








摘要:
高光谱(HS)图像以其连续的光谱信息而著称,能够通过捕捉细微的光谱差异来精细识别物质。由于其出色的局部上下文建模能力,卷积神经网络(CNNs)已被证明是HS图像分类中的强大特征提取器。然而,由于其固有网络骨架的限制,CNNs未能很好地挖掘和表示光谱签名的序列属性。为了解决这个问题,从序列的角度重新思考HS图像分类,并提出了一个新颖的骨干网络,称为SpectralFormer。与传统的transformers相比,SpectralFormer能够学习HS图像相邻波段的局部光谱序列信息,产生群组级光谱嵌入。更重要的是,为了减少在层间传播过程中丢失有价值信息的可能性,设计了一个跨层跳跃连接,通过自适应学习融合跨层的“软”残差,从浅层到深层传递类似记忆的组件。值得注意的是,提出的SpectralFormer是一个高度灵活的骨干网络,可以适用于像素级和块级输入。通过在三个HS数据集上进行广泛的实验来评估所提出的SpectralFormer的分类性能,显示了其超越传统transformers的优势,并与最先进的骨干网络相比取得了显著的改进。为了可重复性,这项工作的代码将可在GitHub上获得。
关键词: 高光谱图像分类,卷积神经网络,深度学习,局部上下文信息,遥感,序列数据,跳跃融合,transformer。
I. 引言:
在高光谱(HS)成像中,每个像素收集数百个(窄)波长带,覆盖整个电磁谱,这使得材料能够在细粒度水平上被识别或检测,特别是那些在视觉线索(例如,RGB)中具有极其相似光谱签名的材料[1]。这为各种高级地球观测(EO)任务提供了巨大的潜力,如准确的土地覆盖制图、精准农业、目标/对象检测、城市规划、树种分类、矿产勘探等。HS图像分类系统的一般顺序过程包括图像恢复(例如,去噪、缺失数据恢复)[2]-[5]、降维[6]、[7]、光谱解混[8]-[12]和特征提取[13]-[16]。其中,特征提取是HS图像分类中的关键步骤,受到了研究者的越来越多的关注。在过去的十年中,提出了大量的先进的手工和基于子空间学习的特征提取方法用于HS图像分类[17]。这些方法能够在小样本分类问题中表现良好。然而,当训练规模逐渐增加且训练集变得更加复杂时,它们往往会遇到性能瓶颈。可能的原因是这些传统方法的数据拟合和表示能力有限。受深度学习(DL)的巨大成功的启发,DL能够从大量多元化数据中发现内涵、内在和潜在的有价值知识[18],人们在设计和添加先进模块到网络中以从遥感数据中提取更多诊断特征方面做出了巨大努力。例如,Zhao等人[19]开发了一个使用HS和激光雷达(LiDAR)数据的联合分类框架,已被证明在从多源遥感数据中提取特征方面表现出色。Zhang等人[20]设计了一个非凡的块到块卷积神经网络(CNN),取得了比其他技术更好的结果。近年来,许多公认的骨干网络已广泛应用于HS图像分类任务[28],如自编码器(AEs)、CNNs、递归神经网络(RNNs)、生成对抗网络(GANs)、胶囊网络(CapsNet)、图卷积网络(GCNs)。Chen等人[21]堆叠多个自编码器网络,从通过主成分分析(PCA)[29]降维生成的HS图像中提取深度特征表示,并应用于HS图像分类。Chen等人[22]使用CNN代替堆叠的AEs,通过考虑HS图像的局部上下文信息来语义提取空间-光谱特征,实现了更高的分类准确率。Hang等人[23]设计了一个级联RNN用于HS图像分类,利用RNN可以有效地表示相邻光谱带之间的关系。在[24]中,GANs被改进,使其适用于HS图像分类任务,输入为三个PCA组件和随机噪声。Paoletti等人[25]通过定义一种新颖的空间-光谱胶囊单元,扩展了基于CNN的模型,为HS图像分类提供了高性能的框架,同时降低了网络设计的复杂性。Hong等人[26]在HS图像分类任务中对CNN和GCN进行了全面的比较,提出了一种小批量GCN(miniGCNs),为解决GCN中的大图问题提供了可行的解决方案,用于最先进的HS图像分类。
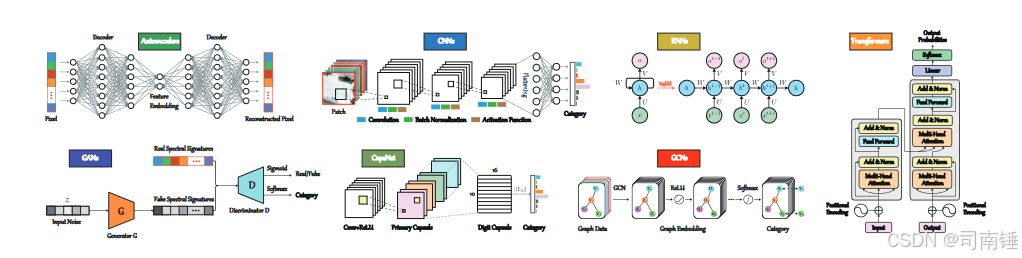
尽管这些骨干网络及其变体已经能够获得有希望的分类结果,它们在表征光谱序列信息(特别是在捕获光谱维度上的细微光谱差异方面)的能力仍然不足。图1给出了这些最先进的骨干网络在HS图像分类任务中的概述图。具体限制大致可以总结如下。
- 作为主流的骨干架构,CNNs在提取HS图像的空间结构信息和局部上下文信息方面表现出强大的能力。然而,一方面,CNNs几乎无法捕捉序列属性,特别是中长期依赖关系。这在HS图像分类任务中不可避免地遇到了性能瓶颈,尤其是在待分类类别种类繁多且光谱签名极其相似的情况下。另一方面,CNNs过于关注空间内容信息,这在光谱上扭曲了学习的序列信息。这在很大程度上增加了挖掘诊断光谱属性的难度。
- 与CNNs不同,RNNs是为序列数据设计的,它们按顺序累积地从HS图像中学习光谱特征。这种模式极度依赖于光谱带的顺序,并倾向于产生梯度消失,因此难以学习长期依赖关系[30]。这可能会导致捕获时间序列中光谱显著变化的困难。更重要的是,实际的HS图像场景中通常有大量的HS样本(或像素)可用,但RNNs无法并行训练模型,限制了实际应用中的分类性能。
- 对于其他骨干网络,即GANs、CapsNet、GCNs,尽管它们在学习光谱表示方面各自具有优势(例如,鲁棒性、等价性、样本之间的长期相关性),但它们的一个共同点是几乎都无法有效地建模序列信息。也就是说,光谱信息的利用是不充分的(这是使用HS数据进行精细土地覆盖分类或制图的关键瓶颈)。
针对上述限制,从序列数据的角度重新思考HS图像分类过程,并提出了一个基于最新transformers[27]的新型骨干网络架构,简称SpectralFormer,以实现高性能的HS图像分类任务。SpectralFormer为上述两个缺点提供了点对点的解决方案。更具体地说,SpectralFormer能够学习来自多个相邻波段的局部光谱表示,而不是原始transformers中的单波段(在每个编码位置),例如,群组级与波段级嵌入。此外,SpectralFormer设计了一个跨层跳跃连接,通过自适应学习融合它们的“软”残差,从浅层到深层逐步传递类似记忆的组件。本文的主要贡献可以总结如下。
- 从序列的角度重新审视HS图像分类问题,并提出了一个新的基于transformers的骨干网络,称为SpectralFormer,以替代基于CNNs或RNNs的架构。据所知,这是第一次纯粹地将transformers(没有任何预处理操作,例如,使用卷积和递归单元或任何其他转换技术进行特征提取)应用于HS图像分类任务。
- 在SpectralFormer中设计了两个简单但有效的模块,即群组级光谱嵌入(GSE)和跨层自适应融合(CAF),以学习局部详细的光谱表示,并分别从浅层到深层传递类似记忆的组件。
- 在三个代表性的HS数据集上定性和定量地评估了所提出的SpectralFormer的分类性能,即Indian Pines、Pavia University和University of Houston,并进行了广泛的消融研究。实验结果表明,与经典transformers(OA增加了约10%)和其他最先进的骨干网络(至少OA提高了2%)相比,具有显著的优越性。
II. SPECTRALFORMER
在本节中,首先回顾经典的transformers相关文献,然后详细说明所提出的SpectralFormer,它包含两个精心设计的模块,即GSE和CAF,使其更适用于HS图像分类任务。最后,还研究了所提出的SpectralFormer模型在输入图像块时对空间上下文信息的建模能力。
A. 变压器的简要回顾
众所周知,transformers[27]在处理自然语言处理(NLP)中的序列到序列问题方面取得了显著的成果,例如机器翻译。由于它们放弃了RNNs中的序列依赖特征,并引入了一种全新的自注意力机制。这使得任何位置的单元都能捕获全局序列信息(长期依赖关系),极大地推动了时间序列数据处理模型的发展。即使不仅限于NLP,图像处理和计算机视觉领域也开始探索transformer架构。最近,视觉transformer(ViT)[33]似乎在各种视觉领域任务上实现了或接近了基于CNNs的最新效果,为视觉相关任务提供了新的见解、灵感和创意空间。transformers的成功在很大程度上取决于多头注意力的使用,其中多个自注意力(SA)[34]层被堆叠和集成。顾名思义,SA机制更擅长捕获数据或特征的内部相关性,从而减少了对外部信息的依赖。图2(a)说明了transformers中SA模块的过程。更具体地说,SA层可以按照以下六个步骤执行:
步骤1. 输入序列数据x,长度为m,其中xi,i = 1,…,m表示标量或向量。
步骤2. 在每个标量或向量xi上获得特征嵌入ai,通过共享矩阵W获得。
步骤3. 每个嵌入分别乘以三个不同的变换矩阵Wq、Wk、Wv,得到三个向量,即查询(Q = [q1,…qm])、键(K = [k1,…km])、值(V = [v1,…,vm])。
步骤4. 计算每个Q向量和每个K向量之间的注意力分数s,以内积的形式,例如,qi · kj,并为了稳定梯度,通过归一化获得缩放分数,即si,j = qi · kj/ √ d,其中d是qi或kj的维度。
步骤5. 对s执行Softmax激活函数;然后有在位置1的情况下: ˆs1,i = es1,i/ ∑j es1,j。
步骤6. 生成注意力表示z = [z1,…,zm],例如,z1 = ∑i ˆs1,ivi。
总之,SA层可以整体表述如下:
z = Attention(Q, K, V) = softmax(QK⊤/ √d)V. (1)
使用方程(1),多个不同的SA层可以组装成多头注意力,如图2(b)所示。具体来说,首先获得多个注意力表示(例如,h = 8),表示为zh,h = 1,…,8,并连接它们成为一个更大的特征矩阵。最后使用线性变换矩阵(例如,Wo)使特征维度与输入数据相同。但需要注意的是,SA层中没有位置信息,这无法利用序列信息。因此,将位置信息编码到特征嵌入中。带有时间信号的嵌入可以这样表述ai+ei,其中ei表示手动给出的唯一位置向量。
B. SpectralFormer概述
目标是开发一种新颖且通用的基于ViT的基线网络(即SpectralFormer),重点关注光谱特性,使其适用于高精度和精细分类HS图像。为此,设计了两个关键模块,即GSE和CAF,并将其集成到transformer框架中,以提高对细微光谱差异的捕获能力,并增强层间信息传递(或连接性)(即,随着层的逐渐加深,减少信息丢失)。此外,所提出的SpectralFormer不仅适用于像素级HS图像分类,还可以扩展到空间-光谱分类,输入批量数据,产生空间-光谱SpectralFormer版本。图3展示了所提出的SpectralFormer在HS图像分类任务的概述图,而表I详细说明了所提出的SpectralFormer中使用的符号定义。
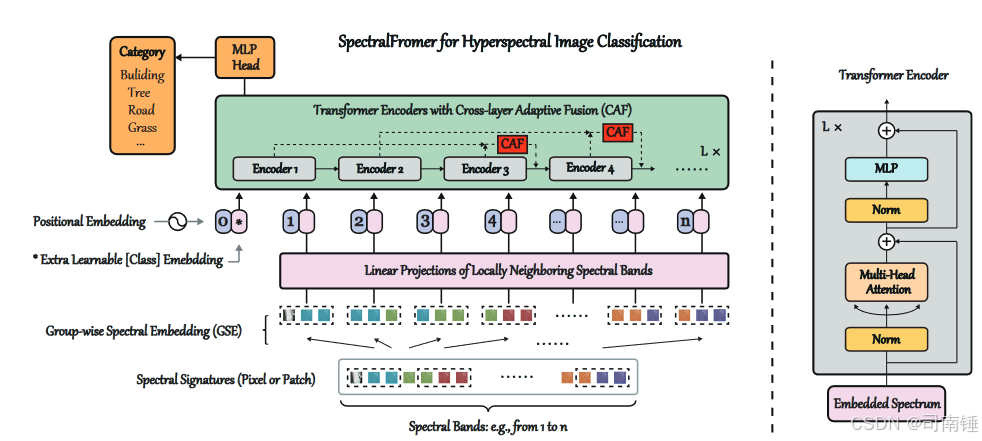
C. 群组级光谱嵌入(GSE)
与经典transformers或ViT中的离散序列性不同(例如,图像块),HS图像中的数百或数千个光谱通道以微妙的间隔(例如,10nm)从电磁谱中密集采样,产生近似连续的光谱签名。不同位置的光谱信息反映了不同波长的对应材料的不同吸收特性。这在很大程度上显示了当前材料的物理属性。捕获这些光谱签名的局部详细吸收(或变化)是准确和精细分类HS场景中材料的关键因素。为此,提出学习群组级光谱嵌入,即GSE,而不是波段级输入和表示。给定一个光谱签名(HS图像中的一个像素)x = [x1,x2,…,xm] ∈ R1×m,经典transformers通过以下方式获得特征嵌入A:
A = wx, (2)
其中w ∈ Rd×1表示线性变换,等同于在光谱签名的所有波段中使用,A ∈ Rd×m收集输出特征。而提出的GSE从局部光谱轮廓(或相邻波段)中学习特征嵌入。因此,GSE可以建模为
A = W X = W g(x), (3)
其中W ∈ Rd×n和X ∈ Rn×m分别对应于变量w和x的分组表示,n表示考虑的相邻波段数。变量W可以简单地看作是网络的一层,可以通过更新整个网络进行优化。函数g(·)表示对变量x的重叠分组操作,即
X = g(x) = [x1,…,xq,…,xm], (4)
其中xq = [xq−⌊n/2⌋,…,xq,…,xq+⌊n/2⌋]⊤ ∈ Rn×1,⌊•⌋表示四舍五入操作。图4比较了基于transformers的骨干网络中的波段级和群组级光谱嵌入(BSE与GSE)的差异。
D. 跨层自适应融合(CAF)
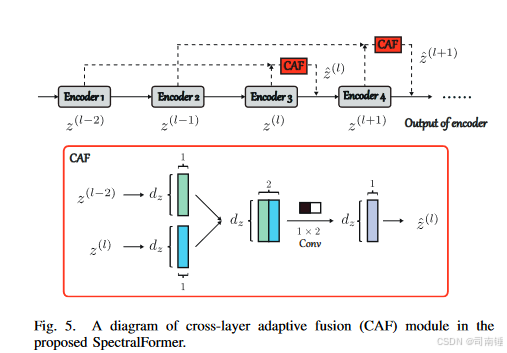
跳跃连接(SC)机制已被证明是深度网络中的有效策略,可以增强层间信息交换并减少网络学习过程中的信息丢失。最近,SC在图像识别和分割中取得了巨大成功,例如ResNet中的短SC[35]和U-Net中的长SC[36]。但需要注意的是,短SC的“记忆”能力有限,而长SC往往由于高低层次特征之间的大差距导致融合不足。这也是transformers中存在的关键问题,为transformers架构设计带来了新的挑战。为此,在SpectralFormer中设计了一个中间范围的SC,以自适应地学习跨层特征融合(即CAF,见图5)。设z(l−2) ∈ R1×dz和z(l) ∈ R1×dz分别为(l−2)层和(l)层的输出(或表示),CAF可以表示为
ˉz(l) ← ¨w ˚ z(l)/ z(l−2), (5)
其中ˉz(l)表示在第(l)层使用所提出的CAF融合后的表示,¨w ∈ R1×2是用于自适应融合的可学习网络参数。需要注意的是,的CAF只跳过一个编码器,例如,从z(l−2)(编码器1的输出)到z(l)(编码器3的输出)在图5中。这种设置的原因有两个。一方面,从浅层和深层获得的低层次和深层次特征之间存在很大的语义差距。如果使用相对较长的SC,例如两个、三个甚至更多的编码器,可能会导致融合不足和潜在的信息丢失。另一方面,HS图像分类通常可以被视为一个小样本问题,因为可用的训练(需要手动标记)样本有限。一个“小”或“浅”的骨干网络,例如4或5层,可能已经适合HS图像分类任务。因此,这在一定程度上可以解释为什么提出在CAF模块中只跳过一个编码器(因为4或5层的浅网络无法添加多个CAF模块)。
E. 空间-光谱SpectralFormer
除了像素级HS图像分类,还研究了块级输入(受CNNs启发),产生了空间-光谱SpectralFormer版本,即块级SpectralFormer。与直接输入3D块的CNNs不同,沿着空间方向展开每个波段的2D块,然后将其展开为相应的1D向量表示。给定一个3D块X ∈ Rm×w×h(w和h是块的宽度和长度),
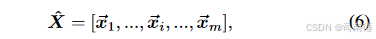
其xi ∈ Rwh×1表示第i个波段的展开块。这种输入方式可以在网络学习中极大地保留光谱序列信息,同时考虑空间上下文信息。
III. 实验
在本节中,首先描述三个著名的HS数据集,然后介绍实现细节和比较的最先进方法。最后,通过广泛的实验和消融分析,定量和定性地评估所提出的SpectralFormer在HS图像分类中的性能。
A. 数据描述
-
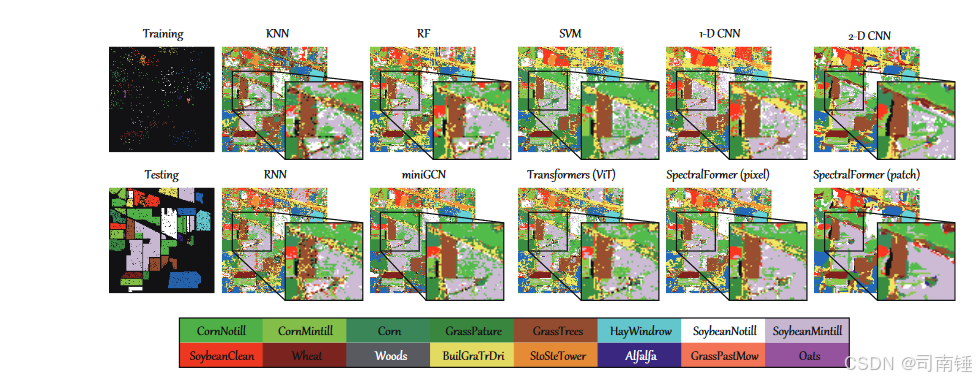
Indian Pines数据 第一个HS数据是在1992年使用Airborne Visible/Infrared Imaging Spectrometer(AVIRIS)传感器在美国印第安纳州西北部收集的。HS图像由145 × 145像素组成,地面采样距离(GSD)为20m,有220个光谱带,覆盖400nm至2500nm的波长范围,光谱分辨率为10m。移除20个嘈杂和水吸收波段后,保留了200个光谱带,即1-103、109-149、164-219。在这个研究场景中有16个主要研究类别。表II列出了每个类别的类别名称和用于训练和测试的样本数量,图7还提供了训练和测试集的空间分布,以便重现分类结果。
-
Pavia University数据 第二个HS场景是由Reflective Optics System Imaging Spectrometer(ROSIS)传感器在意大利帕维亚大学及其周围地区捕获的。传感器可以捕获103个光谱带,范围从430nm到860nm,图像由610 × 340像素组成,GSD为1.3m。这个场景包括9个土地覆盖类别,表III详细列出了固定数量的训练和测试样本,并在图8中进行了空间可视化。
-
Houston2013数据: 第三个数据集是由ITRES CASI-1500传感器在美国德克萨斯州休斯顿大学校园及其邻近农村地区捕获的,作为一个基准数据集,已被广泛用于评估土地覆盖分类的性能[37]。HS立方体包含349 × 1905像素,有144个波长带,范围在364nm至1046nm之间,间隔为10nm。值得注意的是,我们使用的Houston2013数据集是无云版本,通过生成与照明相关的阈值图来恢复缺失数据或移除遮挡[1]。表IV列出了15个具有挑战性的土地覆盖和土地利用类别以及相应的训练和测试样本数量。同样,图10提供了2013年IEEE GRSS数据融合比赛提供的假彩色HS图像和发布的训练和测试样本的可视化结果[2]。
B. 实验设置
-
评估指标: 我们使用三种常用指标来定量评估每个模型的分类性能,即总体准确率(OA)、平均准确率(AA)和Kappa系数(κ)。此外,还通过可视化不同模型获得的分类图来进行定性比较。
-
与最先进的骨干网络比较: 选择了几个代表性的基线和骨干网络进行比较实验。它们是K-最近邻(KNN)、支持向量机(SVM)、随机森林(RF)、1-D CNN[17]、2-D CNN[22]、RNN[23]、miniGCN[26]、transformers[27]和所提出的SpectralFormer。这些比较方法的参数配置如下:
-
对于KNN,最近邻(K)的数量是一个重要因素,这极大地影响了分类性能。我们将其设置为10。
-
对于RF,我们的实验中使用了200个决策树。
-
对于SVM,我们选择了libsvm工具箱[3]来实现HS图像分类任务。SVM使用径向基函数(RBF)核。在RBF中,两个超参数σ和λ可以通过在训练集上进行五折交叉验证来最优确定,σ的范围是[2−3, 2−2,…,24],λ的范围是[10−2, 10−1,…,104]。
-
对于1-D CNN,一个卷积块被定义为基本网络单元,包括一组输出大小为128的1-D卷积滤波器、一个批量归一化(BN)层和一个ReLU激活函数。最后在1-D CNN的顶层添加了一个softmax函数。
-
2-D CNN架构有三个2-D卷积块和一个softmax层。与1-D CNN类似,2-D CNN的每个卷积块由2-D传统层、BN层、最大池化层和ReLU激活函数组成。此外,每个2-D卷积层的空间和光谱接收场分别为3 × 3 × 32、3 × 3 × 64和1 × 1 × 128。
-
对于RNN,有两个递归层,具有门控递归单元(GRU)。每个层有128个神经元单元。使用的代码可以从https://github.com/danfenghong/HyFTech公开获得。
-
对于miniGCN,网络块连续包含一个BN层、一个具有128个神经元单元的图卷积层和一个ReLU层。注意,GCN中的邻接矩阵可以使用基于KNN的图生成(K的数量与KNN分类器相同,即K = 10)。miniGCN和1-D CNN共享相同的网络架构(为了公平比较)。顾名思义,miniGCN可以以小批量方式进行训练。我们参考[26]了解更多细节和代码[4],以便重现。
-
对于transformers[5],我们遵循ViT网络架构[33],即只包括transformer编码器。具体来说,ViT-based网络中使用了五个编码器块进行HS图像分类。
-
对于所提出的SpectralFormer,采用了与上述transformers相同的骨干架构,以便进行公平比较。具体来说,将嵌入的光谱输入64个单元,输入到5个级联的transformer编码器块中进行HS图像分类。每个编码器块由一个四头SA层、一个具有8个隐藏维度的MLP和一个GELU[38]非线性激活层组成。在编码器块之后的位置编码和MLPs中使用dropout层,以抑制10%的神经元。考虑到从像素级SpectralFormer到块级SpectralFormer的参数大小显著增加(块大小经验设置为7 × 7),我们额外使用了ℓ2权重衰减正则化[39],参数化为5e−3,以防止后者潜在的过拟合风险。
-
实现细节: 提出的SpectralFormer在PyTorch平台上实现,使用配备i7-6850K CPU、128GB RAM和NVIDIA GTX 1080Ti 11GB GPU的工作站。我们采用Adam优化器[40],批量大小为64。初始学习率为5e−4,并在总周期的十分之一后乘以0.9进行衰减。我们大致将三个数据集的周期设置为1000[6]。但值得注意的是,我们发现在实践中,我们的SpectralFormer带有CAF模块能够在少得多的周期内通过收敛实现显著的效率提升,即Indian Pines数据集的300周期,以及其他两个数据集的600周期。
-
计算复杂性分析: 对于给定的HS图像,其光谱长度为m,所提出的SpectralFormer每层的计算复杂性主要由自注意力和多头操作主导,需要总体O(m2d + md2),其中d是隐藏特征的大小,这也用于深度竞争者进行公平的理论比较。RNN在经过m次序列操作后,复杂度为O(md2),而内核宽度为k的CNN将其增加到O(kmd2)。GCN(即miniGCN)由于其批量图采样,需要O(bmd + b2m),其中b表示小批量的大小。
C. 模型分析
-
消融研究: 我们通过逐步添加不同的模块(即GSE和CAF)来研究所提出的SpectralFormer在分类准确率方面的性能提升。为此,我们在Indian Pines数据集上进行了广泛的消融实验,以验证这些组件(或模块)在HS图像分类应用中SpectralFormer的有效性,如表V所示。具体来说,没有GSE和CAF模块的经典transformers(ViT)获得了最低的分类准确率,这在一定程度上表明ViT架构可能不适合HS图像分类。通过在ViT中插入GSE或CAF,像素级SpectralFormer的分类结果优于ViT(分别超过约4%和3%的OA)。更值得一提的是,GSE和CAF的联合利用可以进一步带来显著的性能提升(超过4%的OA)。更引人注目的是,我们的SpectralFormer还能够通过简单地展开块级输入来捕获HS图像的局部空间语义。因此,块级SpectralFormer的表现明显优于像素级,至少提高了3%的OA(与第二条记录,即78.55%相比)。有趣的是,表V中有一个值得注意的趋势。也就是说,当仅使用较少的相邻波段时,GSE和CAF的联合使用往往能够获得最佳性能,与仅使用GSE相比。这可以很好地解释为,在激活CAF模块后,光谱信息能够更有效地学习和更容易获得。换句话说,在GSE中相邻波段的重叠较少(即GSE中考虑的相邻波段数量较少)可能就足以获得更好的分类性能。
-
参数敏感性分析 除了网络中的可学习参数和训练过程中所需的超参数外,GSE中的相邻波段数量在最终分类性能中也起着至关重要的作用。因此,探索适当的参数范围是不可或缺的。同样,我们在Indian Pines数据集上以消融方式进行了参数敏感性分析,即仅使用GSE和GSE与CAF的联合使用。表VI列出了随着分组波段数量逐渐增加,分类准确率的变化趋势,以OA、AA和κ为指标。一个共同的结论是,GSE可以通过有效地捕获相邻波段的局部光谱嵌入来更好地挖掘细微的光谱差异。在一定范围内,该参数对分类性能不敏感。这为所提出的模型在实际应用中提供了巨大的潜力。换句话说,该参数可以简单地直接用于其他数据集。我们还在Indian Pines数据集上对使用短程SC(例如,在ResNet中)、长程SC(例如,在U-Net中)和中程SC(即我们的CAF模块)的transformers进行了定量比较,以验证所提出的SpectralFormer在处理光谱数据方面的有效性。表VII量化了在Indian Pines数据集上使用短程、中程和长程SC的分类性能比较。总的来说,具有长程SC的ViT表现较差,可能是因为这种SC策略可能无法充分融合和传递跨层特征,倾向于部分“重要”信息的丢失。这展示了CAF模块的优越性,它可以比短程SC更有效地交换不同层之间的信息(cf.短程SC)并减少信息丢失(cf.长程SC)。此外,我们随机选择Indian Pines数据集给定训练集中的不同数量的训练样本,进行了10次运行,比例为[10%,20%,…,100%],间隔为10%。所提出的SpectralFormer(包括像素级和块级版本)在OA方面获得的平均结果和标准差值在图6中报告。OA的结果基本上呈现出合理的趋势。也就是说,随着使用的培训样本比例的增加,分类性能逐渐提高。值得注意的是,当涉及更多的培训样本(例如,80%,90%和100%)时,OA趋于稳定,这在很大程度上显示了所提出的SpectralFormer的稳定性。而且,块级SpectralFormer的预期表现优于像素级。
D. 定量结果和分析
在表VIII、IX和X中,报告了Indian Pines、Pavia University和Houston2013 HS数据集的定量分类结果,分别以OA、AA和κ三个总体指标以及每个类别的准确率。总体而言,传统的分类器,例如KNN、RF、SVM,在所有三个数据集上的分类性能相似,除了Indian Pines数据集上的KNN在OA、AA和κ方面的准确率远低于使用RF和SVM的准确率。由于DL技术的强大的学习能力,经典的骨干网络,例如1-D CNN、2-D CNN、RNN、miniGCN,明显优于上述传统分类器,例如KNN、RF、SVM。结果在很大程度上证明了DL方法在HS图像分类中的价值和实用性。与没有任何卷积和递归操作的transformers相比,可以从序列角度提取更精细的光谱表示,获得与基于CNNs、RNNs或GCNs的模型相当的性能。
尽管transformers能够捕获全局序列信息,但在建模一些关键因素——局部光谱差异——方面的能力有限,导致性能瓶颈。为了克服这个问题,所提出的SpectralFormer充分提取了相邻波段的局部光谱信息,显著提高了分类性能。特别是,像素级SpectralFormer出人意料地超越了其他方法,尽管与考虑空间内容的CNNs方法相比。毫无疑问,块级SpectralFormer获得了更高的分类准确率,远远优于其他竞争对手,因为在序列特征提取过程中联合考虑了空间上下文信息。此外,对于那些训练样本有限(例如,Grass Pasture Mowed,Oats)和不平衡(或嘈杂)样本(例如,Corn Mintill,Grass Pasture,Hay Windrowed)的Indian Pines数据上的具有挑战性的类别,SpectralFormer,无论是像素级还是块级输入,都倾向于通过关注光谱轮廓的特定吸收位置获得更好的分类性能。相反,尽管transformers(我们案例中的ViT)在光谱序列数据的表示能力方面表现出色,但由于在局部光谱差异建模能力较弱,无法准确捕获详细的光谱吸收或变化。
E. 视觉评估
我们通过可视化不同方法获得的分类图来进行定性评估。图7、8和10分别提供了Indian Pines、Pavia University和Houston2013数据集的获得结果。大致来说,传统的分类模型(例如,KNN、RF、SVM)倾向于在三个考虑的数据集的分类图中产生盐和胡椒噪声。这间接表明这些分类器无法准确识别材料和对象。不足为奇的是,基于DL的模型,例如CNNs、RNNs、GCNs,由于其强大的非线性数据拟合能力,获得了相对平滑的分类图。作为一种新兴的网络架构,transformers(我们案例中的ViT)可以从HS图像中提取高度序列化的表示,导致可视化的分类图与上述经典骨干网络相当。通过增强光谱相邻信息并更有效地传递“记忆”信息,所提出的SpectralFormer获得了非常理想的分类图,特别是在纹理和边缘细节方面。此外,我们选择了一个感兴趣区域(ROI)(从图7、8和10中),放大2倍以突出显示不同模型之间的分类图差异,更直观地评估它们的分类性能。从这些ROIs中可以看出,一个显著的现象是,我们的方法,即像素级和块级SpectralFormers,显示出更现实和更精细的细节。特别是,我们方法的结果与像素级方法(例如,KNN、RF、SVM、1-D CNN、RNN、miniGCN、ViT)相比,噪声点更少,但也避免了边缘或一些小的语义对象的过度平滑(例如,2-D CNN),从而获得了更准确的分类性能。
IV. 结论
HS图像通常被收集(或表示)为一个包含空间-光谱信息的数据立方体,通常可以被视为沿光谱维度的序列数据。与主要关注上下文信息建模的CNNs不同,transformers已被证明是一种强大的架构,用于全局表征序列属性。然而,经典的基于transformers的视觉网络,例如ViT,在处理HS类数据时不可避免地遭受性能下降。这可以很好地解释,因为ViT未能有效地建模局部详细的光谱差异,并从浅层到深层有效地传递“记忆”组件。为此,本文提出了一种新的基于transformers的骨干网络,称为SpectralFormer,它更专注于提取光谱信息。不使用任何卷积或递归单元,所提出的SpectralFormer可以实现HS图像的最新分类结果。
在未来,我们将研究通过使用更先进的技术,例如注意力、自监督学习,进一步改进基于transformers的架构的策略,使其更适用于HS图像分类任务,并尝试建立一个轻量级的基于transformers的网络,以降低网络复杂性,同时保持其性能。此外,我们还将尝试将更多的光谱带物理特性和HS图像的先验知识嵌入到所提出的框架中,产生更具解释性的深度模型。此外,CAF模块中跳过和连接的编码器数量是一个可能能够提高所提出的SpectralFormer分类性能的重要因素,这应该在未来的工作中得到更多关注。
参考文献
[1] D. Hong等人,“可解释的高光谱人工智能:当非凸建模遇见高光谱遥感”,IEEE地球科学与遥感杂志,第9卷,第2期,2021年,页52-87。
[2] Y. Wang等人,“通过总变差正则化的低秩张量分解进行高光谱图像恢复”,IEEE精选应用地球观测与遥感杂志,第11卷,第4期,2017年,页1227-1243。
[3] W. Cao等人,“具有噪声结构学习和空间-光谱低秩建模的鲁棒PCA方法在高光谱图像恢复中的应用”,IEEE精选应用地球观测与遥感杂志,第11卷,第10期,2018年,页3863-3879。
[4] M. Wang等人,“l0-l1混合总变差正则化及其在高光谱图像混合噪声去除和压缩感知中的应用”,IEEE地球科学与遥感杂志,2021年。DOI: 10.1109/TGRS.2021.3055516。
[5] J. Peng等人,“低秩和稀疏表示在高光谱图像处理中的综述”,IEEE地球科学与遥感杂志,2021年。
[6] D. Hong等人,“具有空间-光谱流形对齐的联合和渐进子空间分析用于半监督高光谱降维”,IEEE网络杂志,第51卷,第7期,2021年,页3602-3615。
[7] F. Luo等人,“用于高光谱图像降维的半监督超图判别学习”,IEEE精选应用地球观测与遥感杂志,第13卷,2020年,页4242-4256。
[8] J. Yao等人,“基于非凸稀疏性和非局部平滑性的盲高光谱解混”,IEEE图像处理杂志,第28卷,第6期,2019年,页2991-3006。
[9] D. Hong等人,“增强线性混合模型以解决高光谱解混中的光谱变异性问题”,IEEE图像处理杂志,第28卷,第4期,2019年,页1923-1938。
[10] Y. Yuan等人,“改进的协同非负矩阵因式分解和总变差用于高光谱解混”,IEEE精选应用地球观测与遥感杂志,第13卷,2020年,页998-1010。
[11] L. Gao等人,“Cycunet:通过学习级联自编码器进行循环一致性解混的网络”,IEEE地球科学与遥感杂志,2021年。DOI: 10.1109/TGRS.2021.3064958。
[12] D. Hong等人,“Endmember-guided unmixing network (egu-net): 一种用于自监督高光谱解混的通用深度学习框架”,IEEE神经网络与学习系统杂志,2021年5月。DOI: 10.1109/TNNLS.2021.3082289。
[13] D. Hong等人,“学习在图上传播标签:一种用于半监督高光谱降维的迭代多任务回归框架”,ISPRS摄影测量与遥感杂志,第158卷,2019年,页35-49。
[14] J. Peng等人,“自步速联合稀疏表示用于高光谱图像分类”,IEEE地球科学与遥感杂志,第57卷,第2期,2018年,页1183-1194。
[15] D. Hong等人,“不变量属性配置文件:一种用于高光谱图像分类的空间-频率联合特征提取器”,IEEE地球科学与遥感杂志
,第58卷,第6期,2020年,页3791-3808。
[16] Q. Li等人,“基于集合经验模态分解的光谱-空间特征提取用于高光谱图像分类”,IEEE精选应用地球观测与遥感杂志,第13卷,2020年,页5134-5148。
[17] B. Rasti等人,“高光谱图像特征提取:从浅层到深度的演变:概述和工具箱”,IEEE地球科学与遥感杂志,第8卷,第4期,2020年,页60-88。
[18] Y. LeCun等人,“深度学习”,自然杂志,第521卷,第7553期,2015年,页436-444。
[19] X. Zhao等人,“使用层次随机游走和深度CNN架构对高光谱和LiDAR数据进行联合分类”,IEEE地球科学与遥感杂志,第58卷,第10期,2020年,页7355-7370。
[20] M. Zhang等人,“使用patch-to-patch CNN对高光谱和LiDAR数据进行特征提取和分类”,IEEE网络杂志,第50卷,第1期,2018年,页100-111。
[21] Y. Chen等人,“基于深度学习的高光谱数据分类”,IEEE精选应用地球观测与遥感杂志,第7卷,第6期,2014年,页2094-2107。
[22] Y. Chen等人,“基于卷积神经网络的高光谱图像深度特征提取与分类”,IEEE地球科学与遥感杂志,第54卷,第10期,2016年,页6232-6251。
[23] R. Hang等人,“级联递归神经网络用于高光谱图像分类”,IEEE地球科学与遥感杂志,第57卷,第8期,2019年,页5384-5394。
[24] L. Zhu等人,“用于高光谱图像分类的生成对抗网络”,IEEE地球科学与遥感杂志,第56卷,第9期,2018年,页5046-5063。
[25] M. E. Paoletti等人,“用于高光谱图像分类的胶囊网络”,IEEE地球科学与遥感杂志,第57卷,第4期,2018年,页2145-2160。
[26] D. Hong等人,“图卷积网络在高光谱图像分类中的应用”,IEEE地球科学与遥感杂志,第59卷,第7期,2021年,页5966-5978。
[27] A. Vaswani等人,“注意力就是全部你需要的”,arXiv预印本arXiv:1706.03762,2017年。
[28] S. Li等人,“深度学习在高光谱图像分类中的应用:综述”,IEEE地球科学与遥感杂志,第57卷,第9期,2019年,页6690-6709。
[29] H. Abdi和L. J. Williams,“主成分分析”,Wiley Interdiscip. Rev. Comput. Stat.,第2卷,第4期,2010年,页433-459。
[30] Y. Bengio等人,“用梯度下降学习长期依赖关系是困难的”,IEEE神经网络杂志,第5卷,第2期,1994年,页157-166。
[31] G. Ke等人,“重新思考语言预训练中的位置编码”,arXiv预印本arXiv:2006.15595,2020年。
[32] Y. Dong等人,“注意力不是你所需要的全部:纯粹的注意力在深度上会双重指数级地失去秩”,arXiv预印本arXiv:2103.03404,2021年。
[33] A. Dosovitskiy等人,“一张图片价值16×16个词:用于大规模图像识别的transformers”,arXiv预印本arXiv:2010.11929,2020年。
[34] X. Wang等人,“非局部神经网络”,在CVPR会议录,页7794-7803,2018年。
[35] K. He等人,“深度残差学习用于图像识别”,在CVPR会议录,页770-778,2016年。
[36] O. Ronneberger等人,“U-Net:用于生物医学图像分割的卷积网络”,在MICCAI会议录,页234-241,Springer,2015年。
[37] D. Hong等人,“更多样化意味着更好:多模态深度学习遇见遥感图像分类”,IEEE地球科学与遥感杂志,第59卷,第5期,2021年,页4340-4354。
[38] D. Hendrycks和K. Gimpel,“高斯误差线性单元(GELUs)”,arXiv预印本arXiv:1606.08415,2016年。
[39] I. Loshchilov和F. Hutter,“解耦权重衰减正则化”,arXiv预印本arXiv:1711.05101,2017年。
[40] D. Kingma和J. Ba,“Adam:一种用于随机优化的方法”,arXiv预印本arXiv:1412.6980,2014年。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











