







Xpath
Chrom浏览器安装Xpaht插件

快捷键 Ctrl + shift +x 启动
Xpaht基本使用
- 实例化一个etree对象,且需要将被解析的页面源码数据加载到该对象中
from lxml import etree
1. 将本地的html文档中的源码数据加载到etree对象中
tree = etree.parse(filepath)
2. 将互联网上获取的源码数据加载到该对象中
tree = etree.HTML('page_text')
2. 调用etree对象中的xpaht方法实现标签定位和内容获取,返回的是元素列表
r = tree.xpath('xpath表达式') //返回的是xpath表达式匹配的对象列表
所以我们使用etree对象中的xpath方法根据xpath表达式去解析文件内容。重点学习的是xpath表达式的学习!!!
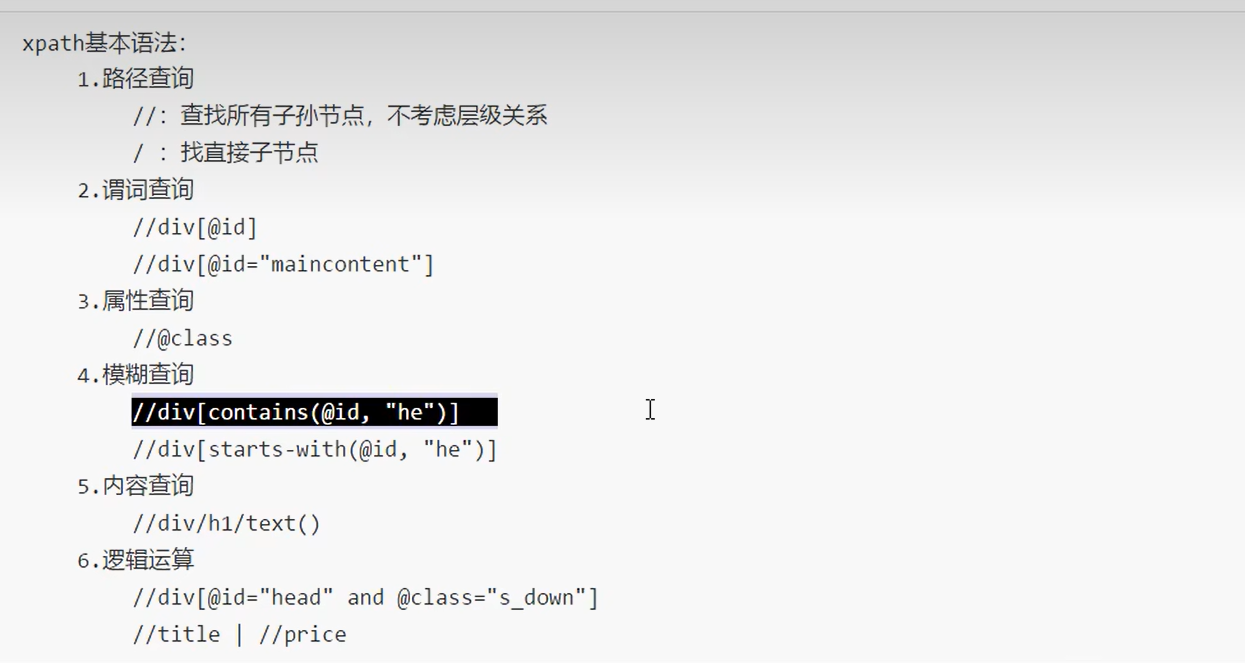
标签定位
层级定位:
单级层级定位:/
r = tree.xpath('/html/body/div')
多层级定位://
r = tree.xpath('/html//div'):获取html下的所有div标签
r = tree.xpath('//div') :获取任务位置的div标签
属性定位:tag[@attr=value]
r = tree.xpath("//div[@class='song']") :获取class属性为song的div选择器
索引定位:tag[索引]
r = tree.xpath('//li[7]/a/text()')
百度备案
import urllib.request
from lxml import html
url = "http://www.baidu.com/"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0',
'sec-ch-ua': '"Chromium";v="128", "Not;A=Brand";v="24", "Microsoft Edge";v="128"'
}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
cont = res.read().decode("utf-8")
# print(cont)
#解析百度 ,获取百度一下
tree =html.fromstring(cont)
list = tree.xpath('//p//a[@href="http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=11000002000001"]')
for i in list:
print(i.text)
爬取 图片
import urllib.request
from lxml import html
def create_req(page):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36 Edg/128.0.0.0',
'sec-ch-ua': '"Chromium";v="128", "Not;A=Brand";v="24", "Microsoft Edge";v="128"'
}
if page == 1:
url = "https://sc.chinaz.com/tupian/huahuitupian.html"
else:
url = 'https://sc.chinaz.com/tupian/huahuitupian_' + str(page) + '.html'
req = urllib.request.Request(url=url, headers=headers)
res = urllib.request.urlopen(req)
cont = res.read().decode("utf-8")
# print(cont)
return cont
def down(cont):
# 下载图片
tree =html.fromstring(cont)
# 使用 XPath 提取图片的 src 链接
jpgname = tree.xpath('/html/body/div[3]/div[2]//img/@alt')
jpgurl = tree.xpath('//div//img/@data-original')
print(len(jpgname),len(jpgurl))
# 打印图片 URL
for i in range(len(jpgname)):
name = jpgname[i]
url = jpgurl[i]
url = 'http:'+url
urllib.request.urlretrieve(url=url,filename='C:/Users/chenxL/Desktop/Robots/jpg/'+name+'.jpg')
if __name__ == '__main__':
start = int(input('开始:'))
end = int(input('结束: '))
for page in range(start, end):
cont = create_req(page)
# 下载
down(cont)
JsonPath
参考 :https://blog.csdn.net/CaffeineDriven/article/details/117936068
{
"store": {
"book": [
{
"category": "reference",
"author": "Nigel Rees",
"title": "Sayings of the Century",
"price": 8.95
},
{
"category": "fiction",
"author": "Evelyn Waugh",
"title": "Sword of Honour",
"price": 12.99
},
{
"category": "fiction",
"author": "Herman Melville",
"title": "Moby Dick",
"isbn": "0-553-21311-3",
"price": 8.99
},
{
"category": "fiction",
"author": "J. R. R. Tolkien",
"title": "The Lord of the Rings",
"isbn": "0-395-19395-8",
"price": 22.99
}
],
"bicycle": {
"color": "red",
"price": 19.95
}
},
"expensive": 10
}
import jsonpath
import json
obj = json.load(open('a.json','r+',encoding="utf-8"))
author_list = jsonpath.jsonpath(obj,'$.store.book[0].author')
print(author_list)
淘票票
import urllib.request
import json
import jsonpath
url = "https://dianying.taobao.com/showAction.json?_ksTS=1726561086239_64&jsoncallback=jsonp65&action=showAction&n_s=new&event_submit_doGetSoon=true"
headers = {
'Accept': 'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
# 'Accept-Encoding': 'gzip, deflate, br, zstd',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Cookie': 'cna=QCmYHS+kW1wCAS7oej+YE8dC; miid=1667218612139589108; thw=xx; tfstk=f5rjZSj9BIAXo1ySsqBrAWa0T7m_5SsFhdMTKRK2BmnvXONaalut_ZVs55PoWoo437GTT7GvbNc2fcw_s5P_ItDt65Fs_r7PY-2mjcCE1MSUnYKBm7Vj6fIRBAH9WpJK2a2mjcCyUhQFA-VC0XZA5cBS2AMiHch9DbBSdAn9DVKvyQhoBchT6V3-wvM6XCKxWLhy8nMPhb2fFuEN7yOHLshpXhEAjqGI8F-6fuMjllexNqgbVxgj945hfTrYaRE4m4bkzc2zR5aT9_8qMyMQN2zfOnNQiAFS0kBGo40TflMur1TsOPe4-P35HieScjgT47permaTilg0ldX3emFu-X0Ar_D70kust4ORM8ySM2a_g_xtgyw8N2ryaHoL-7ZsJDIyIHlQbDY6F2xsFXW5FFYZY_pLw90Oc83xEY5NFTTUIqHoFXW5FFYikYDzQT6W8Rf..; t=477a647b6aa9ce95fa24ee7f393179cf; cookie2=1e212e002b668a42c5d61540568ea97e; v=0; _tb_token_=ee6f14477b380; xlly_s=1; isg=BGtrPrLxiVvS_9YPQgBc21OX-o9VgH8CzlH3-t3oRqoBfIveZVDLUp3f1rwS3Nf6',
'Host': 'dianying.taobao.com',
'Pragma': 'no-cache',
'Referer': 'https://dianying.taobao.com/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/128.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'sec-ch-ua': '"Chromium";v="128", "Not;A=Brand";v="24", "Google Chrome";v="128"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"'
}
req = urllib.request.Request(url=url,headers=headers)
res = urllib.request.urlopen(req)
cont = res.read().decode('utf-8')
cont = cont.split('(')[1].split(')')[0]
# print(cont)
with open ('tpp.json','w',encoding="utf-8") as fp:
fp.write(cont)
name = json.load(open('tpp.json','r',encoding="utf-8"))
obj = jsonpath.jsonpath(name,'$.returnValue[*].showName')
print(obj)
BS4
新建 应该 a.html<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>示例页面</title>
</head>
<body>
<h1>欢迎来到我的示例页面</h1>
<!-- 插入图片 -->
<img src="example.jpg" alt="示例图片" width="500" height="300">
<a href="x" > text </a>
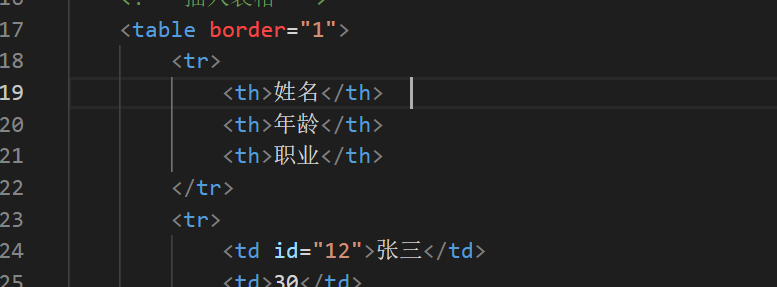
<h2>示例表格</h2>
<!-- 插入表格 -->
<table border="1">
<tr>
<th>姓名</th>
<th>年龄</th>
<th>职业</th>
</tr>
<tr>
<td id="12">张三</td>
<td>30</td>
<td>软件工程师</td>
</tr>
<tr>
<td id ="2">李四</td>
<td>25</td>
<td>设计师</td>
</tr>
<tr>
<td>王五</td>
<td>28</td>
<td>市场营销</td>
</tr>
</table>
<p>这是一个包含图片和表格的示例HTML页面。</p>
</body>
</html>
测试
from bs4 import BeautifulSoup
soup = BeautifulSoup(open('../a.html',encoding="utf-8"),'lxml')
寻找a 标签
print(soup.a) #返回a 标签
print(soup.a.attrs) #返回a 标签 的属性
find 标签
#find 标签
f1 = soup.find('a',title='a') #根据title的值来找到对应标签对象
print(f1)
f1 = soup.find('img',class_="a1") #根据class 来找 ,但是这里的class要加_ ,因为原本python是存在class的
print(f1)
findall
#findall
print(soup.find_all('a')) #返回列表
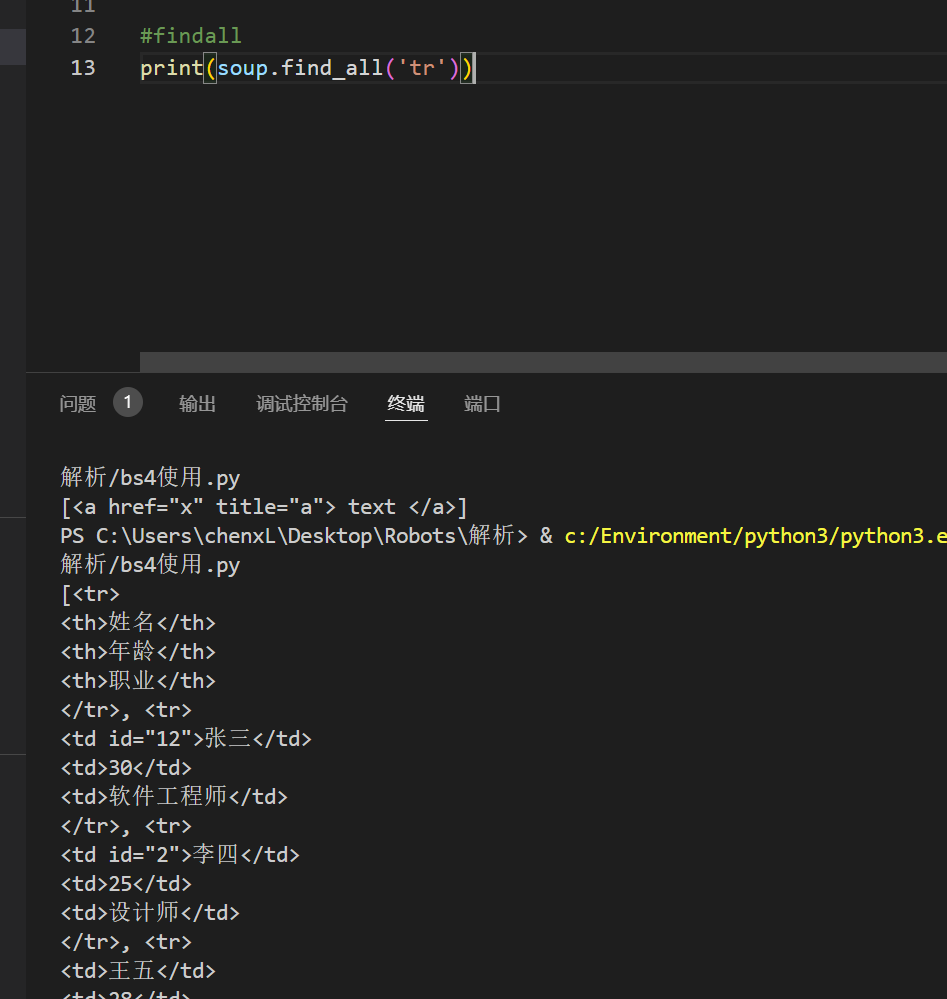
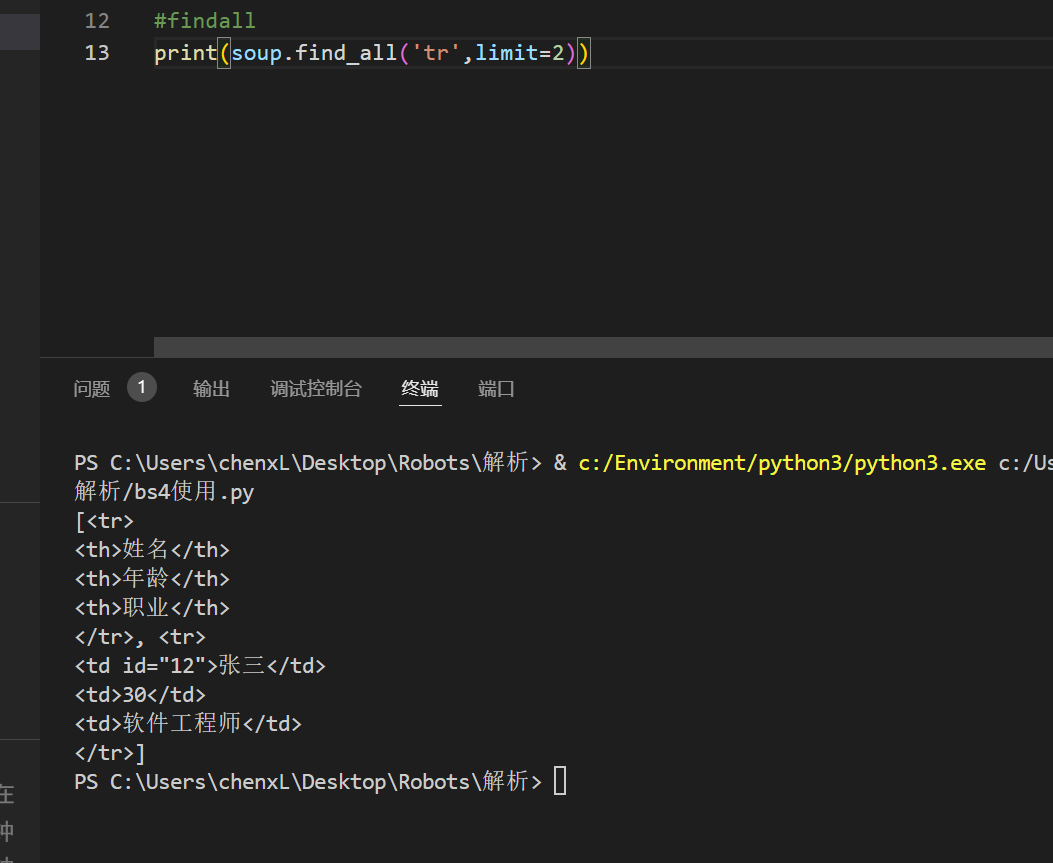
添加 Limit 是选择前几个
#findall
print(soup.find_all('tr',limit=2))
select
#select
print(soup.select('a'))
#返回一个列表 ,并且返回多个数据
属性选择器
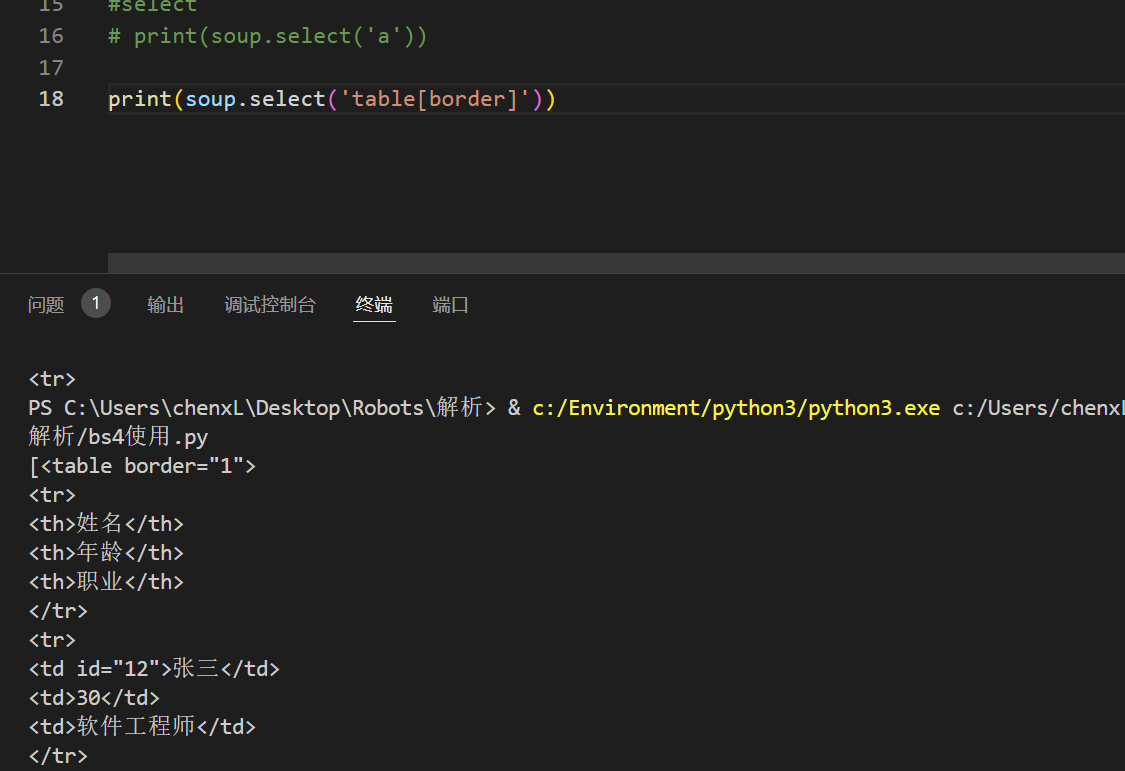
print(soup.select('table[border]'))
print(soup.select('td[id="12"]'))
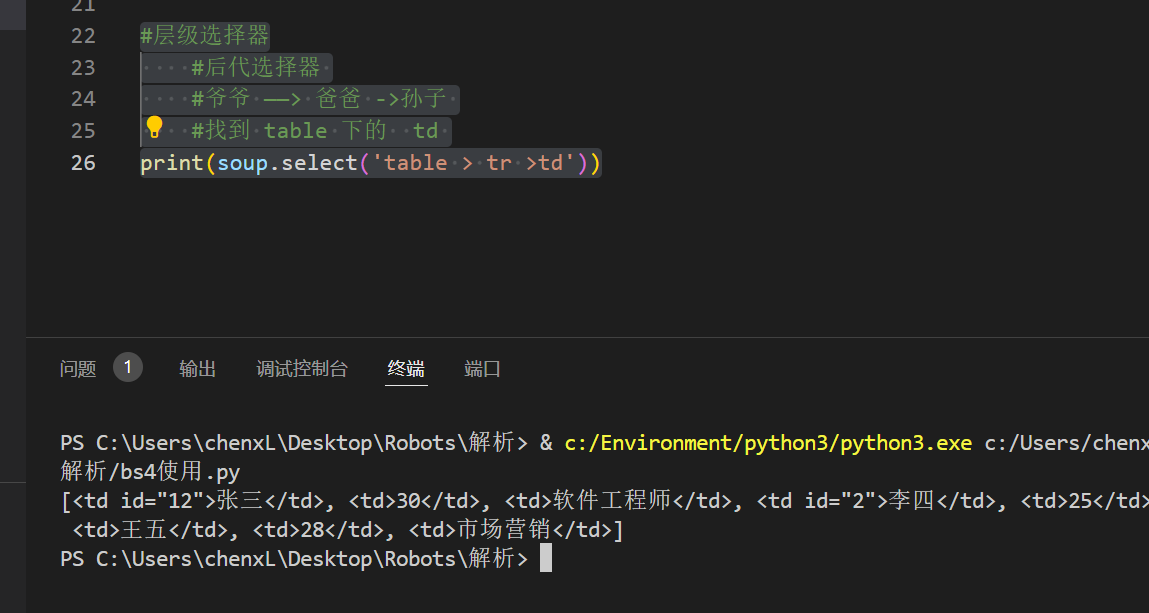
层级选择器
#层级选择器
#后代选择器
#爷爷 ——> 爸爸 ->孙子
#找到 table 下的 td
print(soup.select('table th '))
#子代选择器
print(soup.select('table > tr >td'))
组合标签
print(soup.select('a,th'))

节点信息
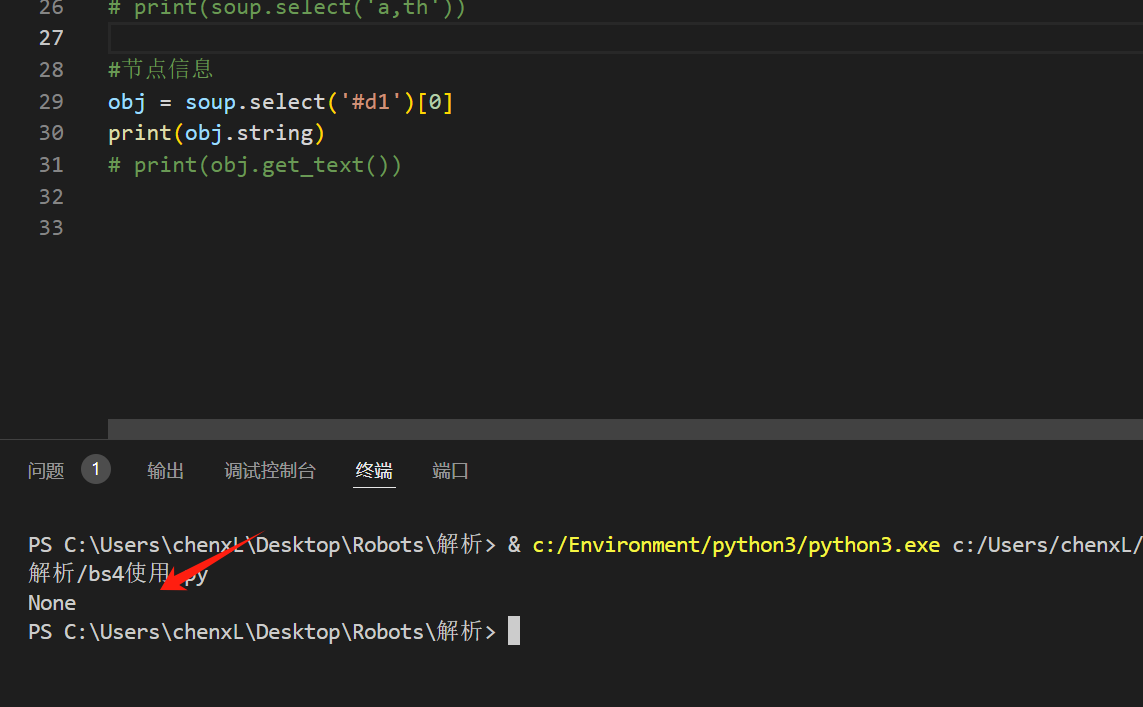
如果标签里面还有标签就会输出None
如果标签里面只有内容可以使用,string方法
如果有标签有内容,也可以使用 get_text()
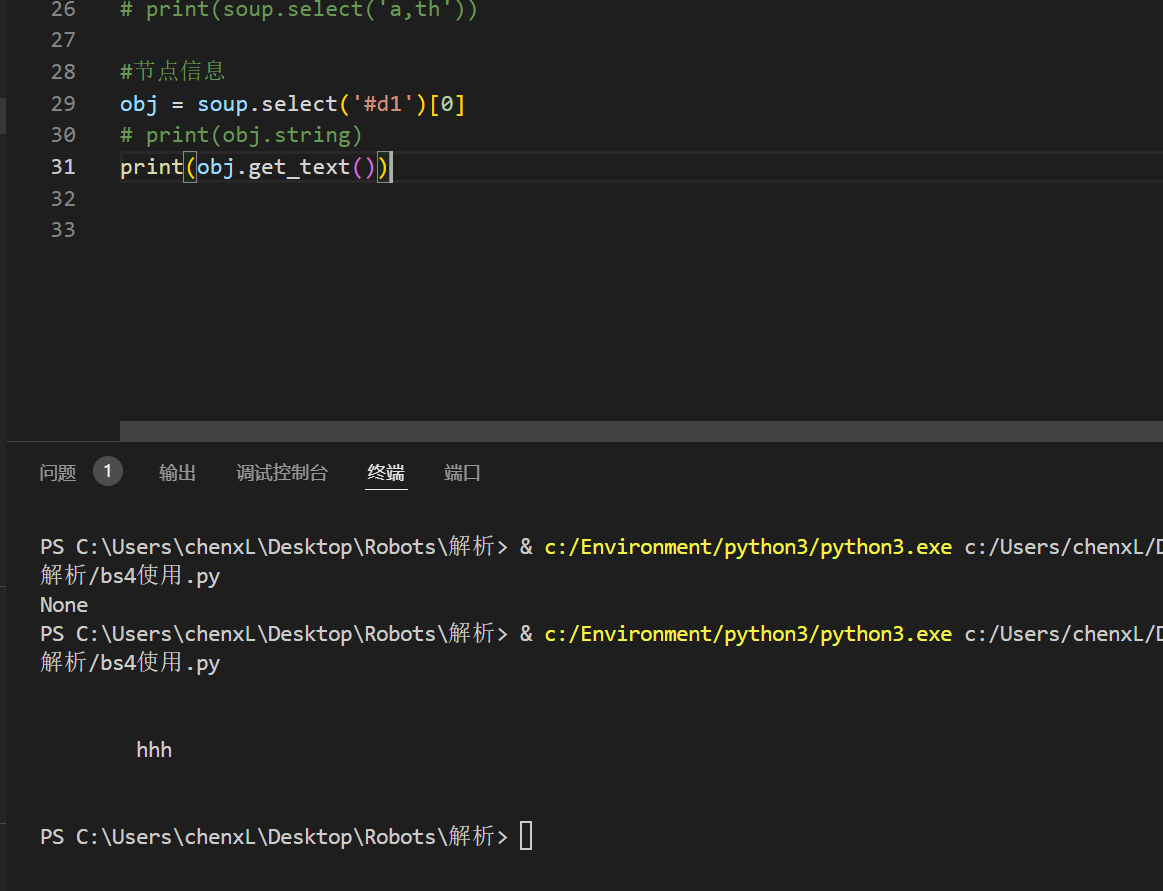
节点属性
<div id="d1" title="1">
<span>
hhh
</span>
#节点属性
obj = soup.select('#d1')[0]
print(obj.attrs.get('title'))
print(obj.get('title'))
print(obj['title'])















 2924
2924

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









