






在机器学习的过程中,我们难免会遇到多重共线性的问题;
目录
多重共线性是什么
就是当我们进行线性回归的时候,经常会出现自变量彼此相关的情况,就是当一个发生变化的时候,另一个也会受到影响,结果就是无法找到x和y之间真正关系,使得模型估计失真或难以估计准确。
如何查看多重共线性
利用相关系数矩阵和VIF
1)相关性分析
a、相关系数:相关系数是度量两个变量之间的线性关系的统计量
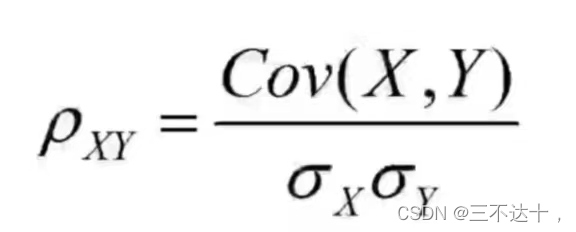
b、相关矩阵:对称阵,

代码示例
plt.figure(figsize=(20,16))#矩阵大小
mask = np.zeros_like(mcorr, dtype = np.bool)#只显示对角矩阵的一部分
g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt='0.2f')#图行绘制
2)检验VIF(方差膨胀因子)
VIF是一个决定变量是否具有多重共线性的数值,代表一个变量与其他变量线性相关而被夸大的程度
VIF=I/(I-R*R)
reg y x1 x2 x3 x4...
estat vif
如果VIF>10则认为可能存在多重共线性问题
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factorX = df[list(df.columns[:-2])]
vif_info = pd.DataFrame()
vif_info['VIF'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif_info['Column'] = X.columns
vif_info.sort_values('VIF', ascending=False)
如何处理多重共线性
1、最直观的方法就是将多重共线性的特征删除就可以了,先做相关分析,如果发现某两个自变量的相关系数值大于0.7,则移除掉一个自变量,在做回归分析。
2、增加样本容量。
3、利用逐步回归法让系统自动进行自变量的剔除,但可能算法会剔除掉本不想剔除的自变量,所以最好使用岭回归进行分析。
4、主成分分析:就是一种降维的操作,在面对数量较大的时候可以在降低维度的同时保留尽量多的信息,就是将将多维特征投影到较少维度的轴上,这样形成新的特征之间一定是相互独立的,而独立的特征之间不存在多重共线性。















 3243
3243











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









