







自监督学习的目的是把物品塔训练的更好。
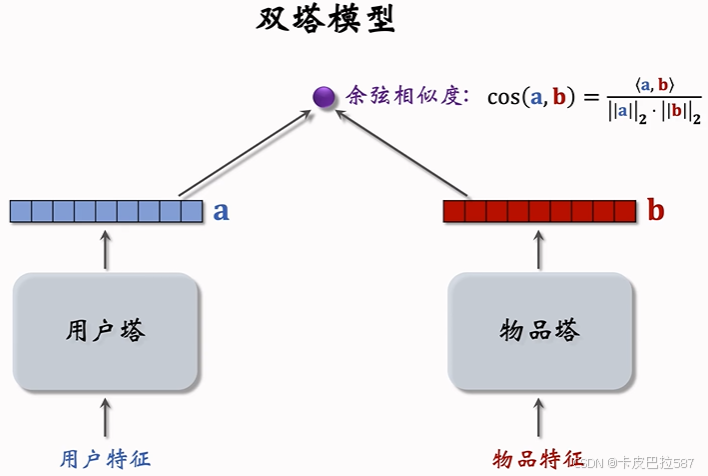
1 双塔模型的问题
-
推荐系统的头部效应严重:
-
少部分物品占据大部分点击。
-
大部分物品的点击次数不高。
-
-
高点击物品的表征学得好,长尾物品的表征学得不好。
-
自监督学习:做 data augmentation,更好地学习长尾物品的向量表征。
参考文献:
Tiansheng Yao et al. Self-supervised Learning for Large-scale Item Recommendations. In CIKM, 2021.
2 双塔模型 Listwise 训练
2.1 损失函数
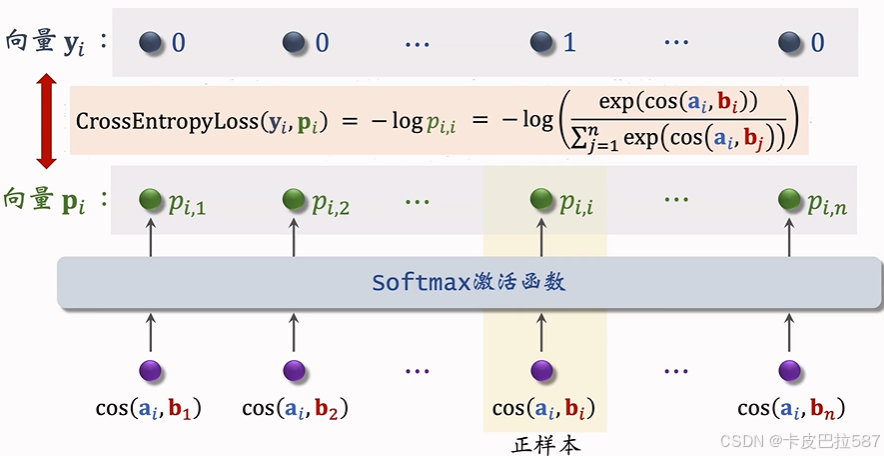
做训练的时候希望
尽量接近
。
2.2 纠偏
笔记07中提到过:Batch 内负样本会过度打压热门物品,造成偏差。如果用 Batch 内负样本就需要纠偏。训练时做调整,热门物品不至于被过分打压。
2.3 训练双塔模型
-
从点击数据中随机抽取 n 个用户—物品二元组,组成一个 batch。
-
双塔模型的损失函数:
-
做梯度下降,减小损失函数:
3 自监督学习
用自监督学习训练物品塔。
3.1 自监督学习
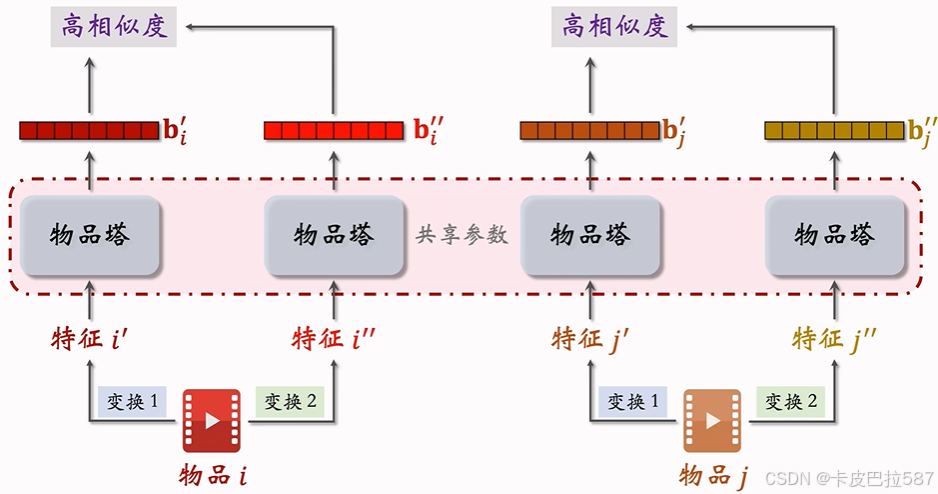
- 同一个物品经过不同的特征变换,最终得到的向量表征不完全相等。
- 如果物品塔足够好,同一个物品的表征应该有很高的相似度。训练的时候会鼓励两个向量的 cos 相似度尽量大。
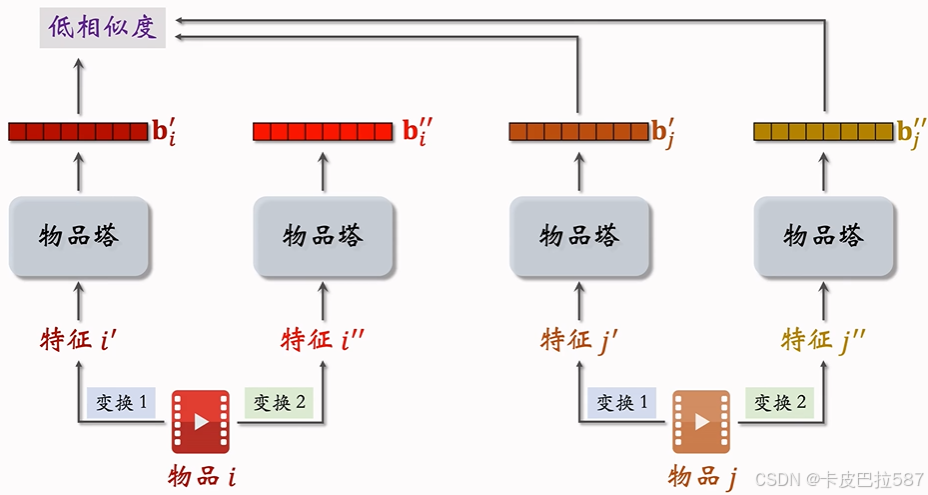
- 不同物品的向量表征应该离得尽量远。
概括
-
物品
的两个向量表征
′ 和
有较高的相似度。
-
物品
有较低的相似度。
-
鼓励
尽量大,
尽量小。
3.2 特征变换
自监督学习用到很多种特征变换。
Random Mask
-
随机选一些离散特征(比如类目),把它们遮住。
-
例:
-
某物品的类目特征是 U={数码,摄影}。
-
Mask 后的类目特征是 U′={default}。
-
Dropout(仅对多值离散特征生效)
-
一个物品可以有多个类目,那么类目是一个多值离散特征。
-
Dropout:随机丢弃特征中 50% 的值。
-
例:
-
某物品的类目特征是 U={美妆,摄影}。
-
Dropout 后的类目特征是 U′={美妆}。
-
互补特征(complementary)
-
假设物品一共有 4 种特征:ID,类目,关键词,城市。
-
随机分成两组:
-
{ID, 关键词} 和 {类目, 城市}
-
{ID, default, 关键词, default}→物品表征
-
{default, 类目, default, 城市}→物品表征
-
鼓励两个物品表征向量相似。
Mask 一组关联的特征
之所以用这种方法,是因为特征之间有较强的关联,遮住一个特征并不会损失太多的信息。模型可以从其他强关联特征中学到遮住的特征。最好是把关联的特征一次全都遮住。
-
受众性别:U={男,女,中性}
-
类目:V={美妆,数码,足球,摄影,科技,⋯}
-
u=女 和 v=美妆 同时出现的概率
大。
-
u=女 和 v=数码 同时出现的概率
-
:某特征取值为
的概率。
-
,同时发生的概率。
-
离线计算特征两两两之间的关联,用互信息(mutual information)衡量:
具体实现
-
设一共有
种特征。离线计算特征两两两之间互信息
,得到
的矩阵。
-
随机选一个特征作为种子,找到种子最相关的
种特征。
-
Mask 种子及其相关的
好处:比 random mask、dropout、互补特征等方法效果更好。
坏处:方法复杂,实现的难度大,不容易维护。
3.3 训练模型
如何用变换后的特征训练模型?
-
从全体物品中均匀抽样,得到
个物品,作为一个 batch。
-
做两类特征变换,物品塔输出两组向量:
和
-
第
跟双塔模型不同,训练模型抽样时,冷门物品和热门物品被抽到的概率是相同的。
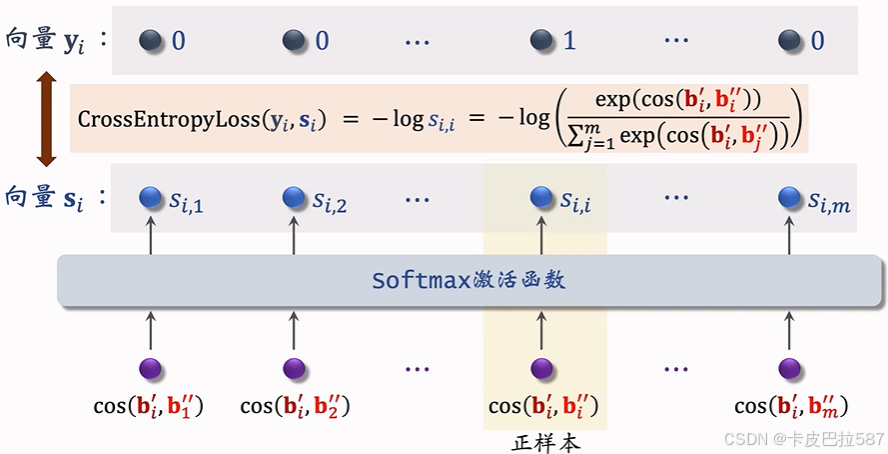
- 自监督学习的损失函数:
- 做梯度下降,减小自监督学习的损失:
4 总结
-
双塔模型学不好低曝光物品的向量表征。
-
自监督学习:
-
对物品做随机特征变换。
-
特征向量
-
特征向量
-
-
实验效果:低曝光物品、新物品的推荐变得更准。
-
训练模型
-
对点击做随机抽样,得到 n 对用户—物品二元组,作为一个 batch(这个 batch 用来训练双塔)。
-
从全体物品中均匀抽样,得到 m 个物品,作为一个 batch(这个 batch 用来做自监督学习,只训练物品塔)。
-
做梯度下降,使得损失减小:
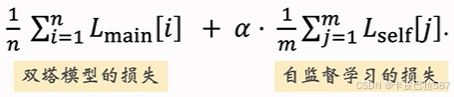
-
其中,α 是一个超参数,用于平衡双塔模型的损失和自监督学习的损失。
-
-

















 5942
5942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









