






主讲人:汪周谦
视频:(4)XTuner 大模型单卡低成本微调实战哔哩哔哩bilibili
主要内容:XTuner大模型单卡低成本微调实战
目录
1.Finetune简介
为什么要微调:当大语言模型运用到实际生活中或是在某个垂直的领域时,大语言模型的回答是不尽人意的。此时我希望模型能够回答出我们想要的结果,我们就需要对模型的参数进行调整,而大语言模型参数量十分庞大,想要将这个模型的参数都进行调整是比较困难的,所以才有了以下两种相对容易的微调方式。
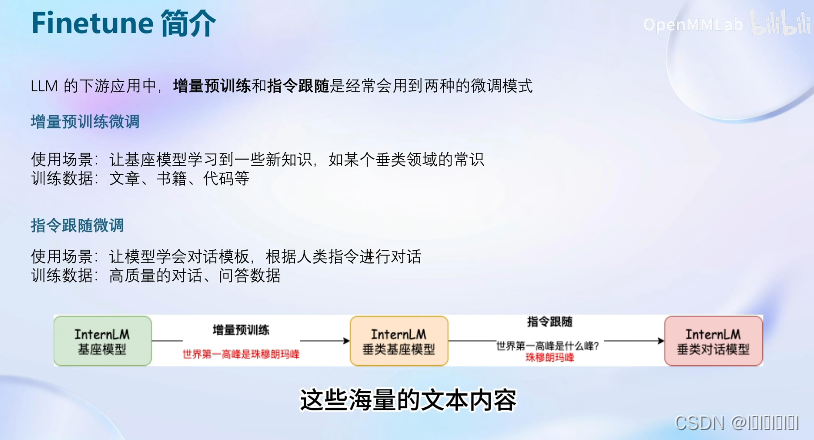
微调方式一:增量预训练
让模型学习到新的知识,如某个垂域的常识。
微调方式二:指令跟随

通过对pretrained模型进行额外的指令微调
指令跟随的实现原理
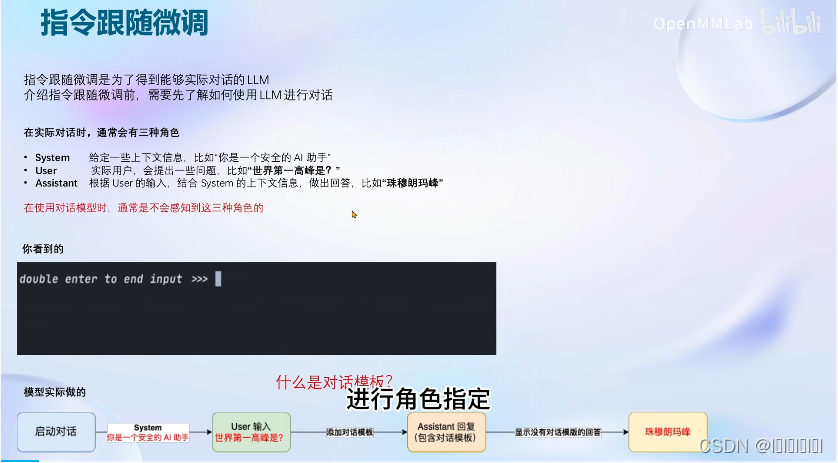
这一步就是完成了对话模板的构建,当我们完成好后就可以直接喂给模型进行微调训练了。
注意:不同的模型对话模板是不同的,如下图LlaMa2 和InternLM的对话模板就是不同的。
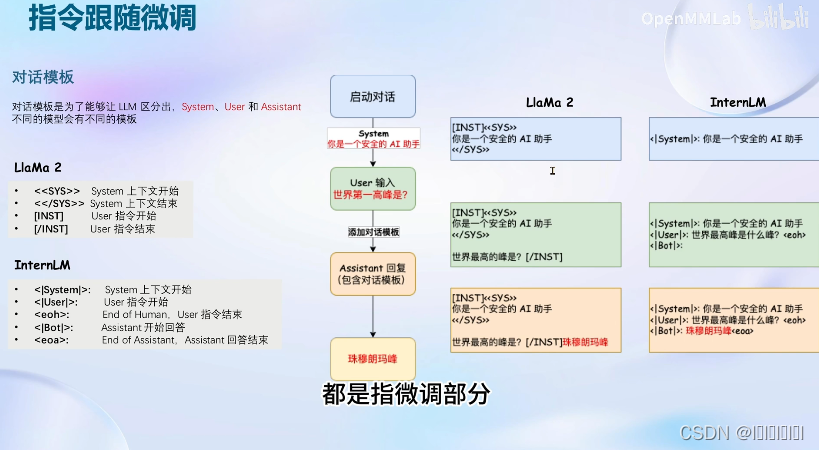
损失计算

增量预训练的微调
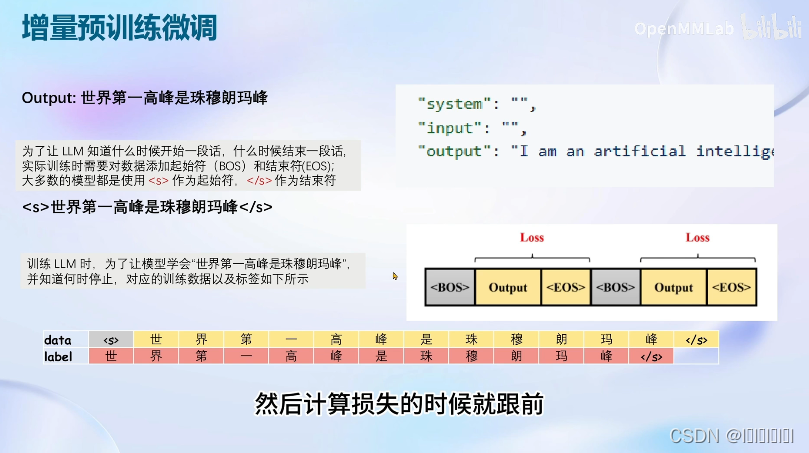
增量预训练的微调相较于指令微调不同是增量微调是喂给模型的是直接的一个陈述句,其中system和user输入都是为空的。
LoRA&QLoRA

LoRA减小显存开销,LoRA通过在原本大模型参数集中的地方(Linear)新增了一个支路,包含两个小的Linear(名为Adapter)远小于Linear。因此训练是会大幅降低显存的消耗。
LoRA&QLoRA&全参数微调
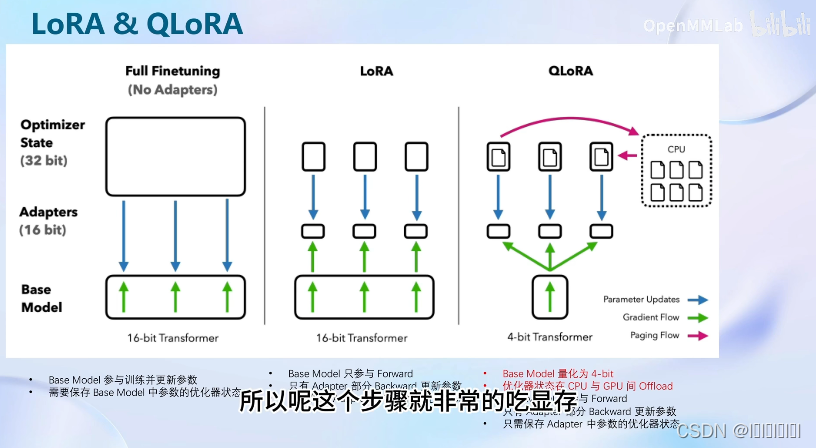
全参数微调:整个模型和参数优化器都会加入到显存中
LoRA微调:整个模型和LoRA部分的参数优化器加入到显存中,大幅减少了显存开销。
QLoRA微调:将基础模型量化为4-bit模型(不是很准确的加载),且优化器在cup和gpu之间可以进行调度。
2.XTuner介绍
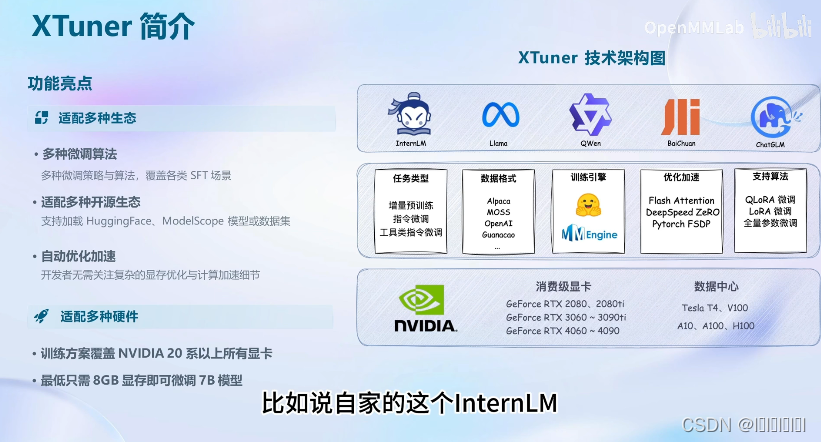
快速上手

数据引擎
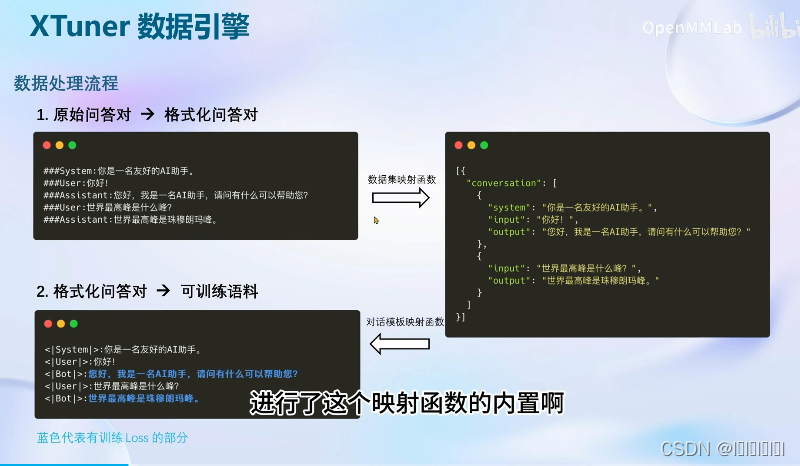
开发者可以专注于数据内容不必花费精力处理复杂的数据格式(👌)
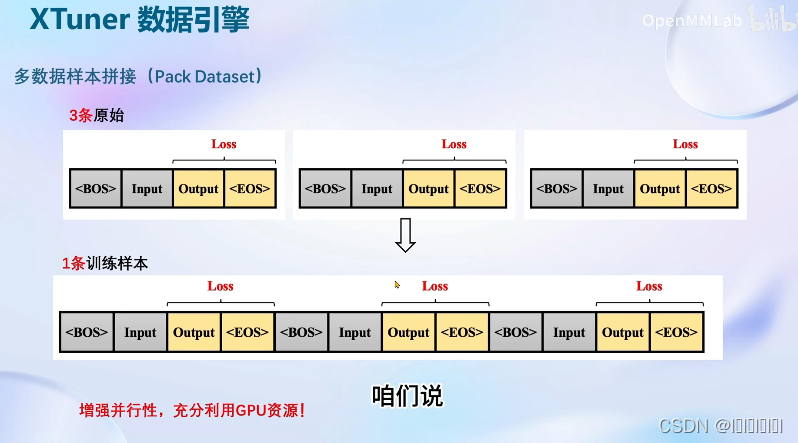
大显存可以使用的方案,增加工作效率。

实践部分
1.安装环境
2.拷贝配置文件

3.拷贝基座模型
![]()
4.开始训练

5.补充内容















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









