






前一篇文章我们介绍了如何学习C语言基础,这一片文章主要是在这基础上进一步介绍C语言的学习历程与一部分的Linux-C的学习。
嵌入式操作系统与Linux
嵌入式操作系统
要学习Linux-C,我们首先要了解的就是什么是嵌入式操作系统。
Linux
Linux是一种自由和开放源代码的操作系统。它最初是由芬兰的林纳斯·托瓦兹(Linus Torvalds)在1991年创建的,并且现在由全球范围内的开发者共同维护和开发。Linux系统基于UNIX操作系统,并以其稳定性、安全性和可定制性而闻名。
Linux操作系统适用于各种设备,包括个人计算机、服务器、移动设备和嵌入式系统。它支持多种硬件架构,如x86、ARM和PowerPC等。许多大型互联网公司和组织使用Linux作为他们的服务器操作系统,因为它具有高度的稳定性和安全性。
Linux操作系统有许多不同的发行版,最流行的包括Ubuntu、Debian、Fedora、CentOS和Red Hat等。每个发行版都有自己的特点和软件包管理系统,用户可以根据自己的需求选择适合自己的发行版。
Linux操作系统具有强大的命令行界面和丰富的命令行工具,这使得它在系统管理和网络管理方面非常受欢迎。同时,Linux也支持图形用户界面,用户可以通过可视化的方式操作系统。
总之,Linux是一种强大、灵活和自由的操作系统,它在各种领域都有广泛的应用。它的开放源代码和活跃的开发社区使得它不断发展和改进,成为了世界上最受欢迎的操作系统之一。
上面说到,Linux有多种流行的版本,而其中一个非常出名的便是本文作者初学时所使用的版本——Ubuntu。
Ubuntu
Ubuntu是基于Linux内核的一种操作系统,它是最受欢迎的Linux发行版之一。Ubuntu的目标是提供一个易于使用、稳定可靠的操作系统,适用于个人计算机、服务器和云平台等各种场景。
Ubuntu的特点之一是它的用户友好性。它提供了直观的图形用户界面,使得用户可以轻松地进行日常任务,如浏览网页、发送电子邮件、编辑文档等。它还内置了许多常用的应用程序,如Web浏览器、办公套件、媒体播放器等,以满足用户的基本需求。
Ubuntu还注重安全性和稳定性。它提供了强大的安全功能和更新机制,以保护用户的系统免受恶意软件和攻击。同时,Ubuntu也经过广泛的测试和开发者社区的支持,以确保系统的稳定性和可靠性。
另一个值得一提的是,Ubuntu是一个开放源代码的发行版。这意味着用户可以自由地查看、修改和分发Ubuntu的源代码。它也鼓励用户参与到开发社区中,为系统的改进和演进做出贡献。
最后,Ubuntu还提供了丰富的软件包管理系统,使用户可以方便地安装、升级和管理软件。用户可以通过Ubuntu软件中心或命令行工具来获取和安装各种应用程序。
总的来说,Ubuntu是一种功能强大、易于使用和稳定可靠的Linux发行版。它在个人计算机、服务器和云平台等场景中广泛应用,并得到了全球用户的认可和喜爱。
当然,你也可以通过一下的链接进入Ubuntu的官网进行下载:
Linux操作系统的使用
Linux系统的使用,最重要的就是了解Shell命令。
Shell命令是在Linux系统中使用Shell解释器执行的命令行指令。Shell命令可用于执行各种系统操作、管理文件和目录、启动和停止进程、设置环境变量等。
以下是一些常用的Shell命令及其功能:
- ls:列出当前目录下的文件和子目录。
- cd:切换当前工作目录。
- pwd:显示当前工作目录的路径。
- mkdir:创建新的目录。
- rm:删除文件或目录。
- cp:复制文件或目录。
- mv:移动或重命名文件或目录。
- touch:创建新的空文件或更改文件的访问和修改时间。
- cat:显示文件内容。
- grep:在文件中搜索指定的模式或字符串。
- echo:将文本输出到屏幕或文件。
- chmod:改变文件或目录的权限。
- chown:改变文件或目录的所有者。
- ps:显示当前运行的进程。
- kill:终止指定进程。
- top:实时显示系统的进程状态和资源使用情况。
- ifconfig:显示和配置网络接口。
- ping:测试与另一个主机的网络连通性。
- ssh:通过安全的远程连接登录到另一台计算机。
- man:查看命令的帮助文档。
这只是一小部分常用的Shell命令,Linux系统提供了大量的命令和工具,可以满足不同的需求。用户可以使用命令行工具或Shell脚本来组合和执行这些命令,实现各种任务和操作。
shell命令的三要素:
命令名称 [ 选项 ] [ 参数 ]
Linux命令
当谈到常用的Linux命令时,以下是一些常见的命令及其功能的简要介绍和解释:
-
ls:用于列出当前目录下的文件和子目录。可以使用-l选项以长格式显示详细信息。
-
cd:用于切换当前工作目录。可以使用cd命令进入到指定的目录,例如cd /home/user。
-
pwd:显示当前工作目录的路径。
-
mkdir:创建新的目录。可以使用mkdir命令创建一个新的目录,例如mkdir new_directory。
-
rm:用于删除文件或目录。使用rm命令可以删除指定的文件或目录,例如rm file.txt或rm -r directory。
-
cp:用于复制文件或目录。可以使用cp命令将文件或目录复制到指定的位置,例如cp file.txt /home/user。
-
mv:用于移动或重命名文件或目录。mv命令可以移动文件或目录到新的位置,或者重命名文件或目录,例如mv file.txt /home/user或mv old_name new_name。
-
touch:用于创建新的空文件或更改文件的访问和修改时间。使用touch命令可以创建一个新的空文件,或者更改已有文件的访问和修改时间,例如touch file.txt。
-
cat:用于显示文件内容。cat命令用于显示文件的内容,例如cat file.txt。
-
grep:用于在文件中搜索指定的模式或字符串。grep命令可以在文件中查找包含指定模式或字符串的行,例如grep "pattern" file.txt。
-
echo:将文本输出到屏幕或文件。echo命令用于将指定的文本输出到屏幕或文件,例如echo "Hello, World!"。
-
chmod:用于改变文件或目录的权限。chmod命令可以更改文件或目录的权限,例如chmod 755 file.txt。
-
chown:用于改变文件或目录的所有者。chown命令可以更改文件或目录的所有者,例如chown user file.txt。
-
ps:用于显示当前运行的进程。ps命令可以显示当前系统中正在运行的进程的列表,例如ps aux。
-
kill:用于终止指定进程。kill命令用于向指定的进程发送终止信号,例如kill PID。
这些命令只是Linux命令的一小部分,Linux系统提供了许多其他命令和工具,用于各种系统管理、文件操作、网络配置和进程控制等任务。用户可以根据需要使用适当的命令来完成特定的操作。
Linux网络配置
测试虚拟机是否有网 (ping):
ping www.baidu.com
如何设置虚拟机的网络:
1.点击虚拟机左上角:编辑--虚拟网络编辑器--更改设置--这里建议设置为桥接模式
2.点击虚拟机左上角:虚拟机--设置--网络适配器--桥接模式
3.重启虚拟机
Linux软件管理
1.离线安装
sudo dpkg -i 软件名.deb
2.apt高级软件包管理工具
sudo apt-get install vim #安装
sudo apt-get update #下载更新软件包列表
sudo apt-get install openssh-server #安装
sudo apt-get remove openssh-server #卸载
VIM编译器
什么是vim编译器
Vim是一种功能强大的文本编辑器,广泛用于Linux系统和其他类Unix系统中。以下是对Vim编辑器的介绍:
-
模式切换:Vim具有多种模式,包括命令模式、插入模式和可视模式。初始状态是命令模式,可以使用各种命令来操作文件。按下i键可以进入插入模式,可以输入和编辑文本。按下Esc键可以退出插入模式,回到命令模式。可视模式允许选择和操作文本块。
-
命令操作:在命令模式下,可以使用各种命令操作文本文件。例如,使用:w保存文件,:q退出Vim,:wq保存并退出。
-
文本编辑:在插入模式下,可以自由编辑文本。包括插入、删除、复制、粘贴、撤销等操作。例如,按下dd删除整行,按下yy复制整行,按下p粘贴。
-
搜索和替换:在命令模式下,可以使用/或?命令来搜索文本。例如,/keyword将搜索关键字,n键可以找到下一个匹配项。使用:%s/old/new/g命令来替换文本中的所有匹配项。
-
多窗口和分屏:Vim支持在一个窗口中打开多个文件,并且可以进行分屏显示。可以使用:split命令垂直分屏,:vsplit命令水平分屏,Ctrl+w+w在不同窗口之间切换。
-
定制和插件:Vim可以通过配置文件.vimrc进行个性化定制,例如设置键盘映射、语法高亮、自动补全等。同时,Vim还支持各种插件,可以增强其功能和扩展性。
Vim是一个高度可定制和功能丰富的文本编辑器,虽然刚开始使用可能需要一些时间适应其独特的操作方式,但一旦熟悉并掌握了一些常用的命令和技巧,它将成为一个非常强大和高效的编辑工具。
vim常用指令
当使用Vim编辑器时,以下是一些常用的指令:
- 模式切换:
- i:进入插入模式,在光标前插入文本。
- Esc:退出插入模式,返回命令模式。
- 光标移动:
- h、j、k、l:分别向左、下、上、右移动光标。
- w、b:按单词前后移动光标。
- gg、G:跳转到文件的开头和结尾。
- Ctrl + f、Ctrl + b:向前翻页和向后翻页。
- :行号:跳转到指定行。
- 文本编辑:
- x:删除光标所在位置的字符。
- dd:删除整行。
- yy:复制整行。
- p:粘贴复制或删除的内容。
- u:撤销上一次操作。
- 搜索和替换:
- /关键字:向下搜索关键字。
- ?关键字:向上搜索关键字。
- n:跳转到下一个匹配项。
- :%s/old/new/g:替换文件中所有匹配的字符串。
- 文件操作:
- :w:保存文件。
- :q:退出Vim。
- :wq:保存并退出。
- :e 文件名:打开指定文件。
- :sp 文件名:在一个新的水平分割窗口中打开指定文件。
- :vsp 文件名:在一个新的垂直分割窗口中打开指定文件。
- :bn、:bp:切换到下一个或上一个缓冲区。
- 分屏操作:
- :split:垂直分屏。
- :vsplit:水平分屏。
- Ctrl + w + w:在不同窗口之间切换。
这只是Vim编辑器中的一些常用指令,还有很多其他的功能和操作。通过逐渐熟悉和掌握这些指令,您将能够更高效地使用Vim编辑器进行文本编辑和操作。
GCC编译器
什么是GCC编译器
GCC(GNU Compiler Collection)是一套由GNU开发的编译器集合,用于编译和链接源代码。它是Linux系统中最常用的编译器之一,支持多种编程语言,包括C、C++、Objective-C、Fortran、Ada等。
以下是对GCC编译器的介绍:
- 编译过程:GCC编译器将源代码转换成可执行文件的过程分为四个阶段:预处理、编译、汇编和链接。
-
预处理:在预处理阶段,GCC会根据源代码中的预处理指令(如#include、#define等)展开代码,并去除注释等不必要的内容,生成一个经过预处理的源代码文件。
-
编译:在编译阶段,GCC将预处理的源代码转换为汇编代码,使用特定的编译选项和优化选项进行处理。
-
汇编:在汇编阶段,GCC将汇编代码转换为机器代码,生成一个目标文件(通常是以.o为扩展名)。
-
链接:在链接阶段,GCC将目标文件与需要的库文件进行链接,生成最终的可执行文件。
-
编译选项:GCC编译器提供了许多编译选项,用于控制编译过程和生成的代码。例如,-c选项用于只编译源代码而不进行链接,-o选项用于指定生成的可执行文件名,-O选项用于开启优化等。
-
调试支持:GCC编译器支持调试功能,可以通过在编译过程中使用-g选项生成调试信息,以便在调试器中进行源代码级别的调试。
-
多语言支持:GCC编译器不仅支持C和C++,还支持其他语言,如Objective-C、Fortran、Ada等。对于不同的语言,可以使用相应的编译选项来进行编译。
-
扩展性和移植性:GCC是一个开源的编译器,具有良好的扩展性和移植性。它可以在多种操作系统下运行,包括Linux、Windows、macOS等,同时也支持多种硬件架构。
GCC编译器是Linux系统中广泛使用的编译器之一,它具有丰富的功能和灵活的选项,可以满足不同编程需求,并且支持多种编程语言。无论是开发系统级应用还是编写应用程序,GCC编译器都是一个强大的工具。
GCC常用指令:
当使用GCC编译器时,以下是一些常用的指令:
1. 编译和链接:
- gcc file.c:将C源代码文件file.c编译为可执行文件a.out。
- gcc file.c -o output:将C源代码文件file.c编译为可执行文件output。
- gcc file1.c file2.c -o output:将多个C源代码文件编译为可执行文件output。
- gcc -c file.c:将C源代码文件编译为目标文件file.o,不进行链接。
2. 编译选项:
- -Wall:显示所有警告信息。
- -Werror:将警告作为错误处理。
- -O0、-O1、-O2、-O3:设置不同级别的优化选项。
- -g:生成调试信息。
- -I<dir>:指定头文件搜索路径。
- -L<dir>:指定库文件搜索路径。
- -l<library>:链接指定的库文件。
3. 链接选项:
- -lm:链接数学库。
- -lpthread:链接线程库。
- -ldl:链接动态链接库。
- -static:静态链接,生成独立的可执行文件。
- -shared:生成共享库。
4. 调试:
- gdb executable:启动GNU调试器,加载可执行文件进行调试。
- break function:在指定函数处设置断点。
- run:运行程序。
- print variable:打印变量的值。
- next:单步执行一行代码。
- quit:退出调试器。
5. 优化:
- gcc -O1 file.c -o output:使用级别1的优化进行编译。
- gcc -O2 file.c -o output:使用级别2的优化进行编译。
- gcc -O3 file.c -o output:使用级别3的优化进行编译。
6. 静态分析:
- gcc -Wall -Wextra -o output file.c:进行静态分析,显示所有警告信息。
以上是GCC编译器的一些常用指令,使用这些指令可以进行编译、链接、调试和优化等操作。通过逐渐熟悉和掌握这些指令,将能够更好地使用GCC编译器进行代码开发和调试。
使用GCC调试C语言
GCC编译C语言时通常分为四个阶段,每个阶段都有不同的功能和处理过程:
1. 预处理阶段(Preprocessing stage):
在预处理阶段,GCC会对源代码进行处理,主要完成以下任务:
- 处理以"#"开头的预处理指令,如#include、#define等,将它们展开或替换为相应的内容。
- 去除注释,包括单行注释(//)和多行注释(/* ... */)。
- 处理条件编译指令,如#ifdef、#ifndef、#if、#elif、#else、#endif等。
预处理阶段的输出结果是一个经过预处理的源代码文件,它是接下来编译阶段的输入。
2. 编译阶段(Compilation stage):
在编译阶段,GCC将预处理后的源代码转换为汇编代码,主要完成以下任务:
- 对每个源文件进行词法分析和语法分析,生成抽象语法树(AST)。
- 进行语义分析,检查代码的语法和语义错误。
- 生成中间代码,通常是一种称为GIMPLE的中间表示形式。
编译阶段的输出结果是一个或多个目标文件,通常以.o作为扩展名。
3. 汇编阶段(Assembly stage):
在汇编阶段,GCC将目标文件转换为机器代码,主要完成以下任务:
- 将中间代码转换为汇编代码,使用特定的目标机器指令表示。
- 为每个汇编代码生成相应的机器指令。
- 生成与目标机器相关的调试信息。
汇编阶段的输出结果是一个或多个汇编文件,通常以.s作为扩展名。
4. 链接阶段(Linking stage):
在链接阶段,GCC将汇编文件和所需的库文件进行链接,生成最终的可执行文件,主要完成以下任务:
- 将各个目标文件合并为一个可执行文件。
- 解析和处理函数和变量的引用和定义。
- 处理库文件的链接,包括静态库和动态库。
- 生成可执行文件的入口点和相关的链接信息。
链接阶段的输出结果是一个可执行文件,它可以在特定的操作系统和硬件上运行。
这些阶段的顺序和执行过程是GCC编译器内部自动完成的,对于开发者而言,只需使用gcc命令对源代码进行编译即可。
在使用GCC编译C语言时,我们可以通过以下命令控制每个阶段的执行:
1. 预处理阶段:
在执行预处理阶段时,可以使用以下命令:
gcc -E file.c
对源代码文件file.c进行预处理,并将输出结果打印到标准输出。
2. 编译阶段:
在执行编译阶段时,可以使用以下命令:
gcc -S file.c
对源代码文件file.c进行编译,生成汇编代码文件file.s。
3. 汇编阶段:
在执行汇编阶段时,可以使用以下命令:
gcc -c file.s
对汇编代码文件file.s进行汇编,生成目标文件file.o。
4. 链接阶段:
在执行链接阶段时,可以使用以下命令:
gcc file1.o file2.o -o output
将多个目标文件file1.o、file2.o进行链接,生成可执行文件output。
在实际编译过程中,可以将这些命令进行组合使用,例如:
- gcc -E file.c -o file.i:执行预处理阶段,并将输出结果保存为file.i。
- gcc -S file.i -o file.s:执行编译阶段,并将输出结果保存为file.s。
- gcc -c file.s -o file.o:执行汇编阶段,并将输出结果保存为file.o。
- gcc file.o -o output:执行链接阶段,生成可执行文件output。
此外,GCC还提供了一些其他的编译选项和参数,用于控制编译过程的各个方面。可以通过查阅GCC的官方文档或使用gcc --help命令来获取更详细的信息和使用说明。
shell编程
什么shell编程
在Linux系统中,Shell是用户与操作系统之间进行交互的接口。它是一种命令行解释器,用于解释和执行用户输入的命令。Shell还可以执行脚本,自动化一系列命令的执行。
Linux系统中最常用的Shell是Bash(Bourne Again SHell),它是Bourne Shell的增强版本。Bash提供了丰富的功能和命令,使用户能够更有效地管理和操作系统。
Shell提供了一些基本的功能,如命令解释、变量定义和赋值、条件判断、循环控制等。通过Shell,用户可以执行各种系统命令、管理文件和目录、启动和停止进程、设置环境变量等。
Shell还支持通配符扩展和管道操作,这使得用户可以方便地处理和操作文件。例如,使用通配符可以快速匹配一组文件;而管道操作可以将多个命令连接起来,实现数据的流动和处理。
此外,Shell还支持脚本编程。用户可以将一系列命令写入脚本文件中,并通过Shell解释器执行。这样可以实现自动化任务,提高工作效率。
除了Bash,Linux系统还有其他的Shell可供选择,如C Shell(csh)、Korn Shell(ksh)等。每种Shell都有其特定的功能和语法,用户可以根据自己的需求选择合适的Shell。
总的来说,Shell是Linux系统中与用户交互的界面,它提供了命令解释、脚本执行、文件操作等功能。通过Shell,用户可以方便地管理和操作系统,实现各种任务和自动化操作。
如何进行shell编程
在Ubuntu中,shell编程是通过编写Shell脚本来实现的。下面是一些常见的规则和示例:
- 文件头部声明: Shell脚本的第一行通常是指定要使用的Shell解释器,常见的是#!/bin/bash,表示使用bash作为解释器。
示例:
#!/bin/bash
- 注释: 可以使用#符号来添加注释,注释内容将被忽略。
# 这是一个示例注释
- 变量声明和使用: 变量名不需要事先声明,直接赋值即可。使用时在变量名前面加上$符号。
name="John" echo "My name is $name" - 输入输出: 通过echo命令输出内容到终端,使用read命令获取用户输入。
echo "What is your name?" read name echo "Hello, $name!" - 条件判断: 使用if语句进行条件判断,语法为if condition then ... fi。
if [ $num -gt 10 ]; then echo "The number is greater than 10" fi
Linux-C
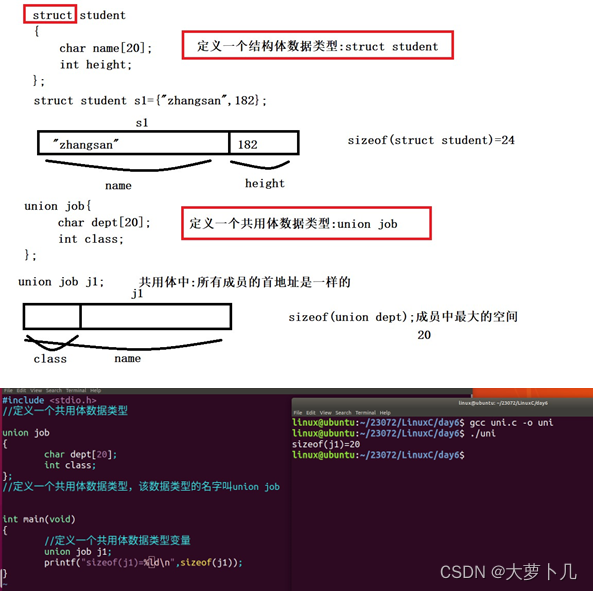
结构体
在编程中,结构体(Struct)是一种用户自定义的数据类型,用于组合多个不同类型的变量。它允许我们将一组相关的数据组织在一起,方便管理和操作。下面是结构体的解释和一个示例:
结构体的定义: 结构体定义使用关键字struct,通过指定成员变量的数据类型和名称来定义。
如何创建结构体数据类型
//定义结构体语句 struct 结构体名字 { 属性1; 属性2; 属性3; ....... };
struct Person {
char name[20];
int age;
float height;
};
结构体的使用
定义结构体后,我们可以声明结构体变量并访问其成员变量。
#include <stdio.h>
int main() {
struct Person person1; // 声明一个Person类型的变量
strcpy(person1.name, "John"); // 赋值给成员变量name
person1.age = 25; // 赋值给成员变量age
person1.height = 1.75; // 赋值给成员变量height
printf("Name: %s\n", person1.name); // 访问并打印成员变量name
printf("Age: %d\n", person1.age); // 访问并打印成员变量age
printf("Height: %.2f\n", person1.height); // 访问并打印成员变量height
return 0;
}
输出结果:
Name: John
Age: 25
Height: 1.75
结构体可以包含不同类型的成员变量,我们可以根据需要定义和使用结构体。通过结构体,可以更好地组织和管理相关的数据,提高代码的可读性和可维护性。在实际编程中,结构体常用于表示复杂的数据结构、定义数据模型等场景。
如何操作结构体的指针
在C语言中,可以使用指针来操作结构体。通过结构体指针,我们可以访问结构体的成员变量,并进行修改或者引用。下面是一个解释和示例:
- 定义结构体指针: 可以使用结构体类型后面加上*来定义结构体指针变量。
struct Person { char name[20]; int age; float height; }; struct Person *personPtr; // 定义一个指向Person结构体的指针- 通过指针访问结构体成员: 使用箭头操作符(->)来访问结构体指针所指向的结构体的成员变量。
struct Person person1; personPtr = &person1; // 将personPtr指向person1 strcpy(personPtr->name, "John"); // 通过指针访问成员变量name personPtr->age = 25; // 通过指针访问成员变量age personPtr->height = 1.75; // 通过指针访问成员变量height- 结构体指针作为函数参数: 可以将结构体指针作为函数参数传递,以便在函数内部对结构体进行修改。
输出结果:void updatePerson(struct Person *person) { strcpy(person->name, "Alice"); person->age = 30; person->height = 1.65; } int main() { struct Person person1; struct Person *personPtr = &person1; updatePerson(personPtr); // 将结构体指针传递给函数 printf("Name: %s\n", person1.name); printf("Age: %d\n", person1.age); printf("Height: %.2f\n", person1.height); return 0; }
Name: Alice
Age: 30
Height: 1.65
- 通过结构体指针,可以方便地访问和修改结构体的成员变量。结构体指针在函数传递和动态内存分配等场景中也非常有用。但需要注意,在使用结构体指针之前,要确保该指针指向了一个已经分配好内存的结构体。
内存管理
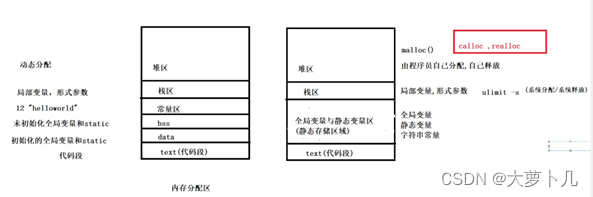
在堆区分配空间和释放空间
分配空间
#include <stdlib.h>
//参数:你要分配空间的大小
//返回值:void * void (表示空) void * (任何数据类型的地址)
//分配成功返回空间的首地址,失败则返回NULL
//malloc分配的空间未进行清空
void *malloc(size_t size);释放空间
#include <stdlib.h>
//参数1:释放空间的首地址
void free(void *ptr);结构体和堆区空间关联起来
#include <stdio.h>
#include <stdlib.h>
#define N 20
#define M 3
#define SIZE 5
//该句话是前两句话的简化
typedef struct student
{
char name[N];
int height;
float scores[M];
}Stu;
int main(void)
{
Stu * ps=NULL;
//1.分配空间
//再堆区创建5个存结构体的空间
ps=(Stu *)malloc(sizeof(Stu)*SIZE);
//2.出错判断
if(NULL==ps)
{
perror("malloc error");
return -1;
}
//3.释放
free(ps);
ps=NULL;
return 0;
}
自定义头文件
1.自定义头文件的要求.h
<1>.引入库头文件
<2>.宏定义
<3>.结构体类型的定义
<4>.枚举类型的定义
<5>.函数声明
2.如何引入自定义头文件
#include <stdio.h>//定义库头文件使用<>引入
#include "stu.h"//定义头文件使用" "引入
3." " 和<>的区别
“”和<>的区别
" ":编译器从用户的工作路径开始搜索头文件
<>: 编译器从标准库路径开始搜索头文件
4.条件编译
1.作用:避免头文件被重复引入
2.语法
#ifndef 标识符 (一般和文件名同名并大写)
#define 标识符
//<1>.引入库头文件
//<2>.宏定义
//<3>.结构体类型的定义//<4>.枚举类型的定义
//<5>.函数声明
#endif
Make工程管理器 (多文件编译)
什么是makefile
Makefile是一种用于构建和管理项目的工具。它的工作原理是通过规则和依赖关系来确定哪些文件需要被重新编译,从而实现自动化构建。
Makefile由一系列规则组成,每个规则包含一个目标文件、依赖文件和一系列命令。当目标文件不存在或者依赖文件的时间戳较新时,Makefile会执行相应的命令来生成目标文件。
下面是一个简单的示例Makefile,假设有两个源文件hello.c和world.c,以及一个头文件hello.h:
CC = gcc
CFLAGS = -Wallhello: hello.o world.o
$(CC) $(CFLAGS) -o hello hello.o world.ohello.o: hello.c hello.h
$(CC) $(CFLAGS) -c hello.cworld.o: world.c hello.h
$(CC) $(CFLAGS) -c world.c
在这个示例中,我们定义了编译器CC为gcc,并指定了编译选项CFLAGS为-Wall(开启所有警告)。然后我们定义了三个规则:hello、hello.o和world.o。
规则hello依赖hello.o和world.o,当hello.o和world.o的时间戳较新时,Makefile会执行命令来生成目标文件hello。命令中的(CC)(CC)(CFLAGS) -o hello hello.o world.o表示使用gcc编译器将hello.o和world.o链接成可执行文件hello。
规则hello.o依赖hello.c和hello.h,当hello.c或hello.h的时间戳较新时,Makefile会执行命令来生成目标文件hello.o。命令中的(CC)(CC)(CFLAGS) -c hello.c表示使用gcc编译器将hello.c编译成目标文件hello.o。
规则world.o同理。
通过使用Makefile,我们可以通过运行make命令来自动化构建项目。make命令会检查每个规则的依赖关系,并根据需要重新编译文件以生成最终的目标文件。在上述示例中,如果我们修改了hello.c文件,运行make命令会重新编译hello.o和hello文件。
makefile中的假目标问题
除了常规的编译操作之外,Makefile还支持一些其他常规操作,如假目标和清理操作。下面是一些常见的示例:
.PHONY: clean test
clean:
rm -f *.o hellotest:
./test_script.sh
在这个示例中,我们定义了两个假目标:clean和test。clean目标用于删除所有的目标文件和可执行文件,test目标用于运行一个测试脚本。通过在命令前面添加.PHONY关键字,我们告诉Makefile这些是假目标而不是实际的文件。
makefile清理操作
清理操作:清理操作用于删除生成的目标文件和可执行文件,以便重新构建项目。
clean:
rm -f *.o hello
makefile中的安装操作
安装操作:安装操作用于将生成的可执行文件或库文件安装到指定的目录中。
install:
mkdir -p /usr/local/bin
cp hello /usr/local/bin
makefile中的调试操作
调试操作:调试操作用于输出一些调试信息,以帮助开发者调试项目。
debug:
@echo "CC: $(CC)"
@echo "CFLAGS: $(CFLAGS)"
Makefile变量
函数指针
什么是函数指针
在C语言中,函数指针是指向函数的指针变量。它可以用于在运行时动态地选择要调用的函数,从而实现函数的灵活调用和多态性。
函数指针的声明通过指定函数的返回类型和参数类型来完成。下面是一个简单的函数指针的声明示例:
int (*sum)(int, int);
在这个示例中,我们声明了一个函数指针sum,它指向一个返回类型为int、参数类型为int和int的函数。
函数指针的相关操作
函数指针的赋值可以将函数的地址赋给函数指针变量。下面是一个示例,演示了如何将函数的地址赋给函数指针:
int add(int a, int b) {
return a + b;
}
int main() {
int (*sum)(int, int);
sum = add;
int result = sum(2, 3); // 调用函数指针
printf("Result: %d\n", result); // 输出:5
return 0;
}
在这个示例中,我们定义了一个add函数,它接受两个整数并返回它们的和。然后,在main函数中,我们声明了一个函数指针sum,并将add函数的地址赋给sum。最后,我们通过sum(2, 3)调用函数指针,并将结果赋给result变量。
函数指针还可以作为函数的参数传递,从而实现回调函数的机制。下面是一个示例,演示了如何将函数指针作为参数传递:
void printResult(int (*operation)(int, int), int a, int b) {
int result = operation(a, b);
printf("Result: %d\n", result);
}
int add(int a, int b) {
return a + b;
}
int subtract(int a, int b) {
return a - b;
}
int main() {
printResult(add, 2, 3); // 输出:5
printResult(subtract, 5, 2); // 输出:3
return 0;
}
在这个示例中,我们定义了一个printResult函数,它接受一个函数指针operation作为参数,并将a和b传递给operation进行计算。在main函数中,我们通过传递add和subtract函数的地址来调用printResult函数,并输出计算结果。
函数指针在C语言中广泛用于回调函数、函数表和动态函数调用等场景,它提供了一种灵活和动态的函数调用方式。
给函数指针取别名
<1>
int (*pfun) (int,int);
int ( *pfunArr[4] ) (int,int )={add,sub,mul,div};
int pfunaction(int (*pfun)(int,int),int num1,int num2)
{
return pfun(num1,num2);
}<2>
//给函数指针取了别名
typedef int (*PFUN) (int,int ); //给函数指针取了别名 int (*) (int,int) ---->PFUN
类型名
int (*pfun) (int,int);
PFUN pfun; 类型名 指针变量名;
int ( *pfunArr[4] ) (int,int )={add,sub,mul,div};
PFUN pfunArr[4]={add,sub,mul,div};
int pfunaction(int (*pfun)(int,int),int num1,int num2)
{
return pfun(num1,num2);
}
int pfunaction(PFUN pfun,int num1,int num2)
{
return pfun(num1,num2);
}未来将会用到函数指针的地方
int pthread_create ( pthread_t * thread , const pthread_attr_t * attr ,void * ( * start_routine ) ( void * ), void * arg );
#include <signal.h>typedef void ( * sighandler_t )( int );sighandler_t signal ( int signum , sighandler_t handler );
存储类型
1.register 寄存器
2.auto (默认)
3.extern 外部的
//show1.c
#include <stdio.h>
int a=10; //全局变量
void show1(void)
{
a+=10;
printf("show1 a=%d\n",a);
}2.extern修饰全局变量
//show2.c
#include <stdio.h>
extern int a; //使用外部变量a
void show2(void)
{
a+=20;
printf("show2 a=%d\n",a);
}3.extern修饰函数
#include <stdio.h>
//extern修饰函数:使用外部的函数
extern void show1(void);
extern void show2(void);
int main(void)
{
show1();
show2();
}4.static 静态的
在C语言中,static关键字具有不同的作用,根据上下文的不同,可以用于以下几种情况:
静态变量
静态变量: 在函数内部声明的静态变量将在程序执行期间保持其值,而不会在函数调用之间丢失。静态变量只能在声明它们的函数内部访问,不能被其他函数访问。
void count() {
static int counter = 0;
counter++;
printf("Counter: %d\n", counter);
}
int main() {
count(); // 输出:Counter: 1
count(); // 输出:Counter: 2
count(); // 输出:Counter: 3
return 0;
}
在上述例子中,我们定义了一个静态变量counter,它在count函数内部声明。每次调用count函数时,counter的值都会递增,并保持在函数调用之间的状态。
静态函数
静态函数: 使用static关键字可以将函数声明为静态函数,这意味着该函数只能在声明它的源文件内部访问,无法被其他源文件调用。
static void printMessage() {
printf("This is a static function.\n");
}
int main() {
printMessage(); // 可以在同一源文件内调用
return 0;
}
在上述例子中,我们将printMessage函数声明为静态函数。这意味着它只能在声明它的源文件内部被调用,无法在其他源文件中调用。
静态全局变量
静态全局变量: 在函数外部声明的静态全局变量具有文件作用域,只能在声明它的源文件内部访问,不能被其他源文件访问。
static int counter = 0;
void incrementCounter() {
counter++;
}
int main() {
incrementCounter();
printf("Counter: %d\n", counter); // 输出:Counter: 1
return 0;
}
在上述例子中,我们在函数外部声明了一个静态全局变量counter。它具有文件作用域,只能在同一源文件内部访问。
static关键字的作用主要是限制变量和函数的作用域,使其只能在特定的范围内访问。这有助于避免命名冲突和提高代码的模块化程度。
共用体
大小端

//测试计算机是大端序还是小端序
#include <stdio.h>
union un
{
int a;
char c;
};
int main(void)
{
union un u1;
u1.a=0x12345678;
if(u1.c==0x78)
{
printf("小端序\n");
}
else
{
printf("大端序\n");
}
return 0;
}枚举:(语义化)定义常量的一种方式
//1. 定义一个枚举的数据类型enum timeDate{MONDAY = 1 , TUESDAY , WEDSDAY , THURSDAY , FRIDAY // 默认是从开始的整数};// 定义一个枚举数据类型 , 该数据类型的名字叫 enum timeDate//2. 定义枚举的变量enum timeDate d1 ;d1 的值可以是 MONDAY , TUESDAY , WEDSDAY , THURSDAY , FRIDAY 任意一个
#include <stdio.h>
//定义一个枚举数据类型
enum timeDate
{
MONDAY=1,TUESDAY,WEDSDAY,THURSDAY,FRIDAY //默认从0开始,后面依次加1
};
int main(void)
{
//定义一个枚举数据变量
int date=0;
enum timeDate d1;
while(1){
printf("请输入时间\n");
scanf("%d",&date);
d1=date;
switch(d1)
{
case MONDAY:
printf("我是周一\n");
break;
case TUESDAY:
printf("我是周二\n");
break;
case WEDSDAY:
printf("我是周三\n");
break;
case THURSDAY:
printf("我是周四\n");
break;
case FRIDAY:
printf("我是周五\n");
break;
default:
printf("我是周末\n");
}
}
}
















 8943
8943

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









