







URLlib基本使用
import urllib.request
#使用urllib获取首页
url = "http://www.baidu.com"
response = urllib.request.urlopen(url) #模拟浏览器发送请求
#获取响应中的页面源码
#read 返回响应的是二进制数据
content = response.read().decode("utf-8")
#打印数据
print(content)
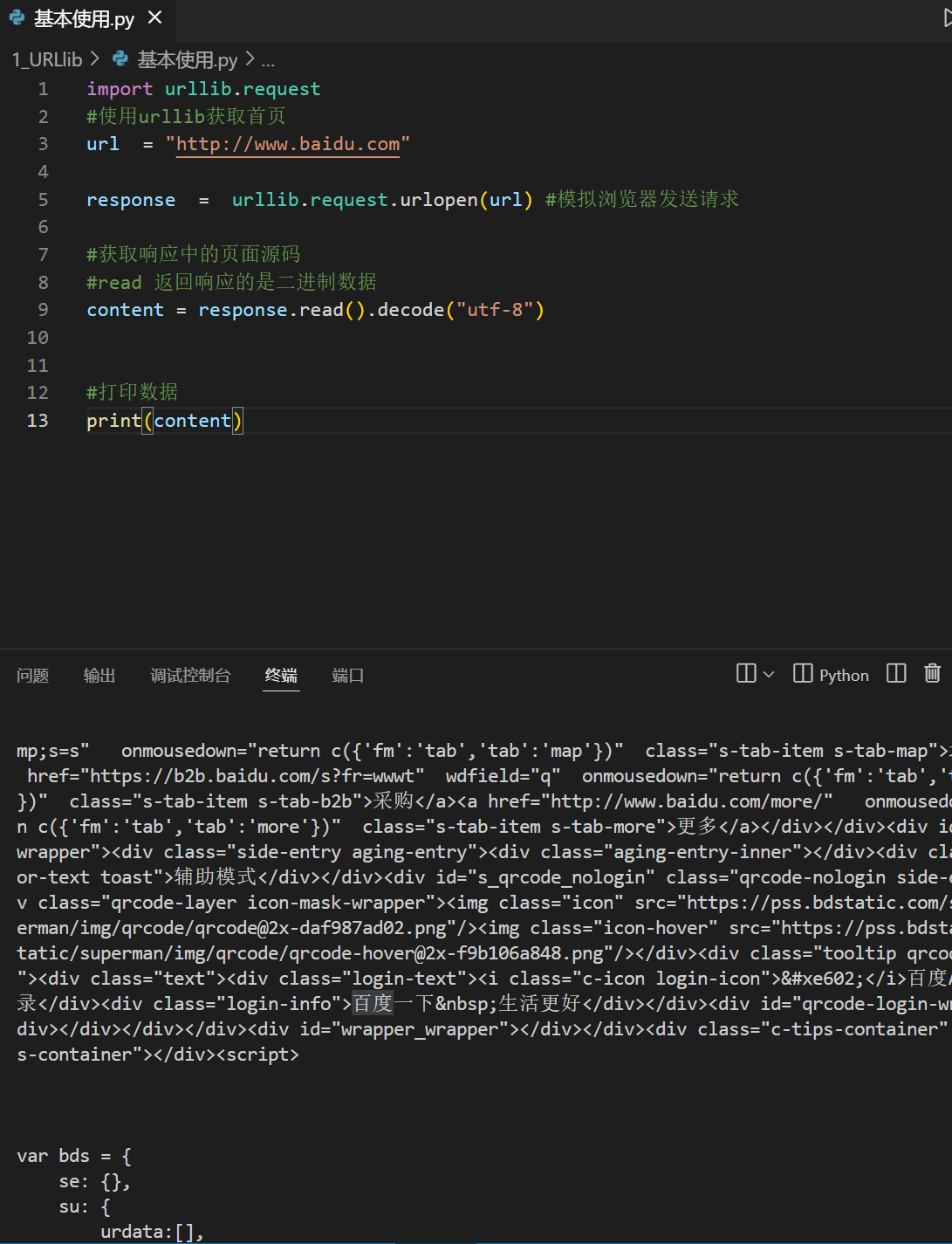
URllib 一个类型 六个方法
#一个类型 和 六个方法
print(type(response))
输出类型
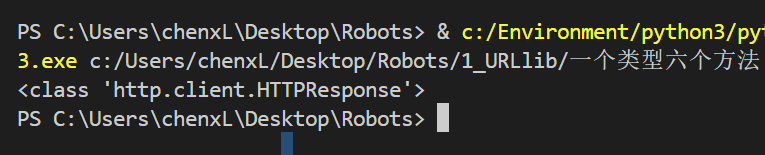
一个字节一个字节读
content = response.read()
读五个
content = response.read(5)
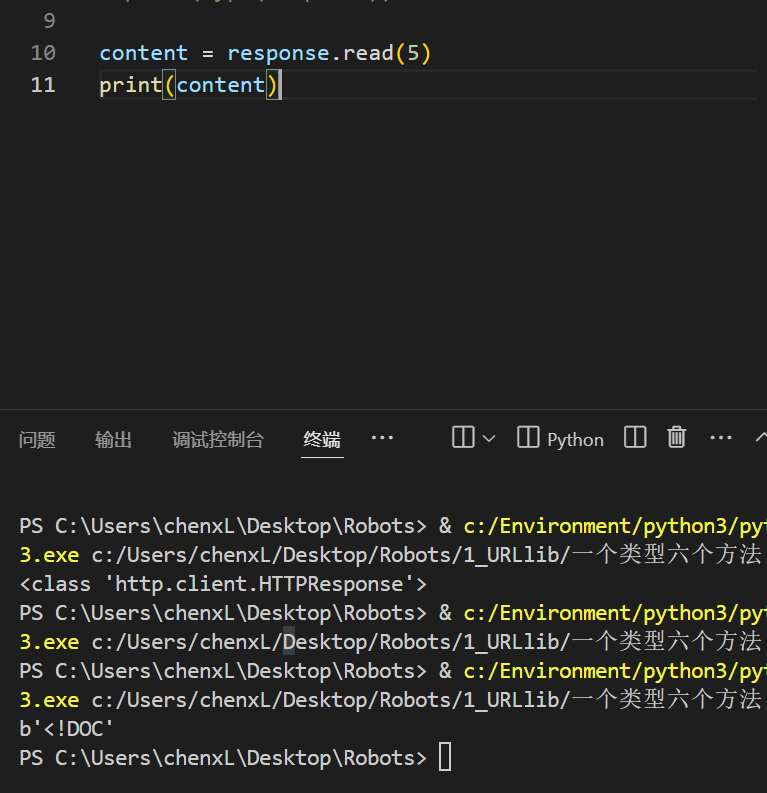
读取一行
content = response.readline()
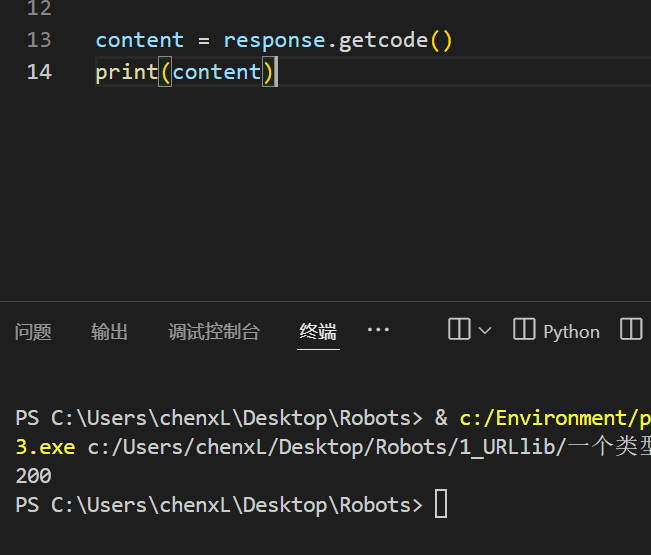
返回状态码
content = response.getcode()
返回url
content =response.geturl()
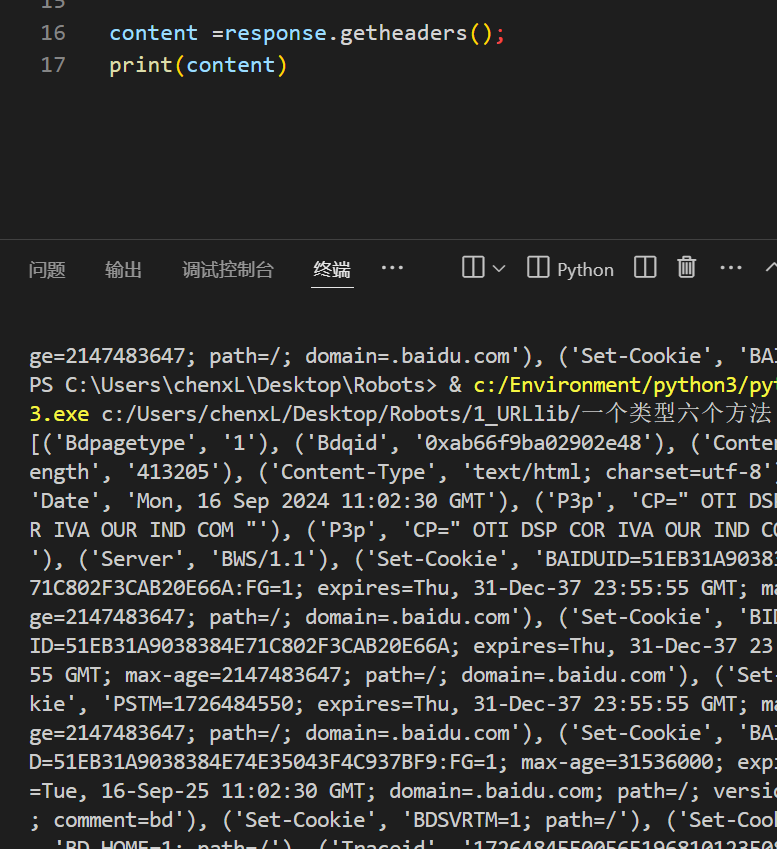
返回haed头信息
content =response.getheaders();
URLlib下载
import urllib.request
#下载网页
url_page = "http://www.baidu.com"
#url 代表的是下载的路径 ,filename是文件的名字
urllib.request.urlretrieve(url_page,'baidu.html')
#下载图片
url_tp = "http://gips3.baidu.com/it/u=3886271102,3123389489&fm=3028&app=3028&f=JPEG&fmt=auto?w=1280&h=960"
urllib.request.urlretrieve(url_tp,'1.jpg')
#下载视频
url_sp = "https://vdept3.bdstatic.com/mda-qidrwffssm81iabi/cae_h264/1726337986877494326/mda-qidrwffssm81iabi.mp4?v_from_s=hkapp-haokan-hbf&auth_key=1726495675-0-0-c772a674588d1dbda061bfdfcc8cb09a&bcevod_channel=searchbox_feed&cr=0&cd=0&pd=1&pt=3&logid=0475415096&vid=5881303377846744801&klogid=0475415096&abtest="
urllib.request.urlretrieve(url_sp,'1.mp4')
请求对象的定制
User Agent中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识别客户使用操作系统及版本、CPU 类型、浏览器及版本。浏览器内核、浏览器渲染引擎、浏览器语言、浏览器插件等添加User-Agent
import urllib.request
url = "https://www.baidu.com"
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60 Opera/8.0 (Windows NT 5.1; U; en)'
}
request = urllib.request.Request(url=url,headers=headers) #先添加headers
response = urllib.request.urlopen(request) #再去请求
content = response.read().decode("utf-8")
print(content)
编解码
import urllib.request
import urllib.parse
url = "https://cn.bing.com/search?q=" #把汉字转换为urlcode编码
name = urllib.parse.quote("UA大全")
url = url + name
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60 Opera/8.0 (Windows NT 5.1; U; en)'
}
req = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(req)
content = response.read().decode("utf-8")
print(content)
urlencode 编码
import urllib.request
import urllib.parse
url = "https://cn.bing.com/search?" #把汉字转换为urlcode编码
data = {
'q' : '大全'
}
url = url + urllib.parse.urlencode(data)
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60 Opera/8.0 (Windows NT 5.1; U; en)'
}
req = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(req)
content = response.read().decode("utf-8")
print(content)
POST 请求
import json
import ssl
import urllib.request
# 创建一个不验证证书的上下文对象
ctx = ssl.create_default_context()
ctx.check_hostname = False
ctx.verify_mode = ssl.CERT_NONE
url = "https://8.134.207.38:5003/api/user/login"
data = {
"username": "admin",
"password": "123456"
}
headers = {
'content-type':'application/json; charset=UTF-8',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36'
}
data_json = json.dumps(data).encode('utf-8')
req = urllib.request.Request(url=url, headers=headers, data=data_json)
# 使用创建的上下文对象打开URL
response = urllib.request.urlopen(req, context=ctx)
content = response.read().decode("utf-8")
obj = json.loads(content)#json 请求响应
print(obj)
ajax 请求
GET请求 并写入文件import urllib.request
import json
import urllib.parse
url = "https://movie.douban.com/j/subject_suggest?"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0',
'sec-ch-ua': '"Chromium";v="128", "Not;A=Brand";v="24", "Microsoft Edge";v="128"'
}
data = {
'q' :'奥特曼'
}
url = url + urllib.parse.urlencode(data)
req = urllib.request.Request(url=url,headers=headers)
response = urllib.request.urlopen(req)
content = response.read().decode("utf-8")
print(json.loads(content))
obj = content
with open('a.json', 'w',encoding="utf-8") as fp:
fp.write(obj)
豆瓣
import json
import urllib.request
import urllib.parse
def create_request(page):
url = 'https://movie.douban.com/j/chart/top_list?type=5&interval_id=100%3A90&action=&'
data = {
'start' : (page -1 ) *20 ,
'limit' : 20
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0',
'sec-ch-ua': '"Chromium";v="128", "Not;A=Brand";v="24", "Microsoft Edge";v="128"'
}
data = urllib.parse.urlencode(data)
url = url + data #拼接
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
cont = res.read().decode("utf-8")
# obj = json.loads(cont)
return cont
def wr(page,obj):
with open('豆瓣'+str(page)+'.json', 'w',encoding="utf-8") as fp:
fp.write(obj)
if __name__ == '__main__':
start = int(input("开始"))
end = int(input("结束"))
for page in range(start,end):
req = create_request(page)
obj = req
wr(page,obj)
KFC
import json
import urllib.parse
import urllib.request
def create(page):
url = "https://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=cname"
data = {
'cname':'北京',
'pid':'',
'pageIndex':page,
'pageSize':10
}
data = urllib.parse.urlencode(data).encode("utf-8")
headers = {
'content-type':'application/x-www-form-urlencoded; charset=UTF-8',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0'
}
req = urllib.request.Request(url=url,data=data,headers=headers)
res = urllib.request.urlopen(req)
cont = res.read().decode("utf-8")
return cont
def wr(page,obj):
with open('KFC'+str(page)+'.json', 'w',encoding="utf-8") as fp:
fp.write(obj)
if __name__ == '__main__':
start = int(input('开始: '))
end = int(input('结束: '))
for page in range(start,end):
obj = create(page)
wr(page,obj)
代理
import urllib.request
url = "http://47.236.41.52:888/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0',
'sec-ch-ua': '"Chromium";v="128", "Not;A=Brand";v="24", "Microsoft Edge";v="128"'
}
proxies = {
'http':'127.0.0.1:7890'
}
req = urllib.request.Request(url=url,headers=headers)
# res = urllib.request.urlopen(req)
handler = urllib.request.ProxyHandler(proxies=proxies)
opener= urllib.request.build_opener(handler)
res = opener.open(req)
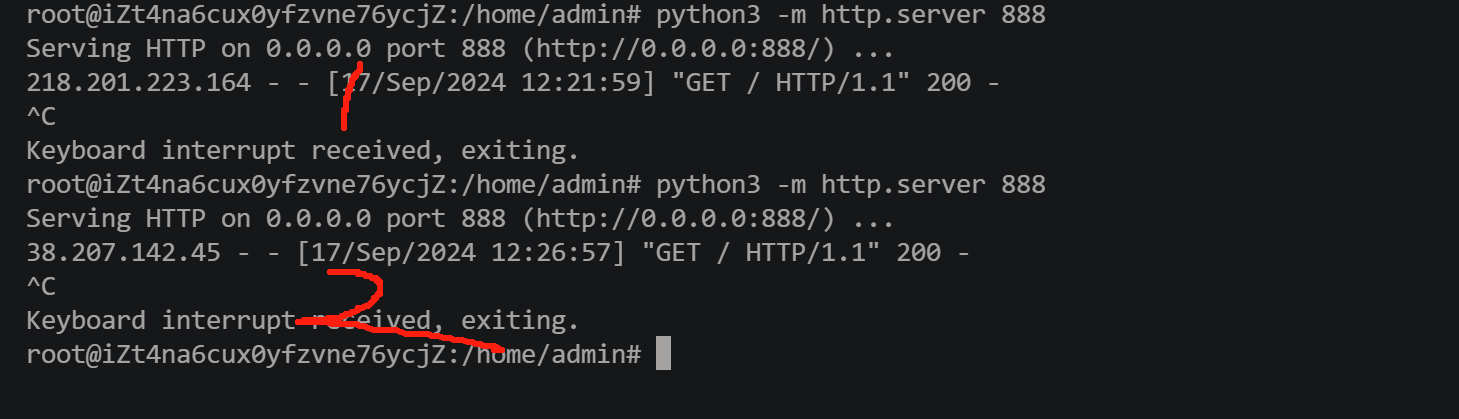
第一次 本地 ,第二次挂的代理
代理池
import urllib.request
import random
url = "http://gjhhkfd2.dnslog.pw"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0',
'sec-ch-ua': '"Chromium";v="128", "Not;A=Brand";v="24", "Microsoft Edge";v="128"'
}
proxies_s = [
{'http':'127.0.0.1:7890'},
{'http':'127.0.0.1:7890'},
{'http':'127.0.0.1:7890'},
{'http':'127.0.0.1:7890'}
]
proxies = random.choice(proxies_s)
req = urllib.request.Request(url=url,headers=headers)
handler = urllib.request.ProxyHandler(proxies=proxies)
opener = urllib.request.build_opener(handler)
res = opener.open(req) #发送















 1288
1288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









