一、python的get方法访问网址
1.pip install requests下载requests库
2.引入谷歌的浏览器
3.直接用get方法访问
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('http://www.baidu.com')
print(driver.page_source)
二、python的post方法访问网址
1.post方法网址打开工作台,会发现发送请求时带了请求体,请求体捕捉,打开F12工具,点到网络,选择fetch/xhr就可以捕捉
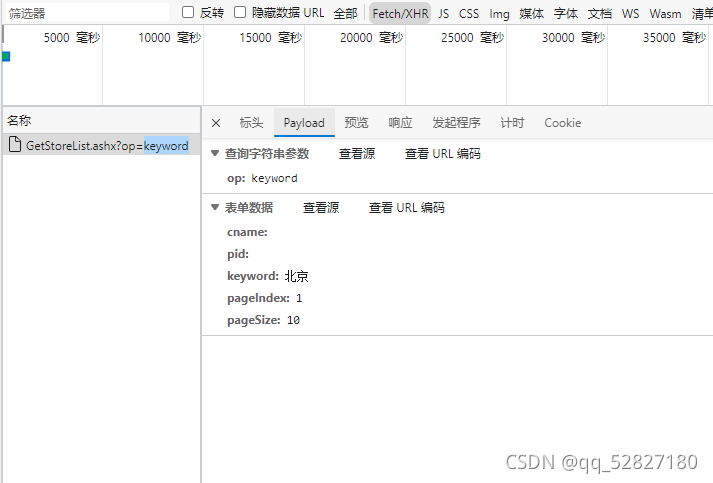
2.我们在访问时带上请求体,就可以实现post方法请求
import requests
url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
mydata={
"cname":'',
"pid":'',
"keyword": input("输入一个地址"),
"pageIndex": 1,
"pageSize": 10
}
resp = requests.post(url,data=mydata)
resp.encoding='utf-8'
print(resp.json())
三、python的正则表达式获取我们想要的数据
1.pip install re下载re库
2. re.compile为正则表达式
3.里面.?就是跳过,(?P.?)就是将文本赋值给name,re.S最好每次都带上
从网页上的<div class="item">开始,一直跳到<span class="title">,将<span class="title">开始到</span>时的数据赋值给name
re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<pingjia>.*?)</span>.*?<span>(?P<pingjiarenshu>.*?)</span>',re.S)
import requests
import re
import json
import pandas as pd
url = "https://movie.douban.com/top250"
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"}
resp = requests.get(url=url, headers=head)
resp.encoding = 'utf-8'
obj = re.compile(r'<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<br>(?P<year>.*?) .*?<span class="rating_num" property="v:average">(?P<pingjia>.*?)</span>.*?<span>(?P<pingjiarenshu>.*?)</span>',re.S)
result = obj.finditer(resp.text)
'''
count = 0
with open('abc.excel','a',encoding='utf-8') as f:
for i in result:
dic = i.groupdict()
dic['year']=dic['year'].strip()
data = json.dumps(dic,ensure_ascii=False).split(',')
count = count+1
for j in range(0,len(data)):
json.loads(data[j], strict=False)
print('\n')
print(count)
#f.write(json.dumps(dic,ensure_ascii=False))
#f.write("\n")
'''
output = open('test.xls','w',encoding='utf-8')
output.write('name\tyear\tpingjia\tpingjiarenshu\n')
for i in result:
dic = i.groupdict()
dic['year']=dic['year'].strip()
data = json.dumps(dic,ensure_ascii=False).split(',')
output.write(dic['name'])
output.write('\t')
output.write(dic['year'])
output.write('\t')
output.write(dic['pingjia'])
output.write('\t')
output.write(dic['pingjiarenshu'])
output.write('\t')
output.write('\n')
output.close()
'''
items = re.findall(obj, resp.text)
for item in items:
print(item)
list=['value1','value2','value3']
dataframe = pd.DataFrame(list)
print(dataframe)
dataframe.to_excel('/home/hzd/list.xls')
'''
四、python用xpath解析获取网页(例子时获取gitee的所有代码名称等数据)
1.pip install lxml引入lxml库
2.xpath解析详情
//为跳过前面所有内容,从div开始,[@class]是通过class选择器筛选,@title是获取title的value,@href是获取href的value,一切都可以@
jianjie = et.xpath('//div[@class="project-desc mb-1"]/@title')
text()是获取文本
pages = et.xpath('//div[@class="ui tiny pagination menu"]/a[@class="item"]/text()')
from lxml import etree
import requests
import re
import emoji
head = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36"}
countIndex=0
url = "https://gitee.com/explore/webframework"
resp = requests.get(url=url, headers=head)
resp.encoding = 'utf-8'
et = etree.HTML(resp.text)
pages = et.xpath('//div[@class="ui tiny pagination menu"]/a[@class="item"]/text()')
pageIndex = pages[len(pages)-1]
print(type(pageIndex))
for page in range(1,int(pageIndex)+1):
url=f'https://gitee.com/explore/webframework?page={page}'
print(url)
resp = requests.get(url=url, headers=head)
resp.encoding = 'utf-8'
et = etree.HTML(resp.text)
urls = et.xpath('//h3/a/@href')
print(urls)
for uri in urls:
uri = "https://gitee.com"+uri
print("\n")
jianjie = et.xpath('//div[@class="project-desc mb-1"]/@title')
yuyanfenlei = et.xpath('//a[@class="project-language project-item-bottom__item"]/text()')
kuangjiafenlei = et.xpath('//a[@class="project-item-bottom__item"]/text()')
fabushiqi = et.xpath('//div[@class="text-muted project-item-bottom__item d-flex-center"]/@title')
shijian = et.xpath('//div[@class="text-muted project-item-bottom__item d-flex-center"]/text()')
xiangmumingcheng = et.xpath('//h3/a/text()')
output = open('gitee代码的项目详情.xls','a',encoding='utf-8')
count = 0
if countIndex==0 :
output.write('项目名称\t项目简介\t项目地址\t使用框架技术\t发布距今时间\n')
for j in urls:
output.write(xiangmumingcheng[count])
output.write('\t')
text = emoji.demojize(jianjie[count])
result = re.sub(':\S+?:', ' ', text)
output.write(result.replace('\n', '').replace('\r', ''))
output.write('\t')
output.write("https://gitee.com/"+urls[count])
output.write('\t')
output.write(kuangjiafenlei[count])
output.write('\t')
output.write(shijian[count].replace('\n', '').replace('\r', ''))
count=count+1
countIndex=1
output.write('\n')
output.close()

























 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









