







Redis数据库
Redis简介
什么是Redis?
Redis是一款高性能的NOSQL系列的非关系型数据库,是一个独立的数据库软件,可以被独立地安装在一台服务器上,可以远程操作,所以被称为远程字典服务器,Remote dictionary server
- 一个开源的基于内存的数据库,常用作键值存储、缓存和消息队列等
- 按db-engines的排名,redis是连续几年最受欢迎的键值存储数据库
- Redis通常将全部数据存储在内存中,也可以不时的将数据写入硬盘实现持久化,但仅用于重新启动后将数据加载回内存
- 内存的速度比硬盘快一个数量级
什么是NOSQL?
NoSQL(NoSQL = Not Only SQL),意即“不仅仅是SQL”,是一项全新的数据库理念,泛指非关系型的数据库。
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型(社会服务类型,类似百度、微信、淘宝)的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。
工作中遇到的挑战:
1 、高并发读写
Web2.0网站,数据库并发负载非常高,往往达到每秒上万次的读写请求
2、高容量存储和高效存储
Web2.0网站通常需要在后台数据库中存储海量数据,如何存储海量数据并进行高效的查询往往是一个挑战
3、高扩展性和高可用性
随着系统的用户量和访问量与日俱增,需要数据库能够很方便的进行扩展、维护
主流的NOSQL产品
- 键值(Key-Value)存储数据库
相关产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
典型应用: 内容缓存,主要用于处理大量数据的高访问负载。
数据模型: 一系列键值对
优势: 快速查询
劣势: 存储的数据缺少结构化 - 列存储数据库
相关产品:Cassandra, HBase, Riak
典型应用:分布式的文件系统
数据模型:以列簇式存储,将同一列数据存在一起
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限 - 文档型数据库
相关产品:CouchDB、MongoDB
典型应用:Web应用(与Key-Value类似,Value是结构化的)
数据模型: 一系列键值对
优势:数据结构要求不严格
劣势: 查询性能不高,而且缺乏统一的查询语法 - 图形(Graph)数据库
相关数据库:Neo4J、InfoGrid、Infinite Graph
典型应用:社交网络
数据模型:图结构
优势:利用图结构相关算法。
劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案。
NOSQL优势与缺点
-
优点:
1)成本:nosql数据库简单易部署,基本都是开源软件,不需要像使用oracle那样花费大量成本购买使用,相比关系型数据库价格便宜。
2)查询速度:nosql数据库将数据存储于缓存之中,关系型数据库将数据存储在硬盘中,自然查询速度远不及nosql数据库。
3)存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库则只支持基础类型。 -
缺点:
1)维护的工具和资料有限,因为nosql是属于新的技术,不能和关系型数据库10几年的技术同日而语。
2)不提供对sql的支持,如果不支持sql这样的工业标准,将产生一定用户的学习和使用成本。
3)不提供关系型数据库对事务的处理。 -
总结:
关系型数据库与NoSQL数据库并非对立而是互补的关系,即通常情况下使用关系型数据库,在适合使用NoSQL的时候使用NoSQL数据库,让NoSQL数据库对关系型数据库的不足进行弥补。
一般会将数据存储在关系型数据库中,在nosql数据库中备份存储关系型数据库的数据.
发展历史
- Salvatore Sanfilippo,意大利程序员
- 他最早使用传统数据库做了一个实时的 Web 日志分析器
- 因为对其性能不够满意,开发了 Redis
- 2020 年6月,Salvatore Sanfilippo 辞去了 Redis 维护者的职务
Redis的数据结构
- redis存储的是:key,value格式的数据,其中key都是字符串,value有5种不同的数据结构
- value的数据结构:
- 字符串类型 string
- 哈希类型 hash : map格式
- 列表类型 list : linkedlist格式。支持重复元素
- 集合类型 set : 不允许重复元素
- 有序集合类型 sortedset:不允许重复元素,且元素有顺序
- value的数据结构:
Redis的基本操作
通用命令
1. keys * : 查询所有的键
2. type key : 获取键对应的value的类型
3. del key:删除指定的key value
数据库操作
redis默认有16个数据库,编号0~15,默认访问0
- 概念语法
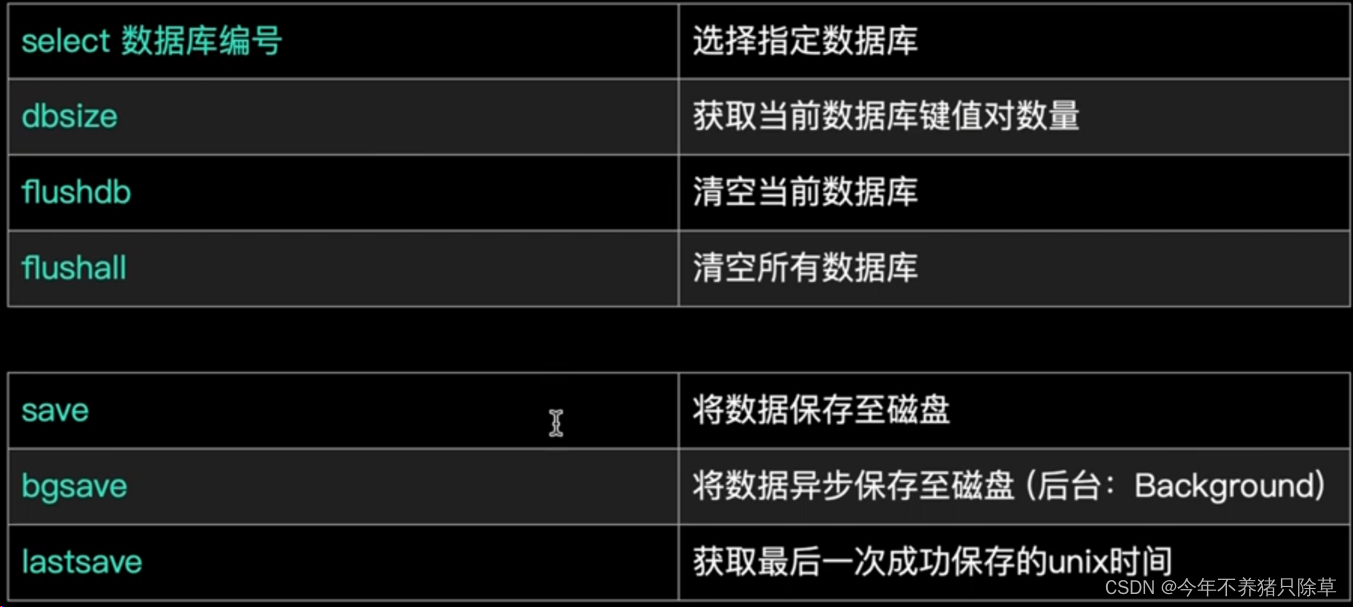
- 执行操作
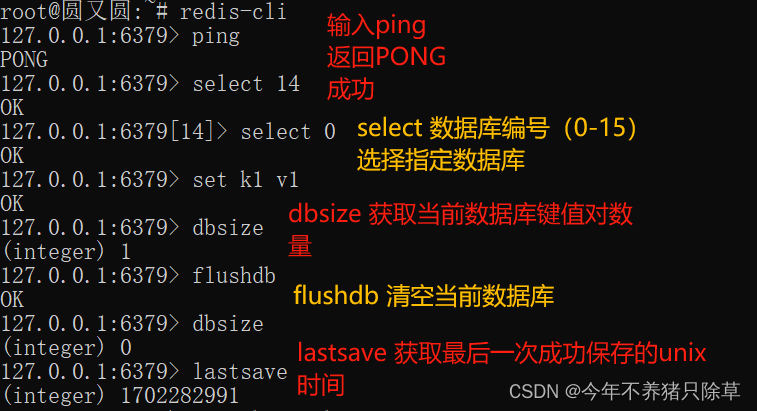
通用数据操作
操作范围为当前数据库
- 概念语法
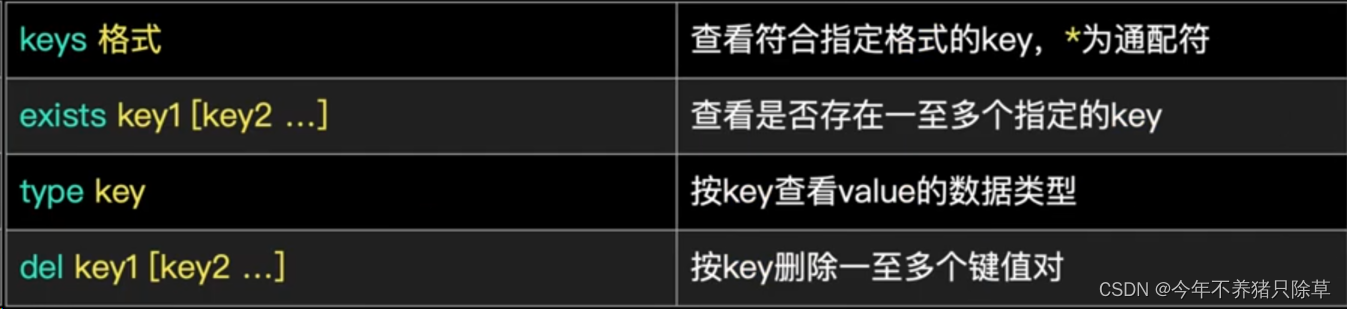
- 执行操作
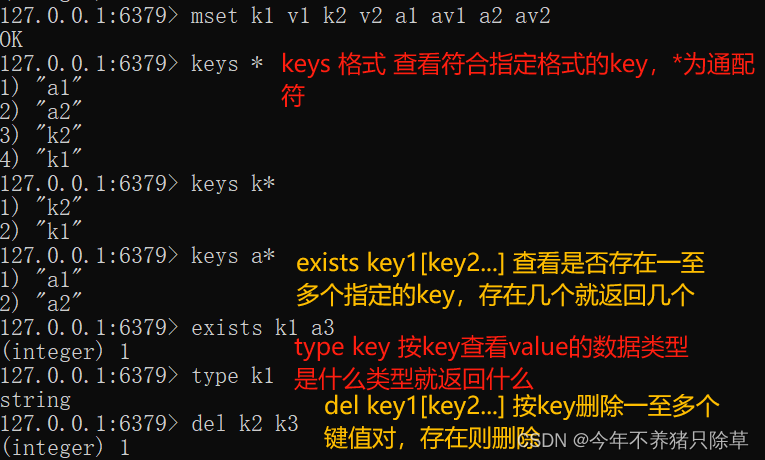
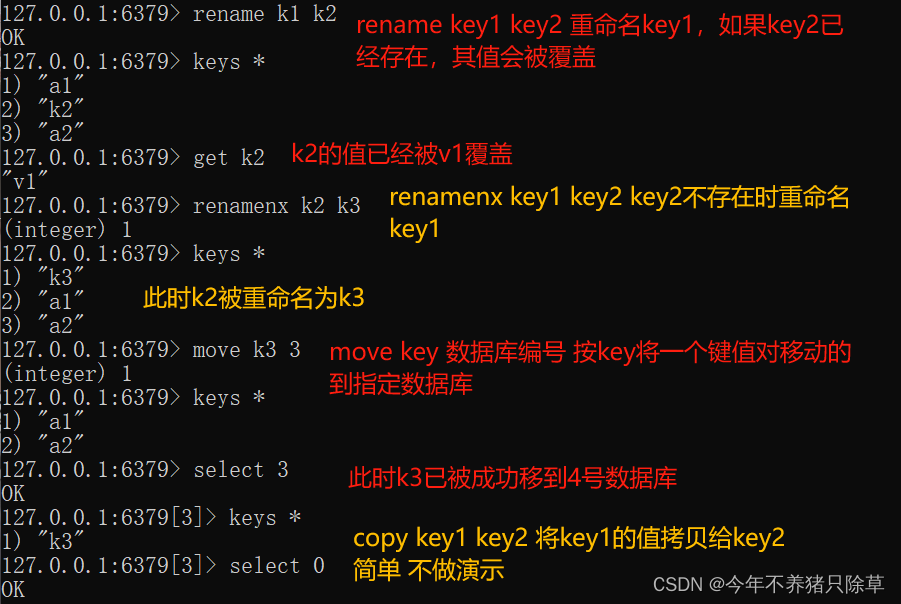
- 概念语法
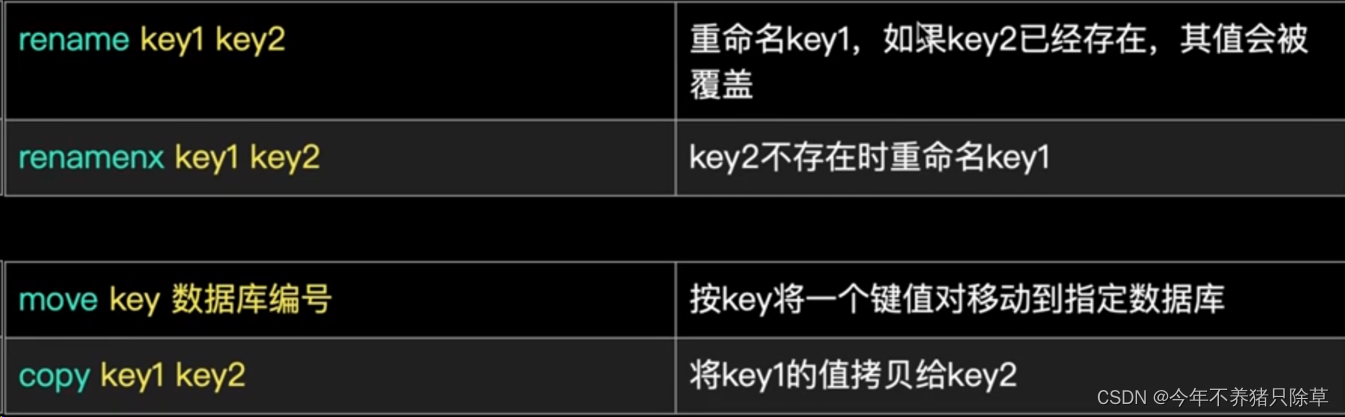
- 执行操作
字符串
字符串类型 string
1. 存储: set key value
127.0.0.1:6379> set username zhangsan
OK
2. 获取: get key
127.0.0.1:6379> get username
"zhangsan"
3. 删除: del key
127.0.0.1:6379> del age
(integer) 1
基本操作
- 概念语法
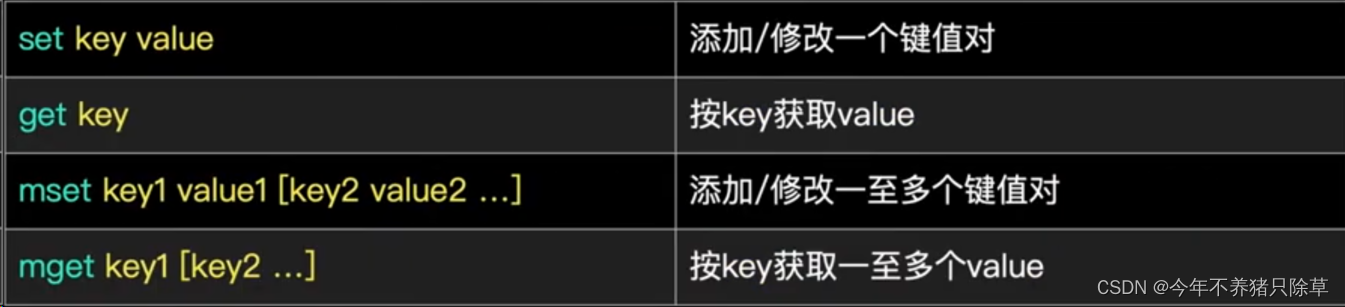

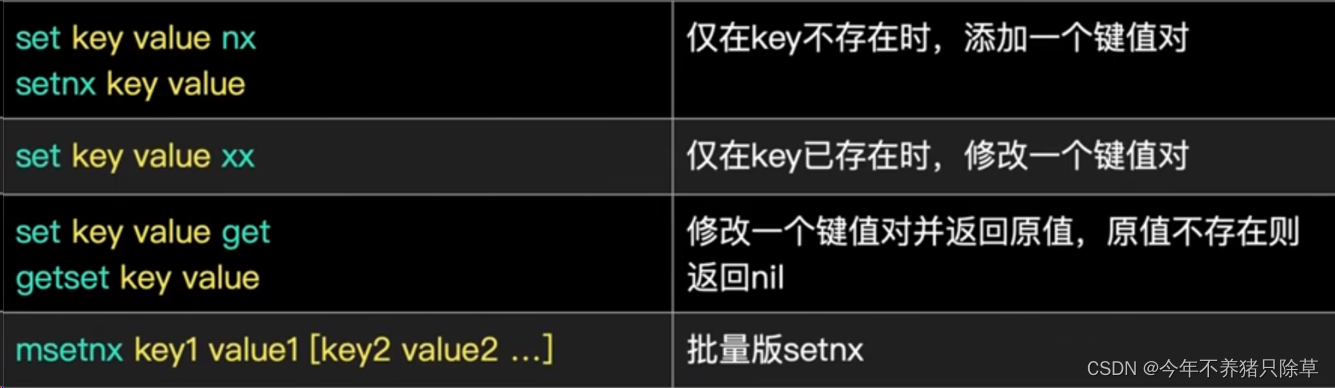
- 执行操作

字符串内容是整数、小数
- 概念语法

- 执行操作

小数操作类似整数,可自行尝试
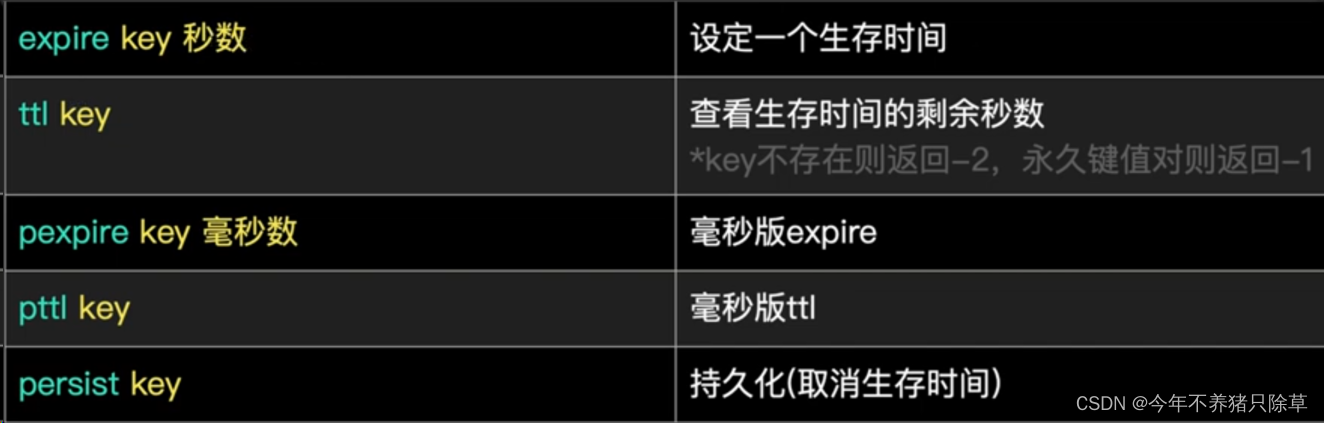
临时键值对
生存时间time to live,缩写为ttl,指键值对距离被删除的剩余秒数如果重新set,生存时间(time to live,ttl)将被重置
以下操作支持各种数据类型
- 概念语法
- 执行操作

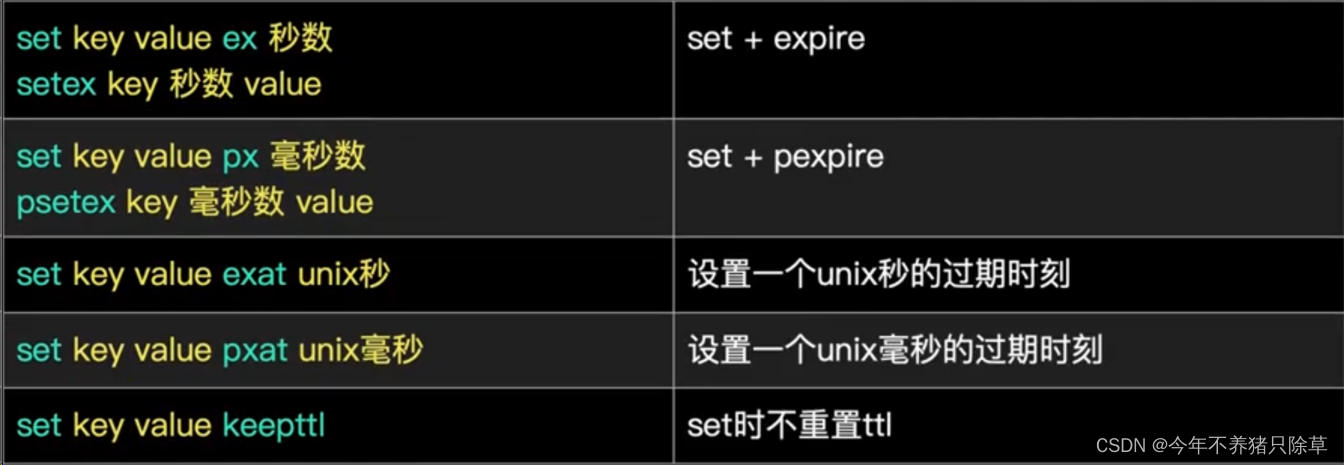
以下操作仅支持字符串
- 概念语法
- 执行操作
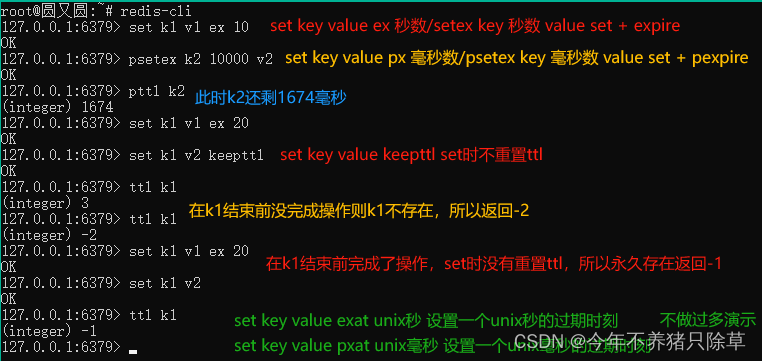
- 有单独的命令就用单独的命令
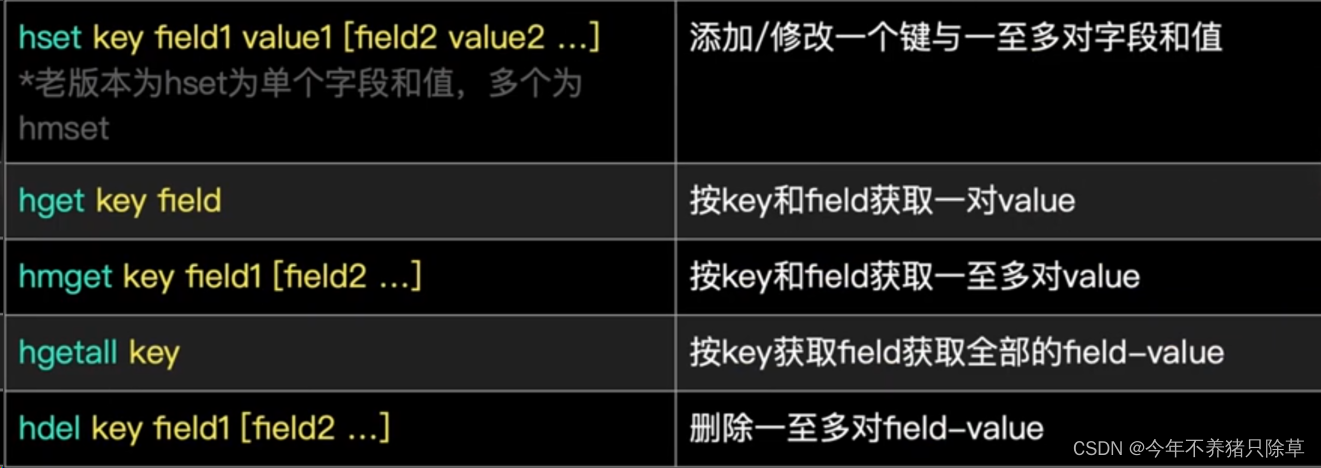
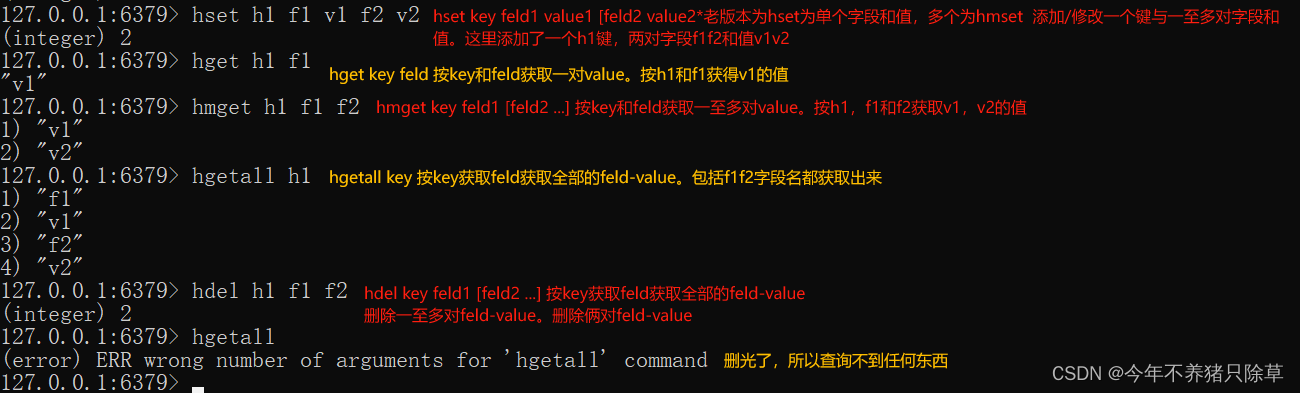
散列表
哈希类型 hash
1. 存储: hset key field value
127.0.0.1:6379> hset myhash username lisi
(integer) 1
127.0.0.1:6379> hset myhash password 123
(integer) 1
2. 获取:
* hget key field: 获取指定的field对应的值
127.0.0.1:6379> hget myhash username
"lisi"
* hgetall key:获取所有的field和value
127.0.0.1:6379> hgetall myhash
1) "username"
2) "lisi"
3) "password"
4) "123"
3. 删除: hdel key field
127.0.0.1:6379> hdel myhash username
(integer) 1
key-field-value,键-字段-值

基本操作
- 概念语法
- 执行操作
- 概念语法
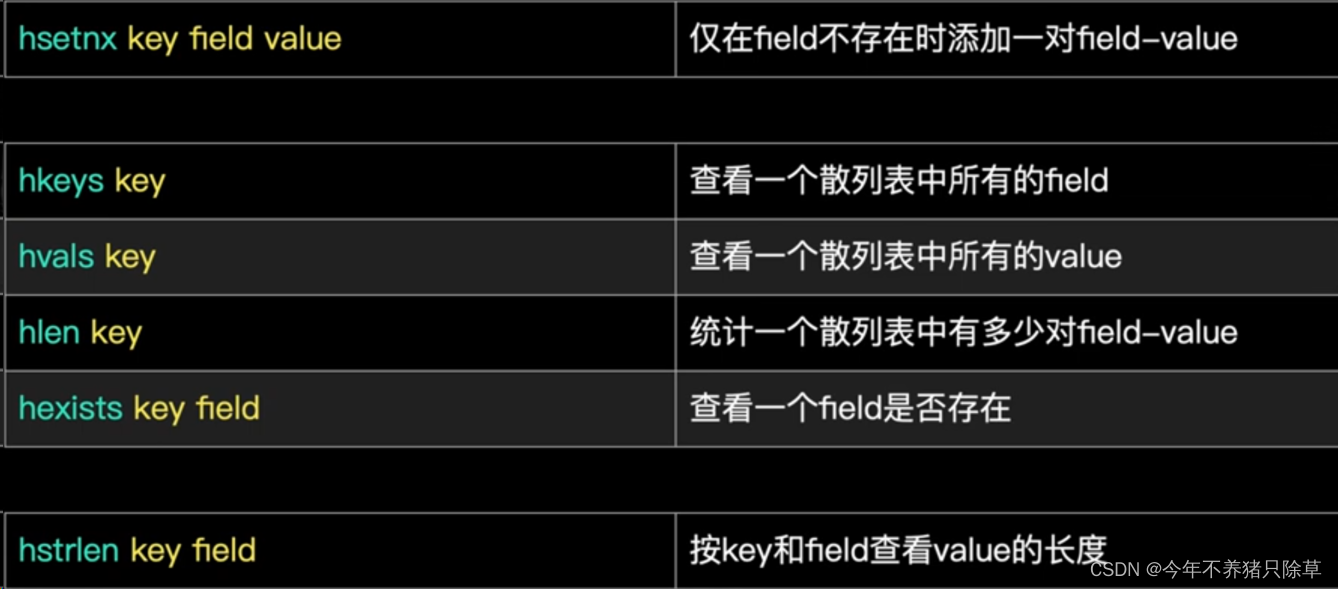
- 执行操作

value字符串的内容是数值
- 概念语法

- 执行操作

列表List
列表类型 list:可以添加一个元素到列表的头部(左边)或者尾部(右边)
1. 添加:
1. lpush key value: 将元素加入列表左表
2. rpush key value:将元素加入列表右边
127.0.0.1:6379> lpush myList a
(integer) 1
127.0.0.1:6379> lpush myList b
(integer) 2
127.0.0.1:6379> rpush myList c
(integer) 3
2. 获取:
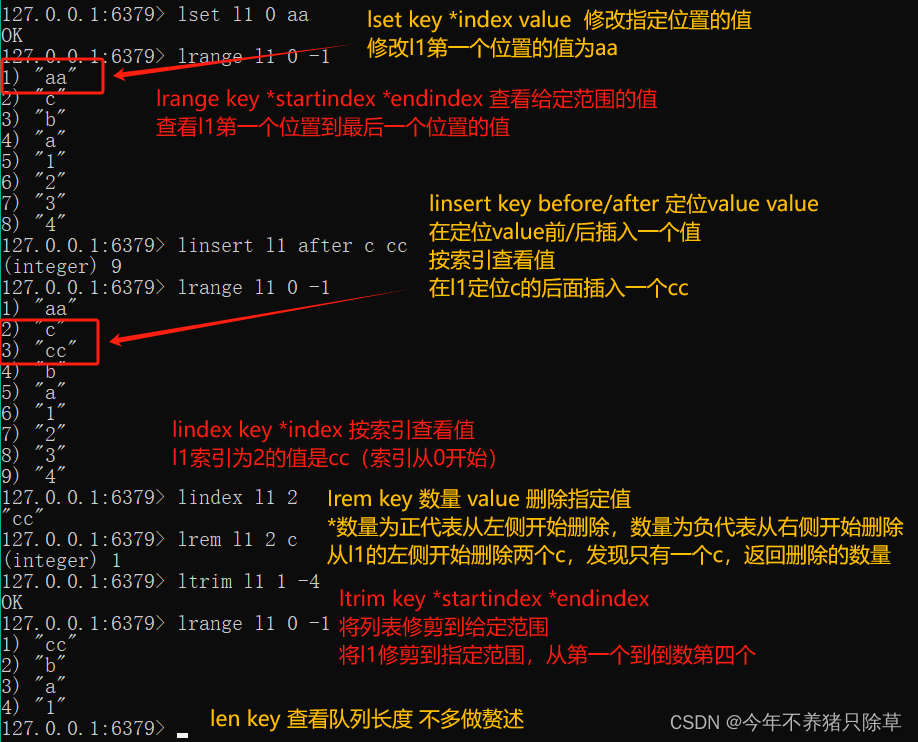
* lrange key start end :范围获取
127.0.0.1:6379> lrange myList 0 -1
1) "b"
2) "a"
3) "c"
3. 删除:
* lpop key: 删除列表最左边的元素,并将元素返回
* rpop key: 删除列表最右边的元素,并将元素返回
key-value0-value1-…,键-有序的值列队
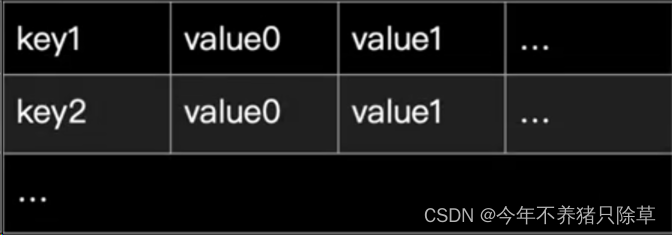
基本操作
- 概念语法


- 执行操作

- 概念语法
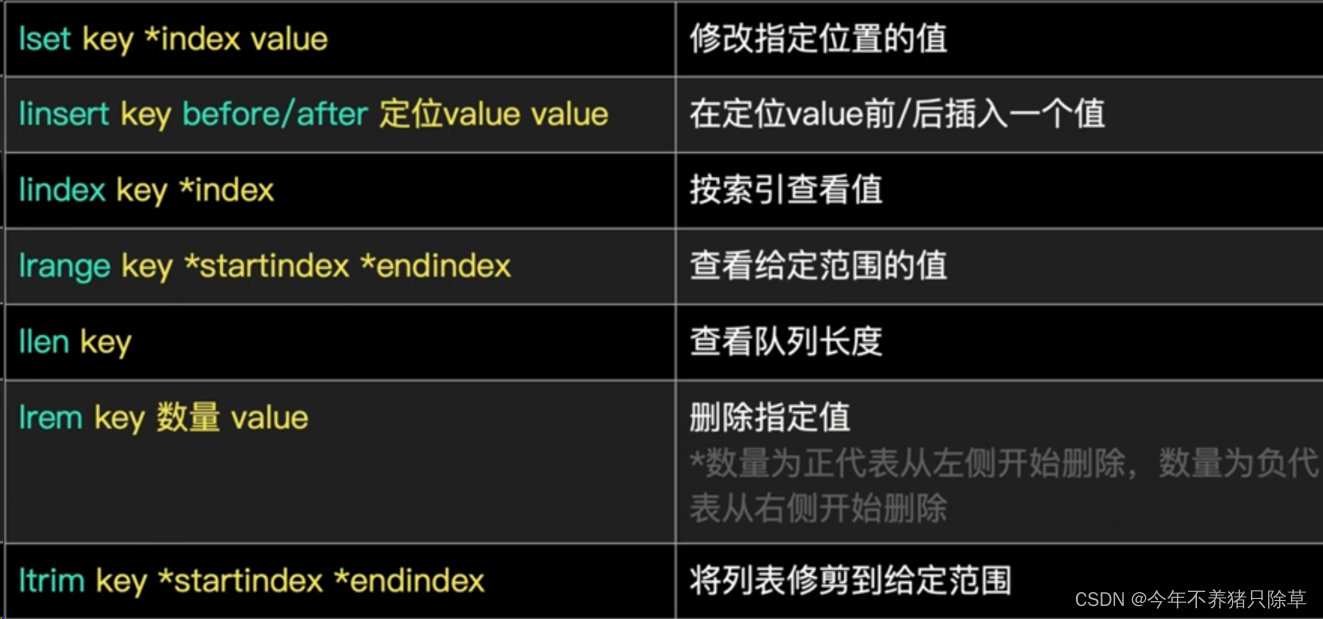
索引从0开始,-n表示倒数第n个
- 执行操作
集合Set
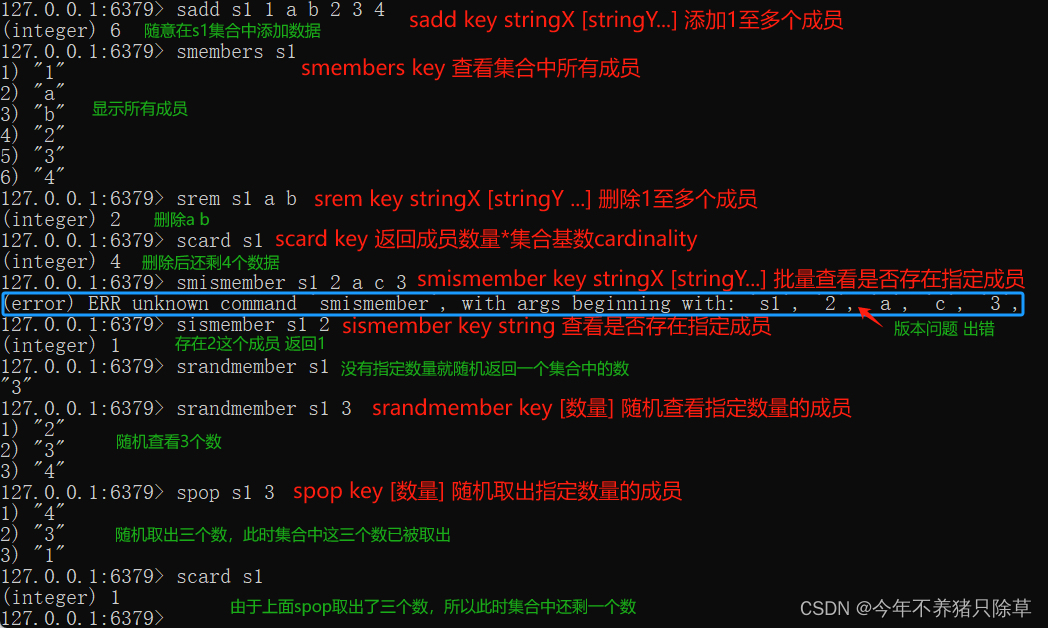
集合类型 set : 不允许重复元素
1. 存储:sadd key value
127.0.0.1:6379> sadd myset a
(integer) 1
127.0.0.1:6379> sadd myset a
(integer) 0
2. 获取:smembers key:获取set集合中所有元素
127.0.0.1:6379> smembers myset
1) "a"
3. 删除:srem key value:删除set集合中的某个元素
127.0.0.1:6379> srem myset a
(integer) 1
key-stringX,stringY…,键-无序的不重复的成员

基本操作
- 概念语法

- 执行操作
- 概念语法
- 执行操作
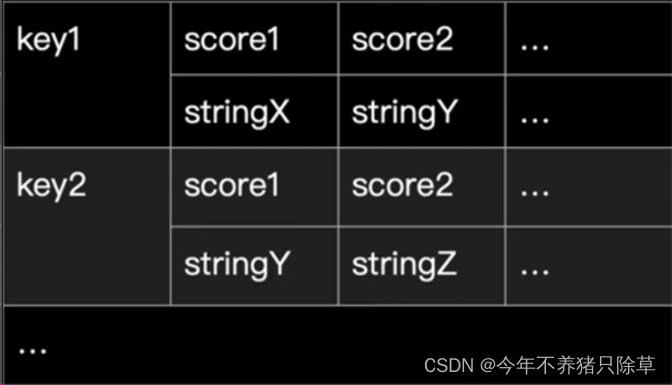
有序集合ZSet
有序集合类型 sortedset:不允许重复元素,且元素有顺序.每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
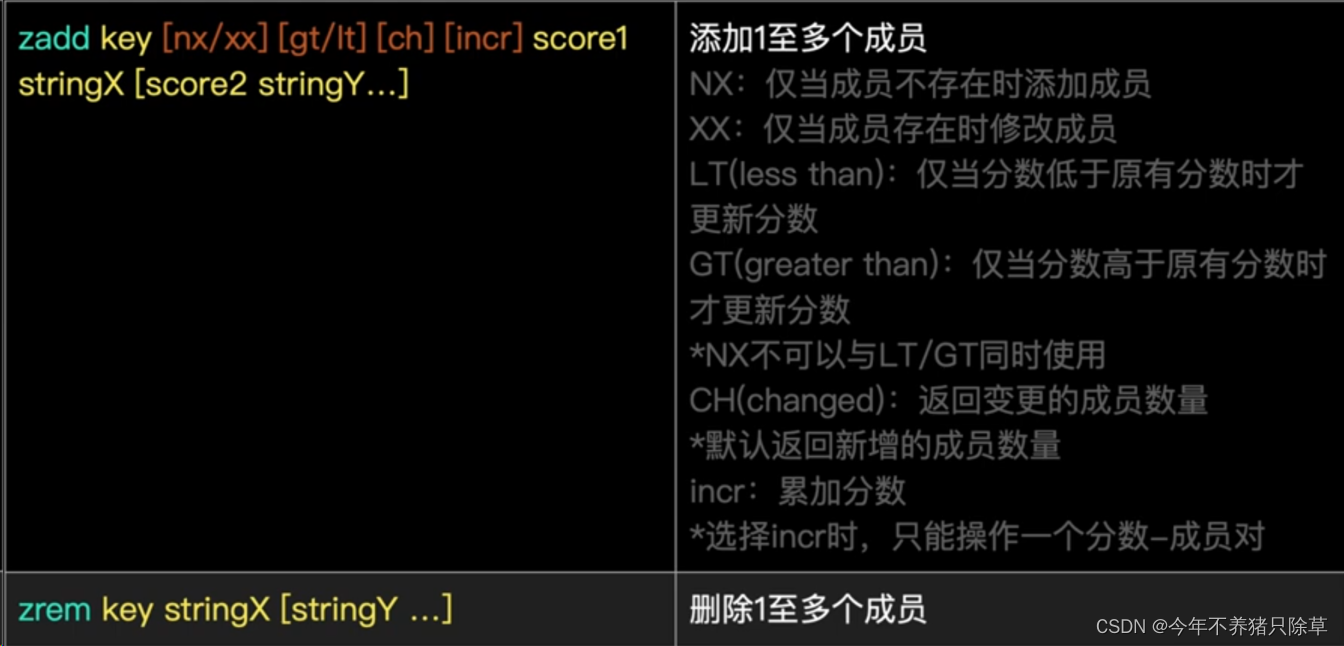
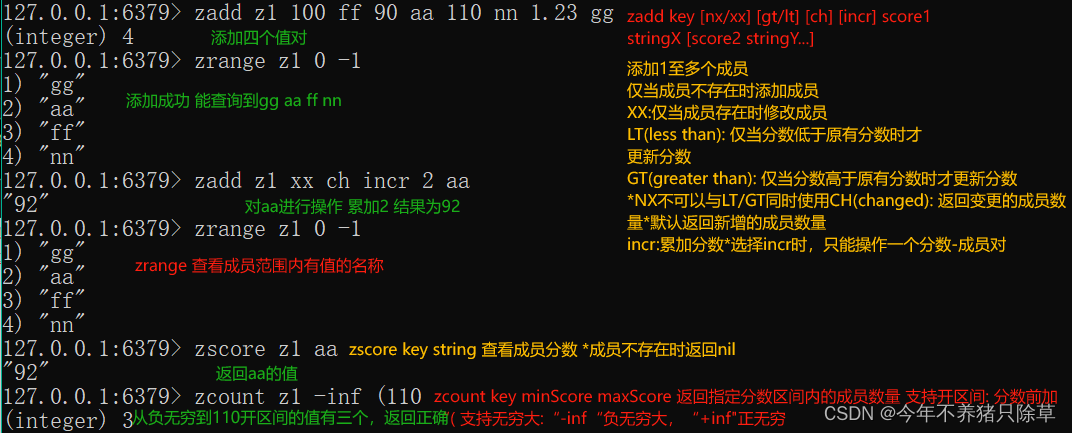
1. 存储:zadd key score value
127.0.0.1:6379> zadd mysort 60 zhangsan
(integer) 1
127.0.0.1:6379> zadd mysort 50 lisi
(integer) 1
127.0.0.1:6379> zadd mysort 80 wangwu
(integer) 1
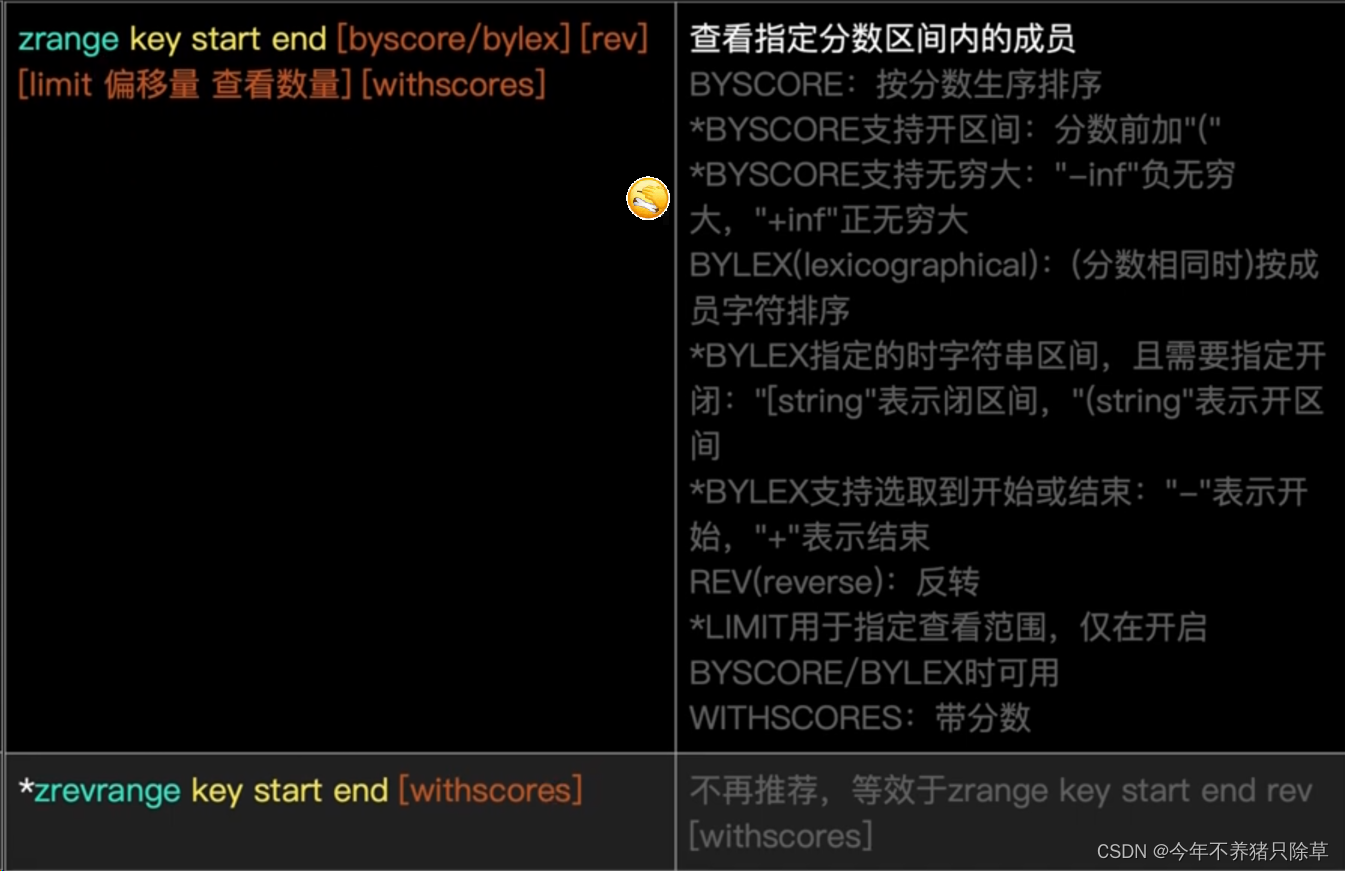
2. 获取:zrange key start end [withscores]
127.0.0.1:6379> zrange mysort 0 -1
1) "lisi"
2) "zhangsan"
3) "wangwu"
127.0.0.1:6379> zrange mysort 0 -1 withscores
1) "zhangsan"
2) "60"
3) "wangwu"
4) "80"
5) "lisi"
6) "500"
3. 删除:zrem key value
127.0.0.1:6379> zrem mysort lisi
(integer) 1
- key-score1:stringX,score2:stringY…
- 分数分为(范围为float64)的浮点数,且可以重复
基本操作

- 执行操作
按区间操作
- 概念语法



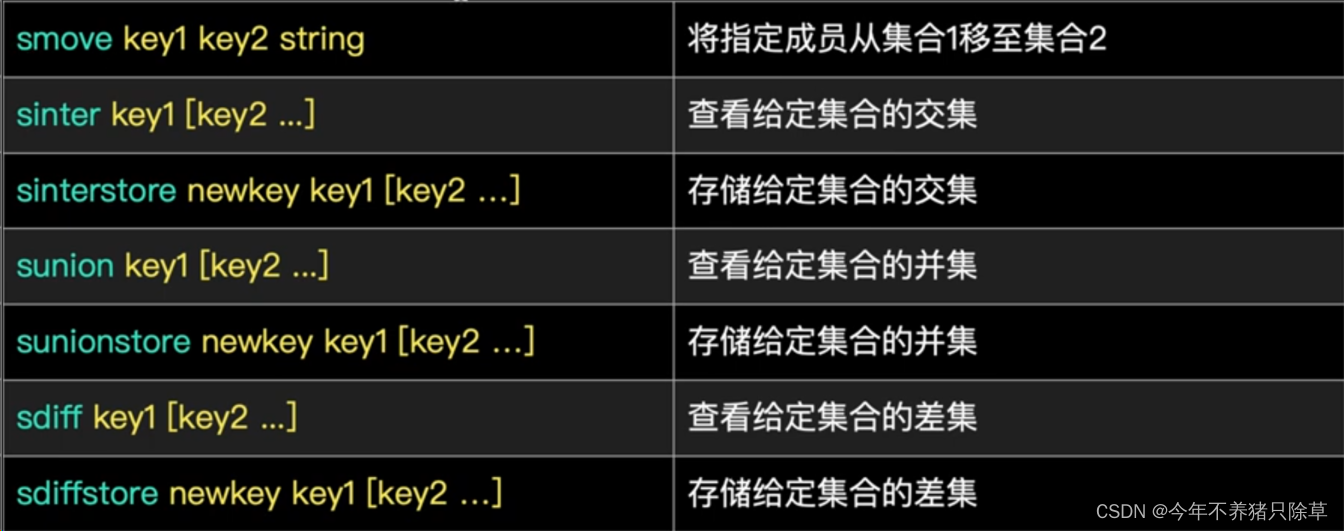
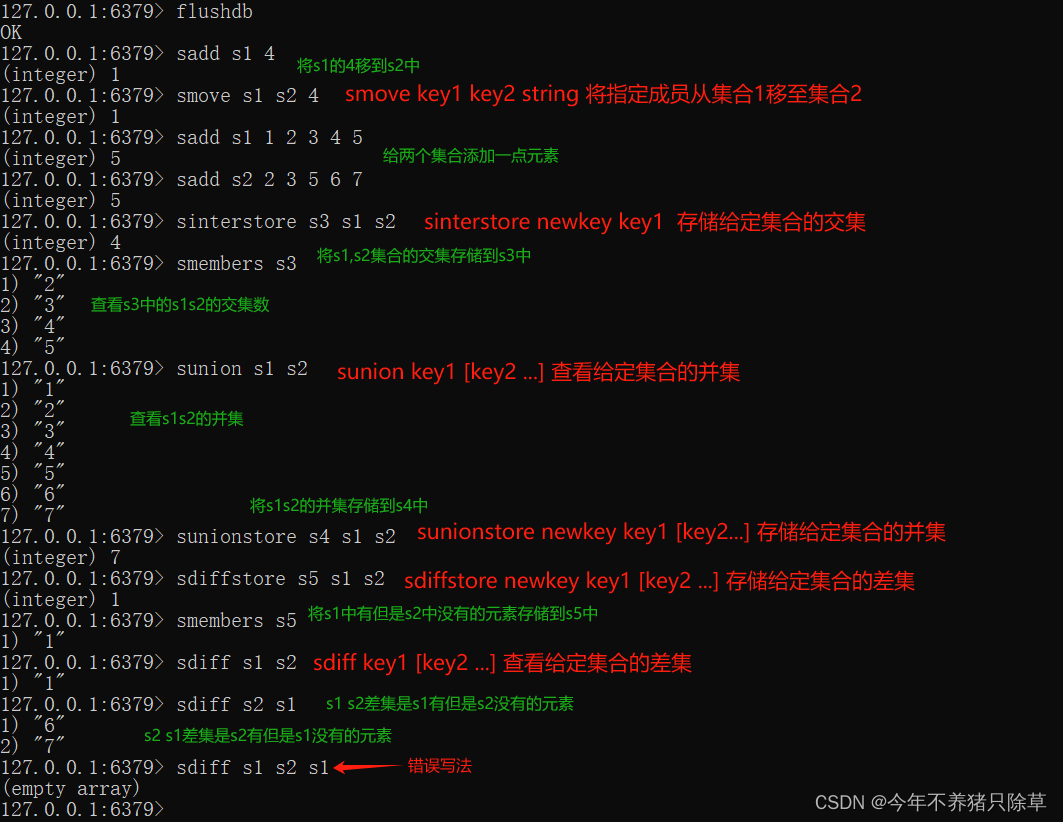
交集、并集、差集
- 概念语法
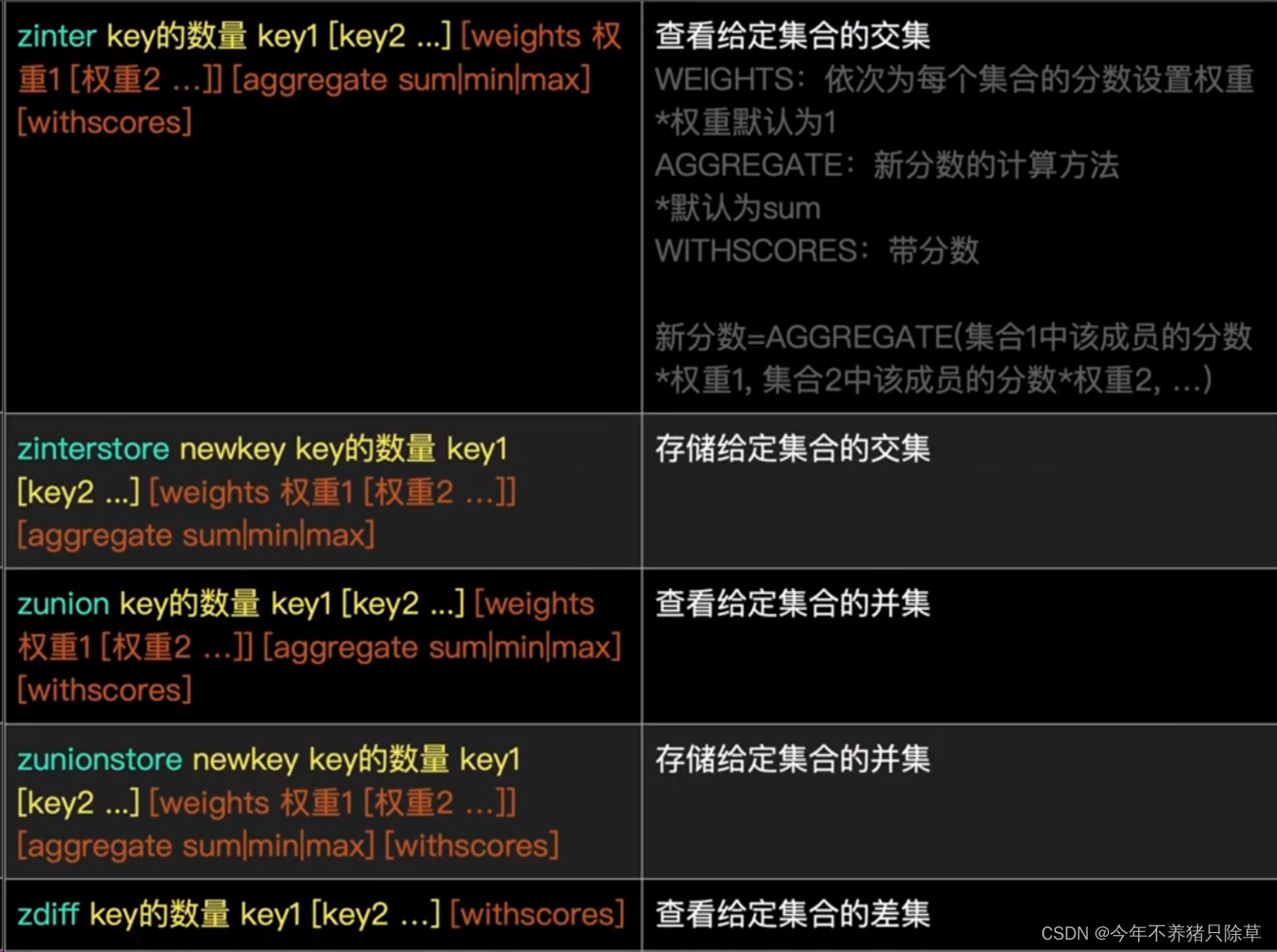

遍历
遍历整个数据库
- 概念语法

- 执行操作
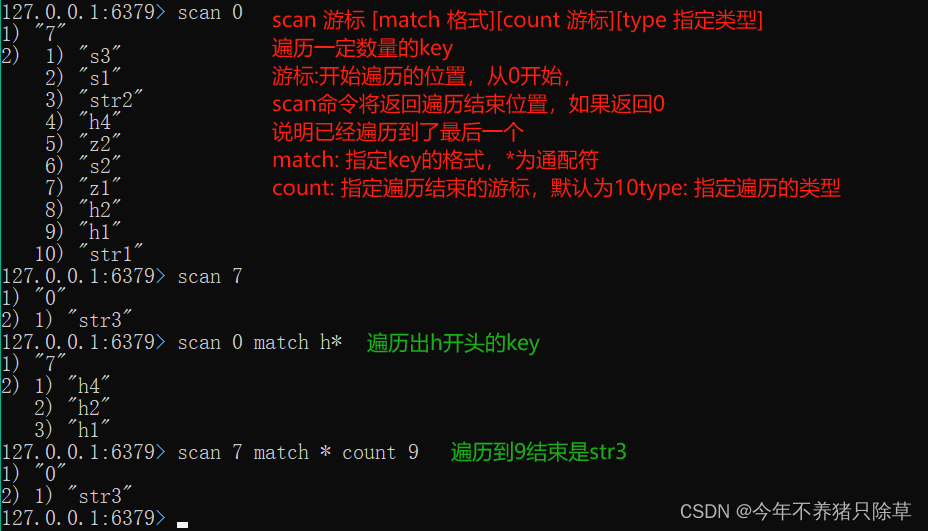
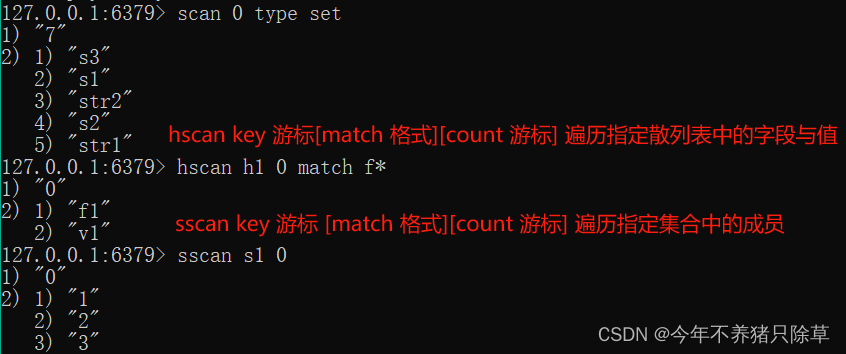
特定键值对的遍历
- 概念语法

- 执行操作
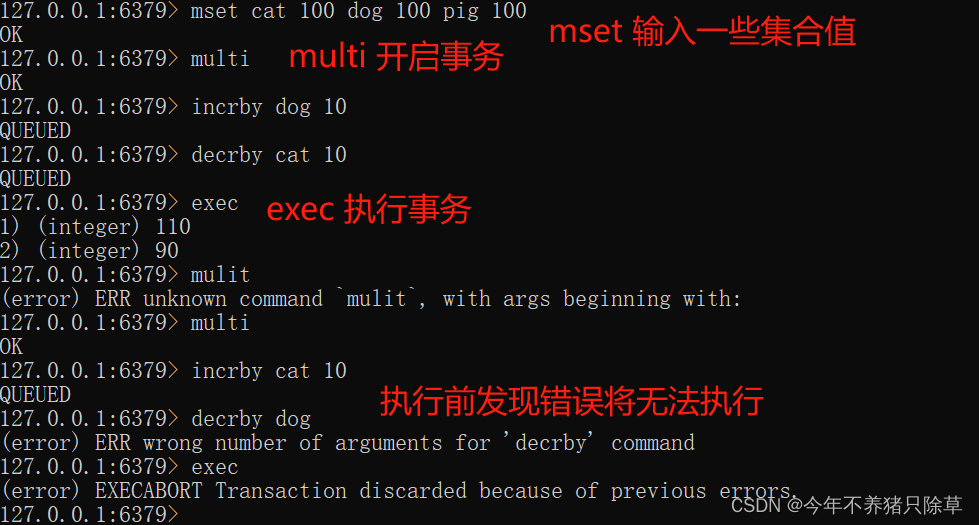
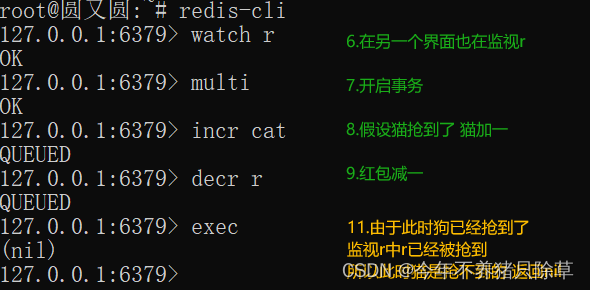
事务
基本操作

- 执行操作
监视

- 执行操作
按序号进行操作

Jedis
在Java 中操作 Redis
Redis 的Java 客户端很多,官方推荐的有三种:
- Jedis
- 以Redis命令作为方法名称,学习成本低,简单实用但是Jedis实例是线程不安全的,多线程环境下需要基于连接池来使用
- Lettuce
- Lettuce是基于Netty实现的,支持同步、异步和响应式编程方式,并且是线程安全的。支持Redis的哨兵模式、集群模式和管道模式。跟spring融合较好
- Redisson
- Redisson是一个基于Redis实现的分布式、可伸缩的Java数据结构集合。包含了诸如Map、Queue、LockSemaphore、AtomicLong等强大功能
Spring 对 Redis 客户端进行了整合,提供了 Spring Data Redis,在Spring Boot项目中还提供了对应的Starter,即spring-boot-starter-data-redis
使用Jedis操作Redis的步骤
- 引入依赖
需要新建一个maven文件,在文件内写入如下代码
<dependency>
<groupld>redis.clients</groupld>
<artifactld>jedis</artifactld>
<version>3.7.0</version>
</dependency>
- 获取连接
Jedis jedis = new Jedis("localhost", 6379);//相当于jdbc的connection
- 执行操作
- 关闭连接
代码实现
测试类
package com.svt.test;
import org.junit.Test;
import redis.clients.jedis.Jedis;
import java.util.Set;
/**
* 使用Jedis操作Redis
*/
public class JedisTest {
@Test
public void testRedis(){
// 获取连接
Jedis jedis = new Jedis("localhost", 6379);//相当于jdbc的connection
// 选择库 默认0
jedis.select(0);
// 执行具体的操作
//存入数据
String result = jedis.set("username", "wonwoo");
System.out.println("result="+result);
//获取数据
String value = jedis.get("username");
System.out.println("username="+value);
//删除数据
//jedis.del("username");
jedis.hset("myhash","addr","bj");
String hvalue = jedis.hget("myhash", "addr");
System.out.println(hvalue);
Set<String> keys = jedis.keys("*");
for (String key : keys) {
System.out.println(key);
}
if (jedis!=null){
// 关闭连接
jedis.close();
}
}
}
















 1846
1846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











