







Ask in Any Modality: A Comprehensive Survey on Multimodal Retrieval-Augmented Generation
原文链接:2502.08826v2.pdf
Github资源链接:llm-lab-org/Multimodal-RAG-Survey: A Survey on Multimodal Retrieval-Augmented Generation
摘要翻译:
大语言模型(LLMs)由于依赖静态训练数据,在处理幻觉和过时知识方面存在困难。检索增强生成(RAG)通过整合外部动态信息,增强事实性和更新信息的基础,从而缓解这些问题。最近,多模态学习的进展推动了多模态 RAG 的发展,它结合了文本、图像、音频和视频等多种模态,以提升生成的输出。然而,跨模态对齐和推理给多模态 RAG 带来了独特的挑战,使其有别于传统的单模态 RAG。本综述对多模态 RAG 系统进行了系统而全面的分析,涵盖数据集、指标、基准测试、评估、方法,以及在检索、融合、增强和生成方面的创新。我们详细回顾了训练策略、鲁棒性增强和损失函数,同时探讨了多样的多模态 RAG 应用场景。此外,我们讨论了开放挑战和未来研究方向,以支持这一不断发展的领域取得进展。本综述为开发更强大、可靠的人工智能系统奠定了基础,这些系统能够有效地利用多模态动态外部知识库。
本文PDF版本笔记可通过链接直接下载
CSDN博文篇幅受限,故于PDF版本笔记中补充了第四章的相关整理;
建议直接下载PDF版本笔记,可读性更强,已设置永久免费下载
文章目录
一、引言及背景
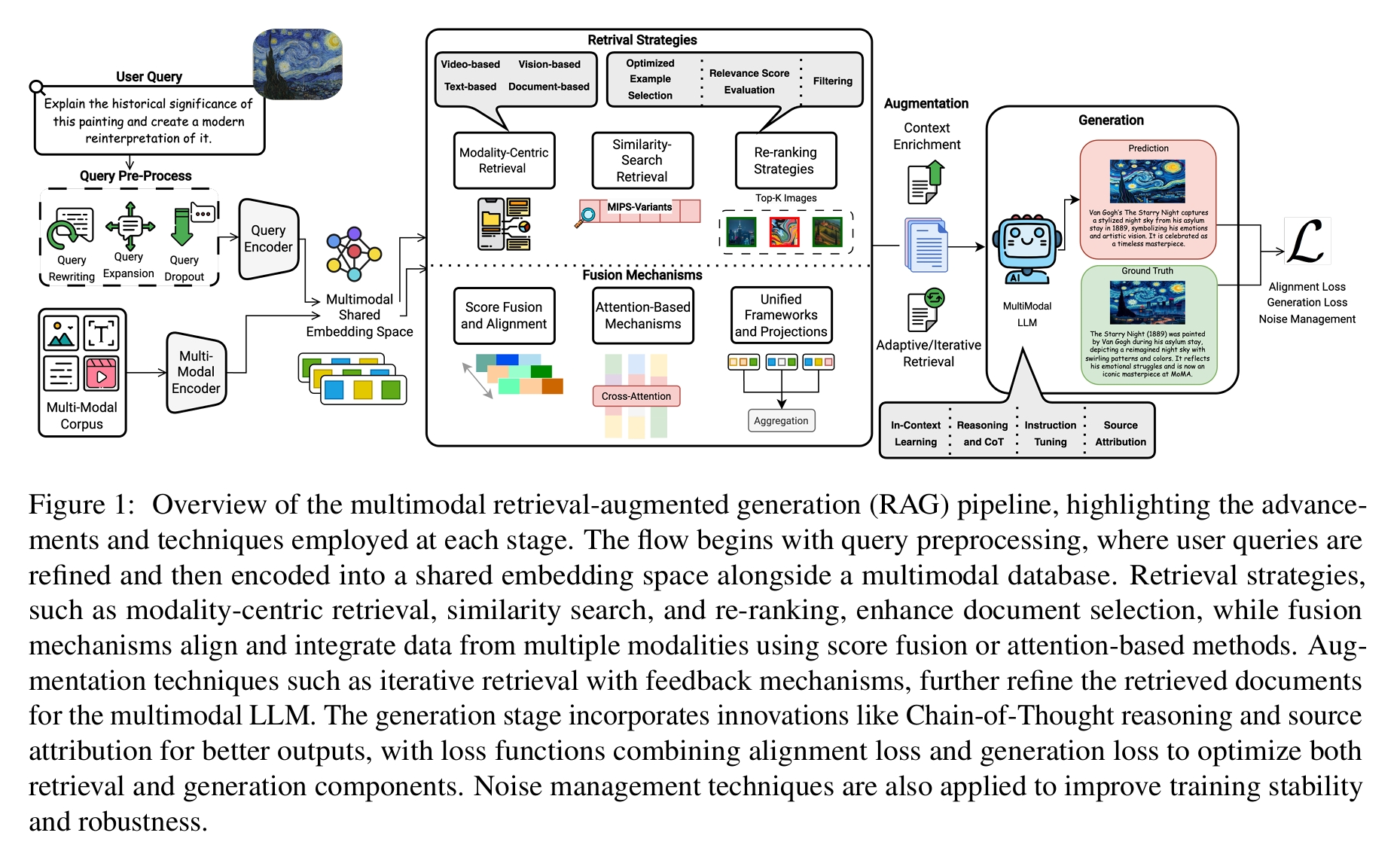
过程简述:
- 查询预处理阶段:用户输入多模态查询,系统对这些查询进行优化处理,使其更符合后续处理的要求。之后,查询与多模态数据库中的数据一同被编码到共享的嵌入空间,为检索阶段做准备。
- 检索策略阶段
- 模态中心检索:根据不同模态的特点进行针对性检索,例如文本模态可利用关键词匹配、语义理解等方式,图像模态可基于图像特征匹配等,提升检索的精准度。
- 相似性搜索:通过计算查询与数据库中数据的相似性,找到与查询相似的文档,常见方法如余弦相似度计算等。
- 重排序:对初步检索出的文档进行重新排序,根据相关性、重要性等因素调整文档顺序,筛选出最符合需求的文档。
- 融合机制阶段
- 分数融合:将来自不同模态的检索分数进行融合,综合判断数据的相关性,确定最终的检索结果。
- 基于注意力的方法:利用注意力机制,让模型自动关注不同模态中更重要的信息,实现多模态数据的有效整合。
- 统一框架和投影:运用统一的框架和投影方法,把多模态输入整合为连贯的表示形式。部分模型会将多模态数据转化为统一的格式,再进行融合处理;还有模型通过投影操作,将不同模态数据映射到同一空间,实现多模态信息的融合
- 增强技术阶段:采用带有反馈机制的迭代检索技术,根据前一次检索的结果进行反馈调整,再次检索,不断优化检索到的文档,为多模态大语言模型提供更优质的输入。
- 生成阶段
- 思维链推理:通过逻辑推理步骤,逐步生成更合理、更具逻辑性的输出,提升回答的质量。
- 来源归因:明确生成内容的信息来源,增强输出结果的可信度和可追溯性。
- 损失函数优化:将对齐损失和生成损失相结合,对检索和生成组件进行联合优化,提高整个系统的性能。
- 噪声管理技术:在训练过程中应用噪声管理技术,提高训练的稳定性,增强模型的鲁棒性,使其在面对各种情况时都能稳定运行
1.1 任务的数学化表达
输入:
- 多模态查询 q q q
中间环节:
-
多模态语料库 D = { d 1 , d 2 , ⋯ , d n } D = \{d_1, d_2, \cdots, d_n\} D={d1,d2,⋯,dn}
-
语料库 D D D中的每一个文档 d i d_i di都与一种模态 M d i M_{d_i} Mdi相关联,并由特定模态的编码器(将不同模态映射到一个共享的语义空间中)进行处理,得到:
z i = E n c M d i ( d i ) (1) z_{i}=Enc_{M_{d_{i}}}\left(d_{i}\right) \tag{1} zi=EncMdi(di)(1) -
所有编码表示的集合记为 Z = { z 1 , z 2 , ⋯ , z n } Z = \{z_1, z_2, \cdots, z_n\} Z={z1,z2,⋯,zn}
-
-
检索模型 R R R
- 评估每个编码文档表示 z z z与查询 q q q的相关性,表示为 R ( q , z ) R(q, z) R(q,z)
-
检索增强的多模态上下文 X X X
X = { d i ∣ s ( e q , z i ) ≥ τ M d i } (2) X=\left\{d_{i} | s\left(e_{q}, z_{i}\right) \geq \tau_{M_{d_{i}}}\right\} \tag{2} X={di∣s(eq,zi)≥τMdi}(2)- τ M d i \tau_{M_{d_i}} τMdi是模态 M d i M_{d_i} Mdi的相关性阈值
- e q e_q eq是查询 q q q在共享语义空间中的编码表示
- s s s是一个评分函数,用于衡量编码后的查询和文档表示之间的相关性( R R R负责初步检索, s s s负责对初步检索结果进行精细化筛选)
输出:
- 生成模型
G
G
G
- 以用户查询 q q q和检索到的文档 X X X为上下文,生成最终的多模态响应,记为 r = G ( q , X ) r = G(q, X) r=G(q,X)
1.2 相关工作整理

- 检索策略
- 高效搜索和相似性检索:使用最大内积搜索(MIPS)变体等进行快速相似性比较,如 MuRAG、RA-CM3 等系统采用近似 MIPS;还有基于 CLIP、BLIP 的多模态编码器,将不同模态投影到共享潜在空间。
- 基于模态的检索:包括文本中心检索(如 BM25、MiniLM 等)、视觉中心检索(如 EchoSight、ImgRet 等)、视频中心检索(如 iRAG、MV - Adapter 等)以及文档检索和布局理解(如 ColPali、ColQwen2 等)。
- 重排序和选择策略:通过优化示例选择(如采用多步检索、统计方法校准等)、相关性评分评估(如使用多模态相似性度量、交叉编码器等)和过滤机制(如硬负挖掘、共识过滤等)来提高检索质量
- 融合机制
- 分数融合和对齐:将多模态表示转换为统一格式或嵌入共享空间,如通过交叉编码器、CLIP 分数融合等方式,使不同模态对齐。
- 基于注意力的机制:利用交叉注意力动态加权跨模态交互,支持任务特定推理,如在视频文本对齐、多模态数据融合等方面应用。
- 统一框架和投影:将多模态输入整合为连贯表示,如通过层次交叉链、迭代集成、统一数据格式等方法,优化存储和可解释性。
- 增强技术
- 上下文丰富:通过精炼或扩展检索数据,整合额外上下文元素,增强检索知识的相关性,如 EMERGE、MiRAG 等模型的做法。
- 自适应和迭代检索:自适应检索根据查询复杂度调整检索,如 SKURG、SAM - RAG 等;迭代检索通过多步细化结果,结合反馈优化后续查询,如 IRAMIG、OMG - QA 等。
- 生成技术
- 上下文学习:利用检索内容作为少样本示例,增强多模态 RAG 的推理能力,如 RMR、Sharifymoghaddam 等人的模型,还有通过优化示例选择、引入新的学习方法提升性能。
- 推理:采用结构化推理技术,如思维链(CoT),将复杂推理分解为小步骤,增强多模态 RAG 系统的连贯性和鲁棒性,多个模型已应用该技术。
- 指令调整:对生成组件进行微调或指令调整,以适应特定应用,多个研究工作通过构建数据集、优化模型等方式提高生成质量。
- 来源归因和证据透明度:确保多模态 RAG 系统中生成结果的来源可追溯,通过识别和引用证据,增强信息的可靠性和透明度。
- 训练策略
- 对齐:使用对比学习,如 InfoNCE 损失,提高表示质量;还有 eCLIP 损失、Mixup 策略等方法,优化检索增强生成。
- 生成:自回归语言模型常用交叉熵损失训练,图像生成则采用生成对抗网络(GANs)和扩散模型(Diffusion Models),并使用相应的损失函数。
- 鲁棒性和噪声管理:处理多模态训练中的噪声和模态特定偏差,如通过注入无关结果、知识蒸馏、基于超图的知识聚合等方法,增强模型的鲁棒性。
二、数据集和基准
多模态数据集汇总于:llm-lab-org/Multimodal-RAG-Survey: A Survey on Multimodal Retrieval-Augmented Generation
🖼 Image-Text
| Name | Statistics and Description | Modalities | Link |
|---|---|---|---|
| LAION-400M | 200M image–text pairs; used for pre-training multimodal models. | Image, Text | LAION-400M |
| Conceptual-Captions (CC) | 15M image–caption pairs; multilingual English–German image descriptions. | Image, Text | Conceptual Captions |
| CIRR | 36,554 triplets from 21,552 images; focuses on natural image relationships. | Image, Text | CIRR |
| MS-COCO | 330K images with captions; used for caption-to-image and image-to-caption generation. | Image, Text | MS-COCO |
| Flickr30K | 31K images annotated with five English captions per image. | Image, Text | Flickr30K |
| Multi30K | 30K German captions from native speakers and human-translated captions. | Image, Text | Multi30K |
| NoCaps | For zero-shot image captioning evaluation; 15K images. | Image, Text | NoCaps |
| Laion-5B | 5B image–text pairs used as external memory for retrieval. | Image, Text | LAION-5B |
| COCO-CN | 20,341 images for cross-lingual tagging and captioning with Chinese sentences. | Image, Text | COCO-CN |
| CIRCO | 1,020 queries with an average of 4.53 ground truths per query; for composed image retrieval. | Image, Text | CIRCO |
🎞 Video-Text
| Name | Statistics and Description | Modalities | Link |
|---|---|---|---|
| BDD-X | 77 hours of driving videos with expert textual explanations; for explainable driving behavior. | Video, Text | BDD-X |
| YouCook2 | 2,000 cooking videos with aligned descriptions; focused on video–text tasks. | Video, Text | YouCook2 |
| ActivityNet | 20,000 videos with multiple captions; used for video understanding and captioning. | Video, Text | ActivityNet |
| SoccerNet | Videos and metadata for 550 soccer games; includes transcribed commentary and key event annotations. | Video, Text | SoccerNet |
| MSR-VTT | 10,000 videos with 20 captions each; a large video description dataset. | Video, Text | MSR-VTT |
| MSVD | 1,970 videos with approximately 40 captions per video. | Video, Text | MSVD |
| LSMDC | 118,081 video–text pairs from 202 movies; a movie description dataset. | Video, Text | LSMDC |
| DiDemo | 10,000 videos with four concatenated captions per video; with temporal localization of events. | Video, Text | DiDemo |
| Breakfast | 1,712 videos of breakfast preparation; one of the largest fully annotated video datasets. | Video, Text | Breakfast |
| COIN | 11,827 instructional YouTube videos across 180 tasks; for comprehensive instructional video analysis. | Video, Text | COIN |
| MSRVTT-QA | Video question answering benchmark. | Video, Text | MSRVTT-QA |
| MSVD-QA | 1,970 video clips with approximately 50.5K QA pairs; video QA dataset. | Video, Text | MSVD-QA |
| ActivityNet-QA | 58,000 human–annotated QA pairs on 5,800 videos; benchmark for video QA models. | Video, Text | ActivityNet-QA |
| EpicKitchens-100 | 700 videos (100 hours of cooking activities) for online action prediction; egocentric vision dataset. | Video, Text | EPIC-KITCHENS-100 |
| Ego4D | 4.3M video–text pairs for egocentric videos; massive-scale egocentric video dataset. | Video, Text | Ego4D |
| HowTo100M | 136M video clips with captions from 1.2M YouTube videos; for learning text–video embeddings. | Video, Text | HowTo100M |
| CharadesEgo | 68,536 activity instances from ego–exo videos; used for evaluation. | Video, Text | Charades-Ego |
| ActivityNet Captions | 20K videos with 3.7 temporally localized sentences per video; dense-captioning events in videos. | Video, Text | ActivityNet Captions |
| VATEX | 34,991 videos, each with multiple captions; a multilingual video-and-language dataset. | Video, Text | VATEX |
| Charades | 9,848 video clips with textual descriptions; a multimodal research dataset. | Video, Text | Charades |
| WebVid | 10M video–text pairs (refined to WebVid-Refined-1M). | Video, Text | WebVid |
| Youku-mPLUG | Chinese dataset with 10M video–text pairs (refined to Youku-Refined-1M). | Video, Text | Youku-mPLUG |
🔊 Audio-Text
| Name | Statistics and Description | Modalities | Link |
|---|---|---|---|
| LibriSpeech | 1,000 hours of read English speech with corresponding text; ASR corpus based on audiobooks. | Audio, Text | LibriSpeech |
| SpeechBrown | 55K paired speech-text samples; 15 categories covering diverse topics from religion to fiction. | Audio, Text | SpeechBrown |
| AudioCap | 46K audio clips paired with human-written text captions. | Audio, Text | AudioCaps |
| AudioSet | 2M human-labeled sound clips from YouTube across diverse audio event classes (e.g., music or environmental). | Audio | AudioSet |
🩺 Medical
| Name | Statistics and Description | Modalities | Link |
|---|---|---|---|
| MIMIC-CXR | 125,417 labeled chest X-rays with reports; widely used for medical imaging research. | Image, Text | MIMIC-CXR |
| CheXpert | 224,316 chest radiographs of 65,240 patients; focused on medical analysis. | Image, Text | CheXpert |
| MIMIC-III | Health-related data from over 40K patients; includes clinical notes and structured data. | Text | MIMIC-III |
| IU-Xray | 7,470 pairs of chest X-rays and corresponding diagnostic reports. | Image, Text | IU-Xray |
| PubLayNet | 100,000 training samples and 2,160 test samples built from PubLayNet for document layout analysis. | Image, Text | PubLayNet |
👗 Fashion
| Name | Statistics and Description | Modalities | Link |
|---|---|---|---|
| Fashion-IQ | 77,684 images across three categories; evaluated with Recall@10 and Recall@50 metrics. | Image, Text | Fashion-IQ |
| FashionGen | 260.5K image–text pairs of fashion images and item descriptions. | Image, Text | FashionGen |
| VITON-HD | 83K images for virtual try-on; high-resolution clothing items dataset. | Image, Text | VITON-HD |
| Fashionpedia | 48,000 fashion images annotated with segmentation masks and fine-grained attributes. | Image, Text | Fashionpedia |
| DeepFashion | Approximately 800K diverse fashion images for pseudo triplet generation. | Image, Text | DeepFashion |
💡 QA
| Name | Statistics and Description | Modalities | Link |
|---|---|---|---|
| VQA | 400K QA pairs with images for visual question-answering tasks. | Image, Text | VQA |
| PAQ | 65M text-based QA pairs; a large-scale dataset for open-domain QA tasks. | Text | PAQ |
| ELI5 | 270K complex questions augmented with web pages and images; designed for long-form QA tasks. | Text | ELI5 |
| OK-VQA | 14K questions requiring external knowledge for visual question answering tasks. | Image, Text | OK-VQA |
| WebQA | 46K queries requiring reasoning across text and images; multimodal QA dataset. | Text, Image | WebQA |
| Infoseek | Fine-grained visual knowledge retrieval using a Wikipedia-based knowledge base (~6M passages). | Image, Text | Infoseek |
| ClueWeb22 | 10 billion web pages organized into subsets; a large-scale web corpus for retrieval tasks. | Text | ClueWeb22 |
| MOCHEG | 15,601 claims annotated with truthfulness labels and accompanied by textual and image evidence. | Text, Image | MOCHEG |
| VQA v2 | 1.1M questions (augmented with VG-QA questions) for fine-tuning VQA models. | Image, Text | VQA v2 |
| A-OKVQA | Benchmark for visual question answering using world knowledge; around 25K questions. | Image, Text | A-OKVQA |
| XL-HeadTags | 415K news headline-article pairs spanning 20 languages across six diverse language families. | Text | XL-HeadTags |
| SEED-Bench | 19K multiple-choice questions with accurate human annotations across 12 evaluation dimensions. | Text | SEED-Bench |
🌎 Other
| Name | Statistics and Description | Modalities | Link |
|---|---|---|---|
| ImageNet | 14M labeled images across thousands of categories; used as a benchmark in computer vision research. | Image | ImageNet |
| Oxford Flowers102 | Dataset of flowers with 102 categories for fine-grained image classification tasks. | Image | Oxford Flowers102 |
| Stanford Cars | Images of different car models (five examples per model); used for fine-grained categorization tasks. | Image | Stanford Cars |
| GeoDE | 61,940 images from 40 classes across six world regions; emphasizes geographic diversity in object recognition. | Image | GeoDE |
多模态RAG测试基准
- 视觉推理、外部知识整合和动态检索
- 统一评估:M2RAG 基准结合细粒度文本模态和多模态指标,对生成语言质量和视觉元素有效整合进行联合评估。
- 视觉任务测试:MRAG-Bench、VQAv2、VisDoMBench 等聚焦视觉的评估,用于测试模型在复杂视觉任务上的表现。
- 跨模态推理评估:Dyn-VQA、MMBench、ScienceQA 等评估模型在文本、视觉和图表输入上的动态检索和多跳推理能力
- 数据整合能力评估
- 知识密集型评估:TriviaQA、Natural Questions 等知识密集型基准,与 OmniDocBench 等面向文档的评估一起,衡量非结构化和结构化数据的整合情况。
- 其他能力评估
- 检索相关评估:RAG-Check 等先进检索基准,评估检索相关性和系统可靠性。
- 鲁棒性评估:Counterfactual VQA 等专门评估,测试模型对对抗性输入的鲁棒性。
- OCR 影响评估:OHRBench 等 OCR 影响研究,考察错误对 RAG 系统的级联效应。

三、评估指标
3.1 检索性能评估
-
基础指标:检索性能通过准确率(Accuracy)、召回率(Recall)、精确率(Precision)来衡量,F1 分数(F1 score)综合了召回率和精确率,用于更全面地评估检索效果。
-
特定召回指标:Recall@K 是在检索结果的前 K 个中,能找到多少真正相关的项目,相较于标准召回率,它能更精准地反映模型在特定数量检索结果内找到相关信息的能力,因此更受青睐。
-
平均倒数排名指标:平均倒数排名(Mean Reciprocal Rank,MRR)
-
平均倒数排名(MRR)衡量的是在一系列查询中,第一个相关结果在返回列表中的排名位置的倒数的平均值。
M R R = 1 Q ∑ q = 1 Q 1 r a n k q MRR=\frac{1}{Q} \sum_{q=1}^{Q} \frac{1}{rank_{q}} MRR=Q1q=1∑Qrankq1- 其中Q表示查询的总数
- r a n k q rank_{q} rankq表示第q个查询的第一个相关结果在返回列表中的排名 。
- 如果一个查询的第一个相关结果排在返回列表的第1位,那么它对MRR的贡献就是1;如果排在第3位,贡献就是1/3。
-
MRR综合考虑了所有查询中相关结果的排名情况,不仅能反映检索系统能否找到相关结果,还能体现这些结果在排序中的位置。MRR的值越接近1,说明检索系统的排序效果越好,相关结果越容易被排在靠前的位置。
-
3.2 文本评估指标
参考资料:文本生成评价方法 BLEU ROUGE CIDEr SPICE Perplexity METEOR - 知乎
-
精确匹配(Exact Match,EM):用于衡量预测文本与参考文本完全一致的比例。若预测文本和参考文本完全相同,EM为1;否则为0。例如,参考文本是 “apple”,预测文本也是 “apple”,则EM = 1;若预测文本是 “apples”,则EM = 0。
-
BLEU(Bilingual Evaluation Understudy):常用于评估机器翻译质量,综合考虑了翻译结果与参考翻译的匹配程度以及长度惩罚。
B L E U ( p n , B P ) = B P ⋅ e x p ( ∑ n = 1 N w n l o g p n ) BLEU\left(p_{n}, BP\right)=BP \cdot exp \left(\sum_{n=1}^{N} w_{n} log p_{n}\right) BLEU(pn,BP)=BP⋅exp(n=1∑Nwnlogpn)- p n p_{n} pn代表n - grams的精确率,也就是 二者n-gram 的重合程度
- w n w_{n} wn是分配给n - gram精确率的权重
- B P BP BP是长度惩罚因子。 B P = { 1 , l e n g t h > r l e x p ( 1 − r l c l ) , l e n g t h ≤ r l BP=\begin{cases}1, & length > rl \\ exp \left(1-\frac{r l}{c l}\right), & length \leq rl\end{cases} BP={1,exp(1−clrl),length>rllength≤rl , r l rl rl表示参考文本长度, c l cl cl表示候选文本长度。
-
ROUGE(Recall - Oriented Understudy for Gisting Evaluation):包括ROUGE - N和ROUGE - L等变体。
- ROUGE - N通过计算生成文本与参考文本中共同出现的N - grams数量占参考文本中N - grams总数量的比例来衡量。
R O U G E − N = ∑ g r a m N ∈ R e f C o u n t m a t c h ( g r a m N ) ∑ g r a m N ∈ R e f C o u n t ( g r a m N ) ROUGE-N =\frac{\sum_{gram _{N} \in Ref} Count_{match }\left(gram_{N}\right)}{\sum_{gram _{N} \in Ref} Count\left(gram_{N}\right)} ROUGE−N=∑gramN∈RefCount(gramN)∑gramN∈RefCountmatch(gramN)
-
ROUGE - L基于最长公共子序列(LCS)计算
R O U G E − L = L C S ( X , Y ) ∣ Y ∣ ROUGE-L =\frac{LCS(X, Y)}{|Y|} ROUGE−L=∣Y∣LCS(X,Y)- L C S ( X , Y ) LCS(X, Y) LCS(X,Y)是生成文本 X X X和参考文本 Y Y Y的最长公共子序列长度, ∣ Y ∣ |Y| ∣Y∣是参考文本的长度。
-
METEOR(Metric for Evaluation of Translation with Explicit ORdering):是一种用于评估机器翻译输出质量的指标。与 BLEU 相比,METEOR 考虑了更多的因素,如同义词匹配、词干匹配、词序等,因此它通常被认为是一个更全面的评价指标。
-
【NLG】(三)文本生成评价指标—— METEOR原理及代码 - 知乎 下图取自该链接
M = F m e a n × ( 1 − p ) M = F_{mean}\times(1 - p) M=Fmean×(1−p)- F值计算:F值通过准确率(候选翻译中正确翻译的比例)和召回率(参考翻译中的单词在候选翻译中被正确翻译出来的比例)的调和平均计算得出,且召回率的权重高于准确率。
- 通过WordNet和词干还原确定匹配单词
- 公式为: F m e a n = P R ( 1 − α ) R + α P F_{mean}=\frac{PR}{(1-\alpha)R + \alpha P} Fmean=(1−α)R+αPPR,其中 α \alpha α为可调参数
- 块惩罚(Chunk Penalty)计算:为了衡量翻译中词序的差异,METEOR引入了“块”(chunk)的概念。块是指候选翻译和参考翻译中连续匹配的单词序列。计算块惩罚时,先统计匹配的总块数 c c c以及匹配的单词总数 u m u_m um 。块惩罚公式为: p = 0.5 × ( c u m ) 3 p = 0.5\times(\frac{c}{u_m})^3 p=0.5×(umc)3,其中0.5和3是超参数,可根据实际情况调整。块惩罚用于惩罚词序不一致的情况,若翻译的词序与参考翻译差异较大,块的数量会增多,惩罚值也就越大。

- F值计算:F值通过准确率(候选翻译中正确翻译的比例)和召回率(参考翻译中的单词在候选翻译中被正确翻译出来的比例)的调和平均计算得出,且召回率的权重高于准确率。
-
3.3 图像评估指标
3.3.1 图像字幕质量评估
-
CIDEr(Consensus - Based Image Description Evaluation):专门用于评价图像描述(image caption)任务,通过计算生成的描述与一组参考描述之间的相似性来评估图像描述的质量
-
把每个句子看成文档,然后计算其 TF-IDF 向量(注意向量的每个维度表示的是n-gram 而不一定是单词)的余弦夹角,据此得到候选句子和参考句子的相似度。
$$
\begin{align}
\text{CIDEr}© &= \frac{1}{m} \sum_{i=1}^m S(c, s_i)\
S(c, s_i) &= \frac{\mathbf{v}_c \cdot \mathbf{v}_i}{|\mathbf{v}_c| \cdot |\mathbf{v}_i|}\end{align}
$$-
S ( c , s i ) S(c, s_i) S(c,si)表示生成描述 c c c与参考描述 s i s_i si之间的相似度
-
v c \mathbf{v}_c vc和 v i \mathbf{v}_i vi分别表示生成描述 c c c和参考描述 s i s_i si的向量形式
v c = [ w g 1 ( c ) , w g 2 ( c ) , … , w g k ( c ) ] v i = [ w g 1 ( s i ) , w g 2 ( s i ) , … , w g k ( s i ) ] \mathbf{v}_c = [w_{g_1}(c), w_{g_2}(c), \dots, w_{g_k}(c)] \\ \mathbf{v}_i = [w_{g_1}(s_i), w_{g_2}(s_i), \dots, w_{g_k}(s_i)] vc=[wg1(c),wg2(c),…,wgk(c)]vi=[wg1(si),wg2(si),…,wgk(si)]- 向量中中每个元素为对应n-gram的TF-IDF权重,可区分常见词和关键信息词
- 计算公式为: w g = tf ( g ) ⋅ log ( N df ( g ) ) w_g = \text{tf}(g) \cdot \log \left( \frac{N}{\text{df}(g)} \right) wg=tf(g)⋅log(df(g)N)
- Term Frequency (TF):统计n-gram g g g在当前描述中的出现次数,并归一化(如除以总词数)。
- Inverse Document Frequency (IDF):统计包含n-gram g g g的参考描述数量 df ( g ) \text{df}(g) df(g),计算其逆文档频率。
-
-
SPICE(Semantic Propositional Image Caption Evaluation):将文本描述解析为场景图(Scene Graph),提取其中的语义命题(如对象、属性、对象间关系),并通过计算生成描述与参考描述的语义命题重叠度来评估质量。(与传统的基于n-gram重叠的指标(如BLEU、CIDEr)不同)
-
场景图构建

-
将描述解析为场景图,包含以下元素:
• 对象(Objects):描述中的实体(如
dog,park)。• 属性(Attributes):对象的特征(如
black,running)。• 关系(Relationships):对象间的交互(如
running in,sitting on)。
-
-
语义命题提取
-

-
将场景图转换为元组集合(即语义命题): T ( G ( c ) ) ≜ O ( c ) ∪ E ( c ) ∪ K ( c ) T(G(c)) \triangleq O(c) \cup E(c) \cup K(c) T(G(c))≜O(c)∪E(c)∪K(c)
-
上图表示成元组集合为:{(girl), (court), (girl, young), (girl, standing), (court, tennis), (girl, on-top-of, court)}
-
命题匹配
- P ( c , S ) = ∣ T ( G ( c ) ) ⊗ T ( G ( S ) ) ∣ ∣ T ( G ( c ) ) ∣ = 匹配的语义命题数量 生成描述的语义命题总数 P(c, S) = \frac{\left| T(G(c)) \otimes T(G(S)) \right|}{\left| T(G(c)) \right|}=\frac{\text{匹配的语义命题数量}}{\text{生成描述的语义命题总数}} P(c,S)=∣T(G(c))∣∣T(G(c))⊗T(G(S))∣=生成描述的语义命题总数匹配的语义命题数量
- R ( c , S ) = ∣ T ( G ( c ) ) ⊗ T ( G ( S ) ) ∣ ∣ T ( G ( S ) ) ∣ = 匹配的语义命题数量 参考描述的语义命题总数 R(c, S) = \frac{\left| T(G(c)) \otimes T(G(S)) \right|}{\left| T(G(S)) \right|}=\frac{\text{匹配的语义命题数量}}{\text{参考描述的语义命题总数}} R(c,S)=∣T(G(S))∣∣T(G(c))⊗T(G(S))∣=参考描述的语义命题总数匹配的语义命题数量
- ⊗ \otimes ⊗:语义命题匹配操作,允许形式差异和同义词等价(与METEOR规则一致)
-
F-score计算
- S P I C E ( c , S ) = F 1 ( c , S ) = 2 ⋅ P ( c , S ) ⋅ R ( c , S ) P ( c , S ) + R ( c , S ) SPICE(c, S) = F_1(c, S) = \frac{2 \cdot P(c, S) \cdot R(c, S)}{P(c, S) + R(c, S)} SPICE(c,S)=F1(c,S)=P(c,S)+R(c,S)2⋅P(c,S)⋅R(c,S)
3.3.2 语义对齐评估
-
BERTScore:通过预训练语言模型(如BERT、RoBERTa)捕捉文本的深层语义关联,解决了传统n-gram匹配(如BLEU、ROUGE)无法处理同义替换和复杂句法结构的局限性。其核心思想是将词向量相似度与对齐策略结合,模拟人类对语义一致性的判断。
-
输入准备
• 候选句子(Candidate Sentence):待评估的生成文本,记为 c = [ w 1 c , w 2 c , . . . , w ∣ c ∣ c ] c = [w_1^c, w_2^c, ..., w_{|c|}^c] c=[w1c,w2c,...,w∣c∣c]。
• 参考句子(Reference Sentence):人工标注的参考答案,记为 r = [ w 1 r , w 2 r , . . . , w ∣ r ∣ r ] r = [w_1^r, w_2^r, ..., w_{|r|}^r] r=[w1r,w2r,...,w∣r∣r]。
-
上下文嵌入提取
使用预训练BERT模型生成词级别的上下文嵌入向量:
• 候选句子嵌入: E c = [ e 1 c , e 2 c , . . . , e ∣ c ∣ c ] E^c = [e_1^c, e_2^c, ..., e_{|c|}^c] Ec=[e1c,e2c,...,e∣c∣c],其中 e i c ∈ R d e_i^c \in \mathbb{R}^d eic∈Rd 是候选词 w i c w_i^c wic 的BERT嵌入。
• 参考句子嵌入: E r = [ e 1 r , e 2 r , . . . , e ∣ r ∣ r ] E^r = [e_1^r, e_2^r, ..., e_{|r|}^r] Er=[e1r,e2r,...,e∣r∣r],其中 e j r ∈ R d e_j^r \in \mathbb{R}^d ejr∈Rd 是参考词 w j r w_j^r wjr 的BERT嵌入。
-
构建余弦相似度矩阵
计算候选与参考词之间的余弦相似度矩阵 S ∈ R ∣ c ∣ × ∣ r ∣ S \in \mathbb{R}^{|c| \times |r|} S∈R∣c∣×∣r∣:
S i , j = cos ( e i c , e j r ) = e i c ⋅ e j r ∥ e i c ∥ ⋅ ∥ e j r ∥ S_{i,j} = \cos(e_i^c, e_j^r) = \frac{e_i^c \cdot e_j^r}{\|e_i^c\| \cdot \|e_j^r\|} Si,j=cos(eic,ejr)=∥eic∥⋅∥ejr∥eic⋅ejr
• 矩阵维度:行数为候选词数 ∣ c ∣ |c| ∣c∣,列数为参考词数 ∣ r ∣ |r| ∣r∣。• 物理意义: S i , j S_{i,j} Si,j 表示候选词 w i c w_i^c wic 与参考词 w j r w_j^r wjr 的语义相似度。
-
对齐策略:贪心匹配(Greedy Matching)
为每个候选词找到最相似的参考词,并记录最大相似度:
• 精确率(Precision):候选词对参考的最佳匹配 :
P BS = 1 ∣ c ∣ ∑ i = 1 ∣ c ∣ max j = 1 ∣ r ∣ S i , j P_{\text{BS}} = \frac{1}{|c|} \sum_{i=1}^{|c|} \max_{j=1}^{|r|} S_{i,j} PBS=∣c∣1i=1∑∣c∣j=1max∣r∣Si,j
• 召回率(Recall):参考词对候选的最佳匹配 :
R BS = 1 ∣ r ∣ ∑ j = 1 ∣ r ∣ max i = 1 ∣ c ∣ S i , j R_{\text{BS}} = \frac{1}{|r|} \sum_{j=1}^{|r|} \max_{i=1}^{|c|} S_{i,j} RBS=∣r∣1j=1∑∣r∣i=1max∣c∣Si,j示例:
• 候选:
["dog", "chases", "ball"]• 参考:
["canine", "pursues", "round", "object"]•
dog→canine(相似度0.9),chases→pursues(0.85),ball→object(0.7)• P BS = ( 0.9 + 0.85 + 0.7 ) / 3 ≈ 0.82 P_{\text{BS}} = (0.9 + 0.85 + 0.7)/3 \approx 0.82 PBS=(0.9+0.85+0.7)/3≈0.82
• R BS = ( 0.9 + 0.85 + 0.7 + 0.3 ) / 4 ≈ 0.69 R_{\text{BS}} = (0.9 + 0.85 + 0.7 + 0.3)/4 \approx 0.69 RBS=(0.9+0.85+0.7+0.3)/4≈0.69
-
计算最终F1值
综合精确率和召回率:$ F_{\text{BS}} = 2 \cdot \frac{P_{\text{BS}} \cdot R_{\text{BS}}}{P_{\text{BS}} + R_{\text{BS}}} $
-
-
CLIP Score:基于对比学习预训练的多模态模型CLIP(Contrastive Language–Image Pre-training)设计的评估指标,用于直接衡量图像与文本描述之间的语义对齐程度,无需依赖人工参考文本。
-
其核心思想是利用图文联合嵌入空间的相似性,量化生成文本与目标图像的相关性。
-
公式为 C L I P S c o r e = c o s ( t , i ) ∥ t ∥ ⋅ ∥ i ∥ CLIPScore =\frac{cos (t, i)}{\| t\| \cdot\| i\| } CLIPScore=∥t∥⋅∥i∥cos(t,i) , t t t和 i i i分别是文本和图像的嵌入向量,通过计算它们的余弦相似度得到图像 - 文本的相似程度得分。
CLIPScore摆脱了传统n-gram匹配指标的固有缺陷——此类指标会因标题包含新词而低估优质描述(上图示例),同时过度偏好使用常见词的普通描述(下图示例)。

-
3.3.3 图像质量评估
-
Inception Score(IS):通过分类概率评估图像的多样性和质量。它利用预训练的
Inception模型对图像进行分类,根据分类结果的概率分布来衡量图像数据集的质量和多样性,IS是对生成图片清晰度和多样性的衡量,IS值越大越好。-
Inception Net-V3是图片分类器,在ImageNet数据集上训练。ImageNet是由120多万张图片,1000个类别组成的数据集。Inception Net-V3可以对一副图片输出一个1000分类的概率。 -
其核心思想是:高质量的生成图像应被分类器明确识别为某类,且生成样本需覆盖多样类别。
- GAN量化评估方法——IS(Inception Score)和FID(Frechet Inception Distance score) - 颀周 - 博客园
- 质量:对于单一的生成图像,Inception输出的概率分布熵值应该尽量小。越小说明生成图像越有可能属于某个类别,图像质量高。
- 多样性:对于生成器生成的一批图像而言,Inception输出的平均概率分布熵值应该尽量大。也就是说,因为生成器应该保证生成图像的多样性,因此一批图像在Inception的输出应该尽量平均地“遍历”所有1000维标签。
IS = exp ( E x ∼ p g [ KL ( p ( y ∣ x ) ∥ p ( y ) ) ] ) \text{IS} = \exp\left( \mathbb{E}_{x \sim p_g} \left[ \text{KL} \left( p(y|x) \parallel p(y) \right) \right] \right) IS=exp(Ex∼pg[KL(p(y∣x)∥p(y))])
- E x ∼ p g \mathbb{E}_{x \sim p_g} Ex∼pg:遍历所有的生成样本,求平均值
- p ( y ∣ x ) p(y|x) p(y∣x):预训练分类模型(Inception-v3)对生成图像 x x x的类别预测概率分布;对于给定图片x,表示为一个1000维数向量。
- p ( y ) p(y) p(y):生成图像集的边缘类别分布,即 p ( y ) = 1 N ∑ x p ( y ∣ x ) p(y) = \frac{1}{N} \sum_{x} p(y|x) p(y)=N1∑xp(y∣x)。
- KL ( ⋅ ) \text{KL}(\cdot) KL(⋅):KL散度,衡量条件分布 p ( y ∣ x ) p(y|x) p(y∣x)与边缘分布 p ( y ) p(y) p(y)的差异。
-
特征提取: 使用预训练的Inception-v3模型(在ImageNet上训练)对生成图像进行推理,输出类别概率分布 p ( y ∣ x ) p(y|x) p(y∣x)
-
统计边缘分布: 计算所有生成图像的类别概率均值 p ( y ) = 1 N ∑ x p ( y ∣ x ) p(y) = \frac{1}{N} \sum_{x} p(y|x) p(y)=N1∑xp(y∣x)
-
KL散度计算:
-
对每张图像计算 p ( y ∣ x ) p(y|x) p(y∣x)与 p ( y ) p(y) p(y)的KL散度:
KL ( p ( y ∣ x ) ∥ p ( y ) ) = ∑ k = 1 K p ( y = k ∣ x ) log p ( y = k ∣ x ) p ( y = k ) \text{KL} \left( p(y|x) \parallel p(y) \right) = \sum_{k=1}^K p(y=k|x) \log \frac{p(y=k|x)}{p(y=k)} KL(p(y∣x)∥p(y))=k=1∑Kp(y=k∣x)logp(y=k)p(y=k∣x) -
取所有生成图像的KL散度均值,再取指数得最终IS值。
-
-
-
FID(Fréchet Inception Distance):通过比较真实图像和生成图像的特征分布来评估图像质量,值越小越好。
-
FID使用Inception Net-V3全连接前的2048维向量作为图片的feature
-
其核心思想是:直接考虑生成数据和真实数据在feature层次的距离,不再额外借助分类器
F I D = ∥ μ r − μ g ∥ 2 + t r ( ∑ r + ∑ g − 2 ∑ r ∑ g ) FID=\left\| \mu_{r}-\mu_{g}\right\| ^{2}+tr\left(\sum_{r}+\sum_{g}-2 \sqrt{\sum_{r} \sum_{g}}\right) FID=∥μr−μg∥2+tr r∑+g∑−2r∑g∑
- μ r , μ g \mu_r, \mu_g μr,μg:真实图像和生成图像特征的均值向量。
- Σ r , Σ g \Sigma_r, \Sigma_g Σr,Σg:真实图像和生成图像特征的协方差矩阵。
- Tr \text{Tr} Tr:矩阵的迹(对角线元素之和)。
- 特征提取:使用预训练的Inception-v3模型(去除非必要的分类层),提取图像的特征向量(默认取最后一层池化层输出,维度2048)。
- 统计量计算:分别计算真实图像集和生成图像集特征的均值( μ r , μ g \mu_r, \mu_g μr,μg)和协方差矩阵( Σ r , Σ g \Sigma_r, \Sigma_g Σr,Σg)。
- Fréchet距离计算: 根据公式计算两分布之间的Fréchet距离(即FID值)。
-
3.4 音频评估指标
声音生成结果比较方法综述——FAD、JSD、NDB多种衡量参数-CSDN博客
-
FAD(Fréchet Audio Distance):
-
其核心思想与FID(Fréchet Inception Distance)类似,但专为音频数据设计,捕捉音频信号的高阶语义特征分布差异。
FAD = ∥ μ r − μ g ∥ 2 + Tr ( Σ r + Σ g − 2 ( Σ r Σ g ) 1 / 2 ) \text{FAD} = \|\mu_r - \mu_g\|^2 + \text{Tr}(\Sigma_r + \Sigma_g - 2(\Sigma_r \Sigma_g)^{1/2}) FAD=∥μr−μg∥2+Tr(Σr+Σg−2(ΣrΣg)1/2)
- μ r , μ g \mu_r, \mu_g μr,μg:真实音频和生成音频特征的均值向量。
- Σ r , Σ g \Sigma_r, \Sigma_g Σr,Σg:真实音频和生成音频特征的协方差矩阵。
- Tr \text{Tr} Tr:矩阵的迹(对角线元素之和)。
- 特征提取:使用预训练的音频编码模型(如VGGish或PANNs)提取音频的深度特征。
- VGGish:基于大规模音频数据集(如Audioset)训练的模型,输出128维特征向量。
- PANNs(Pretrained Audio Neural Networks):覆盖更广泛的音频场景,特征维度可变(如2048维)。
- 统计量计算:分别计算真实音频集和生成音频集特征的均值( μ r , μ g \mu_r, \mu_g μr,μg)和协方差矩阵( Σ r , Σ g \Sigma_r, \Sigma_g Σr,Σg)。
- Fréchet距离计算: 根据公式计算两分布之间的Fréchet距离(即FAD值)。

-
四、关键创新点与方法

本文PDF版本笔记可通过链接直接下载
CSDN博文篇幅受限,故于PDF版本笔记中补充了第四章的相关整理;
建议直接下载PDF版本笔记,已设置永久免费下载
下方为PDF版本笔记第四章部分截图
五、多模态RAG应用场景
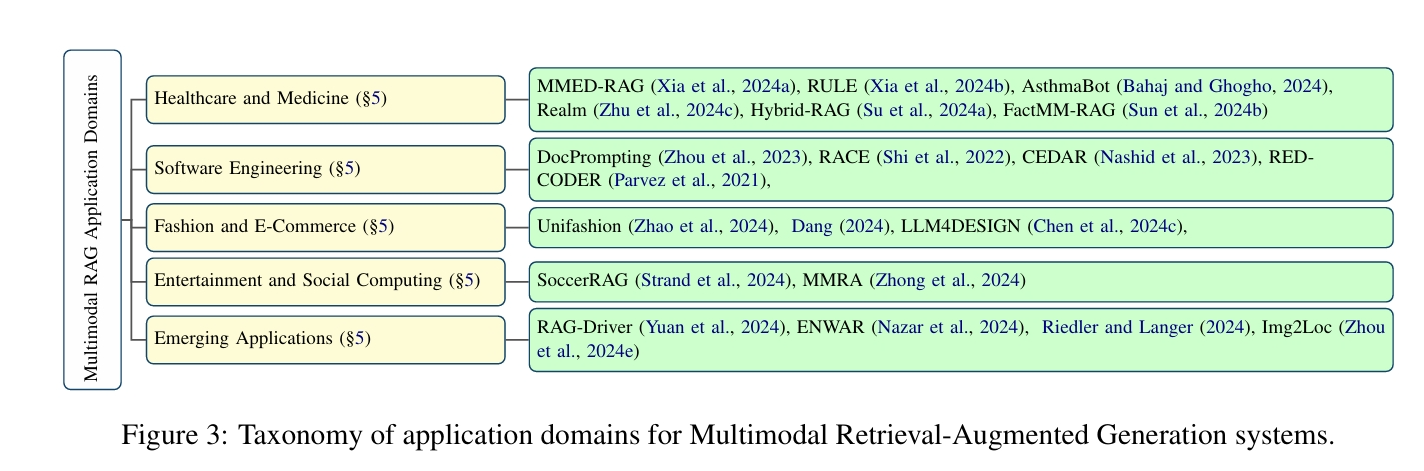
多模态检索增强生成(RAG)系统将传统RAG扩展至需要跨模态整合的任务,提升文本、图像、音频等多模态场景的性能。其应用主要体现在以下领域:
-
内容生成
- 通过检索相关上下文信息,提升图像标注和文本到图像合成质量。
- 增强视觉叙事的连贯性,确保多模态摘要的事实一致性。
-
知识密集型任务
- 支持开放域问答与知识型问答
- 实现基于视频的问答
- 通过检索知识进行事实核查,减少生成内容的幻觉问题。
-
跨模态检索创新
- 推进零样本图文检索
- 结合链式思维推理增强复杂问题解决能力
-
交互式系统整合
- 集成到Gemini等交互代理中,实现:
- 自然语言驱动的视觉搜索
- 文档理解与多模态推理
- 集成到Gemini等交互代理中,实现:
5.1 医疗领域
🩺 Healthcare and Medicine
- MMed-RAG: Versatile Multimodal RAG System for Medical Vision Language Models
- RULE: Reliable Multimodal RAG for Factuality in Medical Vision Language Models
- AsthmaBot: Multi-modal, Multi-Lingual Retrieval Augmented Generation For Asthma Patient Support
- REALM: RAG-Driven Enhancement of Multimodal Electronic Health Records Analysis via Large Language Models
- Hybrid RAG-Empowered Multi-Modal LLM for Secure Data Management in Internet of Medical Things: A Diffusion-Based Contract Approach
- Fact-aware multimodal retrieval augmentation for accurate medical radiology report generation
多模态RAG通过整合医学影像、电子健康记录和生物医学文献的分析,提升临床决策能力。具体应用如下:
-
诊断支持系统
- MMED-RAG(多模态医学检索增强生成模型)通过对齐放射影像与患者上下文数据,解决医学视觉问答中的诊断不确定性。
- RULE通过动态检索临床相似病例,减少自动报告生成中的幻觉问题。
-
多语言患者支持
- AsthmaBot采用多模态RAG方法,支持多语言哮喘患者的结构化语义搜索。
-
预测与隐私保护
- Realm通过融合异构患者数据流实现稳健的风险评估。
- 混合RAG推进联邦临床数据集成的隐私保护架构。
-
自动化报告生成
- FactMM-RAG通过检索医学本体中的生物标志物关联,实现放射学报告的自动化撰写,展现了规模化应用专家知识的能力。
5.2 软件工程领域
💻 Software Engineering
代码生成系统利用多模态RAG从技术文档和版本历史中合成上下文感知的解决方案。具体创新包括:
-
代码补全优化
- DocPrompting通过检索API规范和调试模式,提升代码补全的语义连贯性。
-
提交消息生成
- RACE将代码差异与历史仓库活动关联,生成上下文相关的提交说明。
-
少样本学习增强
- CEDAR(Nashid等,2023)通过基于检索的提示工程优化少样本代码生成。
-
代码摘要改进
- REDCODER(Parvez等,2021)通过开源仓库的语义搜索增强代码摘要生成,同时保留跨编程范式的语法规范。
5.3 时尚与电子商务领域
🕶️ Fashion and E-Commerce
跨模态对齐技术推动产品发现与设计自动化的进步:
- UniFashion通过联合嵌入服装图像和文本描述符实现风格感知检索。
- Dang通过多模态查询扩展减少搜索摩擦。
- LLM4DESIGN通过检索合规约束和环境影响评估实现建筑设计自动化,凸显了 RAG 在创意领域的适应性。
5.4 娱乐与社交计算领域
🤹 Entertainment and Social Computing
多媒体分析受益于 RAG 关联异构信号的能力:
- SoccerRAG 通过将比赛录像与球员统计数据关联,推导战术见解
- MMRA 通过联合建模视觉美学与语言参与模式,预测内容的病毒性传播潜力。
5.5 新兴应用领域
🚗 Emerging Applications
- RAG-Driver: Generalisable Driving Explanations with Retrieval-Augmented In-Context Learning in Multi-Modal Large Language Model
- ENWAR: A RAG-empowered Multi-Modal LLM Framework for Wireless Environment Perception
- Beyond Text: Optimizing RAG with Multimodal Inputs for Industrial Applications
- Img2Loc: Revisiting image geolocalization using multi-modality foundation models and image-based retrieval-augmented generation
-
自主系统
- RAG-Driver通过多模态RAG实现可解释决策:
- 在导航过程中实时检索交通场景
- 支持动态路径规划与风险评估
- RAG-Driver通过多模态RAG实现可解释决策:
-
无线网络优化
- ENWAR通过多传感器融合增强网络弹性:
- 整合异构网络数据
- 提升抗干扰能力与故障恢复效率
- ENWAR通过多传感器融合增强网络弹性:
-
设备维护智能化
- Riedler和Langer提出检索增强维护系统:
- 故障诊断时实时检索设备示意图
- 优化维修流程与资源分配
- Riedler和Langer提出检索增强维护系统:
-
地理空间技术
- Img2Loc推进图像地理定位:
- 基于跨模态地标关联
- 实现高精度场景识别与位置标注
- Img2Loc推进图像地理定位:
六、开放问题与未来方向
6.1 泛化性、可解释性和鲁棒性
-
领域适应与模态偏差 多模态RAG系统在跨领域迁移时存在困难,且常表现出模态偏见(如过度依赖文本进行检索与生成)。
-
可解释性挑战 系统难以将答案精确归因于具体模态来源,当前方法仅能标注完整文档或大段视觉区域,而非定位图像/语音中触发答案的具体部分。
-
模态交互影响与鲁棒性不足
- 单模态(如纯文本)与多模态输入的答案质量存在差异
- 易受对抗性扰动(如误导性图像干扰文本输出)
- 依赖低质量/过时信息源时性能显著下降
- 单模态RAG可信度已有研究,但多模态系统鲁棒性仍需突破
6.2 推理、对齐和检索增强
-
组合推理挑战
- 多模态RAG难以实现跨模态逻辑整合,需通过组合推理生成连贯输出
- 现有技术(如Multimodal-CoT)仍需改进以提升输出的上下文相关性
-
模态对齐与检索优化
- 需增强实体感知检索能力,提升跨模态对齐精度
- 知识图谱在多模态RAG中的应用尚未充分探索,其潜力有待挖掘
-
检索偏差问题
- 存在位置敏感性、冗余检索及数据/内容偏差等挑战
- 开发统一模态嵌入空间是关键方向,可避免中间转换模型(如ASR)的依赖
6.3 Agent-Based and Self-Guided Systems
-
动态反馈机制需求
- 未来多模态RAG需整合交互式反馈与自引导决策,实现输出迭代优化
- 现有反馈机制难以准确定位错误来源(检索/生成/其他阶段)
-
强化学习与人类对齐反馈
- 强化学习与端到端人类对齐反馈的整合尚未探索,但潜力巨大
- 可实现检索必要性评估、内容相关性判断及模态动态选择
-
任意模态支持与具身智能方向
- 需支持任意模态间转换以适应开放任务
- 整合环境传感器等真实世界数据源,提升情境感知能力
- 结合物理交互与检索推理,推动系统向通用人工智能(AGI)发展
6.4 长上下文处理、效率、可扩展性和个性化
-
长上下文处理挑战
- 视频帧采样计算成本高,多页图文文档处理存在内存瓶颈
- 固定帧提取率难以捕捉动态内容,需基于复杂度/运动自适应选择
-
效率与可扩展性需求
- 边缘部署中检索速度与准确性的权衡问题
- 跨模态融合层存在冗余计算,需高效可扩展架构
-
个性化机制探索
- 用户特定上下文(如医疗史)适配检索的个性化机制尚未充分研究
- 个性化需平衡隐私保护与敏感数据泄漏风险
-
数据集局限性
- 缺乏包含复杂推理任务的多模态对抗性示例数据集
- 限制系统鲁棒性评估能力

















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









