




前言
三年硕士一场空,电子厂里当劳工
直方图均衡化概念
直方图是反映图像像素分布的统计表,类似于小学数学学的统计图。横坐标代表像素值的取值区间,纵坐标代表每一像素值在图像中的像素总数或者所占的百分比。
直方图均衡化是将原始图像通过函数变换,调控图像的灰度分布,得到直方图分布合理的新图像,以此来调节图像亮度、增强动态范围偏小的图像的对比度。
直方图均衡化是一种简单有效的图像增强技术。根据直方图的形态可以判断图像的质量,在工程中用以改善图像的亮度和对比度。
直方图均衡化目的
将图像中原本分布集中的像素值,均衡的分布到所有可取值的范围,这样,图像的对比度和亮度就得到了改善。也就是说通过直方图均衡化对图像进行非线性拉伸,重新分配图像像素值,本质上是根据直方图对图像进行线性或非线性灰度变换。
直方图均衡化思路
占比大的灰度级进行展宽,占比小的灰度级进行压缩,使图像的直方图分布较为均匀,扩大灰度值差别的动态范围,从而增强图像整体的对比度。
Python实现代码
import cv2
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams["font.sans-serif"]=["SimHei"]
mpl.rcParams["axes.unicode_minus"]=False
img = cv2.imread(r'bird1.png', cv2.IMREAD_GRAYSCALE)
equ = cv2.equalizeHist(img)
plt.figure("原图")
plt.hist(img.ravel(), 256)
plt.figure("直方图均衡化")
plt.hist(equ.ravel(), 256)
plt.show()
cv2.imshow('原图', img)
cv2.imshow('直方图均衡化', equ)
plt.show()
cv2.waitKey(0)
FPGA实现思路
整体思路分为以下五步:
1、RGB 转 YUV
2、图像灰度统计
3、图像像素累加
4、图像灰度归一化计算
5、YUV 转 RGB
门级网表如下:
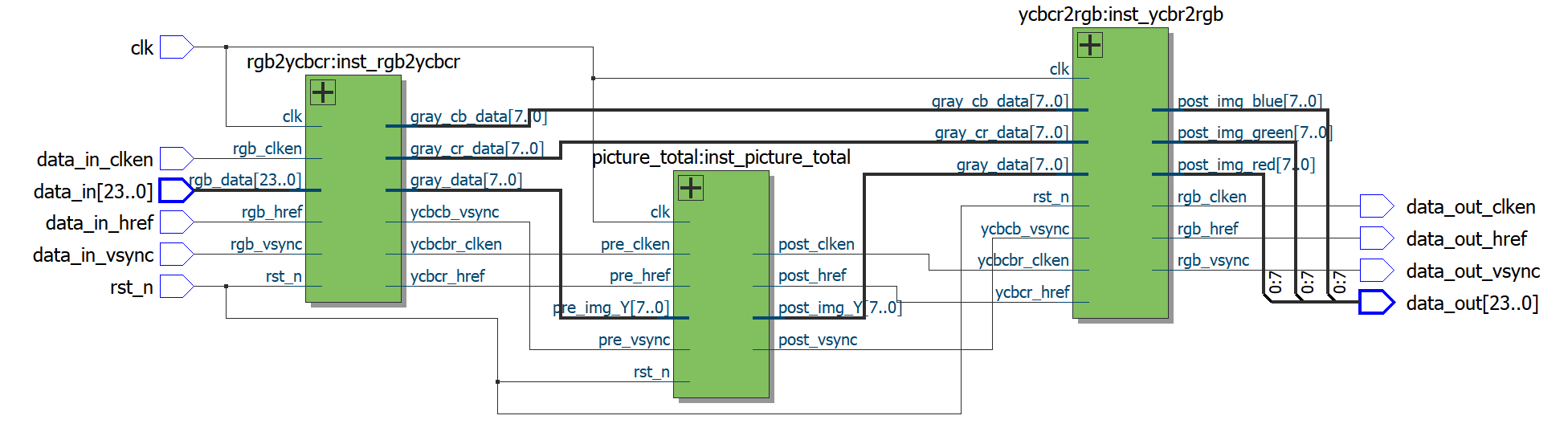
其中picture_total负责其中2、3、4步骤,也就是图像均衡化部分
代码实现
RGB888 to YCbCr
转换公式:
Y= (77 R + 150G + 29 B)>>8
Cb= (-43R- 85 G+128B+32768)>>8
Cr= (128R-107G-21 *B+32768)>>8
这样计算避免了在FPGA中进行乘除运算
代码如下:
//step1 计算括号内的各乘法项
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
rgb_r_m0 <= 16'd0;
rgb_r_m1 <= 16'd0;
rgb_r_m2 <= 16'd0;
rgb_g_m0 <= 16'd0;
rgb_g_m1 <= 16'd0;
rgb_g_m2 <= 16'd0;
rgb_b_m0 <= 16'd0;
rgb_b_m1 <= 16'd0;
rgb_b_m2 <= 16'd0;
end
else begin
rgb_r_m0 <= rgb888_r * 8'd77 ;
rgb_r_m1 <= rgb888_r * 8'd43 ;
rgb_r_m2 <= rgb888_r * 8'd128;
rgb_g_m0 <= rgb888_g * 8'd150;
rgb_g_m1 <= rgb888_g * 8'd85 ;
rgb_g_m2 <= rgb888_g * 8'd107;
rgb_b_m0 <= rgb888_b * 8'd29 ;
rgb_b_m1 <= rgb888_b * 8'd128;
rgb_b_m2 <= rgb888_b * 8'd21 ;
end
end
//step2 括号内各项相加
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
img_y0 <= 16'd0;
img_cb0 <= 16'd0;
img_cr0 <= 16'd0;
end
else begin
img_y0 <= rgb_r_m0 + rgb_g_m0 + rgb_b_m0;
img_cb0 <= rgb_b_m1 - rgb_r_m1 - rgb_g_m1 + 16'd32768;
img_cr0 <= rgb_r_m2 - rgb_g_m2 - rgb_b_m2 + 16'd32768;
end
end
//step3 括号内计算的数据右移8位
always @(posedge clk or negedge rst_n) begin
if(!rst_n) begin
img_y1 <= 8'd0;
img_cb1 <= 8'd0;
img_cr1 <= 8'd0;
end
else begin
img_y1 <= img_y0 [15:8];
img_cb1 <= img_cb0[15:8];
img_cr1 <= img_cr0[15:8];
end
end
//延时3拍以同步数据信号
always@(posedge clk or negedge rst_n) begin
if(!rst_n) begin
rgb_vsync_d <= 3'd0;
rgb_clken_d <= 3'd0;
rgb_href_d <= 3'd0;
end
else begin
rgb_vsync_d <= {rgb_vsync_d[1:0], rgb_vsync};
rgb_clken_d <= {rgb_clken_d[1:0], rgb_clken};
rgb_href_d <= {rgb_href_d[1:0] , rgb_href };
end
end
直方图均衡化

H(i)为第 i 级灰度的像素个数,A0为图像的面积(即分辨率或者说是像素的总数),Dmax为灰度最大值,即255。
从上述公式可以看出,首先需要统计像素总数和计算均衡输出,都要进行写和读,用一个RAM又写又读满足不了要求,因此我们使用双端口RAM,一个口只读不写,另一个口只写不读。
在直方图像素统计的时候,在帧同步信号为高时,统计直方图数据;在帧同步信号为低时,输出直方图数据;
在直方图均衡化的时候,将上一步读出的数据进行累加均衡,根据像素点灰度值对应的地址,写入RAM2中;在延时四个周期后读出。
部分代码如下:
1、信号说明
//信号说明
// ram1读地址总线
wire [7:0] rd_addr_bus;
// ram1读数据
wire [31:0] rd_data;
// ram1写使能总线
wire wren_bus;
// ram1写地址总线
wire [7:0] wr_addr_bus;
// ram1写数据总线
wire [31:0] wr_data_bus;
// 输入灰度打一拍
reg [7:0] pre_img_Y_r;
// 数据有效打一拍
reg pre_clken_r;
// pre_vsync打一拍检测下降沿
reg pre_vsync_r;
// 读出直方图地址计数器
reg [7:0] rd_addr_cnt;
// 读出直方图地址计数器使能
reg rd_addr_cnt_en;
// 计数器使能打4拍,ram1读出数据需要1时钟周期,第一拍用于累加的使能,累加消耗1时钟周期,乘除消耗2时钟周期
reg [3:0] cnt_en_lag4;
// 计数器打4拍作为ram2的写入地址
reg [7:0] rd_addr_cnt_r1;
reg [7:0] rd_addr_cnt_r2;
reg [7:0] rd_addr_cnt_r3;
reg [7:0] rd_addr_cnt_r4;
// 直方图累加和
reg [31:0] sum;
// 直方图累加和 * 255
reg [31:0] sum_x_255;
// 累加 * 255 / 307200,图像分辨率为640*480=307200
reg [7:0] sum_x_255_div_307200;
reg [7:0] cnt_delay;
// vsync高电平期间ram1统计直方图,低电平期间读出ram1直方图,并清零
assign rd_addr_bus = pre_vsync ? pre_img_Y : rd_addr_cnt; //读地址
assign wren_bus = pre_vsync ? pre_clken_r : cnt_en_lag4[0]; //写使能
assign wr_addr_bus = pre_vsync ? pre_img_Y_r : cnt_delay;//写地址
assign wr_data_bus = pre_vsync ? (rd_data + 1) : 8'd0;//写数据
2、第一个RAM 进行数据统计
blk_mem_gen_0 RAM1_8x256 (
//A端口只读不写
.clock(clk), // input wire clka
.wren_a(1'b0), // input wire [0 : 0] wea A端口写使能无效
.address_a(rd_addr_bus), // input wire [7 : 0] addra 输入图像像素作为地址
.data_a(0), // input wire [31 : 0] dina A端口只读不写
.q_a(rd_data), // output wire [31 : 0] douta A端口读出的数据保存到Cnt中
// B端口只写不读
.wren_b(wren_bus), // input wire [0 : 0] web
.address_b(wr_addr_bus), // input wire [7 : 0] addrb
.data_b(wr_data_bus), // input wire [31 : 0] dinb
.q_b() // output wire [31 : 0] doutb
);
3、累加均衡
// 计数器使能打4拍,读出数据消耗一时钟周期,累加、乘、除消耗三时钟周期
always @(posedge clk, negedge rst_n) begin
if(!rst_n)
cnt_en_lag4 <= 0;
else
cnt_en_lag4 <= {cnt_en_lag4[2:0], rd_addr_cnt_en};
end
// 直方图累加,消耗一时钟周期
always @(posedge clk, negedge rst_n) begin
if(!rst_n)
sum <= 0;
else if(cnt_en_lag4[0])// 计数器使能打一拍用于累加,因为读出数据延迟一时钟周期
sum <= sum + rd_data;
else
sum <= 0;
end
// 累加 * 255,即sum * 256 - sum,消耗一时钟周期
always @(posedge clk, negedge rst_n) begin
if(!rst_n)
sum_x_255 <= 0;
else
sum_x_255 <= (sum << 8) - sum;
end
// 累加 * 255 / 307200,消耗一时钟周期
always @(posedge clk, negedge rst_n) begin
if(!rst_n)
sum_x_255_div_307200 <= 0;
else
sum_x_255_div_307200 <= sum_x_255 / 307200;
end
这里其实写的不太好,在FPGA中尽量避免乘除运算,我这里直接写了个乘法,其实可以:
图像分辨率640*480,为避免乘除法采用640*512来处理
[(2^5+2^4)+(2^2+2^1)] / 2^16, 为优化时序用流水线花2拍处理
4、第二个RAM
blk_mem_gen_0 inst_ram_8x256 (
//A端口只读不写
.clock(clk), // input wire clka
.wren_a(1'b0), // input wire [0 : 0] wea A端口写使能无效
.address_a(pre_img_Y), // input wire [7 : 0] addra 输入图像像素作为地址
.data_a(0), // input wire [31 : 0] dina A端口只读不写
.q_a(post_img_Y), // output wire [31 : 0] douta A端口读出的数据保存到Cnt中
// B端口只写不读
.wren_b(cnt_en_lag4[3]), // input wire [0 : 0] web
.address_b(rd_addr_cnt_r4), // input wire [7 : 0] addrb
.data_b(sum_x_255_div_307200), // input wire [31 : 0] dinb
.q_b() // output wire [31 : 0] doutb
);
YUV转RGB
module ycbcr2rgb
(
//module clock
input clk , // 模块驱动时钟
input rst_n , // 复位信号
//图像处理前的数据接口
input ycbcb_vsync , // vsync信号
input ycbcbr_clken , // 时钟使能信号
input ycbcr_href , // 数据有效信号
input [7:0] gray_data, // 输出图像Y数据
input [7:0] gray_cb_data, // 输出图像cb数据
input [7:0] gray_cr_data, // 输出图像cr数据
//图像处理后的数据接口
output rgb_vsync , // vsync信号
output rgb_clken , // 时钟使能信号
output rgb_href , // 数据有效信号
output [7:0] post_img_red , // 输入图像数据RGB
output [7:0] post_img_green ,
output [7:0] post_img_blue
);
reg [19:0] gray_data_r1;
reg [19:0] gray_cb_data_r1,gray_cb_data_r2;
reg [19:0] gray_cr_data_r1,gray_cr_data_r2;
//放大512倍
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
gray_data_r1 <= 0;
gray_cb_data_r1 <= 0; gray_cb_data_r2 <= 0;
gray_cr_data_r1 <= 0; gray_cr_data_r2 <= 0;
end
else
begin
gray_data_r1 <= gray_data * 18'd596;
gray_cb_data_r1 <= gray_cb_data * 18'd200;
gray_cb_data_r2 <= gray_cb_data * 18'd1033;
gray_cr_data_r1 <= gray_cr_data * 18'd817;
gray_cr_data_r2 <= gray_cr_data * 18'd416;
end
end
//右移9位
reg [19:0] XOUT;
reg [19:0] YOUT;
reg [19:0] ZOUT;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
XOUT <= 0;
YOUT <= 0;
ZOUT <= 0;
end
else
begin
XOUT <= (gray_data_r1 + gray_cr_data_r1 - 20'd114131)>>9;
YOUT <= (gray_data_r1 - gray_cb_data_r1 - gray_cr_data_r2 + 20'd69370)>>9;
ZOUT <= (gray_data_r1 + gray_cb_data_r2 - 20'd141787)>>9;
end
end
//像素值>0判断
reg [7:0] R, G, B;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
R <= 0;
G <= 0;
B <= 0;
end
else
begin
R <= XOUT[10] ? 8'd0 : (XOUT[9:0] > 9'd255) ? 8'd255 : XOUT[7:0];
G <= YOUT[10] ? 8'd0 : (YOUT[9:0] > 9'd255) ? 8'd255 : YOUT[7:0];
B <= ZOUT[10] ? 8'd0 : (ZOUT[9:0] > 9'd255) ? 8'd255 : ZOUT[7:0];
end
end
//计算 右移 判断 三个时钟延迟
reg [2:0] post_frame_vsync_r;
reg [2:0] post_frame_href_r;
reg [2:0] post_frame_clken_r;
always@(posedge clk or negedge rst_n)
begin
if(!rst_n)
begin
post_frame_vsync_r <= 0;
post_frame_href_r <= 0;
post_frame_clken_r <= 0;
end
else
begin
post_frame_vsync_r <= {post_frame_vsync_r[1:0], ycbcb_vsync};
post_frame_href_r <= {post_frame_href_r[1:0], ycbcr_href};
post_frame_clken_r <= {post_frame_clken_r[1:0], ycbcbr_clken};
end
end
//逻辑赋值
assign rgb_vsync = post_frame_vsync_r[2];
assign rgb_href = post_frame_href_r[2];
assign rgb_clken = post_frame_clken_r[2];
//拼图
//wire [7:0] post_img_red;
//wire [7:0] post_img_green;
//wire [7:0] post_img_blue;
assign post_img_red = rgb_href ? R : 8'd0;
assign post_img_green = rgb_href ? G : 8'd0;
assign post_img_blue = rgb_href ? B : 8'd0;
//assign rgb_data[23:16] = post_img_red;
//assign rgb_data[15:8] = post_img_green;
//assign rgb_data[7:0] = post_img_blue;
endmodule
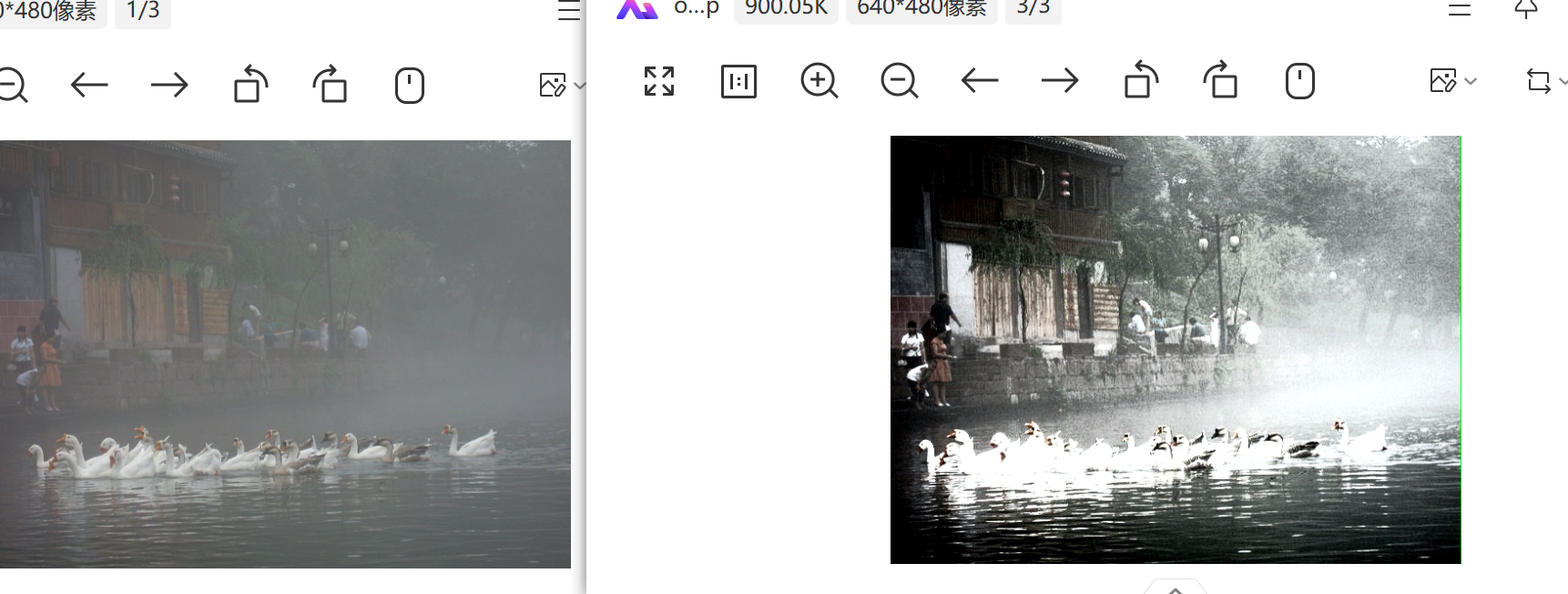
结果
测试代码依旧是利用medelsim仿真图片。代码在我前面的暗通道算法那一节有给出。


















 4284
4284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











