







前言
这篇博客主要是为了记录一下一套完整的深度学习模型的流程,方便以后好copy
代码如下
数据预处理
数据预处理其实比较重要,不过看模型喂入数据的格式就知道应该将数据处理成什么样了,过程肯定仁者见仁,智者见智,这里就不介绍了。
EarlyStopping
这个主要是为了让你训练的时候,能够根据训练结果来决定是否结束训练,如果测试集损失一直在升高,就没必要训练了。
import torch
import numpy as np
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print(device)
class EarlyStopping:
"""Early stops the training if validation loss doesn't improve after a given patience."""
def __init__(self, patience=7, verbose=False, delta=0, name="checkpoint.pt"):
"""
Args:
patience (int): How long to wait after last time validation loss improved.
Default: 7
verbose (bool): If True, prints a message for each validation loss improvement.
Default: False
delta (float): Minimum change in the monitored quantity to qualify as an improvement.
Default: 0
"""
self.patience = patience
self.verbose = verbose
self.counter = 0
self.best_score = None
self.early_stop = False
self.val_loss_min = np.Inf
self.delta = delta
self.name = name
def __call__(self, val_loss, model):
score = -val_loss
if self.best_score is None:
self.best_score = score
self.save_checkpoint(val_loss, model)
elif score < self.best_score + self.delta:
self.counter += 1
print(f'EarlyStopping counter: {self.counter} out of {self.patience}')
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_score = score
self.save_checkpoint(val_loss, model)
self.counter = 0
def save_checkpoint(self, val_loss, model):
'''Saves model when validation loss decrease.'''
if self.verbose:
print(f'Validation loss decreased ({self.val_loss_min:.6f} --> {val_loss:.6f}). Saving model ...')
torch.save(model.state_dict(), './models/' + self.name) # 这里会存储迄今最优模型的参数
self.val_loss_min = val_loss
patience = 7
early_stopping = EarlyStopping(patience, verbose=True, name="R-GAT.pt")
R-GAT模型
这个以前讲过,用的就是异构图卷积,可以参考基于注意力机制的图神经网络且考虑关系的R-GAT的一些理解以及DGL代码实现
但是方面级情感预测,每个句子里的方面可能不止一个词,自己操作一下就好了。
from dgl.nn.pytorch import HeteroGraphConv
import torch
import torch as th
import torch.nn as nn
import torch.nn.functional as F
from dgl import function as fn
from dgl.ops import edge_softmax
from dgl.utils import expand_as_pair
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class GATConv(nn.Module):
def __init__(
self,
in_feats, # 输入的节点特征维度
out_feats, # 输出的节点特征维度
edge_feats, # 输入边的特征维度
num_heads=1, # 注意力头数
feat_drop=0.0, # 节点特征dropout
attn_drop=0.0, # 注意力dropout
edge_drop=0.0, # 边特征dropout
negative_slope=0.2,
activation=None,
allow_zero_in_degree=False,
use_symmetric_norm=False,
):
super(GATConv, self).__init__()
self._num_heads = num_heads
self._in_src_feats, self._in_dst_feats = expand_as_pair(in_feats)
self._out_feats = out_feats
self._allow_zero_in_degree = allow_zero_in_degree
self._use_symmetric_norm = use_symmetric_norm
if isinstance(in_feats, tuple):
self.fc_src = nn.Linear(self._in_src_feats, out_feats * num_heads, bias=False)
self.fc_dst = nn.Linear(self._in_dst_feats, out_feats * num_heads, bias=False)
else:
self.fc = nn.Linear(self._in_src_feats, out_feats * num_heads, bias=False)
self.fc_edge = nn.Linear(edge_feats, out_feats * num_heads, bias=False)
self.attn_l = nn.Parameter(torch.FloatTensor(size=(1, num_heads, out_feats)))
self.attn_edge=nn.Parameter(torch.FloatTensor(size=(1, num_heads, out_feats)))
self.attn_r = nn.Parameter(torch.FloatTensor(size=(1, num_heads, out_feats)))
self.feat_drop = nn.Dropout(feat_drop)
self.attn_drop = nn.Dropout(attn_drop)
self.edge_drop = edge_drop
self.leaky_relu = nn.LeakyReLU(negative_slope)
self.reset_parameters()
self._activation = activation
# 初始化参数
def reset_parameters(self):
gain = nn.init.calculate_gain("relu")
if hasattr(self, "fc"):
nn.init.xavier_normal_(self.fc.weight, gain=gain)
else:
nn.init.xavier_normal_(self.fc_src.weight, gain=gain)
nn.init.xavier_normal_(self.fc_dst.weight, gain=gain)
nn.init.xavier_normal_(self.fc_edge.weight, gain=gain)
nn.init.xavier_normal_(self.attn_l, gain=gain)
nn.init.xavier_normal_(self.attn_r, gain=gain)
nn.init.xavier_normal_(self.attn_edge, gain=gain)
def set_allow_zero_in_degree(self, set_value):
self._allow_zero_in_degree = set_value
def forward(self, graph, feat):
with graph.local_scope():
if not self._allow_zero_in_degree:
if (graph.in_degrees() == 0).any():
assert False
# feat[0]源节点的特征
# feat[1]目标节点的特征
# h_edge 边的特征
h_src = self.feat_drop(feat[0])
h_dst = self.feat_drop(feat[1])
h_edge = self.feat_drop(graph.edata['deprel'])
if not hasattr(self, "fc_src"):
self.fc_src, self.fc_dst = self.fc, self.fc
# 特征赋值
feat_src, feat_dst,feat_edge= h_src, h_dst,h_edge
# 转换成多头注意力的形状
feat_src = self.fc_src(h_src).view(-1, self._num_heads, self._out_feats)
feat_dst = self.fc_dst(h_dst).view(-1, self._num_heads, self._out_feats)
feat_edge = self.fc_edge(h_edge).view(-1, self._num_heads, self._out_feats)
# NOTE: GAT paper uses "first concatenation then linear projection"
# to compute attention scores, while ours is "first projection then
# addition", the two approaches are mathematically equivalent:
# We decompose the weight vector a mentioned in the paper into
# [a_l || a_r], then
# a^T [Wh_i || Wh_j] = a_l Wh_i + a_r Wh_j
# Our implementation is much efficient because we do not need to
# save [Wh_i || Wh_j] on edges, which is not memory-efficient. Plus,
# addition could be optimized with DGL's built-in function u_add_v,
# which further speeds up computation and saves memory footprint.
# 简单来说就是拼接矩阵相乘和拆开分别矩阵相乘再相加的效果是一样的
# 但是前者更加高效
# 左节点的注意力权重
el = (feat_src * self.attn_l).sum(dim=-1).unsqueeze(-1)
graph.srcdata.update({"ft": feat_src, "el": el})
# 右节点的注意力权重
er = (feat_dst * self.attn_r).sum(dim=-1).unsqueeze(-1)
# print("er", er.shape)
graph.dstdata.update({"er": er})
# 左节点权重+右节点权重 = 节点计算出的注意力权重(e)
graph.apply_edges(fn.u_add_v("el", "er", "e"))
# 边计算出来的注意力权重
ee = (feat_edge * self.attn_edge).sum(dim=-1).unsqueeze(-1)
# print("ee", ee.shape)
# 边注意力权重加上节点注意力权重得到最终的注意力权重
# 这里可能应该也是和那个拼接操作等价吧
graph.edata.update({"e": graph.edata["e"]+ee})
# 经过激活函数,一起激活和分别激活可能也是等价吧
e = self.leaky_relu(graph.edata["e"])
# 注意力权重的正则化
if self.training and self.edge_drop > 0:
perm = torch.randperm(graph.number_of_edges(), device=graph.device)
bound = int(graph.number_of_edges() * self.edge_drop)
eids = perm[bound:]
a = torch.zeros_like(e)
a[eids] = self.attn_drop(edge_softmax(graph, e[eids], eids=eids))
graph.edata.update({"a": a})
else:
graph.edata["a"] = self.attn_drop(edge_softmax(graph, e))
# 消息传递
graph.update_all(fn.u_mul_e("ft", "a", "m"), fn.sum("m", "ft"))
rst = graph.dstdata["ft"]
# 标准化
degs = graph.in_degrees().float().clamp(min=1)
norm = torch.pow(degs, -1)
shp = norm.shape + (1,) * (feat_dst.dim() - 1)
norm = torch.reshape(norm, shp)
rst = rst * norm
return rst
class RGAT(nn.Module):
def __init__(
self,
in_feats, # 输入的特征维度 (边和节点一样)
hid_feats, # 隐藏层维度
out_feats, # 输出的维度
num_heads, # 注意力头数
rel_names, # 关系的名称(用于异构图卷积)
rel_feats, # 关系的特征大小
):
super().__init__()
self.conv1 = HeteroGraphConv({rel: GATConv(in_feats, hid_feats // num_heads, rel_feats, num_heads) for rel in rel_names},aggregate='sum')
self.conv2 = HeteroGraphConv({rel: GATConv(hid_feats, out_feats, rel_feats, num_heads) for rel in rel_names},aggregate='sum')
self.hid_feats = hid_feats
def forward(self,graph,inputs):
# graph 输入的异构图
# inputs 输入节点的特征
h = self.conv1(graph, inputs) # 第一层异构卷积
h = {k: F.relu(v).view(-1, self.hid_feats) for k, v in h.items()} # 经过激活函数,将注意力头数拉平
h = self.conv2(graph, h) # 第二层异构卷积
return h
class Model(nn.Module):
def __init__(self, in_features, hidden_features, out_features, num_heads, rel_names, vocab_size, rel_feats, rel_size, num_classes):
super().__init__()
self.rgat = RGAT(in_features, hidden_features, out_features, num_heads, rel_names, rel_feats)
self.embed = nn.Embedding(vocab_size, in_features)
self.dep_embed = nn.Embedding(rel_size, rel_feats)
self.fc = nn.Linear(num_heads * out_features, num_classes)
self.num_heads = num_heads
self.out_features = out_features
def forward(self, g, x):
x = {k: self.embed(v) for k, v in x.items()}
g.edata["deprel"] = self.dep_embed(g.edata["deprel"])
# print(x)
h = self.rgat(g, x)
# 输出的就是每个节点经过R-GAT后的特征
# for k, v in h.items():
# print(k, v.shape)
# 这里就一种关系
h = h["word"].view(-1, self.num_heads * self.out_features)
aspects_words_pos = torch.nonzero(g.ndata["from_to"]!=0).squeeze() # from to 的位置
aspects_num = len(aspects_words_pos) // 2 # aspects方面的个数
aspects_words_h = torch.zeros(aspects_num, self.out_features * self.num_heads) # 方面词的隐藏层,由于一个方面可能不止一个词,采取平均的方式
for i in range(aspects_num):
h_i = h[aspects_words_pos[i*2]:aspects_words_pos[i*2+1]].to(device)
if len(h_i) == 1: # 可能一个词就是方面词
h_i = h_i[0].to(device)
else:
h_i = torch.sum(h_i, axis=0).to(device)
aspects_words_h[i] = h_i.to(device)
return self.fc(aspects_words_h)
模型参数设置
具体含义下面会讲到
batch_size = 4
epochs = 5
lr = 1e-3
vocab_size = 7873
rel_size = 45
in_features = 300
hidden_features = 8
out_features = 300
num_heads = 4
rel_feats = 32
num_classes = 3
assert in_features // (num_heads)
assert rel_feats // (num_heads)
assert hidden_features // (num_heads)
初始化模型和读取数据
g = th.load(r"C:\Users\ASUS\OneDrive\桌面\sentiment_classfication\R-GAT\github_data\MAMS\processed\valid.pt")
model = Model(in_features, # embedding_size
hidden_features, # hidden_size
out_features, # output_size
num_heads, # 注意力头数
g[0].etypes, # 关系
vocab_size, # 字典大小
rel_feats,# 关系的大小rel_embedding_size
rel_size,# 关系的个数
num_classes)# 类别
# print(model)
分batch批量训练
from collections import namedtuple
from torch.utils.data import DataLoader
import numpy as np
DataBatch = namedtuple('SSTBatch', ['graph', 'wordid', 'label', "pos", "tag_word","from_to"])
def batcher(dev):
def batcher_dev(batch):
batch_trees = dgl.batch(batch)
return DataBatch(graph=batch_trees.to(device),
# mask=batch_trees.ndata['mask'].to(device),
wordid=batch_trees.nodes['word'].data['token'].to(device), # 词编号
label=batch_trees.nodes['word'].data['label'].to(device), # 词的标签,无标签为-1
pos=batch_trees.nodes['word'].data['pos'].to(device), # 词性标注
tag_word=batch_trees.nodes['word'].data["tag_word"].to(device), # 标签词的位置
from_to = batch_trees.nodes['word'].data["from_to"].to(device), # 词的开始和结束位置
)
return batcher_dev
train_loader = DataLoader(dataset=g,
batch_size=batch_size,
collate_fn=batcher(device),
shuffle=True)
test_loader = DataLoader(dataset=g,
batch_size=batch_size,
collate_fn=batcher(device),
shuffle=True)
valid_loader = DataLoader(dataset=g,
batch_size=batch_size,
collate_fn=batcher(device),
shuffle=True)
评估模型函数
def evaluate_model(data_loader, data_sum):
loss_step = []
acc_step = 0
for step, batch in tqdm(enumerate(data_loader)):
g = batch.graph.to(device)
h = {"word":batch.wordid.to(device)} # 字典形式传入
label = batch.label[torch.nonzero(batch.label!=-1).squeeze()].long()
logits = model(g, h)
logp = F.softmax(logits, dim=-1)
loss = F.cross_entropy(logp, label)
loss_step.append(loss.cpu().detach().numpy())
pred = th.argmax(logits, 1)
acc_sum = th.sum(th.eq(label, pred)).cpu().detach().numpy()
acc_step += acc_sum
return acc_step / data_sum, np.mean(loss_step)
训练模型
from tqdm import tqdm
optimizer = th.optim.Adagrad(model.parameters(),
lr=lr)
train_sum = len(g) # 训练集的个数
test_sum = len(g) # 测试集的个数
valid_sum = len(g) # 测试集的个数
train_loss = []
test_loss = []
valid_loss = []
train_acc = []
test_acc = []
valid_acc = []
for epoch in range(epochs):
model.train()
for step, batch in tqdm(enumerate(train_loader)):
g = batch.graph.to(device)
h = {"word":batch.wordid.to(device)} # 字典形式传入
label = batch.label[torch.nonzero(batch.label!=-1).squeeze()].long()
logits = model(g, h)
logp = F.softmax(logits, dim=-1)
loss = F.cross_entropy(logp, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 评估模型
model.eval()
tr_acc, tr_loss = evaluate_model(train_loader, train_sum)
te_acc, te_loss = evaluate_model(test_loader, test_sum)
val_acc, val_loss = evaluate_model(valid_loader, valid_sum)
train_acc.append(tr_acc)
train_loss.append(tr_loss)
test_acc.append(te_acc)
test_loss.append(te_loss)
valid_acc.append(val_acc)
valid_loss.append(val_loss)
print("Epoch {:05d} train_Loss {:.4f} | train_Acc {:.4f} | test_Loss {:.4f} | test_Acc {:.4f} | valid_Loss {:.4f} | valid_Acc {:.4f} |".format(
epoch, tr_loss, tr_acc, te_loss, te_acc, val_loss, val_acc))
early_stopping(te_loss, model) # 早停
if early_stopping.early_stop:
print('early_stopping')
break
可以看看训练结果(随便跑个看看)
329it [00:04, 68.48it/s]
329it [00:04, 73.52it/s]
329it [00:04, 73.15it/s]
329it [00:04, 73.38it/s]
Epoch 00000 train_Loss 1.0958 | train_Acc 0.5107 | test_Loss 1.0958 | test_Acc 0.5107 | valid_Loss 1.0958 | valid_Acc 0.5107 |
Validation loss decreased (inf --> 1.095818). Saving model ...
329it [00:04, 69.94it/s]
329it [00:04, 72.80it/s]
127it [00:01, 65.24it/s]Epoch 00001 train_Loss 1.0949 | train_Acc 0.5107 | test_Loss 1.0949 | test_Acc 0.5107 | valid_Loss 1.0949 | valid_Acc 0.5107 |
Validation loss decreased (1.095818 --> 1.094885). Saving model ...
329it [00:04, 69.19it/s]
329it [00:04, 74.51it/s]
329it [00:04, 74.07it/s]
329it [00:04, 71.82it/s]
Epoch 00002 train_Loss 1.0942 | train_Acc 0.5107 | test_Loss 1.0942 | test_Acc 0.5107 | valid_Loss 1.0942 | valid_Acc 0.5107 |
Validation loss decreased (1.094885 --> 1.094210). Saving model ...
329it [00:04, 66.45it/s]
329it [00:04, 71.71it/s]
329it [00:04, 70.01it/s]
329it [00:04, 74.33it/s]
Epoch 00003 train_Loss 1.0936 | train_Acc 0.5107 | test_Loss 1.0936 | test_Acc 0.5107 | valid_Loss 1.0936 | valid_Acc 0.5107 |
Validation loss decreased (1.094210 --> 1.093606). Saving model ...
329it [00:04, 69.57it/s]
329it [00:04, 77.63it/s]
57it [00:00, 72.12it/s]Epoch 00004 train_Loss 1.0931 | train_Acc 0.5107 | test_Loss 1.0931 | test_Acc 0.5107 | valid_Loss 1.0931 | valid_Acc 0.5107 |
Validation loss decreased (1.093606 --> 1.093079). Saving model ...
可以看到损失有一捏捏下降。
可视化训练曲线
import matplotlib.pyplot as plt
x = [i for i in range(len(train_acc))]
fig = plt.figure()
plt.plot(x, train_acc, c="r", label="acc_train")
plt.plot(x, test_acc, c="b", label="acc_test")
plt.plot(x, valid_acc, c="g", label="acc_valid")
plt.legend()
plt.show()
fig_loss = plt.figure()
plt.plot(x, train_loss, c="r", label="loss_train")
plt.plot(x, test_loss, c="b", label="loss_test")
plt.plot(x, valid_loss, c="b", label="loss_valid")
plt.legend()
plt.show()
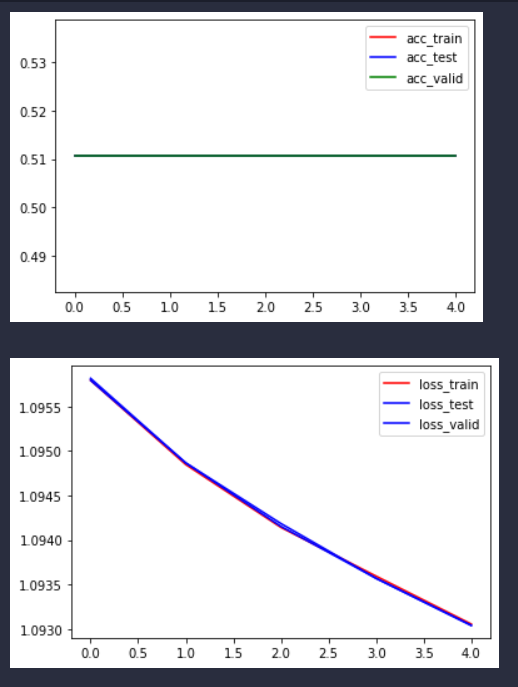
因为我这里公用一个数据集,曲线也确实是重合的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











