







更好的阅读体验点击跳转
更更好的阅读体验点击跳转
导言
你会DFS序吗?
我想,你肯定会说会.不会,欢迎点击搜索和DFS序学习
你会线段树吗?不会,欢迎点击暂无
我想,身为巨佬的你肯定会.
既然巨佬你会DFS序,会线段树.那么接下来的树链剖分,你也一定会.
接下来的学习,您必备的算法知识有,DFS序,线段树.
初学算法
适用范围
- 将树从x到y结点最短路径上所有节点的值都加上z
我们很容易发现,这个算法就是树上差分算法.
- 求树从x到y结点最短路径上所有节点的值之和
Lca大佬们,很容易发现这个其实就是Lca算法,然后通过之前我们所介绍的算法性质.
总而言之,这就是我们的目标数组了,看上去好多啊,但其实只要两次DFS就解决完毕了.
代码解析
void dfs1(int x,int father)//father是x的父亲节点
{
size[x]=1;//刚开始子树为1,也就是直接
for(int i=head[x]; i; i=Next[i])//访问所有出边
{
int y=edge[i];//儿子节点
if (y==father)//访问到唯一一个不是儿子节点的父亲节点去了
continue;//当然不可以,直接跳过
deep[y]=deep[x]+1;//深度+1,儿子节点是父亲节点深度+1
fa[y]=x;//y的父亲节点是x
dfs1(y,x);//y的父亲节点是x
size[x]+=size[y];//加上儿子贡献的子树
if (size[y]>size[wson[x]])//如果这个节点比当前重儿子,子树还要多(还要重) ,那么营养过剩的重儿子就是他了.
wson[x]=y;//wson[x]表示x节点的重儿子
}
}
这一层DFS,就让我们求解出来了前四个数组,那么后三个数组呢?
void dfs2(int x,int tp)//x表示当前节点,tp表示链头
{
dfn[x]=++cnt;//重新编辑编号
pre[cnt]=x;//存储老编号
top[x]=tp;//存储链头
if (wson[x]) //优先处理重儿子
dfs2(wson[x],tp);
for(int i=head[x]; i; i=Next[i])//访问所有的轻链
{
int y=edge[i];//存储出边
if (y==wson[x] || y==fa[x])//重儿子已经处理过了,父亲节点不可以抵达
continue;
dfs2(y,y);//每一个轻链的链头,都是自己,而且重儿子的开头都是轻链.
}
}
算法拓展
咱们知道,树链剖分是LCA+树上差分的合并增强版,那么他们两个有的操作,他当然也得有.
正如同某名言.你的是我的,我的还是我的.
先来看LCA的操作,其实就是其名的求两点的最近公共祖先.
我们对于上面所述的top数组,也就是链头数组,比较懵逼,觉得他似乎没有什么用处啊.
实际上它的用处非常之大,是树链剖分的核心数组之一.
通俗理解的故事,又来了.以下内容纯属瞎编,只为了更好的理解.
AcwingAcwing.
那么我们得出.
因为A小组和B小组是两个没有交集的小组.(也就是互相都不认识)
那么显然A小组这一串人,都不可能成为答案.
同理B小组这一伙人,也不可能成为答案.
明知没有用,何必浪费时间.
所以,我们迅速跨越中间的所有节点.
a=top[a];//直接爬到链头
b=top[b];//直接爬到链头
这样我们发现效率直线上升.
注意点
还有请注意,每次跳跃的话.
比如说a,b节点要跳跃.
我们每次是将链头深度深的节点往上跳跃,而不本节点的深度.
为了避免出现下面评论所说的情况.
两个节点,跳过去了,跳到了LCA节点的上方去了.
拓展代码
int Query_sum(int a,int b)//a,b这条路径上的权值和
{
int ans=0;//初始化为0
while(top[a]!=top[b]) //此时a,b不在同一条重链上面
{
if (deep[top[a]]<deep[top[b]])//我们这里默认a是深度在下面的链
swap(a,b);
ans+=t.Query_sum(1,1,n,dfn[top[a]],dfn[a]);//访问这条重链,dfn[top[a]]是链头,dfn[a]是当前节点,dfn[top[a]]<dfn[a]因为a后访问.
a=fa[top[a]];//往上面访问,也就是往上面爬一步
}
if (dfn[a]<dfn[b])//保证a深度比b深度,深.保证后面查询l<r
swap(a,b);
ans+=t.Query_sum(1,1,n,dfn[b],dfn[a]);//他们已经在同一条重链上面了
return ans;
}
链上结构
路径操作
看到上面的代码,我们发现t是什么东西.
t其实就是我们的线段树数据结构.
根据树上差分的操作们,得知我们的树链剖分需要复制一大波操作.
-
将树从x到y结点最短路径上所有节点的值都加上z
-
求树从x到y结点最短路径上所有节点的值之和
根据上面这些操作,我们不难发现,每条链也需要资瓷这些操作.
综上所述得出.
- 一条链上,需要资瓷区间修改.
- 一条链上,需要支持区间查询.
总而言之,区间操作多多,因此我们使用线段树.
当然了巨佬们,肯定喜欢使用平衡树等等高大上,上档次,有内涵的数据结构,但是线段树的代码复杂度对于考试而言,是最好不过的结构了.
代码复杂度是考试的时候,极为重要的复杂度. by Acwing站长,校长,集训队大佬yxc总裁
总而言之,言而总之,我们树链剖分的代码量,成功的增加了1k.
子树操作
我们再来几个操作.
-
将以x为根节点的子树内所有节点值都加上z
-
求以x为根节点的子树内所有节点值之和
看到子树操作,有点不知所措,线段树似乎不支持这个鬼东西吧,难道代码量又要翻倍处理.
事实上,我们的代码只需要增加八行代码,也就核心两句话.
我们的DFS遍历,在这里起到了决定性,关键性,核心性的作用.(语文老师:捕捉到了病句,起到了,什么的作用,句式杂糅)
我们发现DFS序列的一个重点,就是.一颗子树,它的DFS序,是有序的.
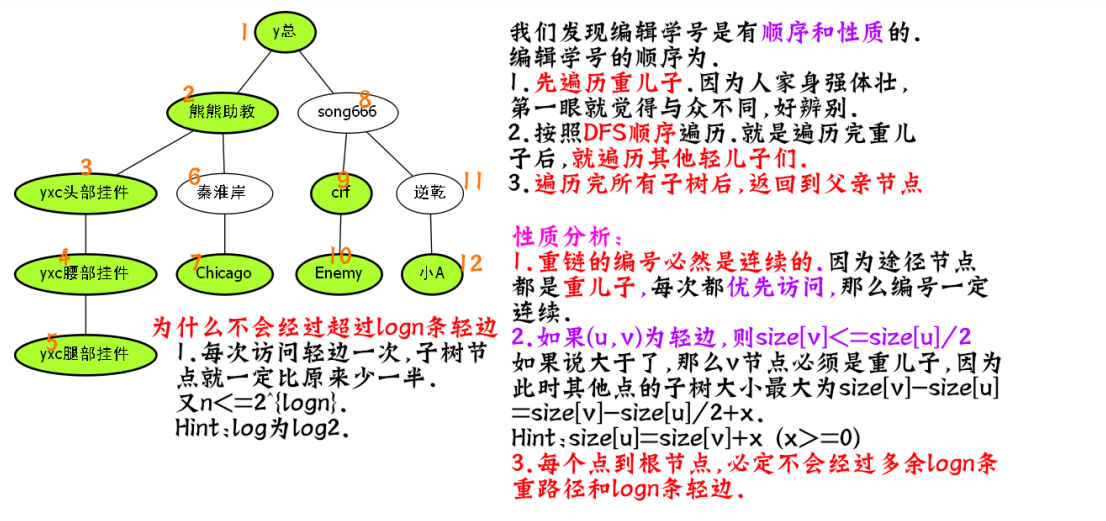
还是这张图,我们发现熊熊助教这颗子树.
其实就是[2,7][2,7]这个区间,就达到了修改以2为根的树修改.
因此代码如下.
void Update(int x,int v)//修改子树的值
{
t1.Update(1,1,n,dfn[x],dfn[x]+size[x]-1,v);//DFS序是有序的数列
}
同理,查询操作也就如下所示了.
int Query_sum(int x)//查询子树的和
{
return t1.Query_sum(1,1,n,dfn[x],dfn[x]+size[x]-1);//统计子树和,其实和修改差不多
}
树链模板
struct line_tree//线段树
{
#define mid (l+r>>1)//二分中点
#define Lson (rt<<1),l,mid//左儿子
#define Rson (rt<<1 | 1),mid+1,r//右儿子
#define Len (r-l+1)//区间长度
void Push_down(int rt,int l,int r)
//这里的懒惰标记只适合区间修改,把[l,r]区间都变成v.如果是都+v,则必须Lazy标记+=,而不是下面的=
{
if (Lazy[rt]!=-1)//当前节点有Lazy标记
{
Lazy[rt<<1]=Lazy[rt<<1 | 1]=Lazy[rt];//懒惰标记下传
sum[rt<<1]=Lazy[rt]*(mid-l+1);//左儿子的区间长度
sum[rt<<1 |1]=Lazy[rt]*(r-(mid+1)+1);//右儿子的区间长度
Lazy[rt]=-1;//此时懒惰标记已经下传完毕了,那么可以全部清空了
}
}
void build(int rt,int l,int r)
{
Lazy[rt]=-1;
if (l==r)//叶子节点
{
sum[rt]=1;//sum数组
return ;
}
build(Lson);//左儿子
build(Rson);//右儿子
sum[rt]=sum[rt<<1]+sum[rt<<1 |1];//左儿子节点+右儿子节点
}
void Update(int rt,int l,int r,int L,int R,int v)//将[L,R]区间统统修改成为v,然后当前区间[l,r]
{
if (L<=l && r<=R)//当前区间被包括了
{
Lazy[rt]=v;//懒惰标记修改
sum[rt]=v*Len;//全部修改完毕
return ;
}
Push_down(rt,l,r);//向下传递Lazy标记
if (L<=mid)//在左儿子身上
Update(Lson,L,R,v);//左儿子
if (R>mid)//在右儿子身上
Update(Rson,L,R,v);//右儿子
sum[rt]=sum[rt<<1]+sum[rt<<1 |1];//左儿子+右儿子
}
int Query_sum(int rt,int l,int r,int L,int R)//查询[L,R]区间和,当前区间[l,r]
{
int ans=0;
if (L<=l && r<=R)//当前区间被包括了
return sum[rt];
if (L<=mid)//左儿子上面
ans+=Query_sum(Lson,L,R);
if (R>mid)//右儿子上面
ans+=Query_sum(Rson,L,R);
sum[rt]=sum[rt>>1]+sum[rt>>1 |1];
return ans;//返回
}
} t1;
struct Tree_Chain//树链剖分
{
void add_edge(int a,int b)//添加边函数
{
edge[++tot]=b;//出边节点
Next[tot]=head[a];//链表链接
head[a]=tot;//上一个节点
}
void dfs1(int x,int father)//x节点,和他的父亲节点father
{
size[x]=1;//刚开始就自己这一个节点
for(int i=head[x]; i; i=Next[i]) //开始遍历所有的出边
{
int y=edge[i];//出边节点
if (y==father)//儿子节点是不可以等于父亲节点的
continue;
deep[y]=deep[x]+1;//儿子的深度,是父亲深度+1
fa[y]=x;//y的父亲节点是x
dfs1(y,x); //开始遍历儿子节点
size[x]+=size[y];//儿子节点贡献子树大小
if (size[y]>size[wson[x]]) //发现当前的儿子节点,比之前的重儿子,还要重(胖),那么更新重儿子
wson[x]=y;//更新
}
return ;//华丽结束
}
void dfs2(int x,int tp)//x节点,以及x节点所在链的链头
{
dfn[x]=++cnt;//当前节点的新编号,也就是DFS序编号
pre[cnt]=x;//老编号,虽然在整道题目中没有用处,但是树链剖分板子打一遍也是好的
top[x]=tp;//链头存储一下
if (wson[x])//有重儿子,那么一定先访问重儿子
dfs2(wson[x],tp); //访问节点,此时重儿子一定在重链上,所以还是tp
for(int i=head[x]; i; i=Next[i]) //访问所有的轻儿子
{
int y=edge[i];//出边
if (y==wson[x] || y==fa[x])//轻儿子节点不能是重儿子,也不能是父亲节点
continue;
dfs2(y,y);//每一个轻儿子,他的链头其实都是自己,而且重链的开头也得是轻儿子
}
}
void Update(int x,int v)//修改子树的值
{
t1.Update(1,1,n,dfn[x],dfn[x]+size[x]-1,v);//DFS序是有序的数列
}
int Query_sum(int x)//查询子树的和
{
return t1.Query_sum(1,1,n,dfn[x],dfn[x]+size[x]-1);//统计子树和,其实和修改差不多
}
long long Query_sum2(int a,int b)//a,b这条路径上的权值和
{
long long ans=0;//初始化为0
while(top[a]!=top[b]) //此时a,b不在同一条重链上面
{
if (deep[top[a]]<deep[top[b]])//我们这里默认a是深度在下面的链
swap(a,b);
now_ans=0;
t1.Query_sum(1,1,n,dfn[top[a]],dfn[a]);
ans+=now_ans;//访问这条重链,dfn[top[a]]是链头,dfn[a]是当前节点,dfn[top[a]]<dfn[a]因为a后访问.
a=fa[top[a]];//往上面访问,也就是往上面爬一步
}
if (deep[a]<deep[b])//保证a深度比b深度,深.保证后面查询l<r
swap(a,b);
now_ans=0;
t1.Query_sum(1,1,n,dfn[top[a]],dfn[a]);
ans+=now_ans;//他们已经在同一条重链上面了
return ans;
}
int Update2(int a,int b) //链上修改
{
while(top[a]!=top[b])//也就是两个点还在不同的重链上
{
if (deep[top[a]]<deep[top[b]])//我们默认a节点是深度比b节点深一些
swap(a,b);//交换一下就好了
t1.Update(1,1,n,dfn[top[a]],dfn[a],0);//在爬的过程中,也帮忙修改一下
a=fa[top[a]];//往上面爬一下
}
if (deep[a]<deep[b])//保证a深度比b深度,深.保证后面查询l<r
swap(a,b);
t1.Update(1,1,n,dfn[b],dfn[a],0);//同一条链了,那么修改这条链上在[a,b]之间的点
}
//请注意,本模板是很多题目的操作合并而成,可能有问题,但是单独没有问题.如果有问题请艾特博主.
//所有代码风格为博主风格,所以操作之间都是通用的,应该不会出现问题.
} t2;
经典选讲
第一题 模板题[HAOI2015]树上操作
题目描述
有一棵点数为 NN ,之后接这个操作的参数( x 或者 x a ) 。
输出格式:
对于每个询问操作,输出该询问的答案。答案之间用换行隔开。
输入输出样例
输入样例#1:
5 5
1 2 3 4 5
1 2
1 4
2 3
2 5
3 3
1 2 1
3 5
2 1 2
3 3
输出样例#1:
6
9
13
数据范围
对于 100100 。
题意理解
一棵树上,要求支持单点修改,子树修改,路径修改操作.
思路解析
学会了树连剖分的我们,很轻松的发现,这就是一个树链剖分的模板题目.
所以说,我们几乎是可以轻松解决这道题目了.
于是我们惊奇的发现一道省选题目,就这样轻松愉快地AC了.
代码超多中文解释,绝对看得懂.
代码解析
#include <bits/stdc++.h>
using namespace std;
#define int long long
const int N=5e5+200;
int sum[N<<2],Lazy[N<<2];//处理区间和;懒惰标记
int head[N<<1],edge[N<<1],ver[N<<1],Next[N<<1],tot;
int pre[N],deep[N],size[N],a[N],fa[N],cnt;
int wson[N],dfn[N],top[N],n,m,now_ans;
struct line_tree
{
#define mid ((l+r)>>1) //二分值
#define lson root<<1,l,mid //左儿子
#define rson root<<1|1,mid+1,r //右儿子
#define len (r-l+1) //区间长度
void build(int root,int l,int r)
{
if (l==r)//抵达叶子节点,也就是单个节点
{
sum[root]=a[pre[l]];
return ;
}
build(root<<1,l,mid);//左儿子
build(root<<1 | 1,mid+1,r);//右儿子
sum[root]=sum[root<<1]+sum[root<<1 | 1];//左右儿子都访问完毕了,可以更新父亲节点了.
}
inline void Push_down(int x,int lenn)
{
Lazy[x<<1]+=Lazy[x];//左儿子得到,父亲节点的懒惰标记下传
Lazy[x<<1 | 1]+=Lazy[x];//右儿子得到,父亲节点的懒惰标记下传
sum[x<<1]+=Lazy[x]*(lenn-(lenn>>1));//懒惰标记的值叠加
sum[x<<1 | 1]+=Lazy[x]*(lenn>>1);//懒惰标记的值叠加
Lazy[x]=0;//懒惰标记已经下传
}
inline void Query_sum(int root,int l,int r,int L,int R)//目标区间ql,qr,当前区间[l,r],当前节点是root
{
if(L<=l&&r<=R)//目标区间包含了当前区间
{
now_ans+=sum[root];//累加
return;//返回
}
else
{
if(Lazy[root])//有标记
Push_down(root,len);//先走标记
if(L<=mid)//左儿子上有
Query_sum(lson,L,R);
if(R>mid)//右儿子上
Query_sum(rson,L,R);
}
}
inline void Update(int root,int l,int r,int L,int R,int k)//目标区间[L,R]全部要加上K,当前区间[l,r]
{
if (L<=l && r<=R)//[L,R]包括了当前区间[l,r]
{
Lazy[root]+=k;//叠加懒惰标记
sum[root]+=k*len;
return ;
}
if (Lazy[root])//有懒惰标记
Push_down(root,len);//下传标记
if (L<=mid)
Update(lson,L,R,k);//左儿子
if (R>mid)
Update(rson,L,R,k);//右儿子
sum[root]=sum[root<<1]+sum[root<<1 |1];
}
} t1;
struct Tree_Chain
{
inline void add_edge(int a,int b)
{
edge[++tot]=b;
Next[tot]=head[a];
head[a]=tot;
}
void dfs1(int x,int father)//fa是x的父亲节点
{
size[x]=1;//刚开始子树为1,也就是直接
for(int i=head[x]; i; i=Next[i])//访问所有出边
{
int y=edge[i];//儿子节点
if (y==father)//访问到唯一一个不是儿子节点的父亲节点去了
continue;//当然不可以,直接跳过
deep[y]=deep[x]+1;//深度+1,儿子节点是父亲节点深度+1
fa[y]=x;//y的父亲节点是x
dfs1(y,x);//y的父亲节点是x
size[x]+=size[y];//加上儿子贡献的子树
if (size[y]>size[wson[x]])//如果这个节点比当前重儿子,子树还要多(还要重) ,那么营养过剩的重儿子就是他了.
wson[x]=y;//wson[x]表示x节点的重儿子
}
}
void dfs2(int x,int tp)//x表示当前节点,tp表示链头
{
dfn[x]=++cnt;//重新编辑编号
pre[cnt]=x;//存储老编号
top[x]=tp;//存储链头
if (wson[x]) //优先处理重儿子
dfs2(wson[x],tp);
for(int i=head[x]; i; i=Next[i])//访问所有的轻链
{
int y=edge[i];//存储出边
if (y==wson[x] || y==fa[x])//重儿子已经处理过了,父亲节点不可以抵达
continue;
dfs2(y,y);//每一个轻链的链头,都是自己,而且重儿子的开头都是轻链.
}
}
long long Query_sum(int a,int b)//a,b这条路径上的权值和
{
long long ans=0;//初始化为0
while(top[a]!=top[b]) //此时a,b不在同一条重链上面
{
if (deep[top[a]]<deep[top[b]])//我们这里默认a是深度在下面的链
swap(a,b);
now_ans=0;
t1.Query_sum(1,1,n,dfn[top[a]],dfn[a]);
ans+=now_ans;//访问这条重链,dfn[top[a]]是链头,dfn[a]是当前节点,dfn[top[a]]<dfn[a]因为a后访问.
a=fa[top[a]];//往上面访问,也就是往上面爬一步
}
if (deep[a]<deep[b])//保证a深度比b深度,深.保证后面查询l<r
swap(a,b);
now_ans=0;
t1.Query_sum(1,1,n,dfn[top[a]],dfn[a]);
ans+=now_ans;//他们已经在同一条重链上面了
return ans;
}
inline void update_son(int x,int k)
{
t1.Update(1,1,n,dfn[x],dfn[x]+size[x]-1,k);
//因为DFS所以子树其实是有序的,而且一个子树大小是size[x],那么dfn+size-1就可以遍历整棵树
}
} t2;
signed main()//其实就是int main()
{
// freopen("stdin.in","r",stdin);
// freopen("a.out","w",stdout);
scanf("%lld%lld",&n,&m);
for(int i=1; i<=n; i++)
scanf("%lld",&a[i]);
for(int i=1; i<n; i++)
{
int a,b;
scanf("%lld%lld",&a,&b);
t2.add_edge(a,b);
t2.add_edge(b,a);//无向图建立边
}
t2.dfs1(1,0);//第一次DFS,求size,deep,fa
t2.dfs2(1,1);//第二DFS求dfn,top
t1.build(1,1,n);
while(m--)
{
int k,a,b,c;
scanf("%lld",&k);
if (k==1)
{
scanf("%lld%lld",&a,&b);
t1.Update(1,1,n,dfn[a],dfn[a],b);//虽然是区间修改[dfn[a],dfn[a]],但是其实是单点修改.
}
if (k==2)
{
scanf("%lld%lld",&a,&b);
t2.update_son(a,b);//修改a以及子树,统统增加b
}
if (k==3)
{
scanf("%lld",&a);
printf("%lld\n",t2.Query_sum(1,a));
}
}
return 0;
}















 1304
1304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









