








摘要 —— 在地球观测相关应用中,多传感器融合具有重要意义。例如,高光谱图像(HSIs)提供了丰富的光谱信息,而激光雷达(LiDAR)数据提供了高程信息,将HSI和LiDAR数据一起使用可以实现更好的分类性能。本文提出了一个名为补丁到补丁卷积神经网络(PToP CNN)的无监督特征提取框架,用于高光谱和激光雷达数据的协同分类。具体来说,首先开发了一个三塔PToP映射,以从HSI到LiDAR数据寻求准确表示,旨在合并两种不同源之间的多尺度特征。然后,通过集成设计的PToP CNN的隐藏层,期望提取的特征具有深度融合特征。因此,不同隐藏层的特征被连接成一个堆叠向量,输入到三个全连接层中。为了验证所提出的分类框架的有效性,实验在两个基准遥感数据集上执行。实验结果表明,所提出的方法在与一些最先进的分类器(如双分支CNN和上下文CNN)相比时提供了更优越的性能。
关键词 —— 深度卷积神经网络(CNN),特征提取,高光谱图像(HSI)分类,多传感器融合。
引言
传感器技术最近取得了重要进展[1]-[4],使我们能够测量地球表面物体的各个方面。遥感高光谱图像(HSIs)提供了丰富的光谱信息,以唯一地区分各种材料,从而实现土地覆盖类别的更精细分类[5]-[8]。然而,在某些情况下,可能需要借助不同源的信息来补充仅由高光谱仪器提供的信息,以进一步改进和/或细化分类。为此,文献中已经研究了一系列融合不同源收集数据的方法[9],[10]。激光雷达(LiDAR)数据提供了被调查区域的高程信息,是补充HSI独提供信息的非常有用来源[11],[12]。HSI和LiDAR的协同分类已在各种应用中广泛使用,如复杂区域分类[13],森林火灾管理[14]等,因其良好的性能。许多研究表明,在集成HSI和LiDAR数据后,分类性能得到了提高。例如,在[15]中,LiDAR用于场景分割,HSI数据用于分类分割区域;在[16]中,Ghamisi等人利用形态学消光剖面提取HSI和LiDAR特征;在[17]中,Rasti等人使用消光剖面进行联合特征提取,然后通过总变分分量分析进一步融合。另一方面,Liao等人[18]强调,简单串联或堆叠特征,如形态学属性剖面,可能包含冗余信息,尽管这类特征融合方法简单,融合系统可能表现不佳(甚至更糟),这不如使用单一类型的特征。这是因为不同特征的元素值可能显著不平衡,不同特征包含的信息不是平等表示或测量的。Khodadadzadeh等人[19]进一步指出,堆叠特征的维度增加和有限的标记样本数量可能导致维数灾难问题。因此,在[20]中,提出了一种HSI和LiDAR数据分类的决策融合方法;此外,线性和非线性特征也通过决策融合策略在[21]中结合。尽管这些基于决策融合的研究在分类任务上表现出色,但它们不能成为处理有限训练样本的可行解决方案,只是避免了对训练样本需求更多的特征提取过程。如何提取包含HSI和LiDAR数据完整信息的联合特征,而不遭受Hughes效应的困扰,仍然面临巨大挑战。传统上,依赖专家经验和参数设置的手工工程特征一直是分类任务的主要工具[22];然而,Liu等人进一步指出,为不同分类任务找到合适的参数生成特征是困难的。最近,基于深度学习的方法已经在许多领域广泛取代了手工工程方法,并因其自动提取稳健和高级特征的能力而引起广泛关注,这些特征通常对输入的大多数局部变化是不敏感的,在更深层。Zhang等人[23]探索了遥感场景中的显著特征,以构建用于场景分类的网络。构建遥感图像的深度网络的一般方法已在[24]中系统分析,该分析尝试评估所有最先进的深度学习方法在遥感图像上的有效性。为了提取HSI中的高级特征,通过无监督方式构建了一个具有多层堆叠自编码器(AE)的深度学习架构[25]。卷积神经网络(CNN),与具有相同隐藏单元数量的全连接网络相比,需要更少的参数,已在图像分析中引起越来越多的关注。例如,CNN被用于提取HSI分类特征,并在[26]中获得了优异的性能。此外,一套基于CNN的改进方法用于遥感分类任务,并取得了优异的性能[27],[28]。CNN方法只有在确保有足够的标记训练样本供应时才能取得有希望的结果[22],[29]-[31];不幸的是,在实际情况下,特别是对于遥感数据,训练中只有少量的标记样本可用。换句话说,监督CNN通常受到有限训练样本或不平衡数据集的困扰。同时,深度模型也被训练以通过无监督学习方法寻找特征表示。无监督特征学习,可以快速访问任意数量的未标记数据,已成为学术界和工业界关注的焦点。通常,无监督特征学习的主要目标是从未标记数据中提取有用特征,检测和消除输入冗余,并仅在鲁棒和区分表示中保留数据的基本方面[32]。Romero等人[33]提出了从监督CNN到无监督CNN的先驱工作,用于学习光谱-空间特征,该工作基于稀疏学习来估计网络权重。然而,这个模型是逐层贪婪训练的,即不是端到端网络。图像到图像翻译网络[34]属于端到端网络,将一个域中的图像映射到另一个域以学习翻译函数。此外,可以在端到端网络的自动学习过程中有效地探索具有足够信息的特征表示,通过最小化输入样本与其重建之间的重建误差[35]。在本文中,研究了通过补丁到补丁(PToP)CNN进行HSI和LiDAR数据联合特征提取的直观但有效的过程。所提出的框架指的是通过PToP CNN进行无监督特征提取框架,以学习HSI和LiDAR数据之间的联合特征,而不考虑标记数据。PToP CNN基于所谓的编码器-解码器翻译架构。具体来说,输入源HSI首先通过编码路径(编码器)映射到隐藏子空间,然后通过解码路径(解码器)反向重建输出源LiDAR数据。同时,在翻译过程中的隐藏表示可以被视为HSI和LiDAR数据的融合特征。之后,从PToP CNN的不同隐藏层提取的特征通过层次融合模块集成,然后转换为堆叠向量并输入到三个全连接层(3 FC)以产生最终的分类图。主要贡献可以总结如下。1)提出了一个多尺度PToP CNN进行特征提取,包括三个隧道,覆盖具有良好设计结构的卷积滤波器库。学习这样一个端到端网络以进行HSI和LiDAR数据的联合特征提取尚未被研究。不同的隐藏节点可以精确捕获不同信息级别的属性,确保方便地访问多尺度联合特征。2)层次融合模块可以最优地利用PToP CNN提取的联合特征进行分类。通过该模块,从多尺度滤波器库获得的初始空间-光谱特征然后组合在一起,形成一个联合空间-光谱特征图。该特征图表示了HSI和LiDAR数据的丰富光谱和空间属性,然后输入到基于卷积的块中进行“多层块连接”操作。3)设计的PToP CNN的神经权重学习过程是完全无监督的,独立于标记样本。在所提出的PToP CNN中,首先通过滑动窗口从HSI和LiDAR数据中收集训练补丁,并且基于这些补丁的学习过程可以确保即使在小尺寸标记样本的情况下也能完善特征。本文的其余部分组织如下。第II节介绍了一些相关工作。第III节描述了所提出的方法。实验结果在第IV节讨论。结论在第V节总结。
相关工作
几个传统的无监督端到端网络架构已被用于多种目的,例如单源特征学习或图像分割。这里,回顾了这些模型的一些基本原则。
A. 经典自动编码器
基本自动编码器(AE)采用输入x ∈ ℜD,通过非线性映射最小化重建误差来寻找x的表示a ∈ ℜN[35]。AE的架构涉及编码器和解码器。编码器将输入x映射到隐藏表示a,编码参数W和b
a = f(Wx + b) (1)
其中W是在训练过程中估计的权重矩阵,b是偏置向量,f(·)代表非线性激活函数,如sigmoid函数和修正函数。编码的特征表示a然后由解码器用于基于反向映射重建输入x。数学上,可以表示为
y = f(W’a + b’) (2)
其中W’和b’是相应的解码参数。典型的AE网络[32]通过最小化输入x和解码重建的输入向量x之间的误差,即y,使∥x − y∥2 2 → 0。AE的参数通常通过随机梯度下降(SGD)[36]进行优化。特别是,如果x可以准确重建为y,隐藏表示a可以从x中提取足够的信息。在这种情况下,隐藏表示a可以被视为x的特征。因此,AE模型可以通过编码和解码步骤实现非线性特征提取。
B. 用于图像分析的端到端架构
众所周知,卷积网络最常见的用途是分类任务[37],其中对图像的输出是一个单一的类别标签。然而,在许多视觉任务中,所需的输出应包括定位;例如,应该为每个像素分配一个类别标签。现有的端到端网络架构,预测任意大小输入的密集输出,通过密集前馈计算和反向传播端到端和像素到像素地进行训练。在端到端网络中,子采样池化操作使学习过程成为可能,而上采样层使像素级预测成为可能[38]。换句话说,用于图像分割的端到端架构通常由用于上下文捕获的编码器路径和用于精确定位的对称解码器路径组成。广泛使用的用于分割的深度架构具有与图1中所示相同的端到端结构,但在编码器-解码器网络设计和训练策略上有所不同。例如,Long等人[38]构建了完全卷积网络,这些网络接受任意大小的输入,并产生相应大小的输出,具有高效的推理和学习。此外,在[37]中,称为U-Net的架构由扩展路径和扩展路径组成,可以使用非常少的样本图像进行端到端训练。
所提出的分类框架
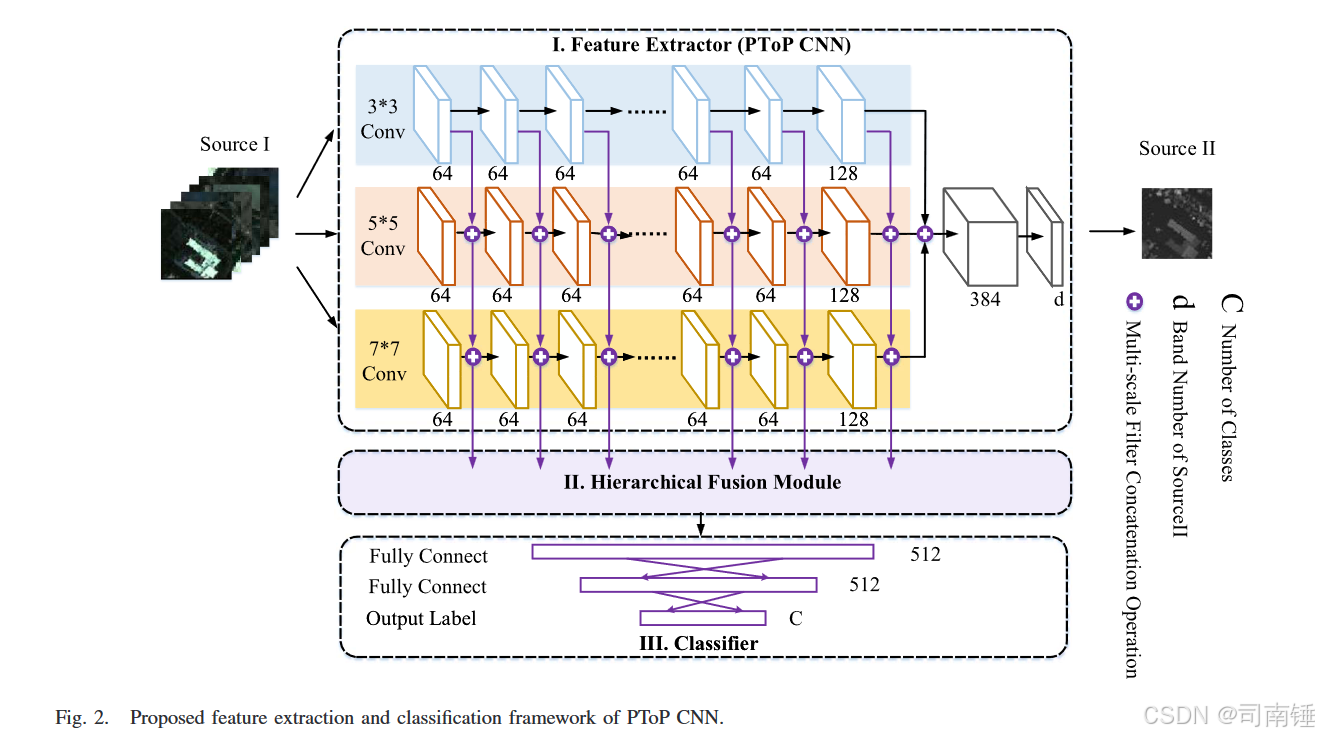
在上述方法中,具有编码器-解码器架构的特征提取方法仅涉及一种类型的数据源。显然,编码器-解码器架构具有两个品质:1)特征提取和2)两个域之间的翻译。例如,图像分割任务总是将图像从一个域映射到另一个域。与现有的单源特征提取方法不同,我们专注于编码器-解码器架构,以在特征提取过程中集成两个域之间的翻译,从而实现HSI和LiDAR数据的无缝融合。在本节中,详细描述了用于HSI和LiDAR数据融合的无监督特征提取方法,并详细阐述了网络训练。如图2所示,所提出的框架包括一个名为PToP CNN的三塔特征提取器(第一部分),一个层次融合模块(第二部分),后跟一个由全连接层和softmax损失组成的分类器(第三部分)。
A. 通过PToP CNN进行特征提取
无监督PToP CNN框架旨在学习两个图像域之间的翻译函数。设XsourceI和XsourceII为不同域中的两个图像,XsourceI代表HSI数据,XsourceII代表LiDAR数据。与广泛使用的监督方式不同,我们尝试以无监督的方式发现XsourceI和XsourceII之间的关系。首先,我们假设XsourceI和XsourceII之间的关系不仅存在于整个图像层面,还存在于局部区域层面[34]。此外,对于任何给定的补丁xsourceI(从XsourceI派生的补丁)和xsourceII(从XsourceII派生的补丁),存在一个底层表示hW,b(xsourceI),使得可以从该底层表示用补丁xsourceI恢复补丁xsourceII,并且该底层表示可以从每对补丁xsourceI-xsourceII计算得出。数学上,翻译过程用权重W和偏置b表示为
hW,b(xsourceI) ≈ xsourceII (3)
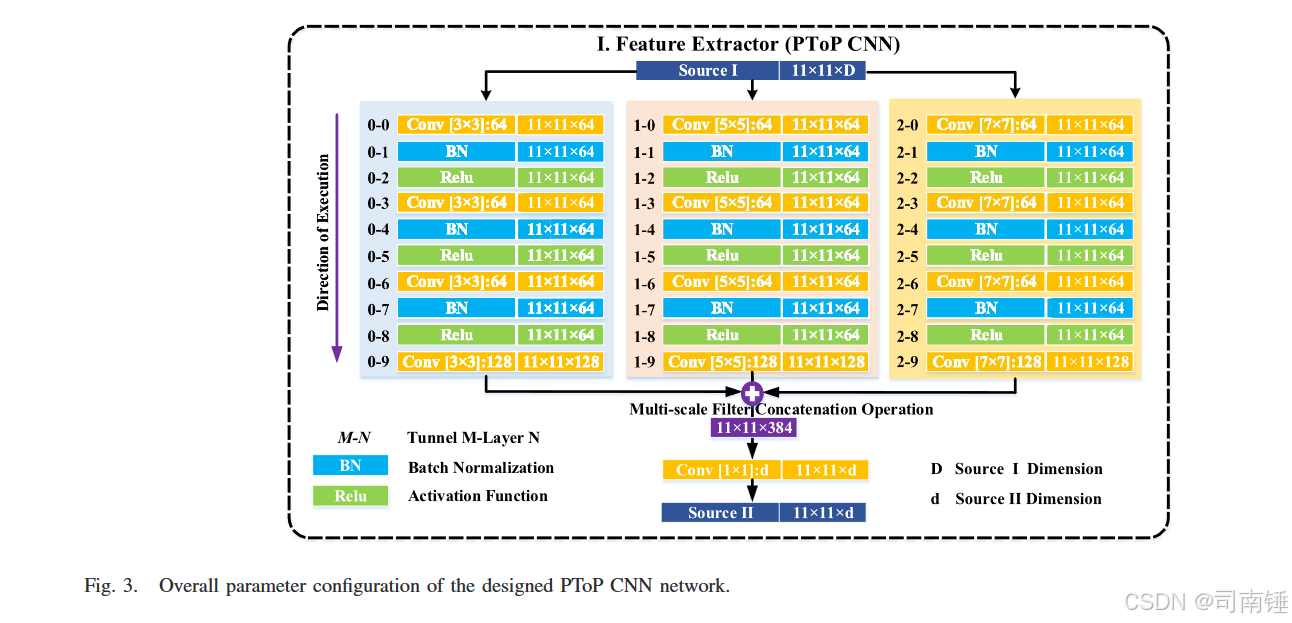
其中xsourceI和xsourceII可以被视为经典AE[35]的输入和输出。xsourceII是PToP CNN的学习对象,其值和内在特性是通过对所有隐藏单元进行反向调整的唯一标准。在完全训练的AE中,(3)中的翻译过程可以被视为从xsourceI和xsourceII中提取的融合特征。如图2所示,Part I的架构反映了翻译过程,将在图3中详细说明。常见的CNN模型通常涉及多层神经元,每层提取不同级别的特征。而在PToP CNN中,如图3所示,应用于输入图像的卷积层使用多尺度滤波器组,同时通过三个不同大小的基于卷积的塔(即3 × 3 × D,5 × 5 × D和7 × 7 × D,其中D是特征带的数量)卷积输入图像。3 × 3 × D隧道专注于处理光谱相关性,而5 × 5 × D和7 × 7 × D隧道用于开发HSI和LiDAR数据的局部空间相关性。PToP CNN中三尺度特征提取器的输出组合在一起,形成一个联合特征图,用于重建源II(LiDAR数据)。由于来自最后一个卷积层的特征图的维度与源II中的带数不同,因此执行最后的卷积操作以使它们一致。三塔特征提取器具有大量的参数,可能在计算上很昂贵,并且三个卷积隧道的输出合并增加了网络的大小,这不可避免地导致了高计算复杂性。随着网络大小的增加,用有限的训练样本优化网络也面临着过拟合和发散的问题。幸运的是,在无监督设置中,设计的PToP网络的训练样本数量与HSI和LiDAR补丁的数量有关,而不是标记像素。图4中所示的补丁预处理部分将在第III-C节中描述。
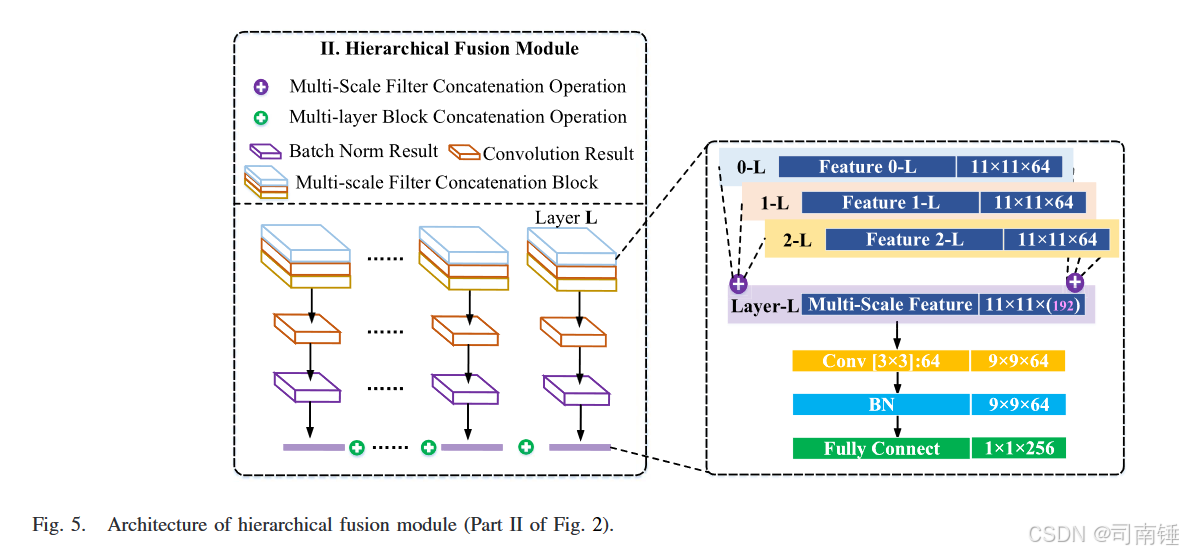
B. 层次融合模块
在PToP网络下,除了高级特征外,HSI和LiDAR数据之间还共享许多低级和中级特征,例如城市图像场景中某些建筑物的边缘位置。特别是,如图5所示(详细阐述了图2的Part II),提供了层次融合模块以集成不同层次的特征,包括不同滤波器尺度的卷积和不同的卷积层。多尺度滤波器组,在概念上类似于[39]中的Inception模块,被采用以充分利用输入图像的不同局部结构。在所提出的框架中,多尺度滤波器组以不同的方式采用;在翻译过程中,同时开发局部空间结构和局部光谱相关性,以更好地集成HSI和LiDAR数据信息,这是通过“多尺度滤波器连接操作”实现的,如图5所示。此外,在设计的PToP CNN中,不同的隐藏层表示不同的特征;例如,较浅的层可能从数据源I中提取更多信息的特征,而较深的层提取更多来自数据源II的抽象特征。也就是说,通过所提出的PToP CNN提取的特征涉及各种空间尺度和每个图像域中所拥有的比例,即源I和源II。在不同隐藏层提取的特征通过多层块连接操作融合,如图5所示,进一步确保信息的完善性。具体来说,我们选择了PToP CNN中的八个不等层,即第2至第9层。总的来说,所提出的PToP CNN不仅可以提供两个数据源之间的优秀映射,还可以提供来自不同尺度和不同层次的不等隐藏层的多尺度和不同级别的特征。此外,层次融合模块可以发挥作用,构建集成层次结构,并且模块的第一阶段是实现多尺度滤波器连接操作。然后,每个层中的多尺度连接数据被输入到网络中,进行具有空间核(例如,3 × 3核)的卷积操作。在批量归一化[40],[41]之后,特征然后被展平并输入到全连接层以进行多层块连接操作。
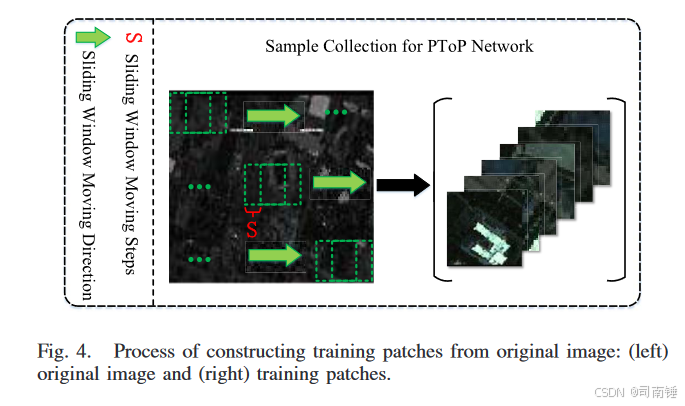
C. PToP CNN的训练过程
对于PToP CNN,通过滑动窗口以无监督方式收集训练补丁,如图4所示。通过图4所示的过程收集HSI和LiDAR补丁,每个HSI-LiDAR补丁对在同一区域获得,从而确保两个源数据之间的高相关性,以进行进一步的联合特征提取。S的值(移动步长)设置为2,窗口大小为11 × 11,训练样本的总数约为[(宽度×高度)/S^2](宽度和高度是图像的空间大小),确保足够的训练样本。对于层次融合阶段和最终分类,使用简单但有效的数据增强方法,该方法在不引入额外标记成本的情况下产生额外数据。具体来说,生成一个随机种子以控制训练阶段的逆时针旋转角度,90°,180°,270°和360°。然后,训练过程分为三个阶段,如图2所示。在第一阶段,从源I(HSI数据)派生的训练补丁输入到设计的PToP网络中,并且详细的网络配置如图3所示。之后,输入样本流经PToP网络以获得不同层次的特征(不同的滤波器尺度,不同的层)。因此,获得了“层次融合模块”的输入,其中详细的参数设置和网络结构如图5所示。图5的右半部分说明了其中一个分支,一个特定层L,包括一些固定操作,卷积和批量归一化。由于同时优化8个分支的参数是困难的,因此分别训练层次融合模块的每个分支。当8个分支合并时,预训练的特征提取器从输入数据中提取相应的特征,其全连接层和softmax预测层被移除。8个分支中剩余的层是固定的或可训练的,具有SGD规则的小学习率。所有分支被连接以生成最终的信息特征向量。在学习过程中,所有数据都被归一化到0-1范围内,以加速网络的收敛过程。所有卷积层的权重和偏置都使用Glorot归一化进行初始化,然后使用小学习率进行更新。
实验和分析
在本节中,使用两个广泛使用的遥感数据集来验证所提出方法的性能。对于所提出的PToP CNN,所有程序都使用Python语言实现,网络是使用TensorFlow1和高级API Keras2构建的。TensorFlow是一个用于数据流图的数值计算的开源软件库,Keras可以被视为TensorFlow的简化接口。所有实验都是在配备Ubuntu 14.04和GTX-1080 GPU的个人计算机上进行的。
A. 实验数据
- 休斯顿数据:第一个场景是由NSF资助的中心于2012年6月在休斯顿大学校园及其邻近地区获取的[19]。数据由HSI和LiDAR派生的DSM(数字表面模型)组成,两者都包含349×1905像素,空间分辨率为2.5米。高光谱数据是在2012年6月23日获取的。传感器离地面的平均高度是5500英尺。HSI场景由144个光谱带组成,波长范围从0.38到1.05微米,包括15个类别。LiDAR数据是在2012年6月22日获取的。传感器离地面的平均高度是2000英尺。表I列出了可用的训练和测试样本。2) 特伦托数据:第二个场景是在意大利特伦托市南部的一个农村地区获取的。数据由600 × 166像素组成,涵盖六个类别,空间分辨率为1米。HSI数据由AISA Eagle传感器[17]捕获,包括63个光谱带,覆盖范围从0.42到0.99微米。LiDAR数据由Optech ALTM 3100EA传感器获取。表II列出了可用的训练和测试样本。
B. 参数调整
为了验证第III-B节中描述的层次融合策略,我们比较了使用不同层次的PToP CNN特征的分类结果。如图3所示,为特定的PToP特征设计了一个独特的编号。例如,在M-N中,M代表卷积隧道,N代表层索引。全连接层与softmax损失作为分类器。1) 多层比较:图6显示了使用不同层次的PToP特征的分类性能。更具体地说,在每一层中,使用大小为11 × 11 × 192的多尺度特征,如在图5的右侧所澄清的。很明显,不同隐藏层的特征对分类性能有很大影响,但是从较浅层(即层0和层1)派生的特征表现不佳。2) 多尺度比较:我们进一步利用PToP特征提取器的不同分支的效果。表III列出了使用不同滤波器尺度(即3 × 3,5 × 5和7 × 7)的单隧道PToP特征提取器提取的特征的总体准确性(OA),平均准确性(AA)和Kappa系数(Kappa)。图7说明了单隧道特征提取器的详细网络结构。实验结果表明,使用不同滤波器尺度的单隧道PToP特征提取器提取的特征产生不同的分类性能,5 × 5的滤波器尺度提供了最佳性能。此外,所提出的三隧道特征提取器实现了进一步的改进;OA分别为休斯顿数据的92.48%和特伦托数据的98.73%。3) 学习率:学习率控制训练过程中梯度下降的步骤,也影响网络的学习行为。在实际实施中,该参数以Adam[42]的初始值策略设置。测试了不同的学习率,并使用相应的融合特征通过3 FC获得分类结果。如表IV所列,两个实验数据的最佳学习率是0.001。4) 有/无微调比较:实际上,微调过程在实现更好的分类性能和构建更强大的网络中起着至关重要的作用[29]。考虑到图6的实验分析,与第2至第9层相关的分支首先被训练,微调策略基于预训练的8层。低级特征是通过预训练的第2至第9层提取的,然后通过多层块连接集成以实现预期目标。图8显示了有和没有微调的分类性能。可以观察到,微调策略比没有微调对每个数据的大多数类别都取得了更好的性能。由于微调策略可以有效地减少计算量并提高计算效率,从而实现更好的分类性能,因此它在我们的后续实验中被采用。
C. 分类性能
为了验证所提出方法的有效性,该模型与几种分类器进行了比较,如传统的SVM和ELM,最近开发的CNNPPF[26],双分支CNN[29]和上下文CNN[31]。注意,基于SVM的方法是使用LIBSVM工具箱[3]实现的,所有比较方法都使用最佳参数实现。为了清晰起见,以下是一些定义:HSI数据表示为H,LiDAR数据用L表示,H + L表示HSI和LiDAR数据被连接在一起进行分类。此外,我们讨论了几个协同分类框架;即,SVM(H+L),CNN-PPF(H+L),ELM(H+L),双分支CNN(H+L)和上下文CNN(H+L)。表V和表VI列出了两个实验数据的OA,AA和Kappa。所提出的PToP CNN明显优于其他方法。以休斯顿数据为例,所提出的PToP CNN的OA为92.48%,比双分支CNN[29]高出4.5%,比CNN-PPF[26]高出9%以上。此外,我们的方法比经典的ELM[H+L]和SVM[H+L]分别高出约11%和12%。显然,由于更强大的特征表示,所提出的HSI和LiDAR数据的联合特征提取方法可以在与其他比较基线相比时显著提高分类准确性。对于分类性能的视觉评估,分类图如图9和图10所示。此外,还提供了整个图像场景的地面真实图和伪彩色图(包括未标记的像素)以供清晰。可以清楚地注意到,所提出的方法产生了最准确和无噪声的分类图,例如图10中的Vineyard类别。同样,可以得出结论,视觉结果与表V和表VI中的结果一致。图11进一步列出了使用不同数量的训练样本的方法的分类性能,以评估所有方法对训练样本大小的敏感性。训练样本的百分比(如表I和表II中所列)从20%变为100%。显然,所提出的方法始终优于其他方法。请注意,即使对于极小的训练数据大小,例如20%,所提出的网络仍然提供出色的分类性能。例如,在图11(a)中,使用20%的训练样本,所提出方法的准确性约为89%,而其他方法的准确性都低于80%。这证实了所提出的框架对小训练样本大小是鲁棒的。表VII总结了所提出方法的训练和测试时间。训练过程需要更长的时间,而所有方法的整个场景的测试相对较快。PToP CNN更耗时,这实际上是由于两个原因。首先,所提出方法的执行包括一个单独但有效的联合特征提取过程和分类过程,而其他方法只关注分类过程。其次,PToP CNN的迭代周期为500,远高于其他方法。
结论
在本文中,提出了PToP CNN模型,用于联合特征提取,充分利用HSI和LiDAR数据中包含的丰富光谱信息和空间/上下文信息。实验结果表明,PToP特征提取器与层次融合模块相结合,可以同时利用HSI和LiDAR数据的信息,实现出色的协同分类性能。此外,PToP的特征提取过程是完全无监督的,从而确保了信息的完善性和在小训练样本大小下提取特征的鲁棒性。经过实验数据验证,所提出的方法已被证明比许多最先进的技术提供更高的准确性。
致谢
感谢P. Ghamisi博士提供特伦托数据。
参考文献
[1] X. Lu, Y. Yuan, and X. Zheng, “Joint dictionary learning for multispectral change detection,” IEEE Trans. Cybern., vol. 47, no. 4, pp. 884–897, Apr. 2017.
[2] Y. Xu, Z. Wu, J. Chanussot, and Z. Wei, “Joint reconstruction and anomaly detection from compressive hyperspectral images using Mahalanobis distance-regularized tensor RPCA,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 5, pp. 2919–2930, May 2018.
[3] S. Jia, L. Shen, J. Zhu, and Q. Li, “A 3-D Gabor phase-based coding and matching framework for hyperspectral imagery classification,” IEEE Trans. Cybern., vol. 48, no. 4, pp. 1176–1188, Apr. 2018.
[4] M. Zhang, W. Li, and Q. Du, “Diverse region-based CNN for hyperspectral image classification,” IEEE Trans. Image Process., vol. 27, no. 6, pp. 2623–2634, Jun. 2018.
[5] W. Li, E. W. Tramel, S. Prasad, and J. E. Fowler, “Nearest regularized subspace for hyperspectral classification,” IEEE Trans. Geosci. Remote Sens., vol. 52, no. 1, pp. 477–489, Jan. 2014.
[6] X. Zheng, Y. Yuan, and X. Lu, “Dimensionality reduction by spatial–spectral preservation in selected bands,” IEEE Trans. Geosci. Remote Sens., vol. 55, no. 9, pp. 5185–5197, Sep. 2017.
[7] Z. Wu et al., “GPU parallel implementation of spatially adaptive hyperspectral image classification,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 11, no. 4, pp. 1131–1143, Apr. 2018.
[8] L. Zhang et al., “Simultaneous spectral–spatial feature selection and extraction for hyperspectral images,” IEEE Trans. Cybern., vol. 48, no. 1, pp. 16–28, Jan. 2018.
[9] M. Khodadadzadeh, A. Cuartero, J. Li, A. Felicísimo, and A. Plaza, “Fusion of hyperspectral and LiDAR data using generalized composite kernels: A case study in extremadura, Spain,” in Proc. IGARSS, Milan, Italy, Jul. 2015, pp. 61–64.
[10] M. Zhang, W. Li, and Q. Du, “Collaborative classification of hyperspectral and visible images with convolutional neural network,” J. Appl. Remote Sens., vol. 11, no. 4, 2017, Art. no. 042607.
[11] J. Jung, E. Pasolli, S. Prasad, J. C. Tilton, and M. M. Crawford, “A framework for land cover classification using discrete return LiDAR data: Adopting pseudo-waveform and hierarchical segmentation,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 7, no. 2, pp. 491–502, Feb. 2014.
[12] M. Zhang, P. Ghamisi, and W. Li, “Classification of hyperspectral and LiDAR data using extinction profiles with feature fusion,” Remote Sens. Lett., vol. 8, no. 10, pp. 957–966, 2017.
[13] M. Dalponte, L. Bruzzone, and D. Gianelle, “Fusion of hyperspectral and LiDAR remote sensing data for classification of complex forest areas,” IEEE Trans. Geosci. Remote Sens., vol. 46, no. 5, pp. 1416–1427, Jun. 2008.
[14] B. Koetz, F. Morsdorf, S. Van der Linden, and B. Allgöwer, “Multisource land cover classification for forest fire management based on imaging spectrometry and LiDAR data,” Forest Ecol. Manag., vol. 256, no. 3, pp. 263–271, Jul. 2008.
[15] D. Lemp and U. Weidner, “Improvements of roof surface classification using hyperspectral and laser scanning data,” in Proc. ISPRS, Tempe, AZ, USA, Mar. 2005, pp. 14–16.
[16] P. Ghamisi, B. Höfle, and X. Zhu, “Hyperspectral and LiDAR data fusion using extinction profiles and deep convolutional neural network,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 10, no. 6, pp. 3011–3024, Jun. 2017.
[17] B. Rasti, P. Ghamisi, and R. Gloaguen, “Hyperspectral and LiDAR fusion using extinction profiles and total variation component analysis,” IEEE Trans. Geosci. Remote Sens., vol. 55, no. 7, pp. 3997–4007, Jul. 2017.
[18] W. Liao, R. Bellens, A. Pizurica, S. Gautama, and W. Philips, “Graph-based feature fusion of hyperspectral and LiDAR remote sensing data using morphological features,” in Proc. IGARSS, Melbourne, VIC, Australia, Jul. 2013, pp. 4942–4945.
[19] M. Khodadadzadeh, J. Li, S. Prasad, and A. Plaza, “Fusion of hyperspectral and LiDAR remote sensing data using multiple feature learning,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 8, no. 6, pp. 2971–2983, Jun. 2015.
[20] W. Liao, R. Bellens, A. Pižurica, S. Gautama, and W. Philips, “Combining feature fusion and decision fusion for classification of hyperspectral and LiDAR data,” in Proc. IGARSS, Quebec City, QC, Canada, Jul. 2014, pp. 1241–1244.
[21] C. Zhao, X. Gao, Y. Wang, and J. Li, “Efficient multiple-feature learning-based hyperspectral image classification with limited training samples,” IEEE Trans. Geosci. Remote Sens., vol. 54, no. 7, pp. 4052–4062, Jul. 2016.
[22] B. Liu et al., “Supervised deep feature extraction for hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 4, pp. 1909–1921, Apr. 2018.
[23] F. Zhang, B. Du, and L. Zhang, “Saliency-guided unsupervised feature learning for scene classification,” IEEE Trans. Geosci. Remote Sens., vol. 53, no. 4, pp. 2175–2184, Apr. 2015.
[24] L. Zhang, L. Zhang, and B. Du, “Deep learning for remote sensing data: A technical tutorial on the state of the art,” IEEE Trans. Geosci. Remote Sens., vol. 4, no. 2, pp. 22–40, Jun. 2016.
[25] Y. Chen, Z. Lin, X. Zhao, G. Wang, and Y. Gu, “Deep learning-based classification of hyperspectral data,” IEEE J. Sel. Topics Appl. Earth Observ. Remote Sens., vol. 7, no. 6, pp. 2094–2107, Jun. 2014.
[26] W. Li, G. Wu, F. Zhang, and Q. Du, “Hyperspectral image classification using deep pixel-pair features,” IEEE Trans. Geosci. Remote Sens., vol. 52, no. 2, pp. 844–853, Apr. 2017.
[27] S. Mei, J. Ji, J. Hou, X. Li, and Q. Du, “Learning sensor-specific spatial–spectral features of hyperspectral images via convolutional neural networks,” IEEE Trans. Geosci. Remote Sens., vol. 55, no. 8, pp. 4520–4533, Aug. 2017.
[28] Y. Li, H. Zhang, and Q. Shen, “Spectral–spatial classification of hyperspectral imagery with 3D convolutional neural network,” Remote Sens., vol. 9, no. 1, p. 67, Jan. 2017.
[29] X. Xu et al., “Multisource remote sensing data classification based on convolutional neural network,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 2, pp. 937–949, Feb. 2018.
[30] W. Li, G. Wu, and Q. Du, “Transferred deep learning for anomaly detection in hyperspectral imagery,” IEEE Geosci. Remote Sens. Lett., vol. 14, no. 5, pp. 597–601, May 2017.
[31] H. Lee and H. Kwon, “Going deeper with contextual CNN for hyperspectral image classification,” IEEE Trans. Image Process., vol. 26, no. 10, pp. 4843–4855, Oct. 2017. [32] L. Mou, P. Ghamisi, and X. Zhu, “Unsupervised spectral–spatial feature learning via deep residual conv–deconv network for hyperspectral image classification,” IEEE Trans. Geosci. Remote Sens., vol. 56, no. 1, pp. 391–406, Jan. 2018.
[33] A. Romero, C. Gatta, and G. Camps-Valls, “Unsupervised deep feature extraction for remote sensing image classification,” IEEE Trans. Geosci. Remote Sens., vol. 54, no. 3, pp. 1349–1362, Mar. 2016.
[34] M.-Y. Liu, T. Breuel, and J. Kautz, Unsupervised Image-to-Image Translation Networks, NIPS, Long Beach, CA, USA, Dec. 2017, pp. 700–708.
[35] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” Science, vol. 313, no. 5786, pp. 504–507, Jul. 2006.
[36] Y. LeCun et al., “Backpropagation applied to handwritten zip code recognition,” Neural Comput., vol. 1, no. 4, pp. 541–551, Dec. 1989.
[37] O. Ronneberger, P. Fischer, and T. Brox, “U-Net: Convolutional networks for biomedical image segmentation,” in Medical Image Computing and Computer-Assisted Intervention. Cham, Switzerland: Springer, Oct. 2015, pp. 234–241.
38] J. Long, E. Shelhamer, and T. Darrell, “Fully convolutional networks for semantic segmentation,” in Proc. Comput. Vis. Pattern Recognit., Boston, MA, USA, Jun. 2015, pp. 3431–3440.
[39] C. Szegedy et al., “Going deeper with convolutions,” in Proc. Comput. Vis. Pattern Recognit., Boston, MA, USA, 2015, pp. 1–9.




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











