






本章为深度学习第一次习题作业,内容是第二章课后题,考察对于基础概念的掌握,掌握这些概念后较为容易解答。
习题 2-1 分析为什么平方损失函数不适用于分类问题 , 交叉熵损失函数不适用于回归问题.
首先要知道什么是平方损失函数和交叉熵损失函数:
平方损失函数是MSE的单个样本损失,又叫平方损失性能,是指预测值与实际值差的平方。在机器学习中,平方损失函数是直接测量机器学习模型的输出结果与实际结果之间的距离,若定义机器学习模型的输出为yi ,实际结果为ti ,那么平方损失函数可以被定义为
交叉熵函数主要用于度量两个概率分布间的差异性,能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异
平方损失函数不适用于分类问题,交叉熵损失函数不适用于回归问题。
因为平方损失函数对每一个输出结果都十分看重,而交叉熵损失函数只对正确分类的结果看重。例如,对于一个多分类模型结果输出为(a, b, c),而实际真实结果为(1, 0, 0)。那么根据两种损失函数的定义其损失函数可以写为:
平方损失函数:
交叉熵损失函数:
从结果可以看出交叉熵函数结果只和正确分类的结果有关,这正是我们所需要的;而平方损失函数还和错误的分类有关,它除了让正确分类尽量变大,还会使错误分类变得更平均,这一步对于分类问题来说是多余的,但对于回归问题来说则是不可缺少的,所以说平方损失函数适用于回归问题,不适用于分类问题;交叉熵损失函数适用于分类问题(离散),不适用于回归问题(连续)。
习题2-2 对于一个三分类问题 , 数据集的真实标签和模型的预测标签如下 :
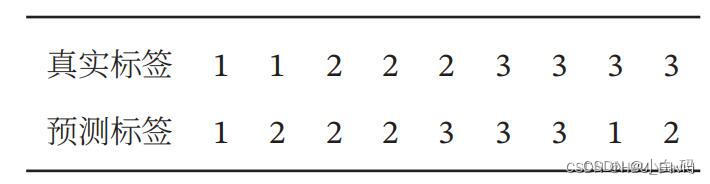
分别计算模型的精确率、召回率、F1值以及它们的宏平均和微平均.
精确率:也叫做精度或查准率,类别c的查准率是所有预测为类别c的样本中预测正确的比例.
召回率:也叫查全率,类别c的查全率是所有真实标签为类别c的样本中预测正确的比例.
F1值:是一个综合指标,为精确率和召回率的调和平均,其中β用于平衡精确率和召回率的重要性,一般取为1,此时F值称为F1值,是精确率和召回率的调和平均.
宏平均:宏平均是每一类的性能指标的算术平均值.
微平均:是每个样本的性能指标的算术平均值.















 134
134











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









