







 本文深入探讨了文本匹配问题,从暴力匹配方法开始,详细解释了KMP算法的工作原理,包括Next数组的构建及其优化。KMP算法通过避免不必要的字符比较,显著提高了匹配效率,达到O(n+m)的时间复杂度,对比暴力匹配的O(nm)有显著优势。此外,还介绍了Next数组的递推求解及其改进方法。
本文深入探讨了文本匹配问题,从暴力匹配方法开始,详细解释了KMP算法的工作原理,包括Next数组的构建及其优化。KMP算法通过避免不必要的字符比较,显著提高了匹配效率,达到O(n+m)的时间复杂度,对比暴力匹配的O(nm)有显著优势。此外,还介绍了Next数组的递推求解及其改进方法。
一、问题背景(文本匹配)
当前有一个文本串 S S S,长度为 n n n
再给定一个模式串 P P P,长度为 m m m
要求给出模式串在文本串中第一次匹配的起始位置。
二、一般思路(暴力匹配)
1.动画展示

2.步骤说明
设 i i i为文本串 S S S上的位置下标, j j j为模式串 P P P上的位置下标, i j ij ij初始值均为 0 0 0
步骤一
判断此时的
i
j
ij
ij是否超出各自字符串的限制,若
j
j
j超出
P
P
P的限制则退出并返回匹配成功处的位置下标,若
i
i
i超出
S
S
S的限制,则退出并说明无解;
再比较
S
[
i
]
S[i]
S[i]与
P
[
j
]
P[j]
P[j],若
S
[
i
]
=
=
P
[
j
]
S[i]==P[j]
S[i]==P[j],则
i
+
+
,
j
+
+
i++,j++
i++,j++,重复步骤一;
若
S
[
i
]
≠
P
[
j
]
S[i]\neq P[j]
S[i]=P[j],进入步骤二;
步骤二
i
=
i
−
j
+
1
i=i-j+1
i=i−j+1
j
=
0
j=0
j=0
返回步骤一
3.代码实现
int match_vio(char *P,char *S){
int n=strlen(S),i=0;
int m=strlen(P),j=0;
while(j<m&&i<n){
if(S[i]==P[j]){
i++;
j++;
}
else{
i-=j-1;
j=0;
}
}
if(j==m)return i-j;
else return -1;
}
三、KMP
1.动画展示

2.步骤说明
步骤一
判断此时的
i
j
ij
ij是否超出各自字符串的限制,若
j
j
j超出
P
P
P的限制则退出并返回匹配成功处的位置下标,若
i
i
i超出
S
S
S的限制,则退出并说明无解;
再比较
S
[
i
]
S[i]
S[i]与
P
[
j
]
P[j]
P[j],若
S
[
i
]
=
=
P
[
j
]
S[i]==P[j]
S[i]==P[j]或者
j
=
=
−
1
j==-1
j==−1,则
i
+
+
,
j
+
+
i++,j++
i++,j++,重复步骤一;
若
S
[
i
]
≠
P
[
j
]
S[i]\neq P[j]
S[i]=P[j],进入步骤二;
步骤二
i
i
i不变
j
=
n
e
x
t
[
j
]
j=next[j]
j=next[j]
进入步骤一
3. N e x t Next Next说明以及 j = N e x t [ j ] j=Next[j] j=Next[j]的合理性解释
N e x t Next Next表示代表当前字符之前的字符串中,字符串最长公共前缀后缀长度,假设其长度为 n n n,则存在 n n n个前缀与 n n n个后缀,我们舍去其中长度为 n n n的情况,则剩下 n − 1 n-1 n−1个前缀与 n − 1 n-1 n−1个后缀,前缀与后缀的最大匹配也就是该字符串的最长公共前缀后缀长度。
由上可知, N e x t Next Next的最小值就是 0 0 0(不包括第一个位置的 − 1 -1 −1)
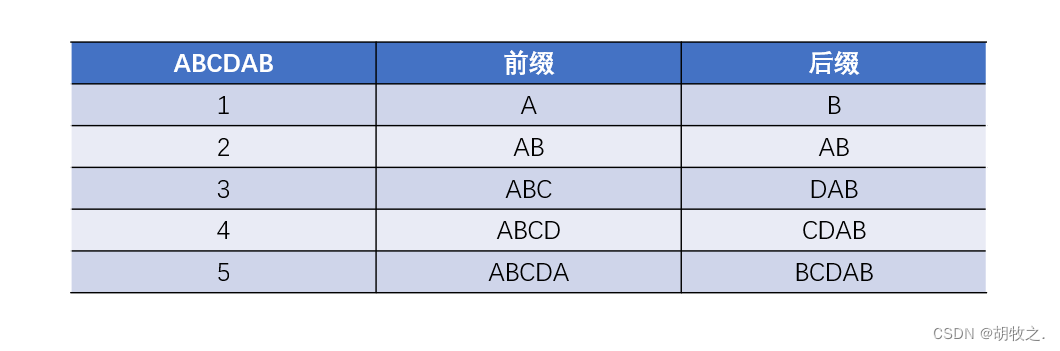
比如说当前字符串为
A
B
C
D
A
B
ABCDAB
ABCDAB
则有:
为什么此时可以不移动 i i i,只改变 j j j,中间是否有可能出现遗漏?( j = N e x t [ j ] j=Next[j] j=Next[j]的合理性解释)
在任一时刻,都满足
S
[
i
−
j
,
i
)
=
=
P
[
0
,
j
)
S[i-j,i)==P[0,j)
S[i−j,i)==P[0,j),也就是我们已经知道了
S
[
i
−
j
,
i
)
S[i-j,i)
S[i−j,i)的所有信息:
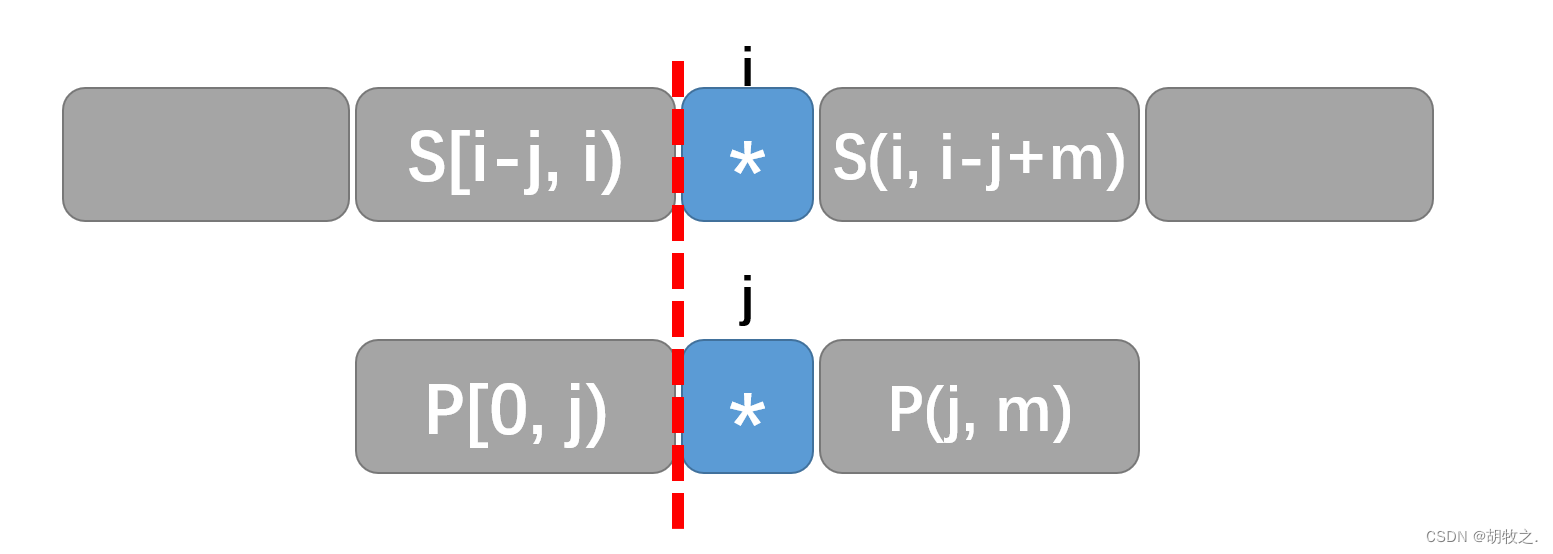
一旦比对失败,我们就可以知道哪些位置值得比对或者不必比对
而
N
e
x
t
[
j
]
Next[j]
Next[j]正是这一思想的践行
由于
N
e
x
t
Next
Next值是当前位置前字符串的最长公共前缀后缀长度,这个值的确认只与模式串有关,与文本串无关,可以事先确定
当失配时,
j
=
N
e
x
t
[
j
]
j=Next[j]
j=Next[j],充分利用已知信息,找出模式串中最值得再次匹配的位置
4.比较异同
最大的区别在于步骤二的处理,之前暴力匹配中需要同时移动 i j ij ij,但此时 k m p kmp kmp算法只需改变 j j j,而 k m p kmp kmp算法中 j j j最坏的结果也就只是变为 0 0 0,所以从整体上来看, k m p kmp kmp算法时间复杂度为 O ( n + m ) O(n+m) O(n+m)(后面会介绍关于 O ( m ) O(m) O(m)为Next数组建立的时间复杂度),暴力匹配时间复杂度为 O ( n m ) O(nm) O(nm),所以明显 k m p kmp kmp更优。
其次的区别是关于 i + + 、 j + + i++、j++ i++、j++条件的变化,暴力匹配中仅当相等时,而 k m p kmp kmp中当 j = = − 1 j==-1 j==−1同样作为条件, j = = − 1 j==-1 j==−1的实际作用是当 j = = 0 j==0 j==0时文本串与模式串失配(模式串的第一位都对不上),我们将 j j j置为-1,从而经过 i + + 、 j + + i++、j++ i++、j++使得模式串的第一位可以与文本串的下一位进行比对。
5.代码实现
int match_kmp(char *P,char *S){
int *next=buildNext(P);
int n=strlen(S),i=0;
int m=strlen(P),j=0;
while(j<m&&i<n){
if(j==-1||S[i]==P[j]){
i++;
j++;
}
else{
j=next[j];
}
}
delete [] next;
if(j==m)return i-j;
else return -1;
}
四、 N e x t Next Next递推求解
1.方法说明(若已知 N e x t [ 0 , j − 1 ] Next[0,j-1] Next[0,j−1],如何求 N e x t [ j ] Next[j] Next[j])
从定义出发,
N
e
x
t
[
j
]
Next[j]
Next[j]表示的是
P
[
0
,
j
)
P[0,j)
P[0,j)中最长公共前缀后缀长度,而我们已知
N
e
x
t
[
0
,
j
−
1
]
Next[0,j-1]
Next[0,j−1]
我们令
t
t
t表示
N
e
x
t
[
j
−
1
]
Next[j-1]
Next[j−1]
若
P
[
j
]
=
=
P
[
t
]
P[j]==P[t]
P[j]==P[t],表示上一次前缀与后缀的下一位同样是匹配的,所以此时的
N
e
x
t
[
j
]
=
N
e
x
t
[
j
−
1
]
+
1
Next[j]=Next[j-1]+1
Next[j]=Next[j−1]+1,也就可以写为:
N
e
x
t
[
+
+
j
]
=
+
+
t
Next[++j]=++t
Next[++j]=++t;为了避免越界,当
t
=
=
−
1
t==-1
t==−1时,同样进行这一步操作,而且所得结果依然符合
N
e
x
t
Next
Next数组
若
P
[
j
]
≠
P
[
t
]
P[j]\neq P[t]
P[j]=P[t],表示表示上一次前缀与后缀的下一位不是匹配的,通过
t
=
N
e
x
t
[
t
]
t=Next[t]
t=Next[t]的操作,回溯到再上一次匹配的前后缀,继续比对,直至
t
=
=
−
1
t==-1
t==−1或找到合理的匹配
2.代码
int * buildNext(char *P){
int m=strlen(P),j=0;
int *N=new int [m];
int t=N[0]=-1;
while(j<m-1){
(t==-1||P[j]==P[t])?N[++j]=++t:t=N[t];
}
return N;
}
五、 N e x t Next Next递推求解改进
1.缺陷

出现了连续的比对失败,原因?
当
P
[
3
]
≠
S
[
3
]
P[3]\neq S[3]
P[3]=S[3]时,根据
K
M
P
KMP
KMP算法的思路就是用
P
[
N
e
x
t
[
3
]
]
P[Next[3]]
P[Next[3]]与
S
[
3
]
S[3]
S[3]进行比对,由于此时满足
P
[
N
e
x
t
[
3
]
]
=
=
P
[
3
]
P[Next[3]]==P[3]
P[Next[3]]==P[3],所以比对的结果依然为失配;
当
P
[
3
]
=
=
S
[
3
]
P[3]== S[3]
P[3]==S[3]时,不必考虑这些
2.方法说明
根据上文,接下来要做的就是对
P
[
N
e
x
t
[
j
]
]
=
=
P
[
j
]
P[Next[j]]==P[j]
P[Next[j]]==P[j]的情况进行处理,避免无必要的比对
若出现了
P
[
N
e
x
t
[
j
]
]
=
=
P
[
j
]
P[Next[j]]==P[j]
P[Next[j]]==P[j]的情况,我们就令
N
e
x
t
[
j
]
=
N
e
x
t
[
N
e
x
t
[
j
]
]
Next[j]=Next[Next[j]]
Next[j]=Next[Next[j]],让它等于再上一位的值,根据递推关系,其实这样也就避免了所有的重复
3.代码
int * buildNext_2(char *P){
int m=strlen(P),j=0;
int *N=new int [m];
int t=N[0]=-1;
while(j<m-1){
if(t==-1||P[j]==P[t]){
j++;
t++;
N[j]=(P[j]!=P[t])?t:N[t];
}
else t=N[t];
}
return N;
}

















 2454
2454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









