










“Convert any URL to an LLM-friendly input with a simple prefix https://r.jina.ai/”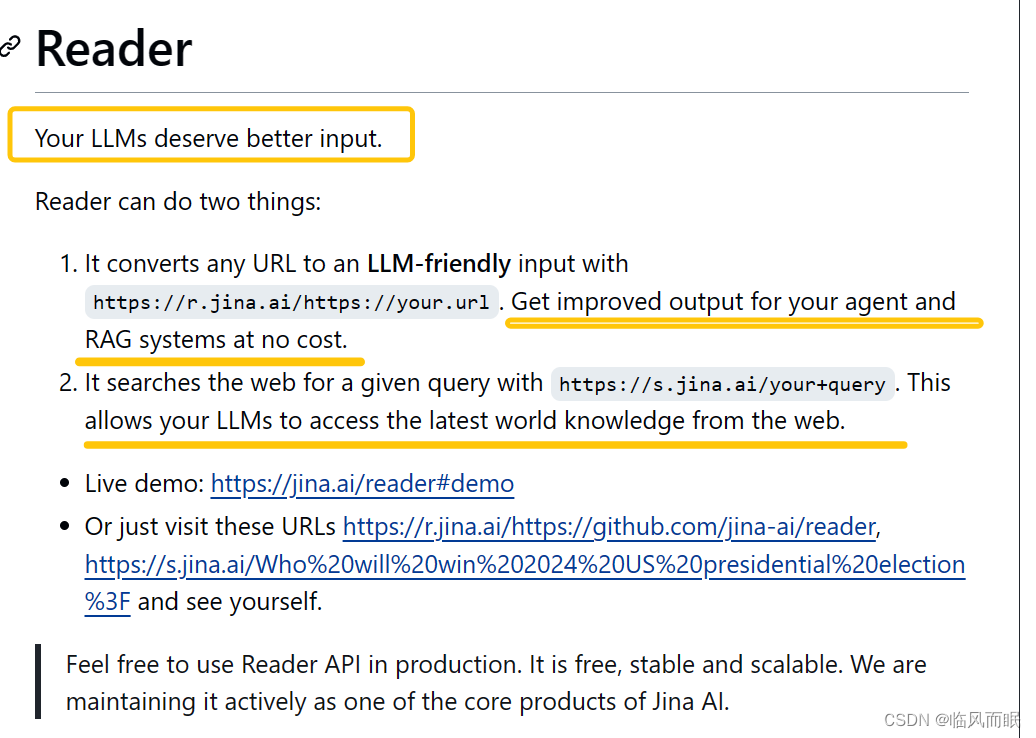
我试了试对于一些没啥反爬措施的(有严格反爬的我还没试),确实挺好用的
这个s.jina的endpoint是5月15发出来的,也很不错,这样子不用自己去调那些搜索引擎的api(有些申请比较麻烦,还有的第三方的像serperapi有次数限制)
源代码是用ts写的,没有仔细看
之前自己也处理过网页代码,用一些库比如bs4,html2text,感觉不如直接用这个hh(懒)
r.jina.ai
- 额 效果有点问题
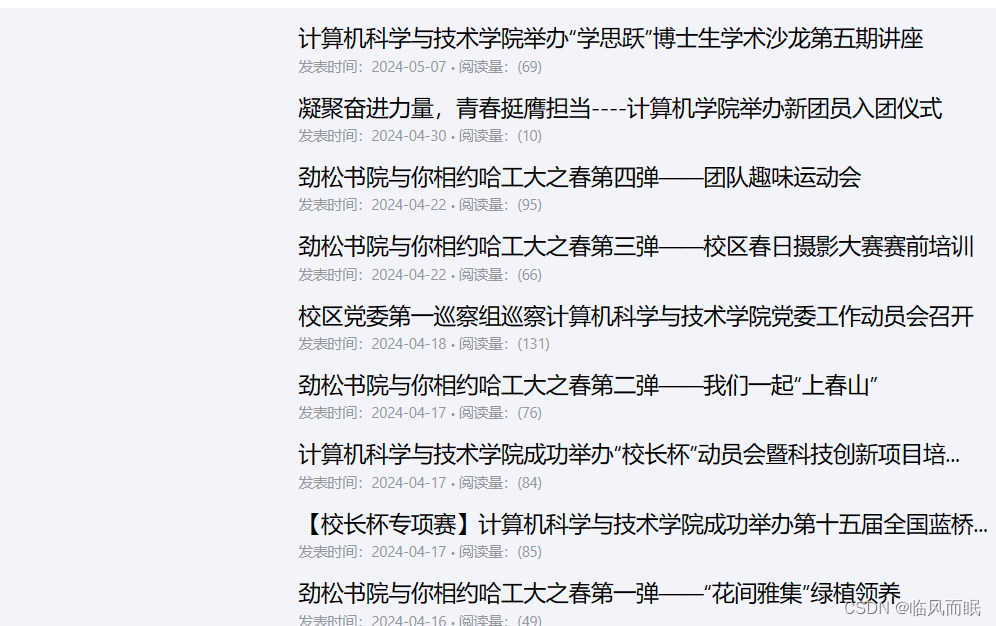
https://r.jina.ai/https://cst.hitwh.edu.cn/370/list.htm

中间的关键内容没了(这是默认模式,后来试了返回markdown格式比较合适)
不过具体的页面还好…
还是和爬虫结合着用吧
s.jina.ai
- 随便试个

https://s.jina.ai/%E6%A3%80%E7%B4%A2%E5%A2%9E%E5%BC%BA%E7%94%9F%E6%88%90
复杂用法
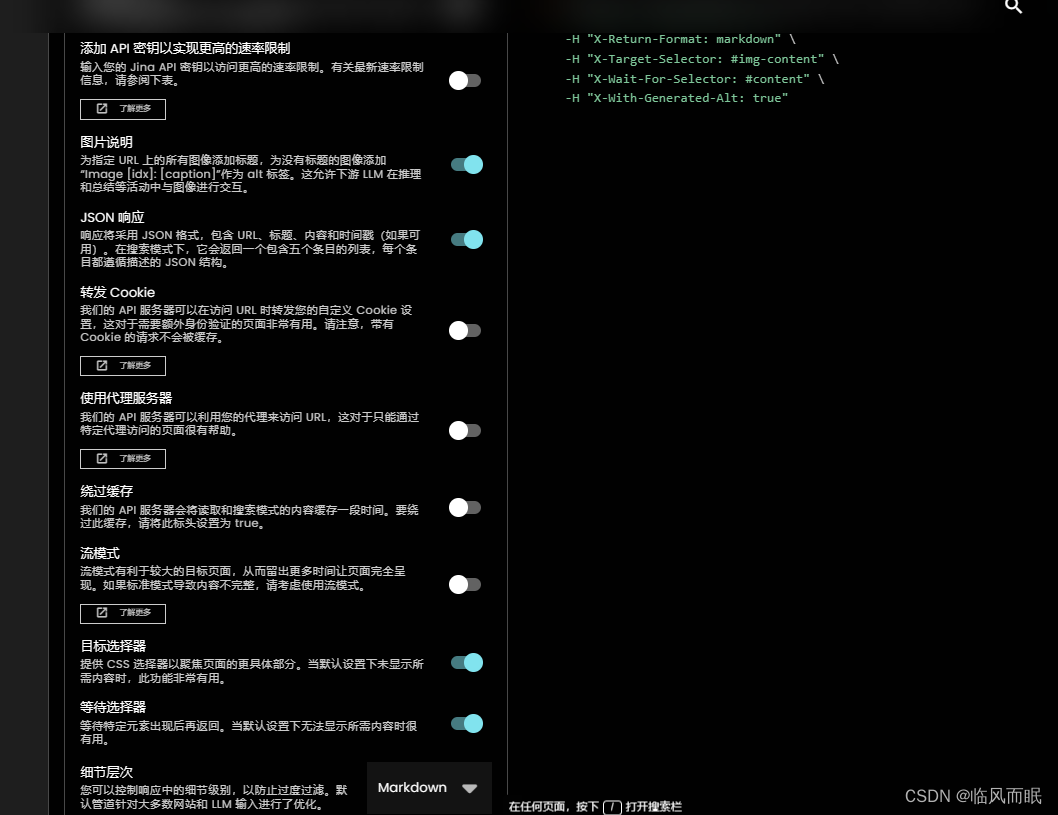
试了试发现可以做的事还有很多!
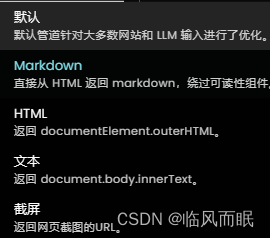
python基础调用
- 就是把那些参数得用上
import requests url = "https://r.jina.ai/https://cst.hitwh.edu.cn/370/list.htm" headers = { "Accept": "application/json", "X-Return-Format": "markdown", "X-Target-Selector": "#img-content", "X-Wait-For-Selector": "#content", "X-With-Generated-Alt": "true", } response = requests.get(url, headers=headers) # 打印响应内容 print(response.json())
更复杂的使用之后再开一篇再说















 671
671











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









