






1.鸢尾花数据集降维(原始数据集维度是4,降维后数据集维度是2)
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import pandas as pd
data = load_iris() # 以字典形式加载鸢尾花数据集
y = data.target # 使用y表示数据集中的标签
X = data.data # 使用X表示数据集中的属性数据
pca = PCA(n_components=2) # 加载PCA算法,设置降维后主成分数目为2
reduced_X = pca.fit_transform(X) # 对原始数据进行降维,保存在reduced_X中
print("降维前:",X.shape)
print("降维后",reduced_X.shape)结果:
降维前: (150, 4)
降维后 (150, 2)2. 对比特征值特征向量
import matplotlib.pyplot as plt
import numpy as np
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import pandas as pd
data = load_iris() # 以字典形式加载鸢尾花数据集
y = data.target # 使用y表示数据集中的标签
X = data.data # 使用X表示数据集中的属性数据
Xcov=np.cov(X.T) #计算协方差矩阵
eig,featueVector=np.linalg.eig(Xcov)
print("原始数据特征值:",eig)#计算降维前数据的特征值
print("原始数据特征向量:\n",featueVector)#计算降维前数据的特征向量
pca = PCA(n_components=2) # 加载PCA算法,设置降维后主成分数目为2
reduced_X = pca.fit_transform(X) # 对原始数据进行降维,保存在reduced_X中
X1cov=np.cov(reduced_X.T) #计算协方差矩阵
eig1,featueVector1=np.linalg.eig(X1cov)
print("降维数据特征值:",eig1)#计算降维后数据的特征值
print("降维数据特征向量:\n",featueVector1)#计算降维后数据的特征向量
print("\n特征方差百分比:",pca.explained_variance_ratio_)
red_x, red_y = [], [] # 第一类数据点
blue_x, blue_y = [], [] # 第二类数据点
green_x, green_y = [], [] # 第三类数据点
for i in range(len(reduced_X)): # 按照鸢尾花的类别将降维后的数据点保存在不同的列表中。
if y[i] == 0:
red_x.append(reduced_X[i][0])#第一列
red_y.append(reduced_X[i][1])#第二列
elif y[i] == 1:
blue_x.append(reduced_X[i][0])
blue_y.append(reduced_X[i][1])
elif y[i]==2:
green_x.append(reduced_X[i][0])
green_y.append(reduced_X[i][1])
plt.scatter(red_x, red_y, c='r', marker='x',label='setosa')
plt.scatter(blue_x, blue_y, c='b', marker='D',label='versicolor')
plt.scatter(green_x, green_y, c='g', marker='.', label='Virginica')
plt.show()结果:
原始数据特征值: [4.22824171 0.24267075 0.0782095 0.02383509]
原始数据特征向量:
[[ 0.36138659 -0.65658877 -0.58202985 0.31548719]
[-0.08452251 -0.73016143 0.59791083 -0.3197231 ]
[ 0.85667061 0.17337266 0.07623608 -0.47983899]
[ 0.3582892 0.07548102 0.54583143 0.75365743]]
降维数据特征值: [4.22824171 0.24267075]
降维数据特征向量:
[[1.00000000e+00 1.82279585e-17]
[0.00000000e+00 1.00000000e+00]]
特征方差百分比: [0.92461872 0.05306648]
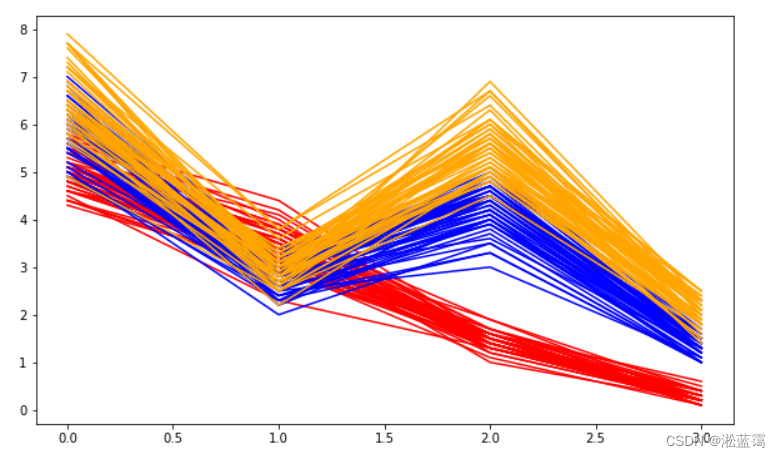
3. 降维前的四维图 (平行坐标图 (parallel coordinate plot) 是可视化高维多元数据的一种常用方法,为了显示多维空间中的一组对象,绘制由多条平行且等距分布的轴,并将多维空间中的对象表示为在平行轴上具有顶点的折线。顶点在每一个轴上的位置就对应了该对象在该维度上的中的变量数值)
import sklearn.datasets as ds
import pandas as pd
import matplotlib.pyplot as plt
iris = ds.load_iris()
x_name = iris.feature_names
x = iris.data #shape (150, 4)
y = iris.target
#鸢尾花平行座标图,不同类别的做了颜色区分
plt.figure(figsize=(10,6))
for i in range(150):
if y[i] == 0:
lcolor = 'red'
elif y[i] == 1:
lcolor = 'blue'
else:
lcolor = 'orange'
line = x[i,:]
plt.plot(line,color = lcolor)
plt.show()















 2817
2817











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









