






背景
ICDM 2022 : 大规模电商图上的风险商品检测,要求在一张异构图上跑点分类,由于是异常检测,正负样本数据集在1比10,记录一下初赛过程。
数据
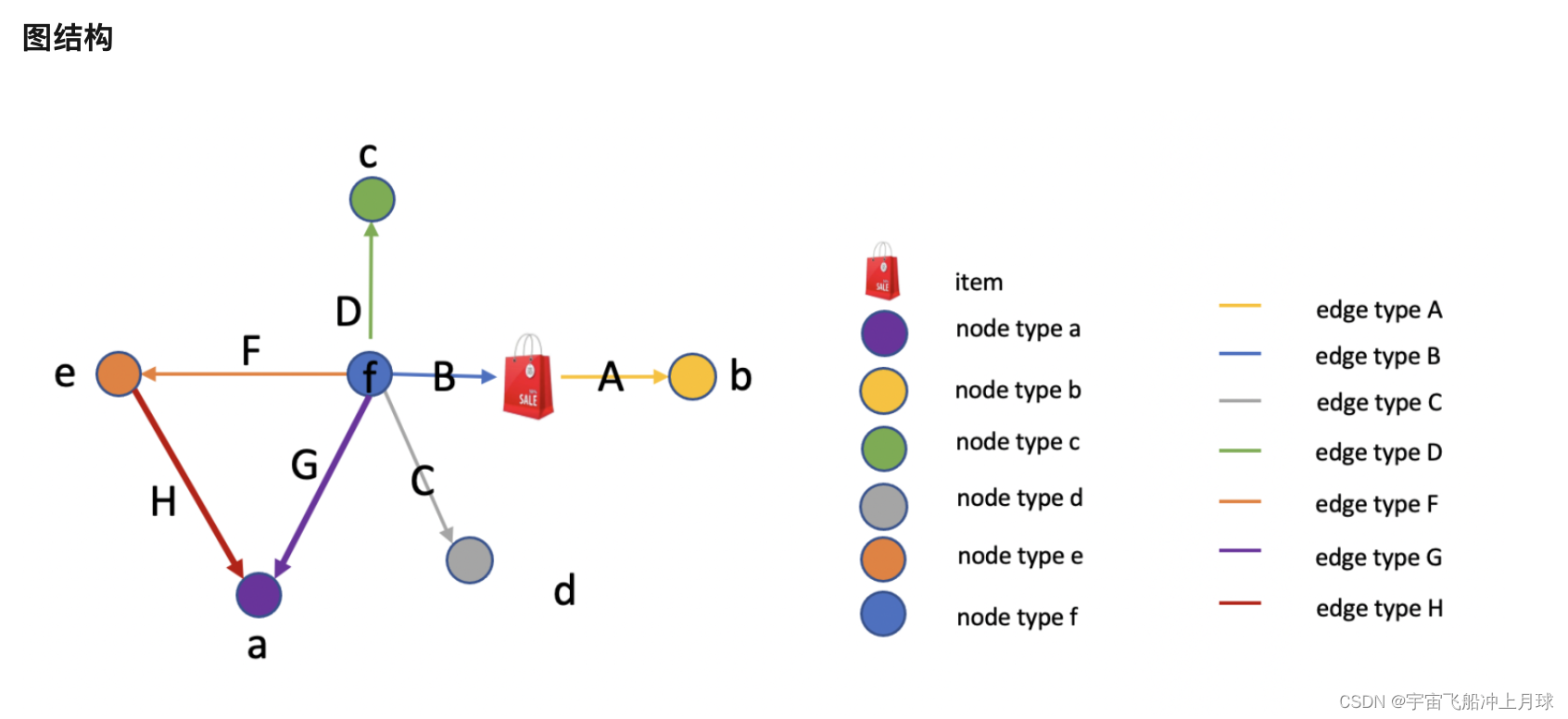

过程
赛事官方开源了PyG实现的baseline,拿过来直接用于预处理数据了,将图结构进行预处理后得到pt文件,使用pt文件做后续处理:
graph = torch.load(dataset) //dataset = "xxx.pt"
graph[type].x = [num_nodes , 256] 点数*特征维度
graph[type].y = [num_nodes] 标签=label
graph[type].num_nodes = 数量
graph[type].maps = id 离散化映射:针对不同的type重新从0开始记录id
# 异构图特殊存边方式,需要指定两个点的种类和边的种类。
graph[(source_type, edge_type, dest_type)].edge_index = (source,dest) [2, num_edges]
# 借鉴GraphSage的邻居采样dataload,每次训练不使用整张图,可以分batch
train_loader = NeighborLoader(graph, input_nodes=('要分类的type', train_idx),
num_neighbors=[a] * b 往外采样b层,每层每种边a个,内存够a可以填-1 ,
shuffle=True, batch_size=128)
for batch in train_loader():
batch['item'].batch_size = 128
batch['item'].x =[num, 256] 前batch_size个是要预测的点,其他为采样出来的点。
batch['item'].y =[num] 前batch_size个是预测点的label,其他无用。
batch = batch.to_homogeneous() 转化为同构图
batch.x = [所有点数量, 256]
batch.edge_idx = [2, 所有边数量] 记录所有边
batch.edge_type = [所有边数量] 记录边的类型
model(batch.x,batch.edge_index,batch.edge_type)
RGCN
RGCN比较简单,其实就是借鉴GCN处理同构图的思路,将其运用到处理异构图上。
GCN的基本思想就是为了计算下一层i节点的embedding,拿出上一层和i相邻的节点和i节点本身的embedding,将这些embedding乘上对应的网络要学习的变化权重矩阵W,前面再乘上单位矩阵和归一化矩阵,每一层的W用同一个,类比卷积。
RGCN很简单,异构图不是有很多种边吗,我就把不同种类的边分开来,每种关系一张图,这样这张图上边都是一样的了,理所当然使用GCN共享W矩阵,求出这种关系下节点i的embedding,最后所有关系的embedding来个融合,随便加个权,来个relu激活一下完成。
from torch_geometric.nn import RGCNConv
class RGCN(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels, n_layers=2, dropout=0.5):
super().__init__()
self.convs = torch.nn.ModuleList()
self.relu = F.relu
self.dropout = dropout
self.convs.append(RGCNConv(in_channels, hidden_channels, num_relations))
for i in range(n_layers - 2):
self.convs.append(RGCNConv(hidden_channels, hidden_channels, num_relations))
self.convs.append(RGCNConv(hidden_channels, out_channels, num_relations))
def forward(self, x, edge_index, edge_type):
for conv, norm in zip(self.convs, self.norms):
x = norm(conv(x, edge_index, edge_type))
x = F.relu(x)
x = F.dropout(x, p=self.dropout, training=self.training
return x
RGAT
由于RGCN每一层W都是固定的,不够灵活,所以加入attention机制,毕竟万物皆可attention。
先说一下GAT在GCN上的改动,在计算i节点的embedding时,还是拿出和它邻近的节点和它自己的embedding,对于每一个这样的节点j,将i,j节点的embedding拼接,变成两倍长度,然后算一个self-attention,好像就是一个单层前馈网络,就得到节点j相对于节点i的权重。
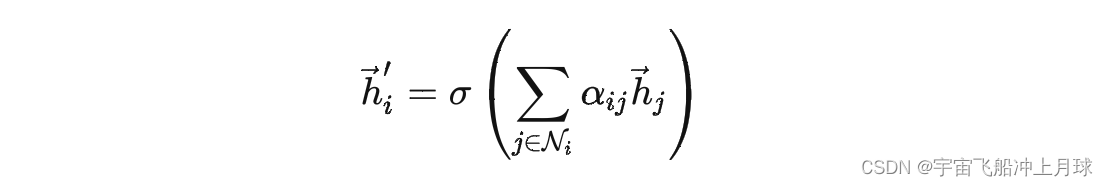
RGAT一样,在关系上下功夫,利用关系特征再算一个attention。
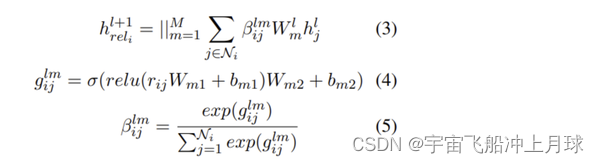
最后两者做融合
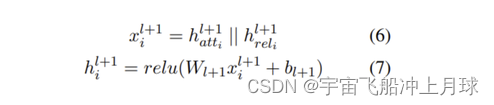
RGAT可以看成是RGCN进化版,在attention不起作用的时候会退化成RGCN。
但实战和RGCN不分伯仲,甚至在本次竞赛的场景中逊色于RGCN。原因见论文:

- RGAT通过attention机制比较好的完成任务之后,很难在损失机制反馈的作用下找到那个把attention设置成归一化常数后效果更好的点。
- RGCN在一些任务上会通过记忆样本的方式提升效果,但是RGAT模型更复杂发生这种情况的概率更低。
from torch_geometric.nn import RGATConv
class RGAT(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels, n_layers=2, n_heads=3):
super().__init__()
self.convs = torch.nn.ModuleList()
self.relu = F.relu
self.convs.append(RGATConv(in_channels, hidden_channels, num_relations, heads=n_heads,
concat=False))
for i in range(n_layers - 2):
self.convs.append(RGATConv(hidden_channels, hidden_channels, num_relations,
heads=n_heads, concat=False))
self.convs.append(RGATConv(hidden_channels, hidden_channels, num_relations,
heads=n_heads, concat=False))
self.lin1 = torch.nn.Linear(hidden_channels, out_channels)
def forward(self, x, edge_index, edge_type):
for i, conv in enumerate(self.convs):
x = conv(x, edge_index, edge_type)
x = x.relu_()
x = F.dropout(x, p=0.2, training=self.training
x = self.lin1(x)
return x
Heterogeneous Graph Attention Network (HAN HGAT)
根据专家经验设置多条matapath(路径):点、边、点、边、点…

针对不同的matapath,节点i针对路径拿到其所有邻居节点j。
1.点和点计算attention并求和。使用多头注意力机制。

2.所有关系要聚合时算一个attention,其中q,w,b共享。

实验中效果很差,可能是我matapath设置的不好吧,而且多头注意力训练时间也太久了,我RGCN一个epoch只要5min,它要480min。
from torch_geometric.nn import HANConv
labeld_class = 'item'
class HAN(torch.nn.Module):
def __init__(self, in_channels: Union[int, Dict[str, int]],
out_channels: int, hidden_channels=16, heads=4, n_layers=2):
super().__init__()
self.convs = torch.nn.ModuleList()
self.relu = F.relu
self.convs.append(HANConv(in_channels, hidden_channels, heads=heads, dropout=0.6,
metadata=metada))
for i in range(n_layers - 1):
self.convs.append(HANConv(hidden_channels, hidden_channels, heads=heads, dropout=0.6,
metadata=metada))
self.lin = torch.nn.Linear(hidden_channels, out_channels)
def forward(self, x_dict, edge_index_dict):
for i, conv in enumerate(self.convs):
x_dict = conv(x_dict, edge_index_dict)
x_dict = self.lin(x_dict[labeled_class])
return x_dict
GNN-Film(线性特征调整)
对比RGCN,改动的点与RGAT类似,同样想使得权重有所变化。加入了一个简单的前馈网络:
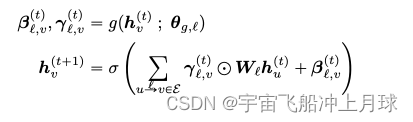
优点在于他在算权重的时候,加了一个仿射变换,相当于是用神经网络去计算参数。再用b和y去作为权重调整embedding。
实验中效果出奇的好,训练快,效果超越RGCN。
class GNNFilm(torch.nn.Module):
def __init__(self, in_channels, hidden_channels, out_channels, n_layers,
dropout=0.5):
super().__init__()
self.dropout = dropout
self.convs = torch.nn.ModuleList()
self.convs.append(FiLMConv(in_channels, hidden_channels, num_relations))
for _ in range(n_layers - 1):
self.convs.append(FiLMConv(hidden_channels, hidden_channels, num_relations))
self.norms = torch.nn.ModuleList()
for _ in range(n_layers):
self.norms.append(BatchNorm1d(hidden_channels))
self.lin_l = torch.nn.Sequential(OrderedDict([
('lin1', Linear(hidden_channels, int(hidden_channels//4), bias=True)),
('lrelu', torch.nn.LeakyReLU(0.2)),
('lin2', Linear(int(hidden_channels//4),out_channels, bias=True))]))
def forward(self, x, edge_index, edge_type):
for conv, norm in zip(self.convs, self.norms):
x = norm(conv(x, edge_index, edge_type))
x = F.dropout(x, p=self.dropout, training=self.training)
x = self.lin_l(x)
return x
总结
RGCN、RGAT、GNN-FILM代码替换十分简单,训练代码完全不用动,只要改模型代码即可,完全可以三者都尝试效果,HAN慎用,效果太吃matapath的设置,训练时间还长,不值得。

















 2306
2306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









