







计算pi值的方法有很多,本文用的是蒙特卡洛模拟法,并且使用mpi并行化加速之。
蒙特卡罗模拟是一种计算方法,使用随机采样和迭代计算来估计复杂系统的行为或导出问题的解决方案。蒙特卡洛方法以摩纳哥著名的蒙特卡洛赌场命名,围绕着概率和偶然性原理。其基本思想是通过改变输入参数并检查结果输出来执行多次随机试验。分析大量迭代的结果有助于确定模式、概率和期望值。
然而蒙特卡罗模拟可能需要大量的计算资源,因为需要大量的迭代才能获得准确的结果,同时当模拟次数过多时所需要的时间也是很多的,针对进行大模拟量时时间过多的缺点,我们可以采用并行化的方式以克服部分。
消息传递接口(MPI)是一种用于高性能计算(HPC)中并行化的标准化通信协议。它允许开发能够在多个处理器或分布式计算机集群上运行的并行应用程序。MPI提供了一个函数库,用于在并发执行的多个进程之间交换消息和数据,使它们能够在解决复杂问题时进行协作。它被广泛用于科学研究、工程模拟和数据密集型应用,有助于显著提高计算性能和减少处理时间。
下面程序的实现我们需要下载MicrosoftMPI,点击此处下载。
下载mpi4py包,在终端使用命令pip install mpi4py。
此处计算pi的基本思想是在-1到1之间取两个数,也就是平面上一个点的坐标(a,b),如果该点位于圆之内,也就是,那么计数器count加1。最后pi就等于(count/n)*4。
from mpi4py import MPI
import random
import math
import time
comm = MPI.COMM_WORLD
rank = comm.Get_rank() # 获得线程号
size = comm.Get_size() # 获得进程数
random.seed(0)
count = 0
n = 10000000 # 模拟次数
# 分配任务
normal_man = n // size # 其他进程任务大小
zero_man = n - normal_man * (size - 1) #主进程任务大小
t0 = time.time()
#所有进程开始模拟
if rank == 0:
for i in range(zero_man):
a = 2*random.random()-1
b = 2*random.random()-1
if a**2+b**2 <= 1:
count += 1
else:
for i in range(normal_man):
a = 2*random.random()-1
b = 2*random.random()-1
if a**2+b**2 <= 1:
count += 1
comm.send(count, dest=0)
# 主进程汇总结果
if rank == 0:
for j in range(1, size): # 主进程接受其他进程的结果
count_out = comm.recv(source=j)
count += count_out
t_b = time.time() - t0
p_i = count / n * 4 # 计算pi值
rel_error = abs(1 - p_i / math.pi)
print('{:.2e}次模拟下pi的模拟值为:{:.10f},相对误差为:{:.10f}'.format(n, p_i, rel_error))
# 开始串行
t0 = time.time()
count = 0
for i in range(n):
a = 2*random.random()-1
b = 2*random.random()-1
if a**2+b**2 <= 1:
count += 1
t_c = time.time() - t0
p_i = count / n * 4
print('{:.2e}次模拟下pi的模拟值为:{:.10f},相对误差为:{:.10f}'.format(n, p_i, rel_error))
print('并行耗时:{}'.format(t_b))
print('串行耗时:{}'.format(t_c))
print('加速比{}'.format(t_c/t_b))
print('效率{}'.format(t_c / t_b/size))打开终端将文件路径cd到文件所在的路径,之后输入:
mpiexec -np 8 python figure_pi.py上面的数字表示要开的进程数,最后一个是文件名字,例如模拟次数一千万次,进程数开8个,结果如下:
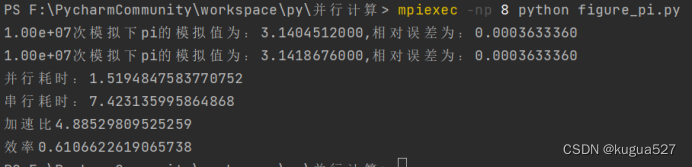
注意并行效率是不可能到达1的,因为进程之间交流需要一定时间,有时候进程数太多,进程之间交流次数过多效率会很低。














 1051
1051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









