






简单说点
- 数据来源:kaggle数据来源
- 工具:Sql、Navicat Premium15
本次项目所采用的数据集比较小,共1000条,数据比较干净,而且数据波动不大,怀疑数据被预处理过,所以直接选用Sql进行简单的数据分析,可视化比较少。
一、数据处理
根据从kaggle获取的数据源,对数据进行简单的数据处理,便于后续的数据分析。
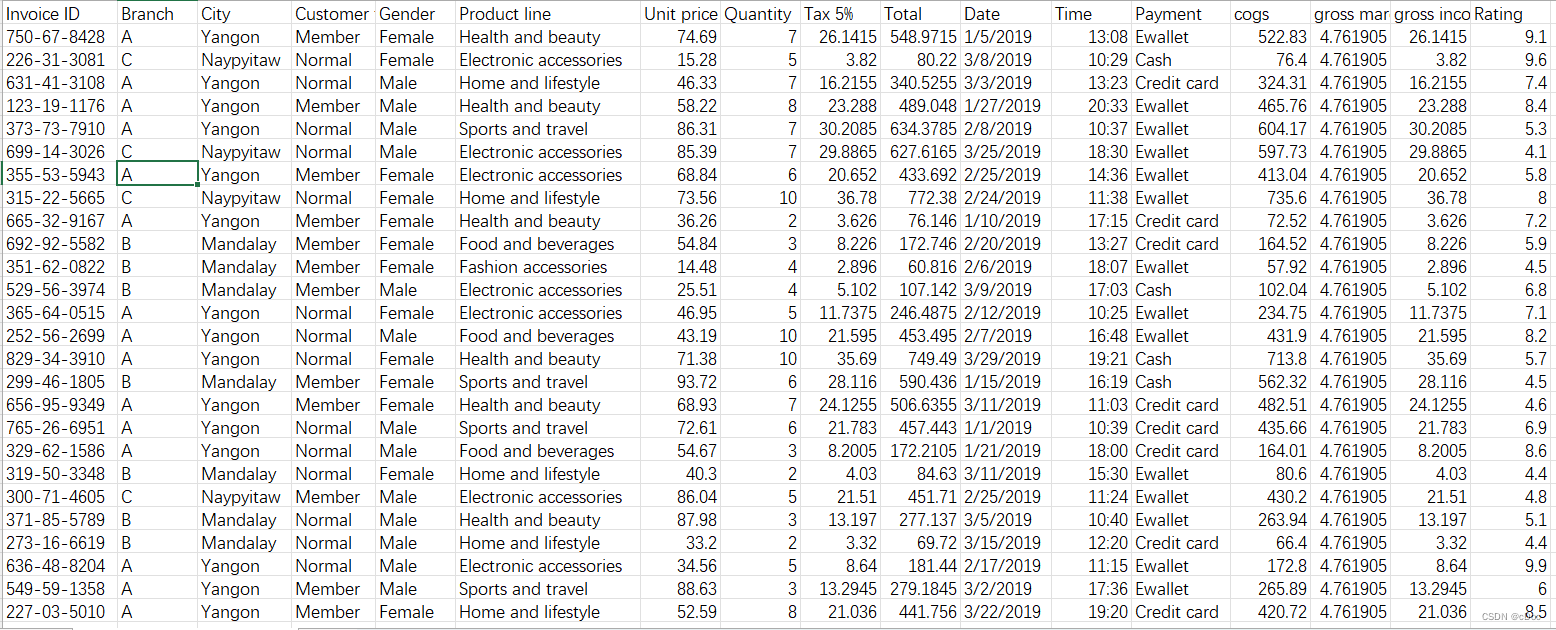
源数据如下
首先,修改表格数据类型,便于后续计算
源数据日期类型是“月/日/年 如:5/18/2019”,个人认为有点难理解,使用STR_TO_DATE函数将其转化为“年-月-日”的日期类型,一并设置主键以及将金额相关的设置为NUMERIC数据类型。
-- 设置主键
ALTER TABLE supermarket_sales_data MODIFY invoice_id VARCHAR ( 255 ) PRIMARY KEY;
-- 设置其他时间数据类型【注意分隔符】
-- 时间类型
UPDATE supermarket_sales_data set buy_date = STR_TO_DATE(buy_date,'%m/%d/%Y');
UPDATE supermarket_sales_data set buy_Time = STR_TO_DATE(buy_Time,"%H:%i");
-- 设置numeric数据类型
ALTER TABLE supermarket_sales_data MODIFY Unit_price NUMERIC (12,2),
MODIFY `Tax_5%` NUMERIC (12,2),MODIFY Total NUMERIC(12,2),
MODIFY cogs NUMERIC (12,2),MODIFY gross_income NUMERIC (12,2),
MODIFY gross_margin_percentage NUMERIC (12,2);
其次,剔除空值、重复值等垃圾数据。
这里采取一种新的思路,如果数据字段较多,一个一个字段重复的检查会比较繁琐,所以利用源数据重新创建一张无空值和重复值的数据表。
-- 删除空值【这里只检测Total,因为源数据无空值】
INSERT INTO supermarket_sales_data(invoice_id) VALUES("555");
DELETE FROM supermarket_sales_data AS s WHERE Total is null;
-- 删除重复值【这里采用新思路,直接创建一个无重复值的新表,空值也可以,如果字段太多】
CREATE TABLE supermarket_perfect_data ( SELECT DISTINCT * FROM supermarket_sales_data )
最后,检查有无其他垃圾数据
因为该数据是2019年第一季度的销售数据,所以排除其他无关数据。
-- 筛选无关数据
SELECT *
FROM supermarket_sales_data
WHERE buy_Date NOT BETWEEN "2019-01-01" AND "2019-04-01"
二、数据分析
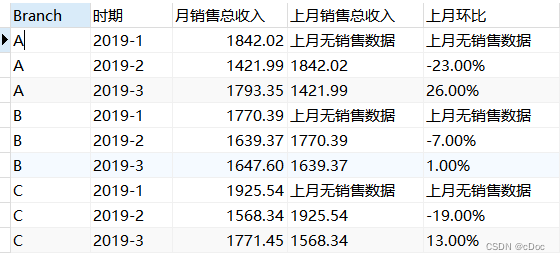
1.计算不同商店月环比
*月环比公式:(本月营收-上月营收)/ 上月营收 100%
使用with as 语句简化sql子查询,并用round函数保留两位小数,最后用concat函数将数值和“%”连接。这样做又有一个缺点,就是数据类型变了。
注意:需要判断这个月是不是1月以及上个月是否有数据,因为环比是跟上个月数据作比较,今年1月的上一个月就是去年的12月,如果上个月没数据的话,那除数就是0,会出错
-- 月环比计算
-- 1.计算月收入
WITH monthIncome AS
(
SELECT Branch,YEAR(buy_Date) AS 年份,MONTH(buy_Date) AS 月份,SUM(gross_income) AS 月销售总收入
FROM supermarket_sales_data
GROUP BY Branch,MONTH(buy_Date)
ORDER BY Branch
)
-- 2.分别计算不同品牌的月环比
SELECT t1.Branch,CONCAT(t1.年份,"-",t1.月份) AS 时期,t1.月销售总收入,
(CASE
WHEN t2.月销售总收入 IS NULL THEN "上月无销售数据"
ELSE t2.月销售总收入
END) AS 上月销售总收入,
(CASE
WHEN t2.月销售总收入 IS NULL THEN "上月无销售数据"
ELSE
CONCAT(ROUND((t1.月销售总收入 - t2.月销售总收入)/t2.月销售总收入,2)*100,"%")
END) AS 上月环比
FROM monthIncome as t1 LEFT JOIN monthIncome AS t2 on (t1.Branch = t2.Branch)
AND ((t1.月份 - t2.月份 = 1 AND t1.年份 = t2.年份) OR (t1.月份 = 1 AND t2.月份 = 12 AND t1.年份 = t2.年份 +1))
2.购物高峰期和各个超市的季度利润
-- 购物高峰期
SELECT HOUR(buy_Time) AS 时间,COUNT(*) AS 进店人数
FROM supermarket_sales_data
GROUP BY HOUR(buy_Time)
ORDER BY 进店人数 DESC
-- 计算各个超市的利润
SELECT City,SUM(Total - cogs) as profit
FROM supermarket_sales_data
GROUP BY City
ORDER BY profit;
3.会员人数及热销商品
-- 会员人数
SELECT Customer_type,count(*) 人数
FROM supermarket_sales_data
GROUP BY Customer_type
-- 热销商品
SELECT Product_line,count(*) AS 销售数量
FROM supermarket_sales_data
GROUP BY Product_line
ORDER BY 销售数量 DESC
4.不同支付方式
-- 不同超市支付方式占比
-- 获取不同超市名称及所消费人数
WITH cntAll AS (
SELECT Branch,COUNT(*) AS cnt
FROM supermarket_sales_data
GROUP BY Branch
),
-- 获取不同支付方式的人数
cntOwn AS(
SELECT sp.Branch AS 品牌,Payment AS 支付方式,COUNT(*) AS 本商店计数,cnt
FROM supermarket_sales_data AS sp JOIN cntAll ON sp.Branch = cntAll.Branch
GROUP BY sp.Branch,Payment
ORDER BY sp.Branch
)
-- 计算占比
SELECT 品牌,支付方式,本商店计数,CONCAT(ROUND(本商店计数/cnt,2)*100,"%") AS 本店占比
FROM cntOwn
三、可视化
由于这个数据非常简单,并且数据量较少,我直接使用了Navicat Premium进行简单的可视化分析

从上图可以看出,每个分店的进店支付人数相对均衡,可以说明该超市受众群体大致相同

从上品牌营收额图表也可以看出各个不同品牌之间的营收额差距并不大,可以看出该超市的各个产品都受人喜爱,或者是产品类较少等其他原因,购买的人较少,因为营收额都不高

从上营收额数据表可以看出,三个不同城市的超市分店营收额大致相同但是相对来说,营收额偏低。
总结
我们使用了Sql对从kaggle获取的数据进行分析,在分析过程中及以上图表,大家可以看出该超市的不同分店各个方面都相对均衡,包括进店消费人数、评分、会员等情况,并且营收额都不算太高,我们可以猜测,该超市的规模不算太大,且受众群体变化不大,一般以老顾客为主,收入比较稳定;也可以间接推断出该超市所在城市较小,人员流动较少。 还有一种可能是该数据被人修改过,并不是源数据。

















 957
957

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









