节点的汇总结果被组织为向量 Z1,对应的输出被组织为 A1。其它层类似。最后的 Z3 和 A3 在
本例中是标量。
必须指出, 为方便理解, 本招聘案例在一开始就定义了隐藏层结点的作用:评估应聘者的智商、
情商、工作能力、工作态度等特征。但神经网络的特点是自动进行特征工程,隐藏层结点自主学习、
自动提取输入数据的特征,最后形成的决策权值,并不一定代表智商、情商、工作能力、工作态度。
3、 示例代码
1. import numpy as np
2. import matplotlib.pyplot as plt
3.
4. # 输入数据 1 行 2 列
5. X = np.array([[1,0.1]])
6.
7. # 标签,也叫真值, 1 行 1 列
8. T = np.array([[1]])
9.
10. # 定义一个 2 隐层的神经网络: 2-2-2-1
11. # 输入层 2 个神经元,隐藏 1 层 2 个神经元,隐藏 2 层 2 个神经元,输出层 1 个神经元
12.
13. # 输入层到隐藏层 1 的权值初始化, 2 行 2 列
14. W1 = np.array([[0.8,0.2],
15. [0.2,0.8]])
16. # 隐藏层 1 到隐藏层 2 的权值初始化, 2 行 2 列
17. W2 = np.array([[0.5,0.0],
18. [0.5,1.0]])
19. # 隐藏层 2 到输出层的权值初始化, 2 行 1 列
20. W3 = np.array([[0.5],
21. [0.5]])
22.
23.
24. # 初始化偏置值
25. # 隐藏层 1 的 2 个神经元偏置
26. b1 = np.array([[-1,0.3]])
27. # 隐藏层 2 的 2 个神经元偏置
28. b2 = np.array([[0.1,-0.1]])
29. # 输出层的 1 个神经元偏置
30. b3 = np.array([[-0.6]])
31. # 学习率设置
32. lr = 0.1
33. # 定义训练周期数 10000
34. epochs = 10000
35. # 每训练 1000 次计算一次 loss 值
36. report = 1000
37. # 将所有样本分组,每组大小为
38. batch_size = 1
39.
40. # 定义 sigmoid 函数
41. def sigmoid(x):
42. return 1/(1+np.exp(-x))
43.
44. # 定义 sigmoid 函数导数
45. def dsigmoid(x):
46. return x*(1-x)
47.
48. # 更新权值和偏置值
49. def update():
50. global batch_X,batch_T,W1,W2,W3,lr,b1,b2,b3
51.
52. # 隐藏层 1 输出
53. Z1 = np.dot(batch_X,W1) + b1
54. A1 = sigmoid(Z1)
55.
56. # 隐藏层 2 输出
57. Z2 = (np.dot(A1,W2) + b2)
58. A2 = sigmoid(Z2)
59.
60. # 输出层输出
61. Z3=(np.dot(A2,W3) + b3)
62. A3 = sigmoid(Z3)
63.
64. # 求输出层的误差
65. delta_A3 = (batch_T - A3)
66. delta_Z3 = delta_A3 * dsigmoid(A3)
67.
68. # 利用输出层的误差,求出偏导(即隐藏层 2 到输出层的权值改变) # 由于一次计算了多个样本,所
以需要求平均
69. delta_W3 = A2.T.dot(delta_Z3) / batch_X.shape[0]
70. delta_B3 = np.sum(delta_Z3, axis=0) / batch_X.shape[0]
71.
72. # 求隐藏层 2 的误差
73. delta_A2 = delta_Z3.dot(W3.T)
74. delta_Z2 = delta_A2 * dsigmoid(A2)
75.
76. # 利用隐藏层 2 的误差,求出偏导(即隐藏层 1 到隐藏层 2 的权值改变) # 由于一次计算了多个样
本,所以需要求平均
77. delta_W2 = A1.T.dot(delta_Z2) / batch_X.shape[0]
78. delta_B2 = np.sum(delta_Z2, axis=0) / batch_X.shape[0]
79.
80. # 求隐藏层 1 的误差
81. delta_A1 = delta_Z2.dot(W2.T)
82. delta_Z1 = delta_A1 * dsigmoid(A1)
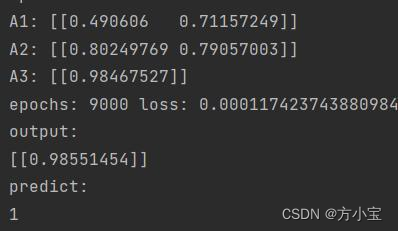
83.
84. # 利用隐藏层 1 的误差,求出偏导(即输入层到隐藏层 1 的权值改变) # 由于一次计算了多个样本,
所以需要求平均
85. delta_W1 = batch_X.T.dot(delta_Z1) / batch_X.shape[0]
86. delta_B1 = np.sum(delta_Z1, axis=0) / batch_X.shape[0]
87.
88. # 更新权值
89. W3 = W3 + lr *delta_W3
90. W2 = W2 + lr *delta_W2
91. W1 = W1 + lr *delta_W1
92.
93. # 改变偏置值
94. b3 = b3 + lr * delta_B3
95. b2 = b2 + lr * delta_B2
96. b1 = b1 + lr * delta_B1
97.
98. # 定义空 list 用于保存 loss
99. loss = []
100. batch_X = []
101. batch_T = []
102. max_batch = X.shape[0] // batch_size
103. # 训练模型
104. for idx_epoch in range(epochs):
105.
106. for idx_batch in range(max_batch):
107. # 更新权值
108. batch_X = X[idx_batch*batch_size:(idx_batch+1)*batch_size, :]
109. batch_T = T[idx_batch*batch_size:(idx_batch+1)*batch_size, :]
110. update()
111. # 每训练 5000 次计算一次 loss 值
112. if idx_epoch % report == 0:
113. # 隐藏层 1 输出
114. A1 = sigmoid(np.dot(X,W1) + b1)
115. # 隐藏层 2 输出
116. A2 = sigmoid(np.dot(A1,W2) + b2)
117. # 输出层输出
118. A3 = sigmoid(np.dot(A2,W3) + b3)
119. # 计算 loss 值
120. print('A3:',A3)
121. print('epochs:',idx_epoch,'loss:',np.mean(np.square(T - A3) / 2))
122. # 保存 loss 值
123. loss.append(np.mean(np.square(T - A3) / 2))
124.
125. # 画图训练周期数与 loss 的关系图
126. plt.plot(range(0,epochs,report),loss)
127. plt.xlabel('epochs')
128. plt.ylabel('loss')
129.
130. plt.show()
131. # 隐藏层 1 输出
132. A1 = sigmoid(np.dot(X,W1) + b1)
133. # 隐藏层 2 输出
134. A2 = sigmoid(np.dot(A1,W2) + b2)
135. # 输出层输出
136. A3 = sigmoid(np.dot(A2,W3) + b3)
137. print('output:')
138.
139. print(A3)
140. # 因为最终的分类只有 0 和 1,所以我们可以把
141. # 大于等于 0.5 的值归为 1 类,小于 0.5 的值归为 0 类
142. def predict(x):
143. if x>=0.5:
144. return 1
145. else:
146. return 0
147.
148. # map 会根据提供的函数对指定序列做映射
149. # 相当于依次把 A2 中的值放到 predict 函数中计算
150. # 然后打印出结果
151. print('predict:')
152. for i in map(predict,A3):
153. print(i)4、实验内容
请回答下列问题:
1) 如果去掉总裁这一层,相应张三的样本修改为(1.0,0.1,1.0,1.0),分别对应张三的学习成绩、
张三的实践成绩、张三的工作能力真值、张三的工作态度真值,代码应该如何修改?
2) 如果增加一个样本,李四(0.1,1.0,0),分别对应李四的学习成绩,李四的实践成绩,李四
被招聘可能性的真值,代码应该如何修改?此时是一个样本计算一次偏导、更新一次权值,还是两个
样本一起计算一次偏导、更新一次权值? (提示:注意 batch_size 的作用)
3) 样本为张三[1,0.1,1]、李四[0.1,1,0]、王五[0.1,0.1,0]、赵六[1,1,1], 请利用 batch_size 实现
教材 279 页提到的“批量梯度下降”、“随机梯度下降”和“小批量梯度下降”,请注意“随机梯度
下降” 和“小批量梯度下降” 要体现随机性。
4 ) 【 选 做 】 本 例 中 输 入 向 量 、 真 值 都 是 行 向 量 , 请 将 它 们 修 改 为 列 向 量 , 如
X = np.array([[1,0.1]])改为 X = np.array([[1],[0.1]]), 请合理修改其它部分以使程序得到与行向量时相
同的结果。 (不允许直接使用 X 的转置进行全局替换)
题目答案
1) 如果去掉总裁这一层, 相应张三的样本修改为(1.0,0.1,1.0,1.0), 分别对应张三的学
习成绩、 张三的实践成绩、 张三的工作能力真值、 张三的工作态度真值, 代码应该如何修
改?
答:
设置真值:
T = np.array([[1,1]])
删除了总裁层, 将 W3 去掉, 修改方式:
# 输入层到隐藏层 1 的权值初始化, 2 行 2 列
W1 = np.array([[0.8,0.2],
[0.2,0.8]])
# 隐藏层 1 到隐藏层 2 的权值初始化, 2 行 2 列
W2 = np.array([[0.5,0.0],
[0.5,1.0]])
然后设置神经元的偏置。
# 隐藏层 1 的 2 个神经元偏置
b1 = np.array([[-1,0.3]])
# 隐藏层 2 的 2 个神经元偏置
b2 = np.array([[0.1,-0.1]])
在 update 函数中, 修改以下代码:
def update():
global batch_X,batch_T,W1,W2,W3,lr,b1,b2,b3
Z1 = np.dot(batch_X,W1) + b1
A1 = sigmoid(Z1)
Z2 = (np.dot(A1,W2) + b2)
A2 = sigmoid(Z2)
delta_A2 = (batch_T - A2)
delta_Z2 = delta_A2 * dsigmoid(A2)
delta_W2 = A1.T.dot(delta_Z2) / batch_X.shape[0]
delta_B2 = np.sum(delta_Z2, axis=0) / batch_X.shape[0]
delta_A1 = delta_Z2.dot(W2.T)
delta_Z1 = delta_A1 * dsigmoid(A1)
delta_W1 = batch_X.T.dot(delta_Z1) / batch_X.shape[0]
delta_B1 = np.sum(delta_Z1, axis=0) / batch_X.shape[0]
W2 = W2 + lr * delta_W2
W1 = W1 + lr * delta_W1
b2 = b2 + lr * delta_B2
b1 = b1 + lr * delta_B1
修改主函数中的代码:
print('epochs:',idx_epoch,'loss:',np.mean(np.square(T - A2) / 2))
loss.append(np.mean(np.square(T - A2) / 2))
print('output:')
print(A2)
print('predict:')
for i in map(predict,A2.T):
print(i)
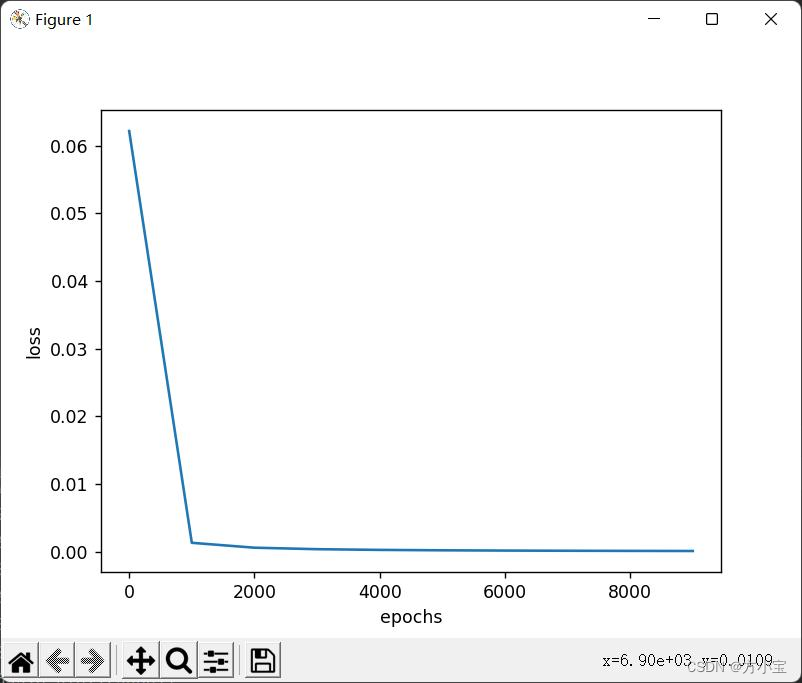
得到结果:
2) 如果增加一个样本, 李四(0.1,1.0,0), 分别对应李四的学习成绩, 李四的实践成绩,
李四被招聘可能性的真值, 代码应该如何修改? 此时是一个样本计算一次偏导、 更新一次
权值, 还是两个样本一起计算一次偏导、 更新一次权值? (提示: 注意 batch_size 的作
用)
答:
首先修改 X 输入为:
X = np.array([[1.0,0.1],[0.1,1.0]])
表示输入张三和李四的成绩。 然后修改 T 真值的大小:
T = np.array([[1],[0]])
表示张三被录取了, 李四没有被录取。
运行结果如图所示: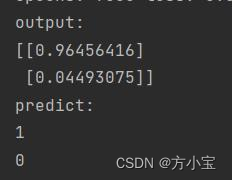
上图是 batch_size=1 的结果, max_batch = X.shape[0] // batch_size=2, 是一个
样本单独计算偏导, 更新权值。 batch_size=2 是两个样本一起计算。
3) 样本为张三[1,0.1,1]、 李四[0.1,1,0]、 王五[0.1,0.1,0]、 赵六[1,1,1], 请利用
batch_size 实现教材 279 页提到的“批量梯度下降”、“随机梯度下降” 和“小批量梯度
下降”, 请注意“随机梯度下降” 和“小批量梯度下降” 要体现随机性。
答:
解开关于 X 和 T 的注释, 将样本增加到 4。
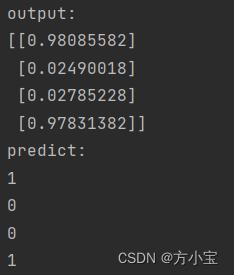
①批量梯度下降是指每次更新使用所有的样本, 不需要更改代码, 得到结果: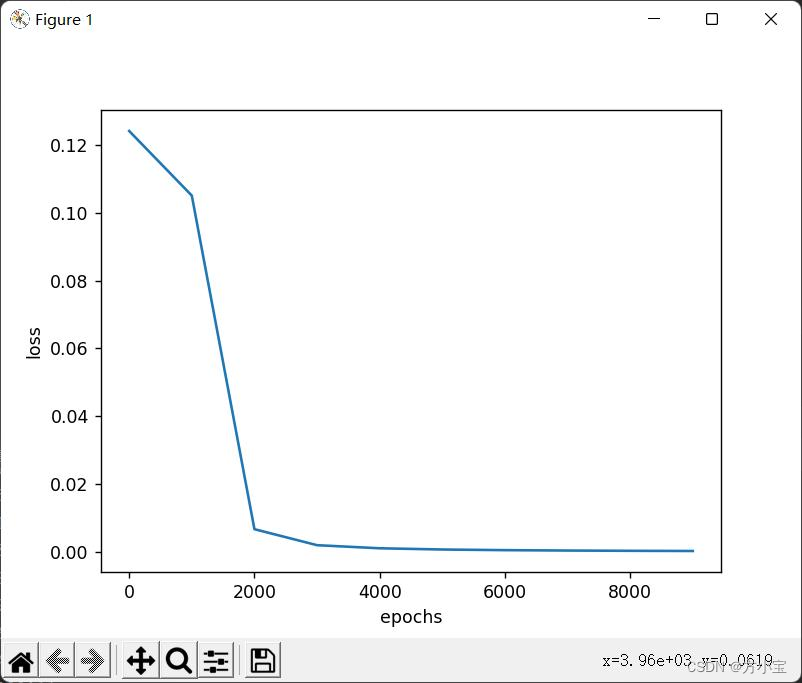
②随机梯度下降是指每次更新数据都使用一个随机的数据进行更新, 修改训练的前半
部分代码:
for idx_epoch in range(epochs):
ran = random.randint(0, X.shape[0]-1)
batch_X = X[ran:ran+1, : ]
batch_T = T[ran:ran+1, : ]
update()
#后面的不用修改, 这里就不贴了
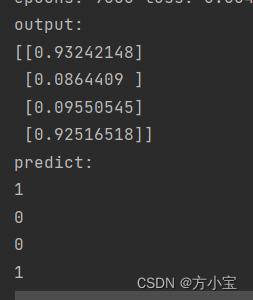
得到结果: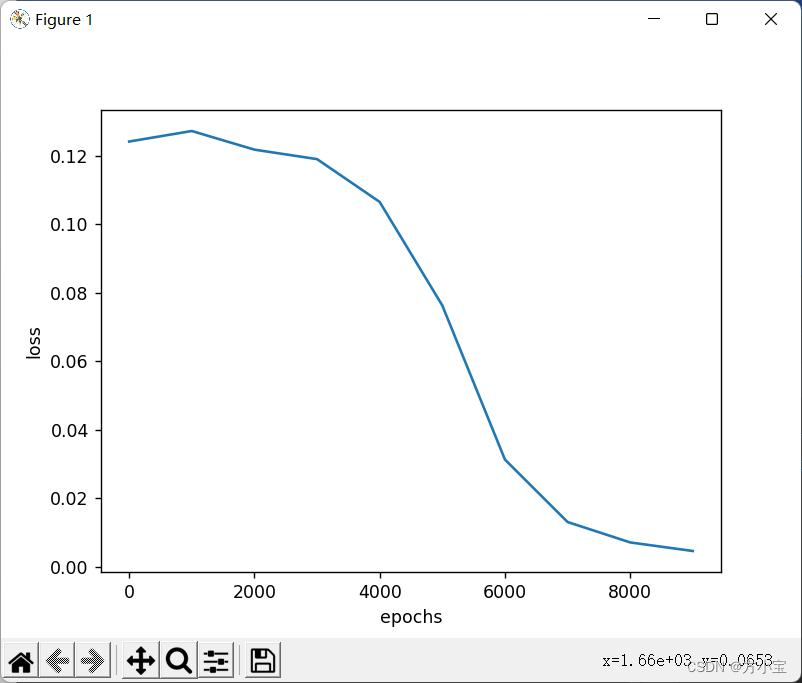
③小批量梯度随机是指每次使用固定数量的随机样本进行训练, 修改代码:
for idx_epoch in range(epochs):
train_size = 3
train_i = np.arange(0,X.shape[0],1)
np.random.shuffle(train_i)
for index in range(train_size):
ran = train_i[index]
batch_X = X[ran:ran + 1, :]
batch_T = T[ran:ran + 1, :]
update()
固定了每次选 3 个随机的样本进行更新, 每次训练的分组大小是 1。 得到的结果是: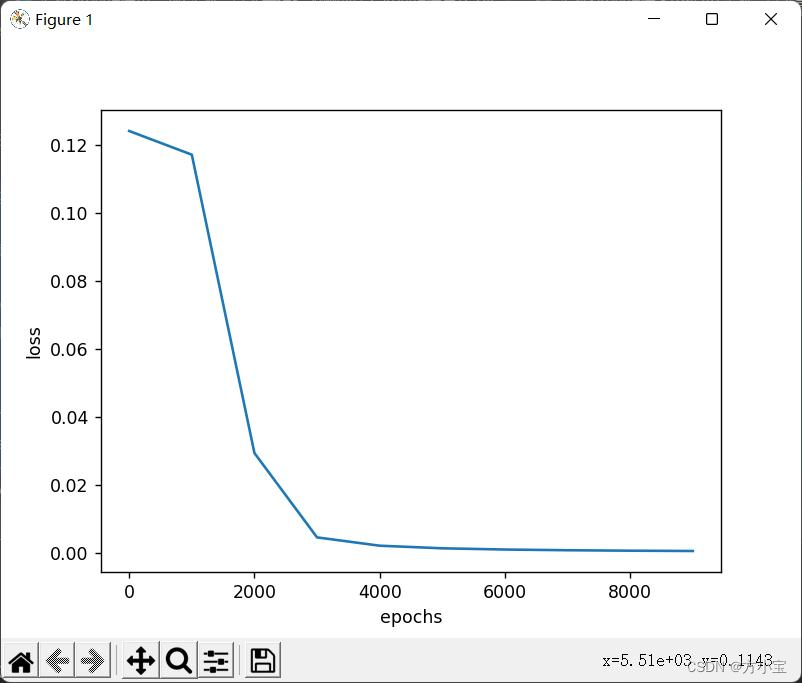
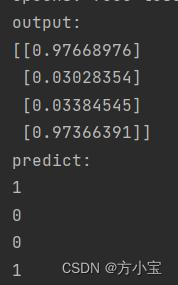
4 ) 【 选 做 】 本 例 中 输 入 向 量 、 真 值 都 是 行 向 量 , 请 将 它 们 修
改 为 列 向 量 , 如 X = np.array([[1,0.1]])改为 X = np.array([[1],[0.1]]), 请
合理修改其它部分以使程序得到与行向量时相
同的结果。 ( 不允许直接使用 X 的转置进行全局替换)
答:
首先修改输入为 X = np.array([[1],[0.1]]), 然后修改 max_batch = X.shape[1] //
batch_size, 取列向量作为 max_batch, 然后修改 update 进入函数前的输出:
#因为修改成了列向量, 所以每次的输入都属取列中的
batch_X = X[:, idx_batch*batch_size:(idx_batch+1)*batch_size]
batch_T = T[:, idx_batch*batch_size:(idx_batch+1)*batch_size]
对于 T, W, b 层的输入进行转置, 这里虽然可以手动修改, 但是直接转置更方便, 所
以只对 X 手动更改了输入:
X = np.array([[1.0]
,[0.1]])
T = np.array([[1]])
T=T.T
# 输入层到隐藏层 1 的权值初始化, 2 行 2 列
W1 = np.array([[0.8,0.2],
[0.2,0.8]])
# 隐藏层 1 到隐藏层 2 的权值初始化, 2 行 2 列
W2 = np.array([[0.5,0.0],
[0.5,1.0]])
# 隐藏层 2 到输出层的权值初始化, 2 行 1 列
W3 = np.array([[0.5],
[0.5]])
#可以手动更改, 这里调用 python 的转置直接处理了
W1=W1.T
W2=W2.T
W3=W3.T
b1 = np.array([[-1,0.3]])
# 隐藏层 2 的 2 个神经元偏置
b2 = np.array([[0.1,-0.1]])
# 输出层的 1 个神经元偏置
b3 = np.array([[-0.6]])
#可以手动更改, 这里调用 python 的转置直接处理了
b1=b1.T
b2=b2.T
b3=b3.T
接下来的是对 update 函数中进行修改:
# batch_X 由之前的(1, 2) 变成了(2, 1)
#W1 也进行了转置, 但是前后都是(2, 2)
#交换两者的位置, 让之前的得到的[[Z1,Z2]]变成[[Z1],[Z2]]
Z1 = np.dot(W1,batch_X) + b1
A1 = sigmoid(Z1)
Z2 = (np.dot(W2,A1) + b2)
A2 = sigmoid(Z2)
Z3=(np.dot(W3,A2) + b3)
A3 = sigmoid(Z3)
delta_A3 = (batch_T - A3)
delta_Z3 = delta_A3 * dsigmoid(A3) # batch 和 A3 已经设置好了不需要改原来的代码
#W3 应该取 delta_Z3 与 A2 相 dot, 但是原代码中形状不一致, 需要像之前一样
#调换位置, 并且分母应该取列数, 而不是原代码的列数
delta_W3 = delta_Z3.dot(A2.T) / batch_X.shape[1]
#需要额外解释一下 axis, sum 默认的 axis=0 就是普通的相加而当加入 axis=1
#以后就是将一个矩阵的每一行向量相加。 故我们这里应该用 axis=1 来计算
delta_B3 = np.sum(delta_Z3, axis=1) / batch_X.shape[1]
#和之前同理, 为了能够正确的相乘, 需要改变原代码, 让 W3 能够与 delta_Z3 相乘
#后面的与前面第三层的同理
delta_A2 = W3.T.dot(delta_Z3)
delta_Z2 = delta_A2 * dsigmoid(A2)
delta_W2 = delta_Z2.dot(A1.T) / batch_X.shape[1]
delta_B2 = np.sum(delta_Z2, axis=1) / batch_X.shape[1]
delta_A1 = W2.T.dot(delta_Z2)
delta_Z1 = delta_A1 * dsigmoid(A1)
delta_W1 = delta_Z1.dot(batch_X.T) / batch_X.shape[1]
delta_B1 = np.sum(delta_Z1, axis=1) / batch_X.shape[1]
#对于偏置的更新这里使用了笨办法, 因为使用 sum 求平均之后, 得到的只能说一个或
#一行数据, 所以在相加的时候无法与形状为(1,2)的 b 相加, 所以就需要先转置再相加
#再转置
b1 = b1.T
b2 = b2.T
b3 = b3.T
b3 = b3 + lr * delta_B3
b2 = b2 + lr * delta_B2
b1 = b1 + lr * delta_B1
b1 = b1.T
b2 = b2.T
b3 = b3.T
修改完 update 函数之后, 还需要修改每次输出 loss 值得时候 A 层的计算方式, 修改
的原理和之前一样:
A1 = sigmoid(np.dot(W1,X) + b1)
A2 = sigmoid(np.dot(W2,A1) + b2)
A3 = sigmoid(np.dot(W3,A2) + b3)
最后运行! 得到的结果和原代码一样, A1, A2, A3 的形状和 batch_X 一样, 修改后得
到的解:
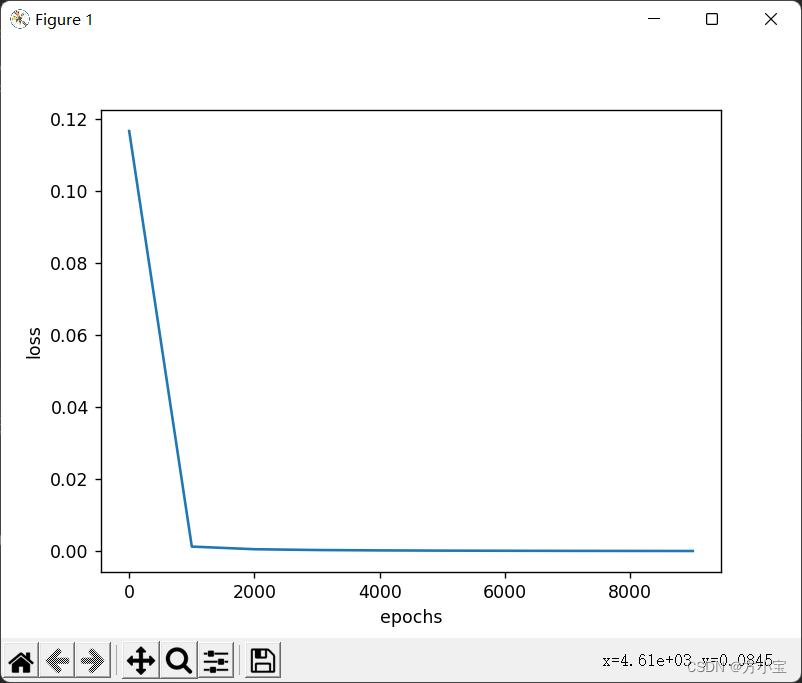
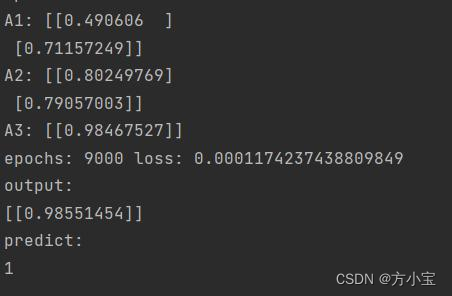
修改前得到的解: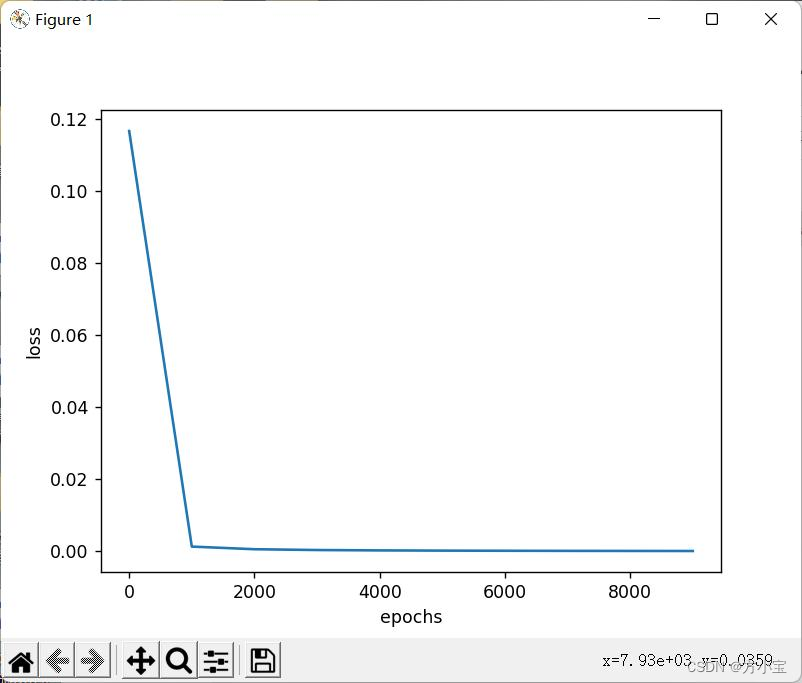
最后的话
:)看完点赞让我更快更新到你想要的内容。















 549
549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









