







双塔模型:模型和训练
双塔模型可以看做是矩阵补充的升级版。
1 双塔模型
双塔模型由两个独立的神经网络组成,通常称为用户塔和物品塔。每个塔负责处理一类实体的特征,用户塔处理用户特征,物品塔处理物品特征。这两个塔的输出通常是低维的向量表示,这些向量可以捕捉到用户和物品的深层次特征。
1.1 用户塔和物品塔
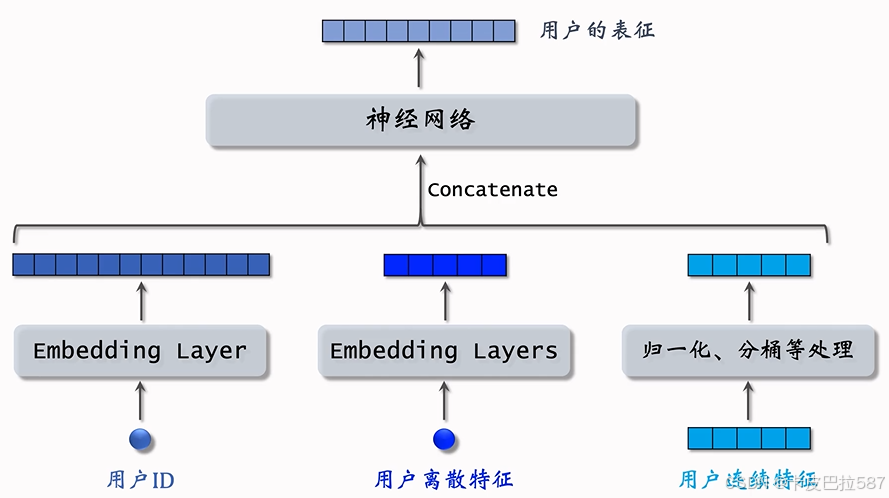
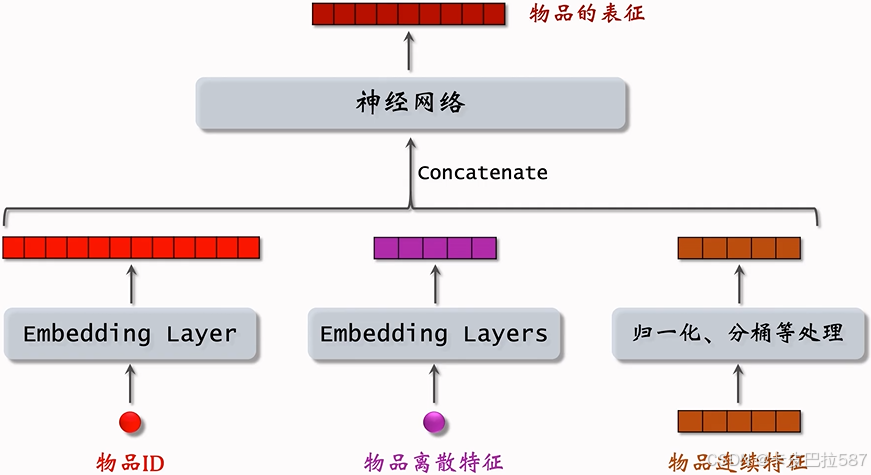
- 特征处理
- 对于每个离散特征,用单独一个 Embedding 层得到一个向量。比如用户所在的城市用一个 Embedding 层,用户感兴趣的话题用另一个 Embedding 层。
- 对于性别这样类别很少的离散特征,直接用 One-Hot 编码就行,可以不做 Embedding。
- 不同类型的连续特征有不同的处理方法,最简单的是做归一化,让特征均值是0,标准差是1。
- 有些长尾分布的连续特征需要特殊处理,比如取log、做分桶。
- 做完特征处理会有很多特征向量,把这些特征向量都拼起来输入神经网络。
- 神经网络可以是简单的全连接网络,也可以是更复杂的结构,比如深度交叉网络。
- 神经网络输出一个向量,这个向量就是对用户(物品)的表征,做召回要用到这个向量。
1.2 双塔模型
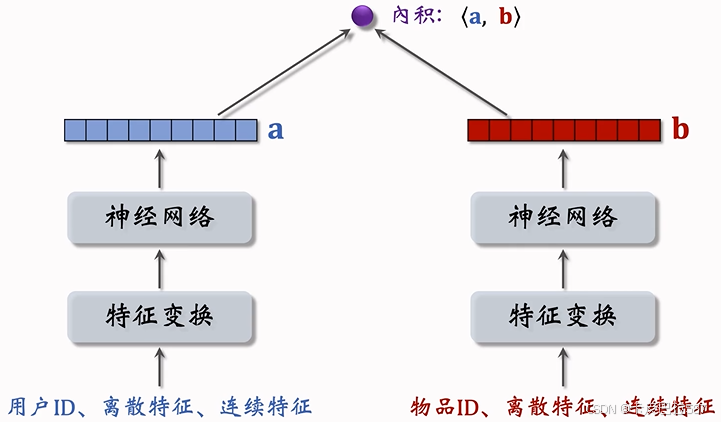
现在更常用余弦相似度预估用户对物品的兴趣。
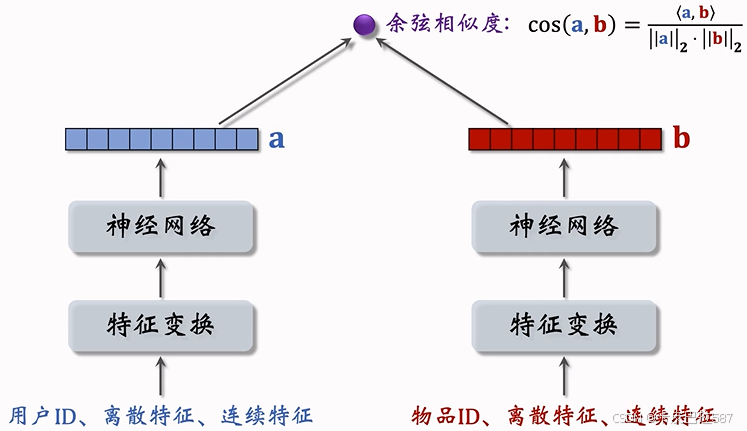
2 双塔模型的训练
2.1 训练方式
有三种训练双塔模型的方式。
-
Pointwise:将每个正样本和负样本独立看待,进行简单的二元分类。模型的目标是预测用户对物品的偏好概率。
-
Pairwise:每次取一个正样本和一个负样本,模型的目标是确保正样本的匹配度高于负样本的匹配度 [1]。
-
Listwise:每次取一个正样本和多个负样本,模型的目标是优化整个列表的排序 [2]。
2.2 正负样本的选择
-
正样本:用户点击的物品。
-
负样本[1, 2] :
-
没有被召回的?
-
召回但是被粗排、精排淘汰的?
-
曝光但是未点击的?
-
2.3 Pointwise 训练
-
把召回看做二元分类任务。
-
对于正样本,鼓励 cos(a,b) 接近 +1。
-
对于负样本,鼓励 cos(a,b) 接近 -1。
-
控制正负样本数量为 1:2 或者 1:3。
2.4 Pairwise 训练
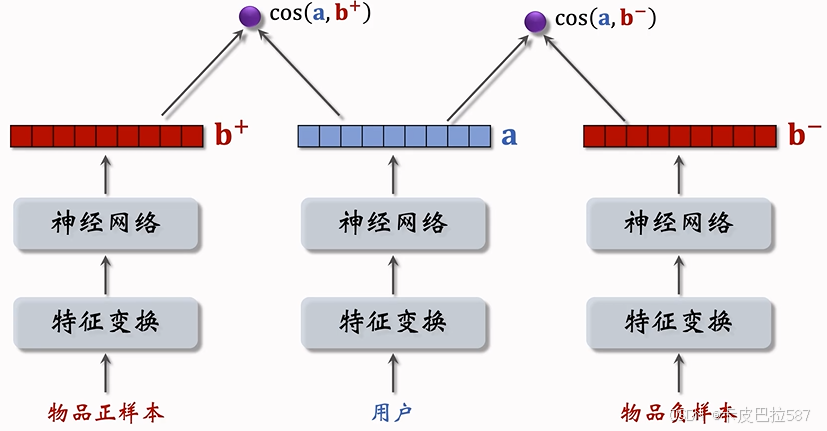
- 做训练的时候,每组的输入是一个三元组,包括一个用户和两个物品。
- 两个物品塔是相同的,里面的 Embedding 层和全连接层都用一样的参数。
- 分别计算用户对两个物品的兴趣。
基本想法:鼓励
大于
。
- 如果
,则没有损失。
- 否则,损失等于
。
这样就推导出三元组铰链损失(Triplet hinge loss):
Triplet hinge loss 只是其中一种损失函数,还有别的损失函数起到同样的作用,三元组逻辑损失(Triplet Logistic Loss):
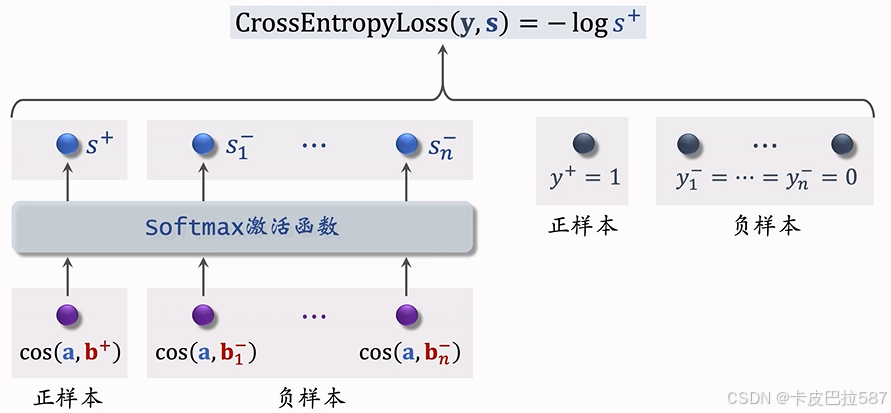
2.5 Listwise 训练
-
一条数据包含:
-
一个用户,特征向量记作
。
-
一个正样本,特征向量记作
。
-
多个负样本,特征向量记作
。
-
-
鼓励
-
鼓励
尽量小,最好接近-1。
具体操作:
总结
-
用户塔、物品塔各输出一个向量。
-
两个向量的余弦相似度作为兴趣的预估值。
-
三种训练方式:
-
Pointwise:每次用一个用户、一个物品(可正可负)。
-
Pairwise:每次用一个用户、一个正样本、一个负样本。
-
Listwise:每次用一个用户、一个正样本、多个负样本。
-
不适用于召回的模型
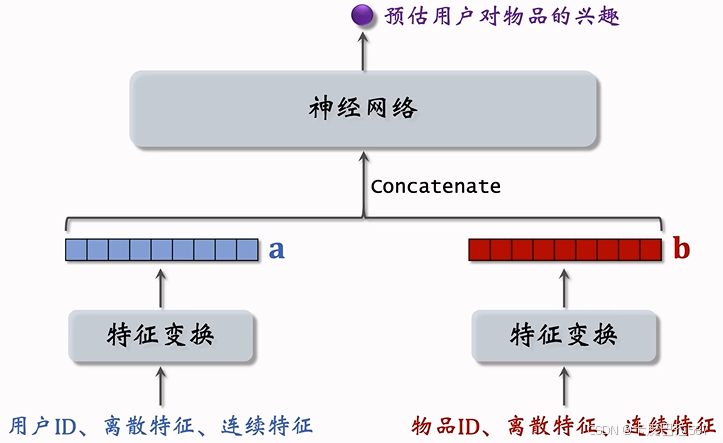
- 看到这种结构,就应该知道这是精排或粗排的模型,而不是召回的模型。
- 下面这块结构跟双塔模型是一样的,都是分别提取用户和物品的特征,得到两个特征向量。
- 但上层的结构就不一样了。这种神经网络结构属于前期融合,在进入全连接层之前就把特征向量拼起来了。这种前期融合的神经网络结构跟前面讲的双塔模型有很大区别。
- 双塔模型属于后期融合,两个塔在最终输出相似度的时候才融合起来。
- 这种前期融合的模型不适用于召回。假如把这种模型用于召回,就必须把所有物品的特征都挨个输入模型,预估用户对所有物品的兴趣。这种计算量显然不可行。
- 如果用这种模型,就没办法用近似最近邻查找来加速计算。
- 这种模型通常用于排序,从几千个候选物品中选出几百个,计算量不会太大。
参考文献:
Ji-Ting Huang et al. Embedding-based Retrieval in Facebook Search. In KDD, 2020.
Xinyang Yi et al. Sampling-Bias-Corrected Neural Modeling for Large Corpus Item Recommendations. In RecSys, 2019.

















 2835
2835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









