







 本文介绍了如何利用Python的pyecharts库,从豆瓣TOP250电影数据中提取导演与演员的关联关系,并生成关系图的json文件。首先,对数据进行预处理,包括清洗、合并和去重。接着,生成json数据,包括节点和边的信息。然后,将数据转换为json格式,并绘制关系图。最后,展示了生成的关系图HTML页面,呈现了中国电影导演与演员的网络关系。
本文介绍了如何利用Python的pyecharts库,从豆瓣TOP250电影数据中提取导演与演员的关联关系,并生成关系图的json文件。首先,对数据进行预处理,包括清洗、合并和去重。接着,生成json数据,包括节点和边的信息。然后,将数据转换为json格式,并绘制关系图。最后,展示了生成的关系图HTML页面,呈现了中国电影导演与演员的网络关系。
前言
帮别人做了一个小作业,需要根据豆瓣TOP250的电影信息,提取需要人物关联关系,并生成节点链接网格图绘制需要的json文件,用关系图描述导演和演员的联系。
其中,节点大小编码映射该节点与其他人物链接关系次数
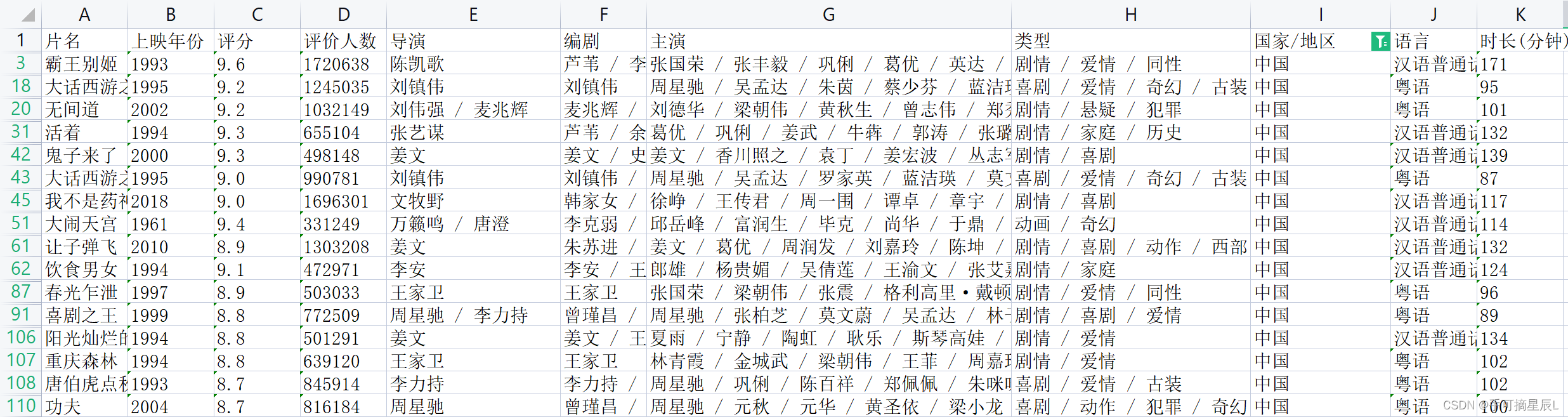
数据集样式:
TOP250电影数据包含字段:片名、上映年份、评分、评价人数、导演、编剧、主演、类型、国家/地区、时长等

一、pyecharts是什么?
Echarts是一个由百度开源的数据可视化工具,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而python是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上了数据可视化时,pyecharts诞生了。
pyecharts官网:https://pyecharts.org/#/zh-cn/intro
安装:pip install pyecharts
二、操作步骤
所有电影数据全部绘制出来,可能数据量比较大,先在原表格筛选出中国的数据,所以这里先绘制“中国”的电影导演人物关联关系。
1.导入包
import pandas as pd
import json
import random
from pyecharts import options as opts
from pyecharts.charts import Graph
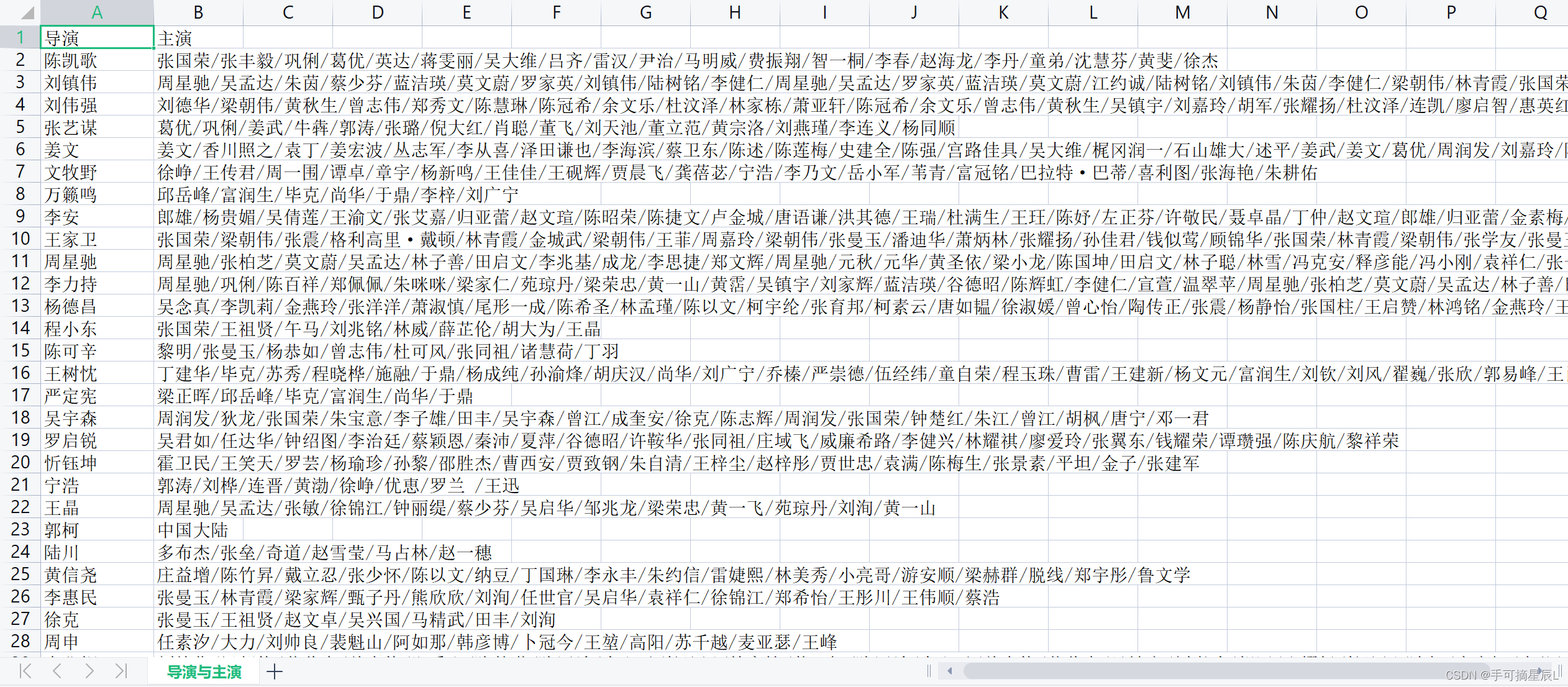
2.数据预处理
1、如《霸王别姬》主演数据信息:张国荣 / 张丰毅 / 巩俐 / 葛优 / 英达 / 蒋雯丽 / 吴大维 / 吕齐 / 雷汉 / 尹治 / 马明威 / 费振翔 / 智一桐 / 李春 / 赵海龙 / 李丹 / 童弟 / 沈慧芬 / 黄斐 / 徐杰
‘/’前后都带了空格,需要把前后空格替换
2、以‘/’为分隔符,把多个导演的分隔开,设置成“第一导演”“第二导演”…
3、同一主演可能出演了另一部电影,所以需要合并去重
4、最后生成一个新的表格,一个导演对应所有的主演
代码如下:
df['导演'] = df['导演'].str.replace(' / ', '/')
df['主演'] = df['主演'].str.replace(' / ', '/')
df=df[['导演','主演']]
three_dy=pd.DataFrame((x.split('/') for x in df['导演']),index=df.index,columns=['第一导演','第二导演','第三导演'])
new=pd.merge(df,three_dy,left_index=True,right_index=True)
new=new.drop(columns = ['导演'])
dy1=new[['第一导演','主演']]
dy1.rename(columns={
'第一导演':'导演'}, inplace = True)
dy2=new[['第二导演','主演']]
dy2.rename(columns={
'第二导演':'导演'}, inplace = True)
dy2=dy2.dropna()
dy3=new[['第三导演','主演']]
dy3.rename(columns={
'第三导演':'导演'}, inplace = True)
dy3=dy3.dropna()
one_dy=pd.concat([dy1,dy2],axis=0,join='outer')
one_dy=pd.concat([one_dy,dy3],axis= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









