







本文所提供的信息和内容仅供参考。作者对本文内容的准确性、完整性、及时性或适用性不作任何明示或暗示的保证。在任何情况下,作者不对因使用本文内容而导致的任何直接或间接损失承担责任,包括但不限于数据丢失、业务中断或其他经济损失。
读者在使用本文信息时,应自行验证其准确性和适用性,并对其使用结果负责。本文内容不构成专业技术咨询或建议,具体的技术实现和应用应根据实际情况和需要进行详细分析和验证。
本文所涉及的任何商标、版权或其他知识产权均属于其各自的所有者。若本文中引用了第三方的资料或信息,引用仅为学术交流目的,不构成对第三方内容的认可或保证。
若有任何疑问或需进一步信息,请联系本文作者或相关专业人士。
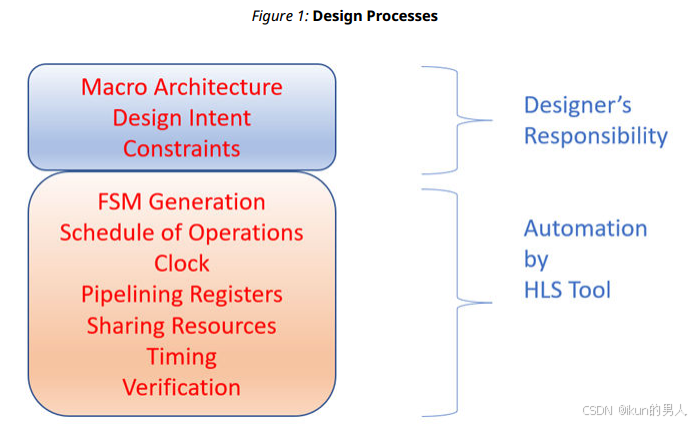
1. 什么是HLS?
HLS是一种自动化设计流程,它从高层次的行为描述(C/C++/SystemC)生成寄存器传输级(RTL)结构,从而实现特定的功能。
2. HLS的典型流程
-
高层建模:用C/C++/SystemC编写算法,并考虑系统架构。
-
功能验证:在行为级进行仿真,确保正确性。
-
RTL生成:HLS工具根据时钟约束、输入条件等生成RTL代码。
-
RTL验证:检查生成的RTL是否符合预期功能。
-
架构探索:在相同代码基础上调整约束,探索不同实现方案。
3. HLS的主要优势
-
快速生成高质量RTL,相比手写RTL更高效、减少人为错误。
-
设计层次提升:设计者只需专注于宏观架构(算法设计和系统交互),而微观架构(状态机、数据通路、流水线等)可交由HLS工具优化。
-
灵活性强:通过修改约束(如时钟周期、性能要求、目标设备等),可以快速生成不同的RTL实现,权衡性能与资源占用。
4.示例
以下是一个简单的程序,其中包含一个用C++编写的compute()函数,用于在CPU上执行。
#include <vector>
#include <iostream>
#include <ap_int.h>
#include "hls_vector.h"
#define totalNumWords 512
unsigned char data_t;
int main(int, char**) {
// initialize input vector arrays on CPU
for (int i = 0; i < totalNumWords; i++) {
in[i] = i;
}
compute(data_t in[totalNumWords], data_t Out[totalNumWords]);
check_results();
}
void compute (data_t in[totalNumWords ], data_t Out[totalNumWords ]) {
data_t tmp1[totalNumWords], tmp2[totalNumWords];
A: for (int i = 0; i < totalNumWords ; ++i) {
tmp1[i] = in[i] * 3;
tmp2[i] = in[i] * 3;
}
B: for (int i = 0; i < totalNumWords ; ++i) {
tmp1[i] = tmp1[i] + 25;
}
C: for (int i = 0; i < totalNumWords ; ++i) {
tmp2[i] = tmp2[i] * 2;
}
D: for (int i = 0; i < totalNumWords ; ++i) {
out[i] = tmp1[i] + tmp2[i] * 2;
}
}
该程序也可以在FPGA上顺序运行,产生正确的结果,与CPU相比没有任何性能提升。为了使应用程序在FPGA上以更高的性能执行,需要重新设计程序以实现各级并行性。
问题分析
-
计算过程是串行的,每个循环
A → B → C → D逐步执行,无法充分利用 FPGA 的并行计算能力。 -
数据流问题:
-
tmp1由in计算得到后,在B中再修改。 -
tmp2由in计算得到后,在C中再修改。 -
out依赖于tmp1和tmp2的计算结果。
-
-
访存优化问题:
-
in数组在A中被访问两次 (tmp1[i] = in[i] * 3; tmp2[i] = in[i] * 3;)。 -
tmp1和tmp2是独立的,可以并行计算。 -
out依赖tmp1和tmp2,但计算可优化。
-
从前面的例子来看,需要为基于FPGA的加速重新构建compute()函数。
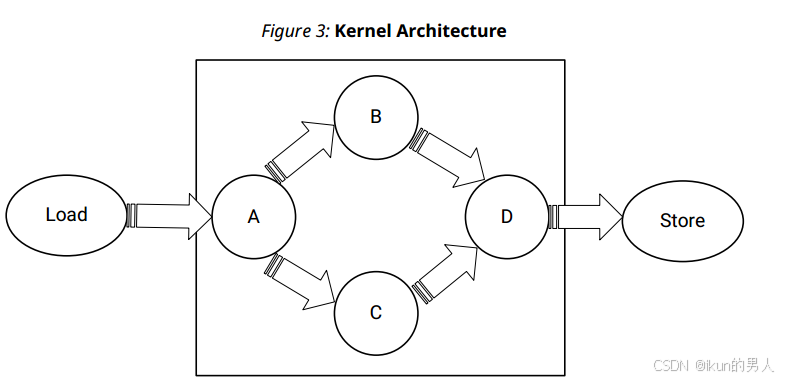
compute()函数Loop A将输入值与3相乘,并创建两个单独的路径B和C。Loop B和C执行操作并将数据馈送到D。这是一个现实情况的简单表示,其中您有几个任务要一个接一个地执行,这些任务作为一个网络相互连接,如下图所示。


















 1416
1416

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









